Merge remote-tracking branch 'origin/doc' into doc
sync
Showing
doc/CUBE_LOCAL.md
0 → 100644
doc/CUBE_LOCAL_CN.md
0 → 100644
doc/DESIGN_DOC.md
0 → 100644
doc/DESIGN_DOC_EN.md
0 → 100644
doc/INSTALL.md
已删除
100644 → 0
doc/blank.png
0 → 100644
{kind=link}

18.2 KB
doc/coding_mode.png
0 → 100644
{kind=link}
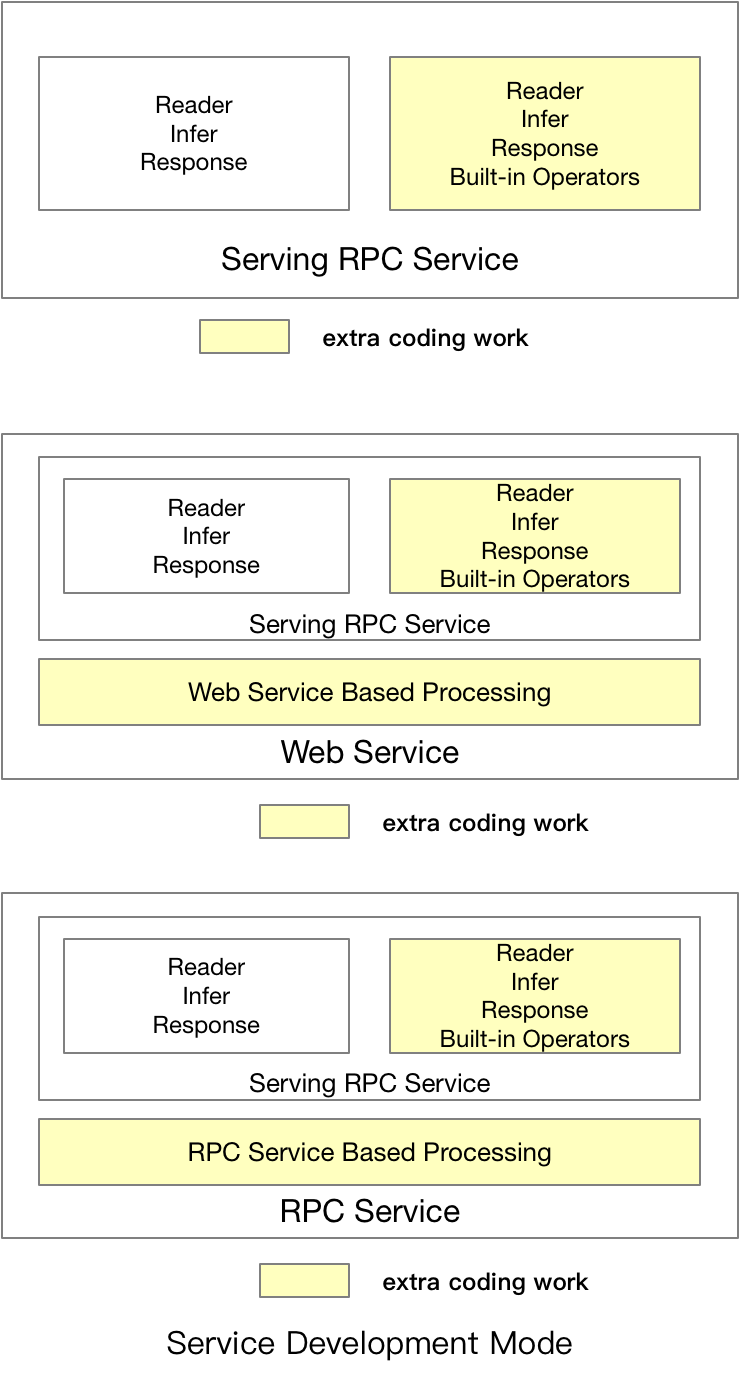
126.6 KB
doc/cube-cli.png
0 → 100644
{kind=link}
151.1 KB
