Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
001c93c0
S
Serving
项目概览
PaddlePaddle
/
Serving
大约 2 年 前同步成功
通知
187
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
001c93c0
编写于
3月 23, 2020
作者:
M
MRXLT
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update TRAIN_TO_SERVICE.md
上级
19c7a1f8
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
16 addition
and
7 deletion
+16
-7
doc/TRAIN_TO_SERVICE.md
doc/TRAIN_TO_SERVICE.md
+16
-7
doc/imdb_loss.png
doc/imdb_loss.png
+0
-0
未找到文件。
doc/TRAIN_TO_SERVICE.md
浏览文件 @
001c93c0
...
@@ -34,7 +34,7 @@ saw a trailer for this on another video, and decided to rent when it came out. b
...
@@ -34,7 +34,7 @@ saw a trailer for this on another video, and decided to rent when it came out. b
<details>
<details>
<summary>
imdb_reader.py
</summary>
<summary>
imdb_reader.py
</summary>
```
python
```
python
import
sys
import
sys
import
os
import
os
...
@@ -200,12 +200,12 @@ if __name__ == "__main__":
...
@@ -200,12 +200,12 @@ if __name__ == "__main__":
dataset
.
set_use_var
([
data
,
label
])
dataset
.
set_use_var
([
data
,
label
])
pipe_command
=
"python imdb_reader.py"
pipe_command
=
"python imdb_reader.py"
dataset
.
set_pipe_command
(
pipe_command
)
dataset
.
set_pipe_command
(
pipe_command
)
dataset
.
set_batch_size
(
128
)
dataset
.
set_batch_size
(
4
)
dataset
.
set_filelist
(
filelist
)
dataset
.
set_filelist
(
filelist
)
dataset
.
set_thread
(
10
)
dataset
.
set_thread
(
10
)
#定义模型
#定义模型
avg_cost
,
acc
,
prediction
=
cnn_net
(
data
,
label
,
dict_dim
)
avg_cost
,
acc
,
prediction
=
cnn_net
(
data
,
label
,
dict_dim
)
optimizer
=
fluid
.
optimizer
.
SGD
(
learning_rate
=
0.01
)
optimizer
=
fluid
.
optimizer
.
SGD
(
learning_rate
=
0.0
0
1
)
optimizer
.
minimize
(
avg_cost
)
optimizer
.
minimize
(
avg_cost
)
#执行训练
#执行训练
exe
=
fluid
.
Executor
(
fluid
.
CPUPlace
())
exe
=
fluid
.
Executor
(
fluid
.
CPUPlace
())
...
@@ -218,7 +218,7 @@ if __name__ == "__main__":
...
@@ -218,7 +218,7 @@ if __name__ == "__main__":
exe
.
train_from_dataset
(
exe
.
train_from_dataset
(
program
=
fluid
.
default_main_program
(),
dataset
=
dataset
,
debug
=
False
)
program
=
fluid
.
default_main_program
(),
dataset
=
dataset
,
debug
=
False
)
logger
.
info
(
"TRAIN --> pass: {}"
.
format
(
i
))
logger
.
info
(
"TRAIN --> pass: {}"
.
format
(
i
))
if
i
==
99
:
if
i
==
64
:
#在训练结束时使用PaddleServing中的模型保存接口保存出Serving所需的模型和配置文件
#在训练结束时使用PaddleServing中的模型保存接口保存出Serving所需的模型和配置文件
serving_io
.
save_model
(
"{}_model"
.
format
(
model_name
),
serving_io
.
save_model
(
"{}_model"
.
format
(
model_name
),
"{}_client_conf"
.
format
(
model_name
),
"{}_client_conf"
.
format
(
model_name
),
...
@@ -228,8 +228,9 @@ if __name__ == "__main__":
...
