Merge pull request #5 from PaddlePaddle/develop
merge
Showing
{kind=link}
23.7 KB
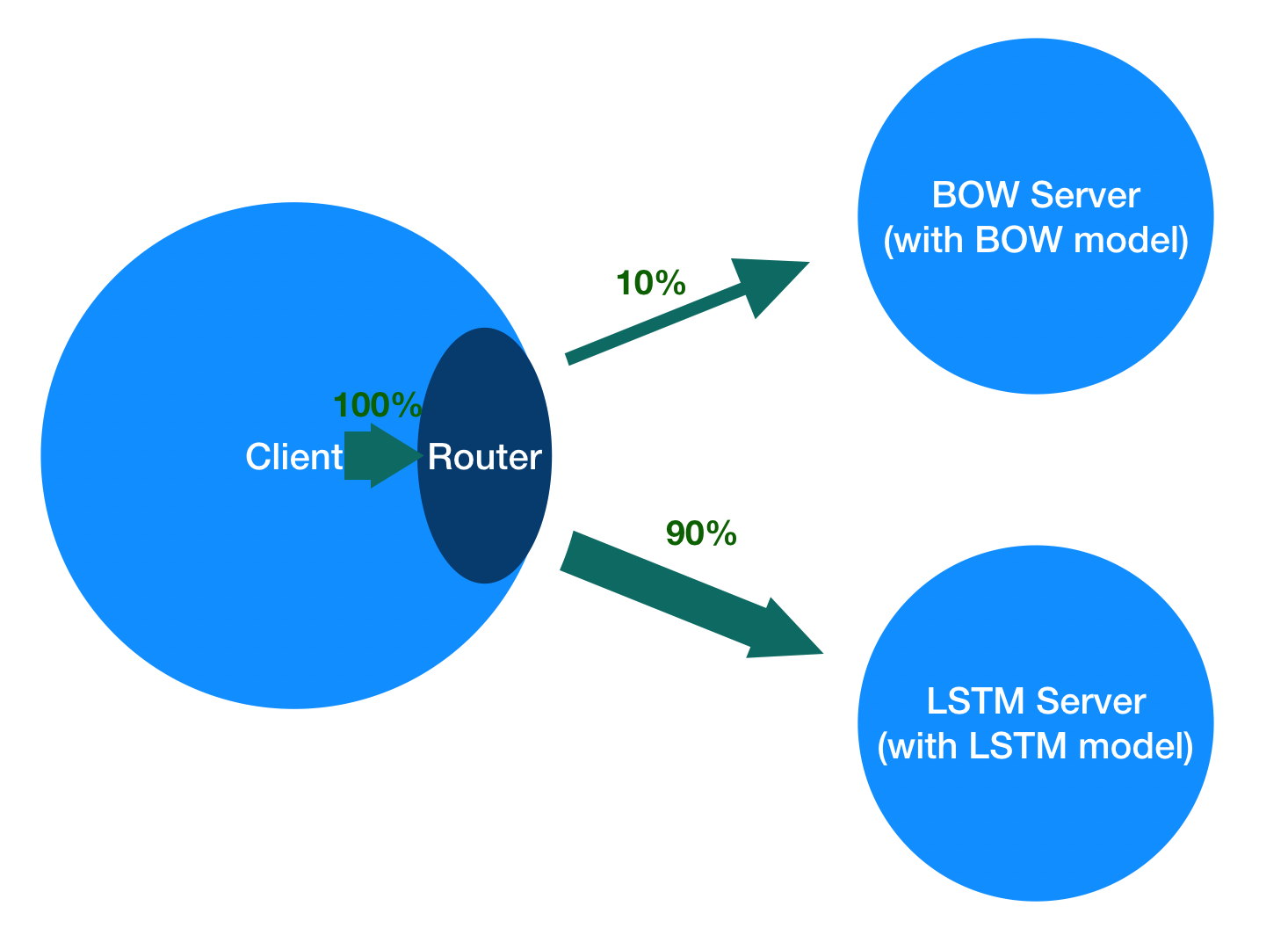
doc/ABTEST_IN_PADDLE_SERVING.md
0 → 100644
doc/BERT_10_MINS.md
0 → 100644
doc/BERT_10_MINS_CN.md
0 → 100644
doc/COMPILE_CN.md
0 → 100644
doc/CUBE_QUANT.md
0 → 100644
doc/CUBE_QUANT_CN.md
0 → 100644
doc/DESIGN_CN.md
0 → 100644
此差异已折叠。
doc/DESIGN_DOC_CN.md
0 → 100644
doc/DESIGN_DOC_EN.md
已删除
100644 → 0
doc/DOCKER_CN.md
0 → 100644
doc/IMDB_GO_CLIENT_CN.md
0 → 100644
doc/INSTALL.md
已删除
100644 → 0
doc/NEW_OPERATOR_CN.md
0 → 100644
doc/README.md
0 → 100644
doc/SAVE_CN.md
0 → 100644
doc/SERVER_DAG_CN.md
0 → 100644
doc/TRAIN_TO_SERVICE.md
0 → 100644
doc/TRAIN_TO_SERVICE_CN.md
0 → 100644