doc/cube.png
0 → 100644
{kind=link}
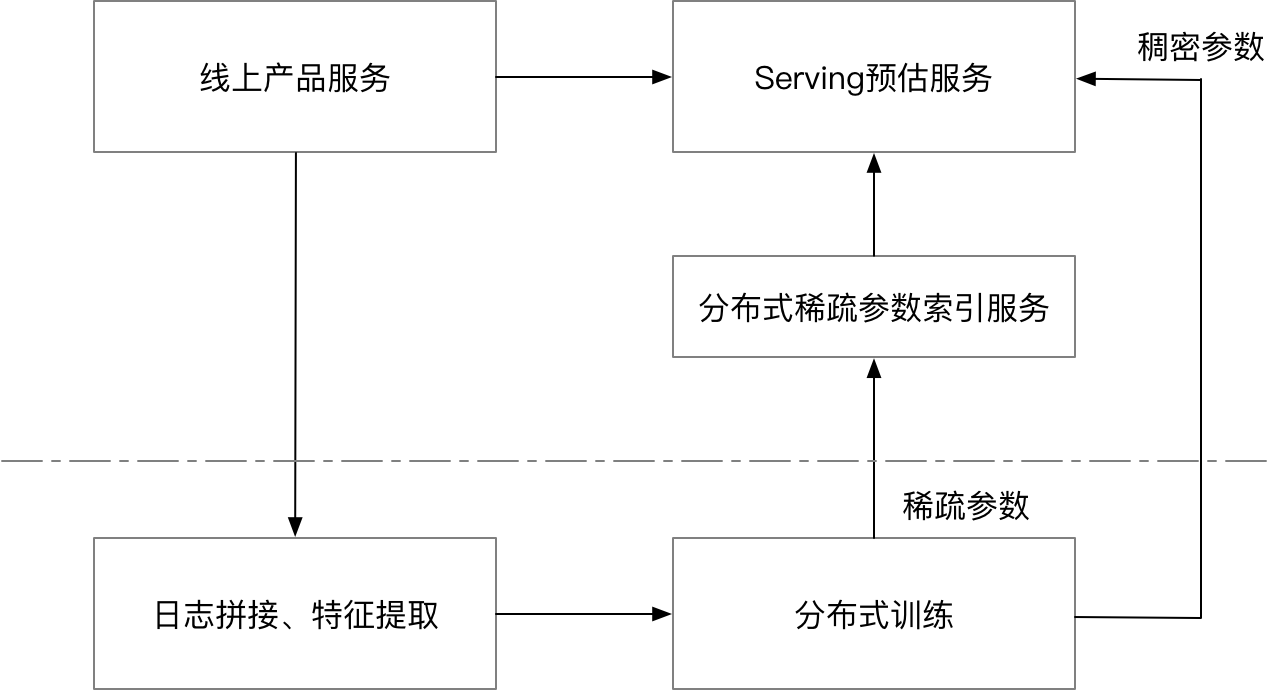
62.2 KB
doc/cube_eng.png
0 → 100644
{kind=link}
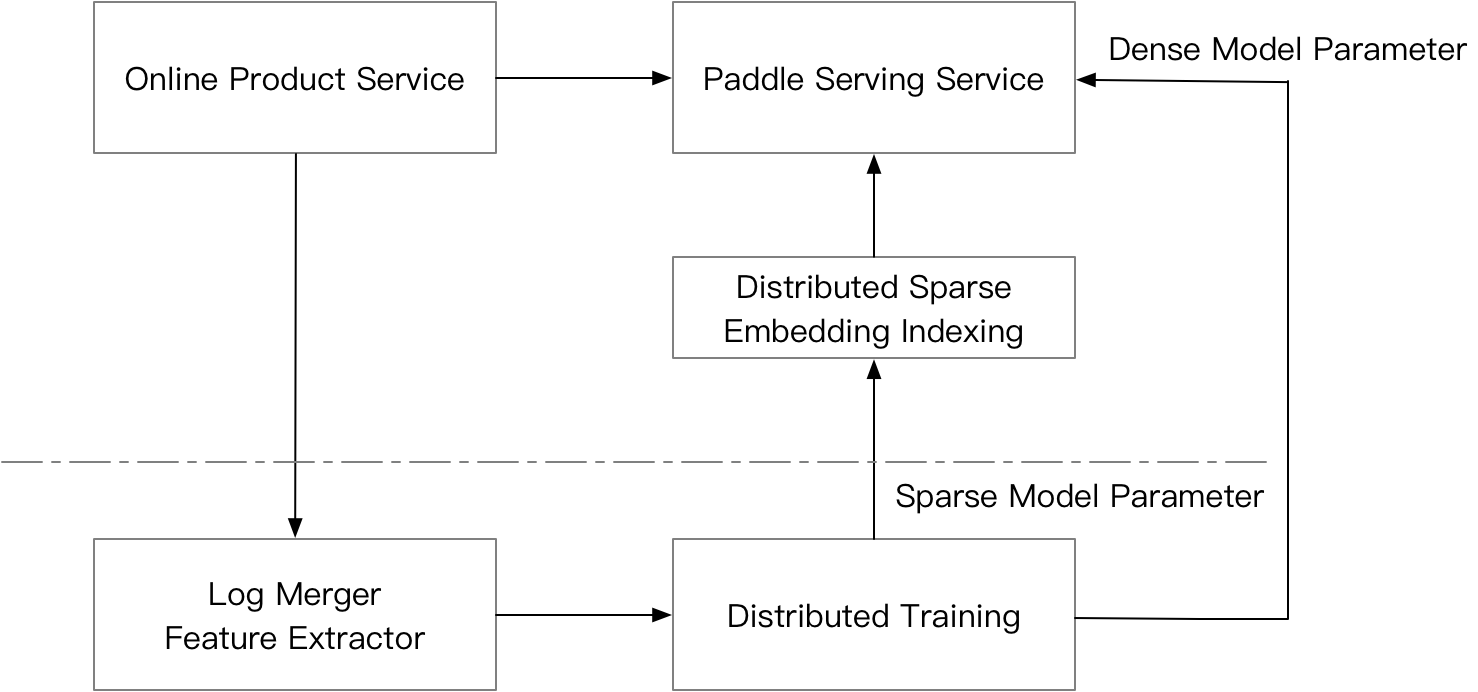
72.2 KB
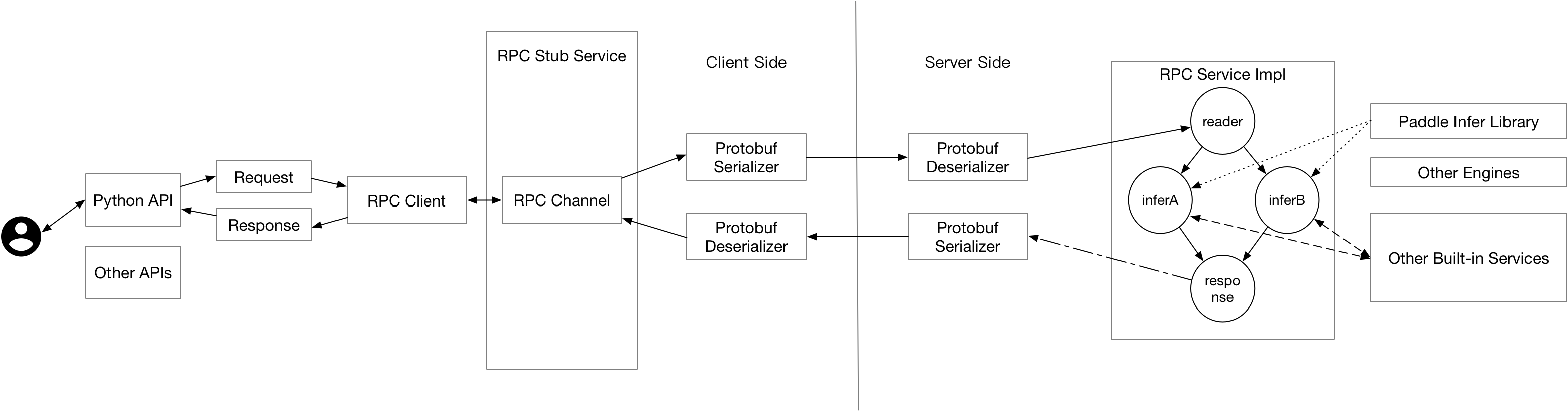
