Merge branch 'develop' of https://github.com/PaddlePaddle/Serving into dev_2
Showing
doc/C++Serving/Benchmark_CN.md
0 → 100755
文件已移动
此差异已折叠。
doc/C++Serving/Introduction_CN.md
0 → 100755
doc/cpp_server/C++DESIGN.md
已删除
100644 → 0
doc/images/asyn_benchmark.png
0 → 100644
{kind=link}
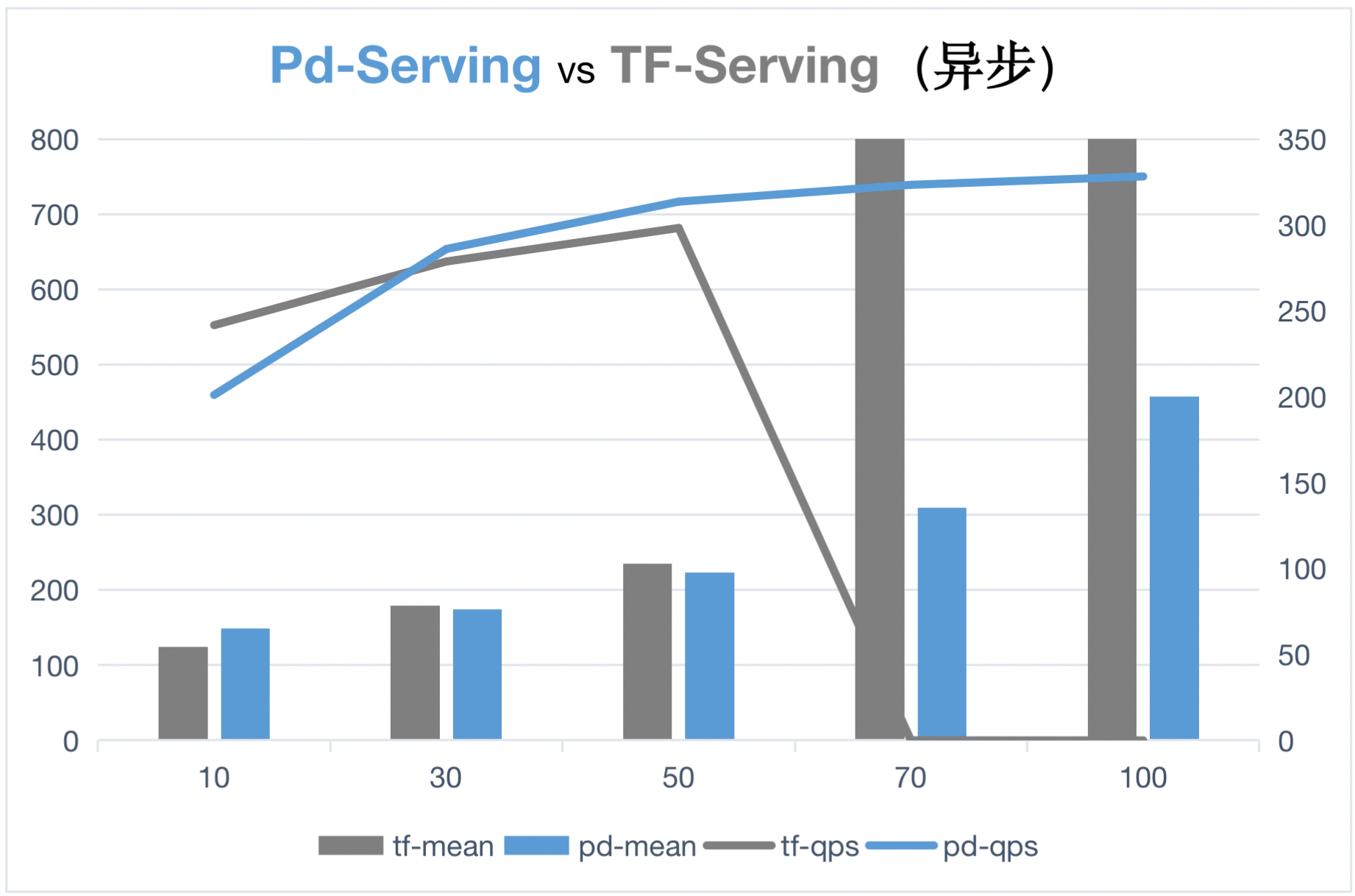
616.5 KB
doc/images/asyn_mode.png
