Merge pull request #225 from MRXLT/general-server-bert-v1
updated readme && benchmark
Showing
{kind=link}
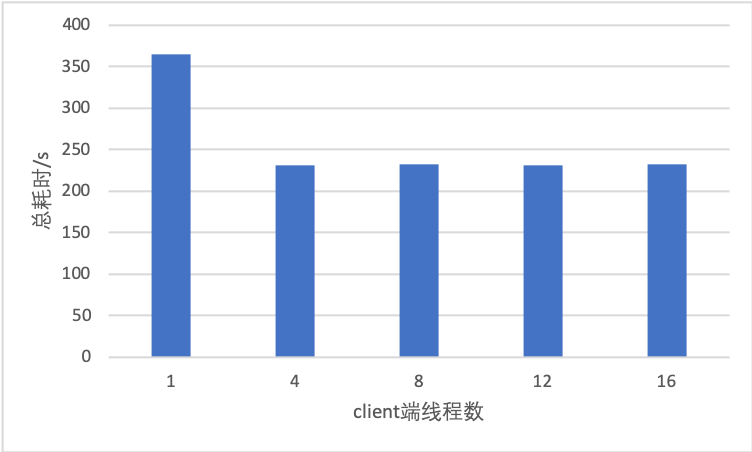
24.2 KB
doc/imdb-benchmark-server-16.png
0 → 100644
{kind=link}
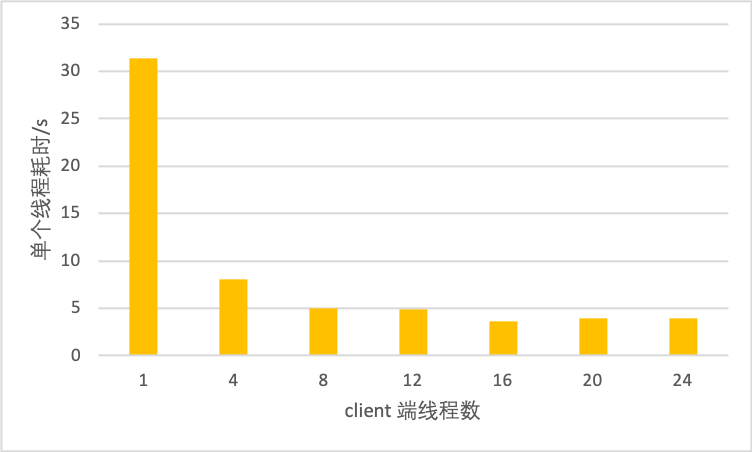
24.3 KB
python/examples/bert/README.md
0 → 100644
python/examples/util/README.md
0 → 100644