Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
223645b6
S
Serving
项目概览
PaddlePaddle
/
Serving
大约 2 年 前同步成功
通知
187
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
223645b6
编写于
3月 24, 2020
作者:
D
Dong Daxiang
提交者:
GitHub
3月 24, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #328 from MRXLT/doc
add doc build bert as service in 10 mins
上级
52b885a6
5857b506
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
85 addition
and
1 deletion
+85
-1
README.md
README.md
+1
-1
doc/4v100_bert_as_service_benchmark.png
doc/4v100_bert_as_service_benchmark.png
+0
-0
doc/BERT_10_MINS.md
doc/BERT_10_MINS.md
+84
-0
未找到文件。
README.md
浏览文件 @
223645b6
...
...
@@ -163,7 +163,7 @@ curl -H "Content-Type:application/json" -X POST -d '{"url": "https://paddle-serv
### New to Paddle Serving
-
[
How to save a servable model?
](
doc/SAVE.md
)
-
[
An end-to-end tutorial from training to serving(Chinese)
](
doc/TRAIN_TO_SERVICE.md
)
-
[
Write Bert-as-Service in 10 minutes
](
doc/B
ert_10_mins
.md
)
-
[
Write Bert-as-Service in 10 minutes
](
doc/B
ERT_10_MINS
.md
)
### Developers
-
[
How to config Serving native operators on server side?
](
doc/SERVER_DAG.md
)
...
...
doc/4v100_bert_as_service_benchmark.png
0 → 100644
浏览文件 @
223645b6
23.7 KB
doc/BERT_10_MINS.md
0 → 100644
浏览文件 @
223645b6
## 十分钟构建Bert-As-Service
Bert-As-Service的目标是给定一个句子,服务可以将句子表示成一个语义向量返回给用户。
[
Bert模型
](
https://arxiv.org/abs/1810.04805
)
是目前NLP领域的热门模型,在多种公开的NLP任务上都取得了很好的效果,使用Bert模型计算出的语义向量来做其他NLP模型的输入对提升模型的表现也有很大的帮助。Bert-As-Service可以让用户很方便地获取文本的语义向量表示并应用到自己的任务中。为了实现这个目标,我们通过四个步骤说明使用Paddle Serving在十分钟内就可以搭建一个这样的服务。示例中所有的代码和文件均可以在Paddle Serving的
[
示例
](
https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/bert
)
中找到。
#### Step1:保存可服务模型
Paddle Serving支持基于Paddle进行训练的各种模型,并通过指定模型的输入和输出变量来保存可服务模型。为了方便,我们可以从paddlehub加载一个已经训练好的bert中文模型,并利用两行代码保存一个可部署的服务,服务端和客户端的配置分别放在
`bert_seq20_model`
和
`bert_seq20_client`
文件夹。
```
python
import
paddlehub
as
hub
model_name
=
"bert_chinese_L-12_H-768_A-12"
module
=
hub
.
Module
(
model_name
)
inputs
,
outputs
,
program
=
module
.
context
(
trainable
=
True
,
max_seq_len
=
20
)
feed_keys
=
[
"input_ids"
,
"position_ids"
,
"segment_ids"
,
"input_mask"
,
"pooled_output"
,
"sequence_output"
]
fetch_keys
=
[
"pooled_output"
,
"sequence_output"
]
feed_dict
=
dict
(
zip
(
feed_keys
,
[
inputs
[
x
]
for
x
in
feed_keys
]))
fetch_dict
=
dict
(
zip
(
fetch_keys
,
[
outputs
[
x
]]
for
x
in
fetch_keys
))
import
paddle_serving_client.io
as
serving_io
serving_io
.
save_model
(
"bert_seq20_model"
,
"bert_seq20_client"
,
feed_dict
,
fetch_dict
,
program
)
```
#### Step2:启动服务
```
shell
python
-m
paddle_serving_server_gpu.serve
--model
bert_seq20_model
--thread
10
--port
9292
--gpu_ids
0
```
| 参数 | 含义 |
| ------- | -------------------------- |
| model | server端配置与模型文件路径 |
| thread | server端线程数 |
| port | server端端口号 |
| gpu_ids | GPU索引号 |
#### Step3:客户端数据预处理逻辑
Paddle Serving内建了很多经典典型对应的数据预处理逻辑,对于中文Bert语义表示的计算,我们采用paddle_serving_app下的ChineseBertReader类进行数据预处理,开发者可以很容易获得一个原始的中文句子对应的多个模型输入字段。
安装paddle_serving_app
```
shell
pip
install
paddle_serving_app
```
#### Step4:客户端访问
客户端脚本 bert_client.py内容如下
```
python
import
os
import
sys
from
paddle_serving_client
import
Client
from
paddle_serving_app
import
ChineseBertReader
reader
=
ChineseBertReader
()
fetch
=
[
"pooled_output"
]
endpoint_list
=
[
"127.0.0.1:9292"
]
client
=
Client
()
client
.
load_client_config
(
"bert_seq20_client/serving_client_conf.prototxt"
)
client
.
connect
(
endpoint_list
)
for
line
in
sys
.
stdin
:
feed_dict
=
reader
.
process
(
line
)
result
=
client
.
predict
(
feed
=
feed_dict
,
fetch
=
fetch
)
```
执行
```
shell
cat
data.txt | python bert_client.py
```
从data.txt文件中读取样例,并将结果打印到标准输出。
### 性能测试
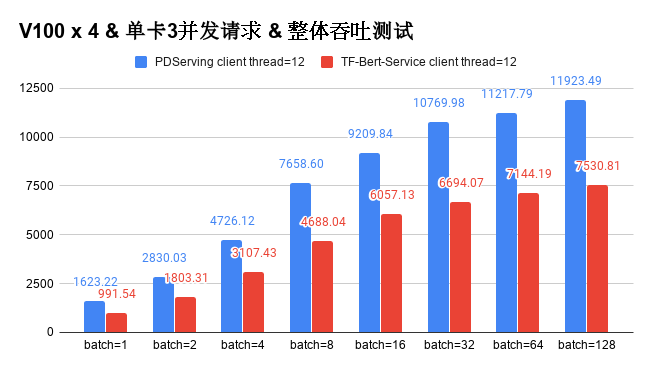
我们基于V100对基于Padde Serving研发的Bert-As-Service的性能进行测试并与基于Tensorflow实现的Bert-As-Service进行对比,从用户配置的角度,采用相同的batch size和并发数进行压力测试,得到4块V100下的整体吞吐性能数据如下。

编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}