0 → 100644
{kind=link}
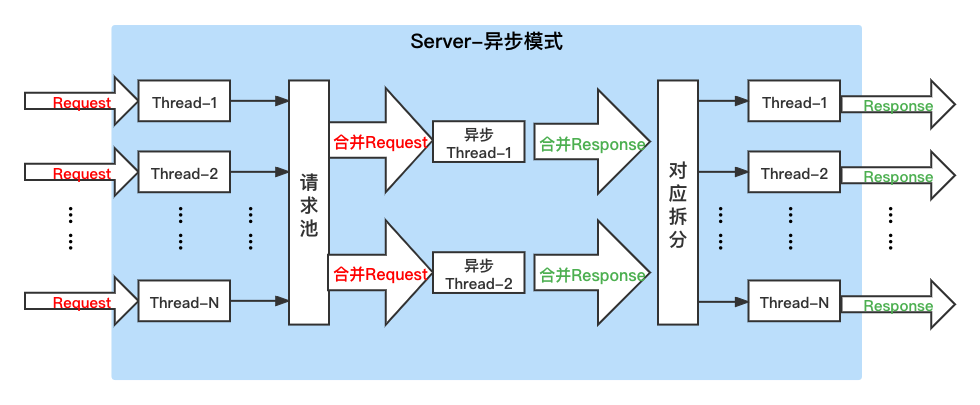
62.2 KB
doc/images/multi_model.png
0 → 100644
{kind=link}
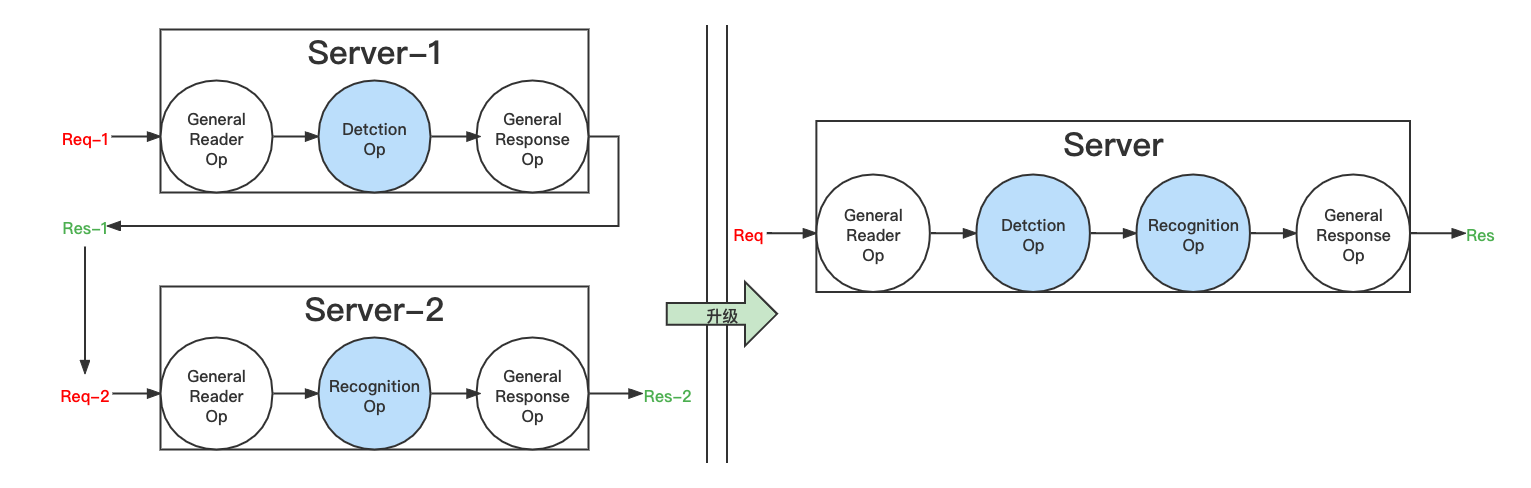