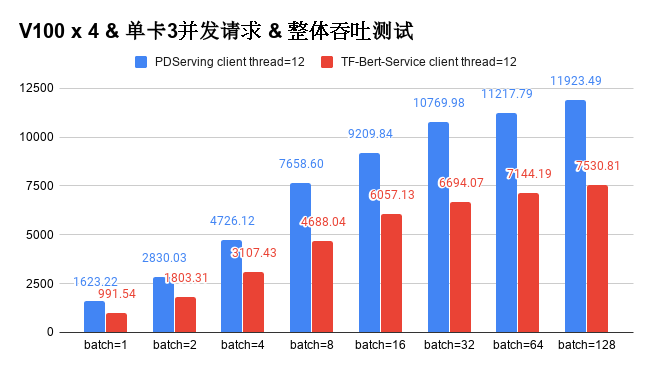
doc/abtest.png
0 → 100644
{kind=link}
291.5 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
文件已移动
doc/doc_test_list
0 → 100644
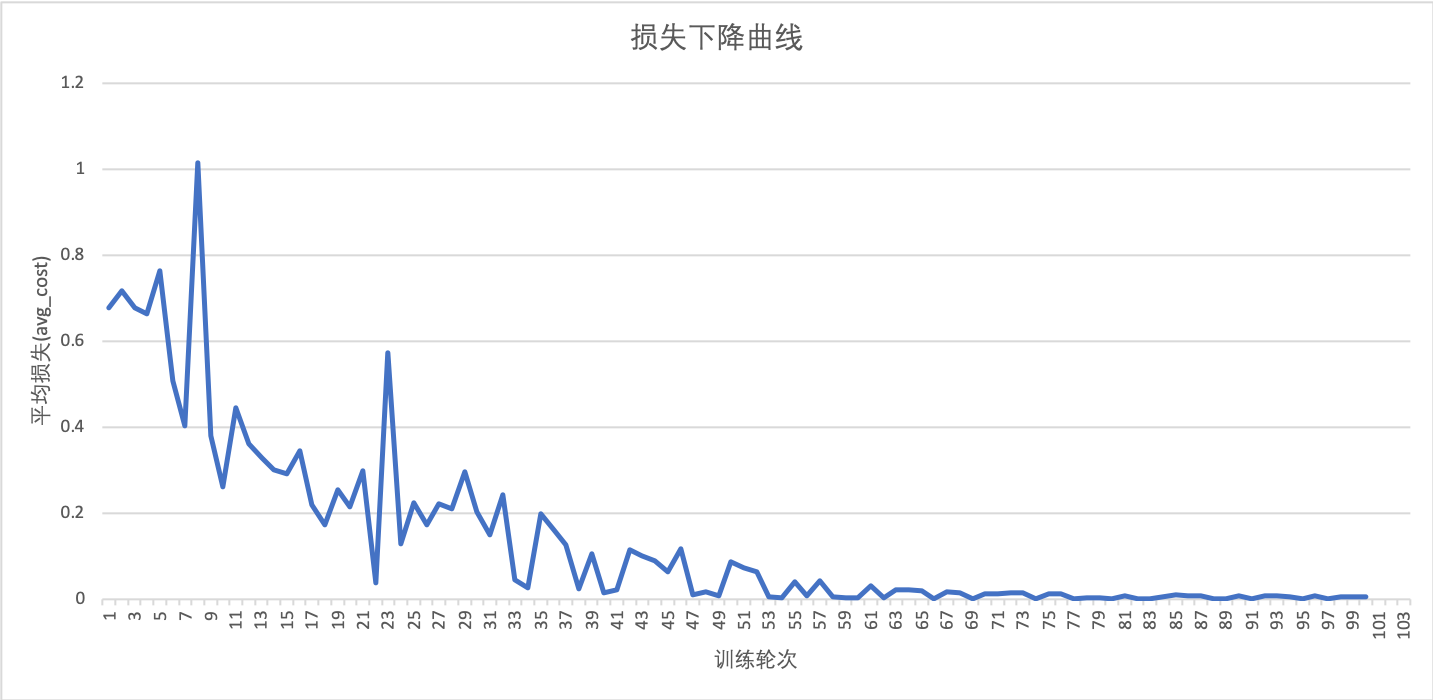
doc/imdb_loss.png
0 → 100644
{kind=link}
81.2 KB
doc/timeline-example.png
0 → 100644
{kind=link}

272.3 KB
python/examples/bert/README_CN.md
0 → 100644
此差异已折叠。
python/examples/imdb/README_CN.md
0 → 100644
此差异已折叠。
python/examples/lac/README.md
0 → 100644
此差异已折叠。
python/examples/lac/README_CN.md
0 → 100644
此差异已折叠。
python/examples/util/README_CN.md
0 → 100644
此差异已折叠。
此差异已折叠。
python/setup.py.app.in
0 → 100644
此差异已折叠。
tools/doc_test.sh
0 → 100644
此差异已折叠。
tools/doc_tester_reader.py
0 → 100644
此差异已折叠。