@@ -228,8 +228,9 @@ if __name__ == "__main__":
</details>
</details>
执行loca_train.py脚本会进行训练并在训练结束时
保存模型和配置文件。保存的文件分为imdb_cnn_client_conf和imdb_cnn_model文件夹,前者包含client端的配置文件,后者包含server端的配置文件和保存的模型文件。

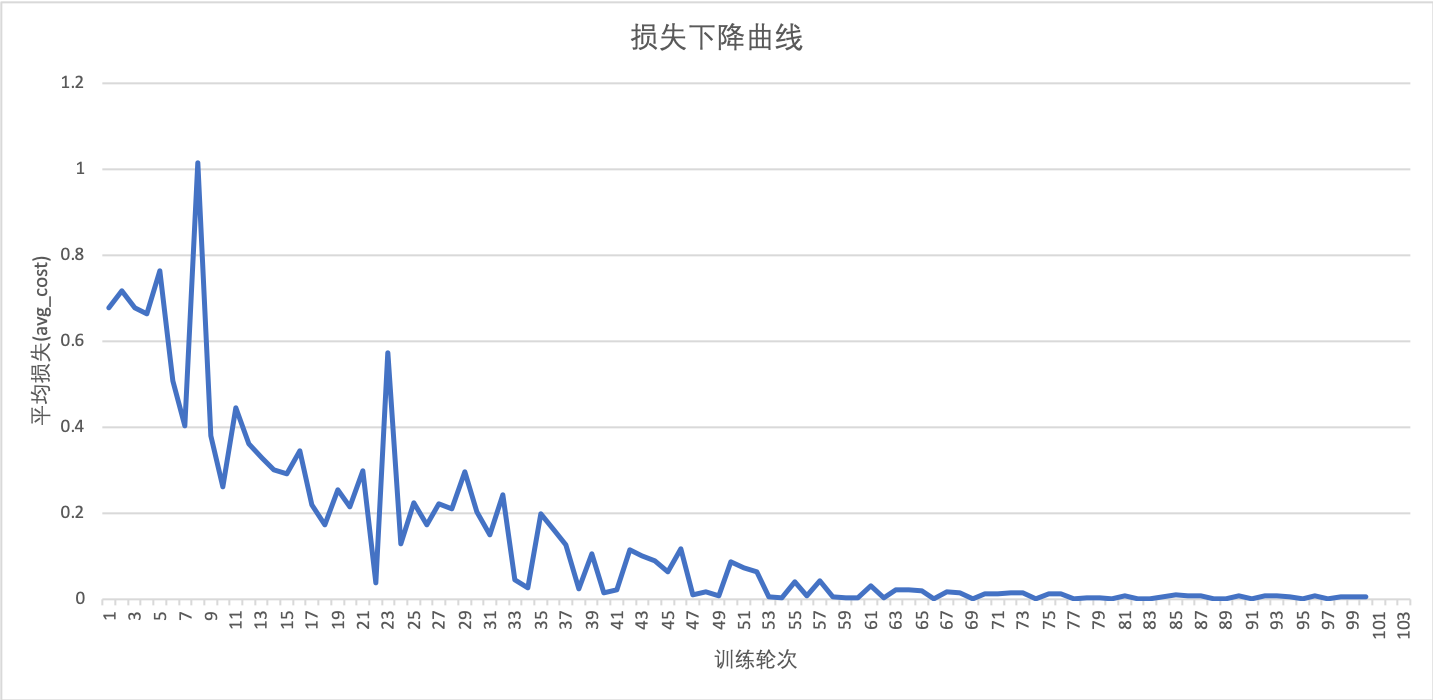
由上图可以看出模型的损失在第65轮之后开始收敛,我们在第65轮训练完成后
保存模型和配置文件。保存的文件分为imdb_cnn_client_conf和imdb_cnn_model文件夹,前者包含client端的配置文件,后者包含server端的配置文件和保存的模型文件。
save_model函数的参数列表如下:
save_model函数的参数列表如下:
| 参数 | 含义 |
| 参数 | 含义 |
| -------------------- | ------------------------------------------------------------ |
| -------------------- | ------------------------------------------------------------ |
| server_model_folder | 保存server端配置文件和模型文件的目录 |
| server_model_folder | 保存server端配置文件和模型文件的目录 |
...
@@ -290,7 +291,9 @@ for line in sys.stdin:
...
@@ -290,7 +291,9 @@ for line in sys.stdin:
cat
test_data/part-0 | python test_client.py imdb_lstm_client_conf/serving_client_conf.prototxt imdb.vocab
cat
test_data/part-0 | python test_client.py imdb_lstm_client_conf/serving_client_conf.prototxt imdb.vocab
```
```
使用test_data/part-0文件中的2084个样本进行测试测试,模型预测的准确率为86.90%,。
使用test_data/part-0文件中的2084个样本进行测试测试,模型预测的准确率为88.19%。
**注意**
:每次模型训练的效果可能略有不同,使用训练出的模型预测的准确率会与示例中接近但有可能不完全一致。
## Step8:部署HTTP预测服务
## Step8:部署HTTP预测服务
...
@@ -350,4 +353,10 @@ python text_classify_service.py imdb_cnn_model/ workdir/ 9292 imdb.vocab
...
@@ -350,4 +353,10 @@ python text_classify_service.py imdb_cnn_model/ workdir/ 9292 imdb.vocab
```
```
curl -H "Content-Type:application/json" -X POST -d '{"words": "i am very sad | 0", "fetch":["prediction"]}' http://127.0.0.1:9292/imdb/prediction
curl -H "Content-Type:application/json" -X POST -d '{"words": "i am very sad | 0", "fetch":["prediction"]}' http://127.0.0.1:9292/imdb/prediction
```
```
预测流程正常时,会返回预测概率。
预测流程正常时,会返回预测概率,示例如下。
```
{"prediction":[0.5592559576034546,0.44074398279190063]}
```
**注意**
:每次模型训练的效果可能略有不同,使用训练出的模型预测概率数值可能与示例不一致。
doc/imdb_loss.png
0 → 100644
浏览文件 @
001c93c0
81.2 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}