99.2 KB
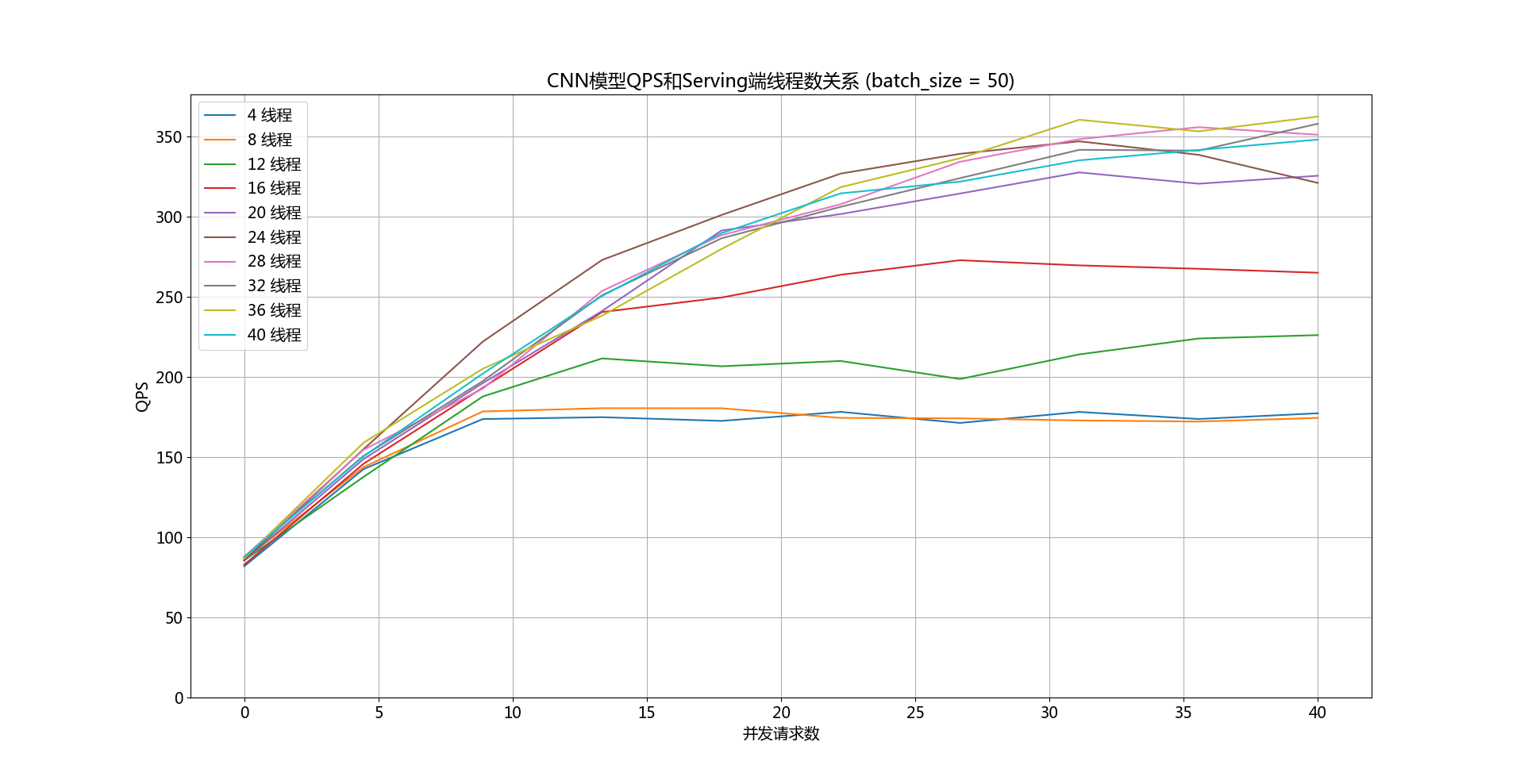
doc/images/qps-threads-bow.png
0 → 100755
{kind=link}
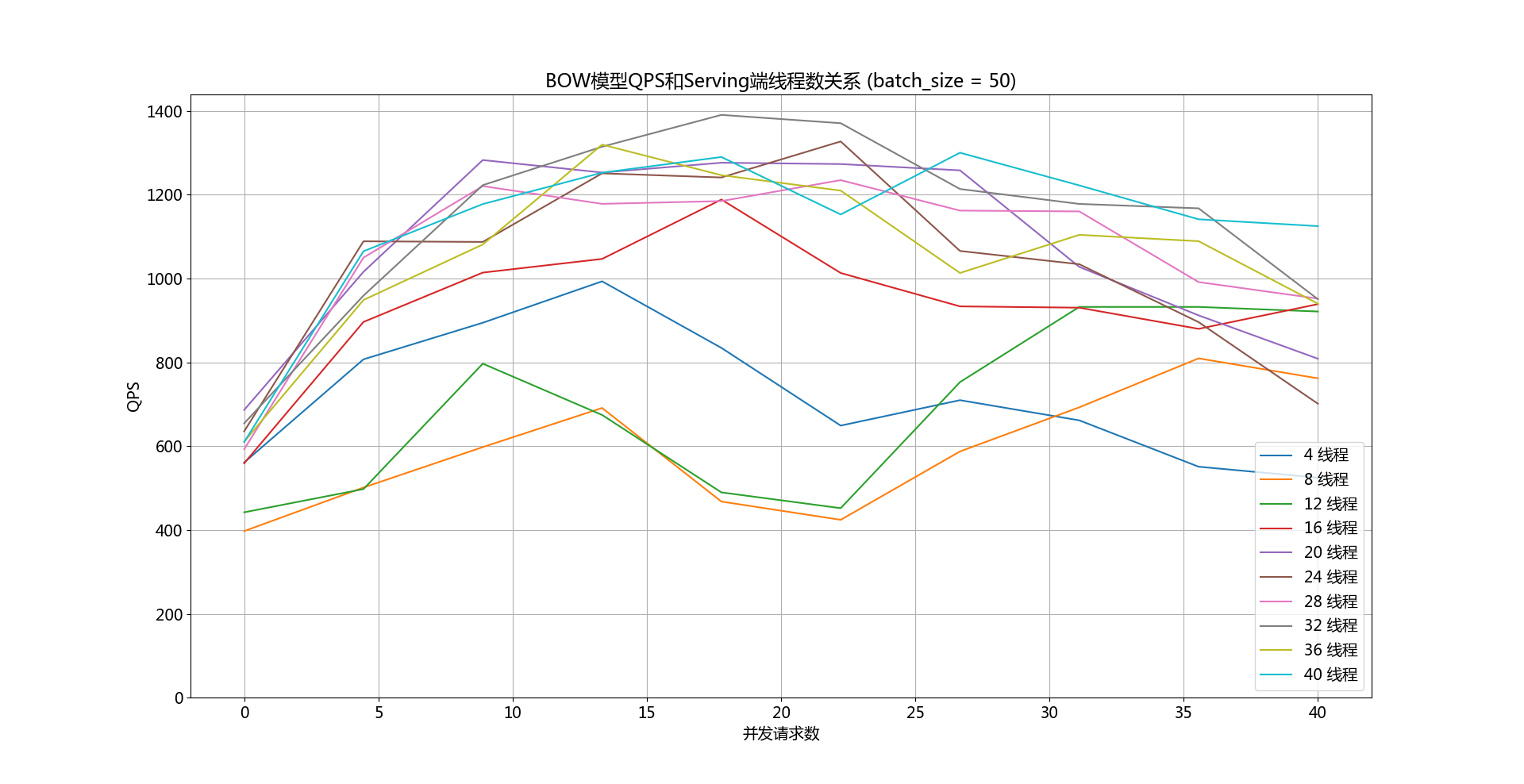
237.2 KB
doc/images/qps-threads-cnn.png