doc/design_doc.png
0 → 100644
{kind=link}
182.3 KB
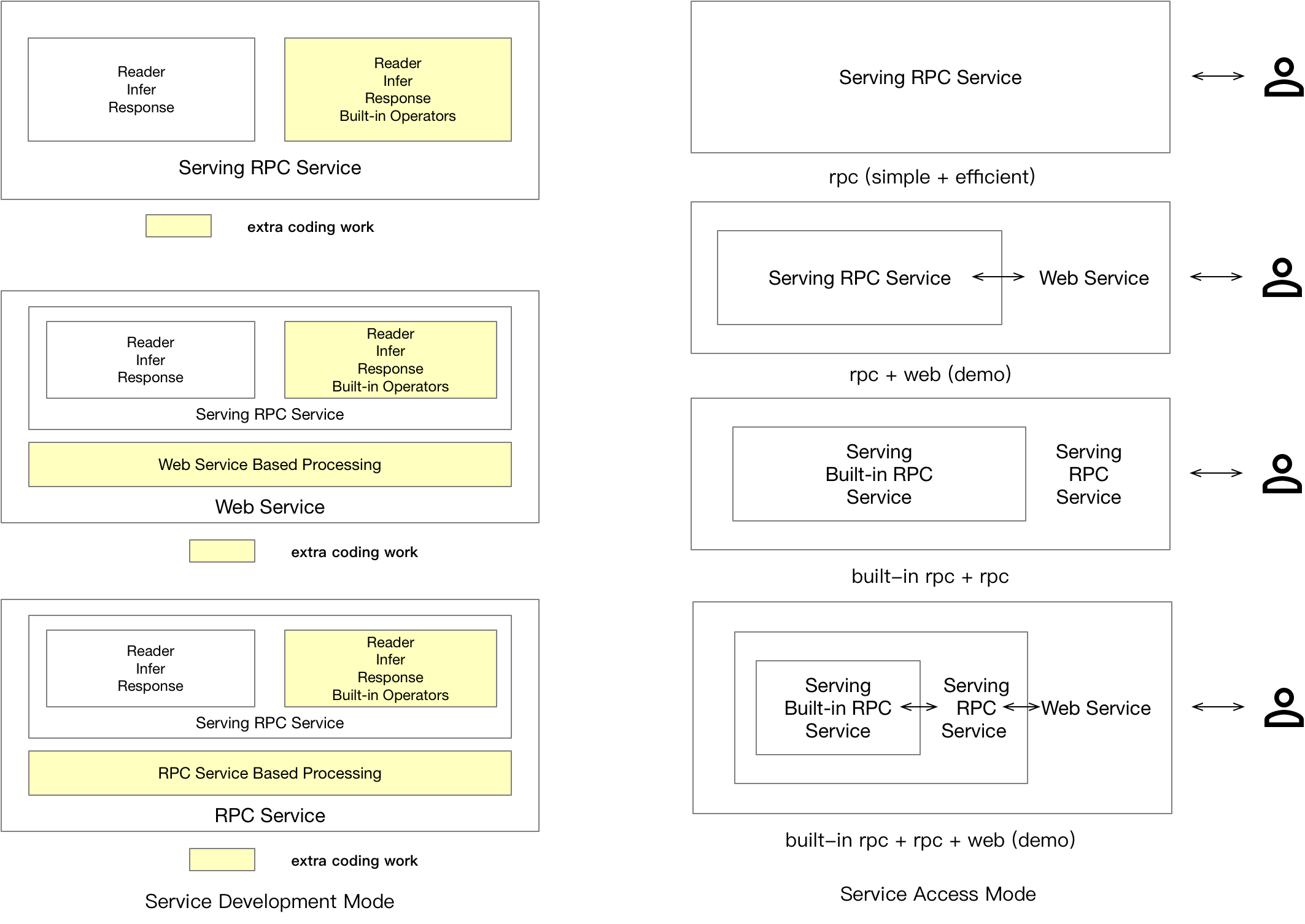
doc/user_groups.png
0 → 100644
{kind=link}
265.4 KB
tools/Dockerfile.gpu.devel
0 → 100644