0 → 100755
{kind=link}
174.9 KB
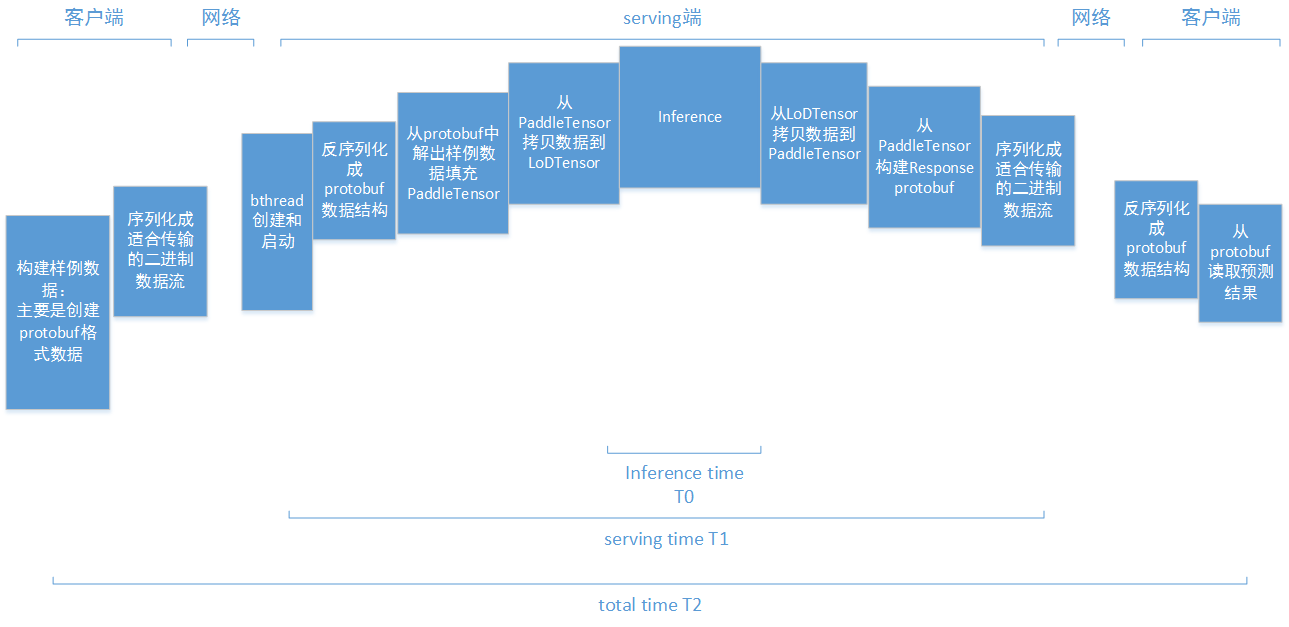
doc/images/serving-timings.png
0 → 100755
{kind=link}
36.9 KB
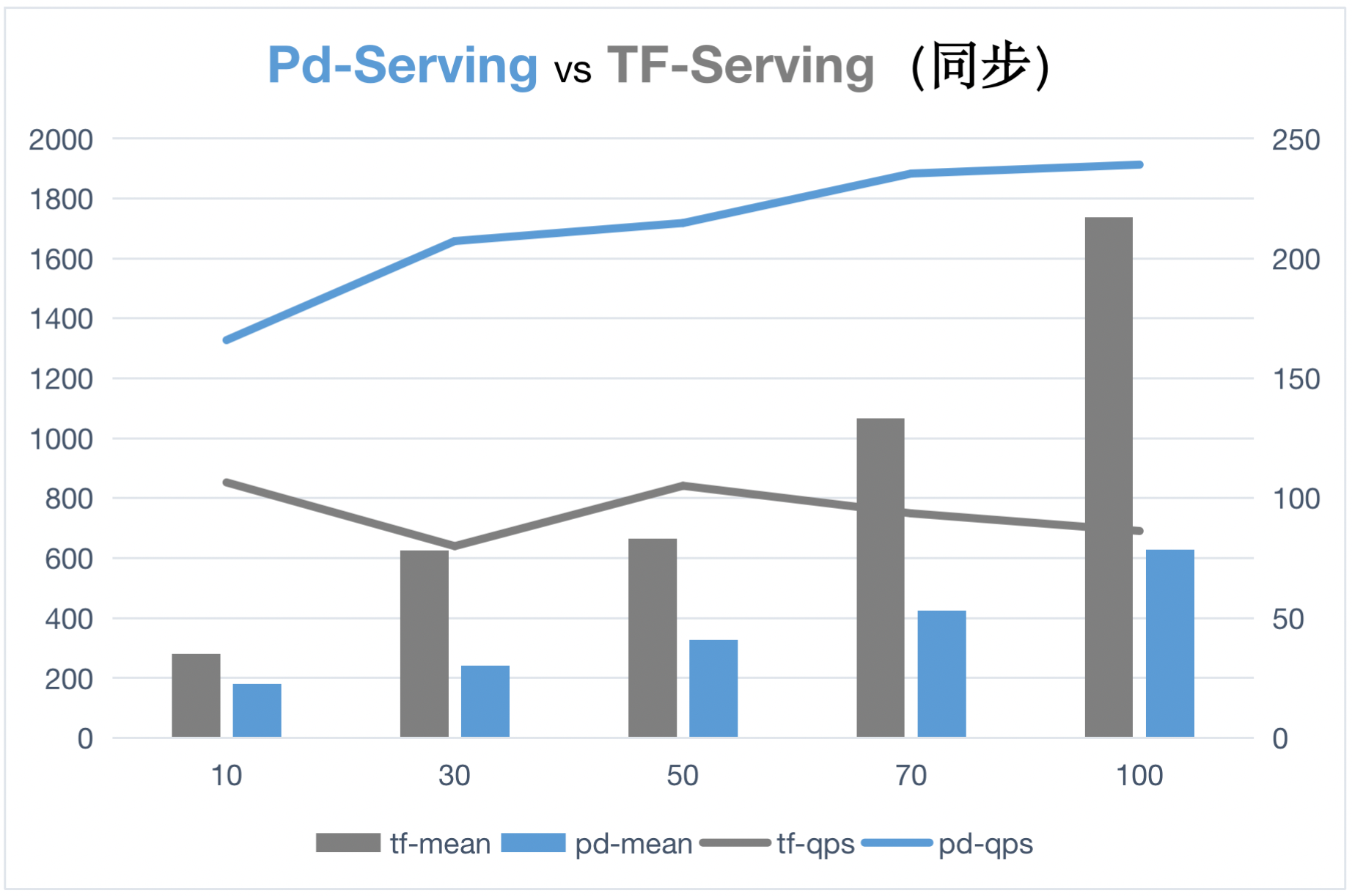
doc/images/syn_benchmark.png
0 → 100644
{kind=link}
595.1 KB
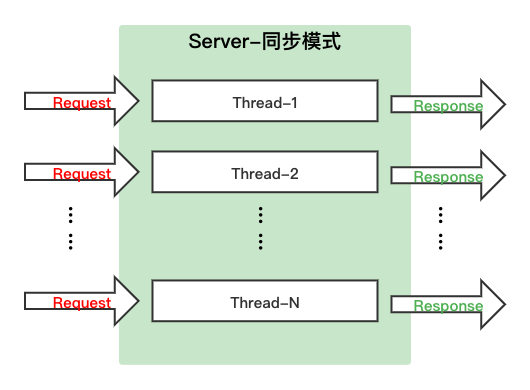
doc/images/syn_mode.png
0 → 100644
{kind=link}
27.9 KB