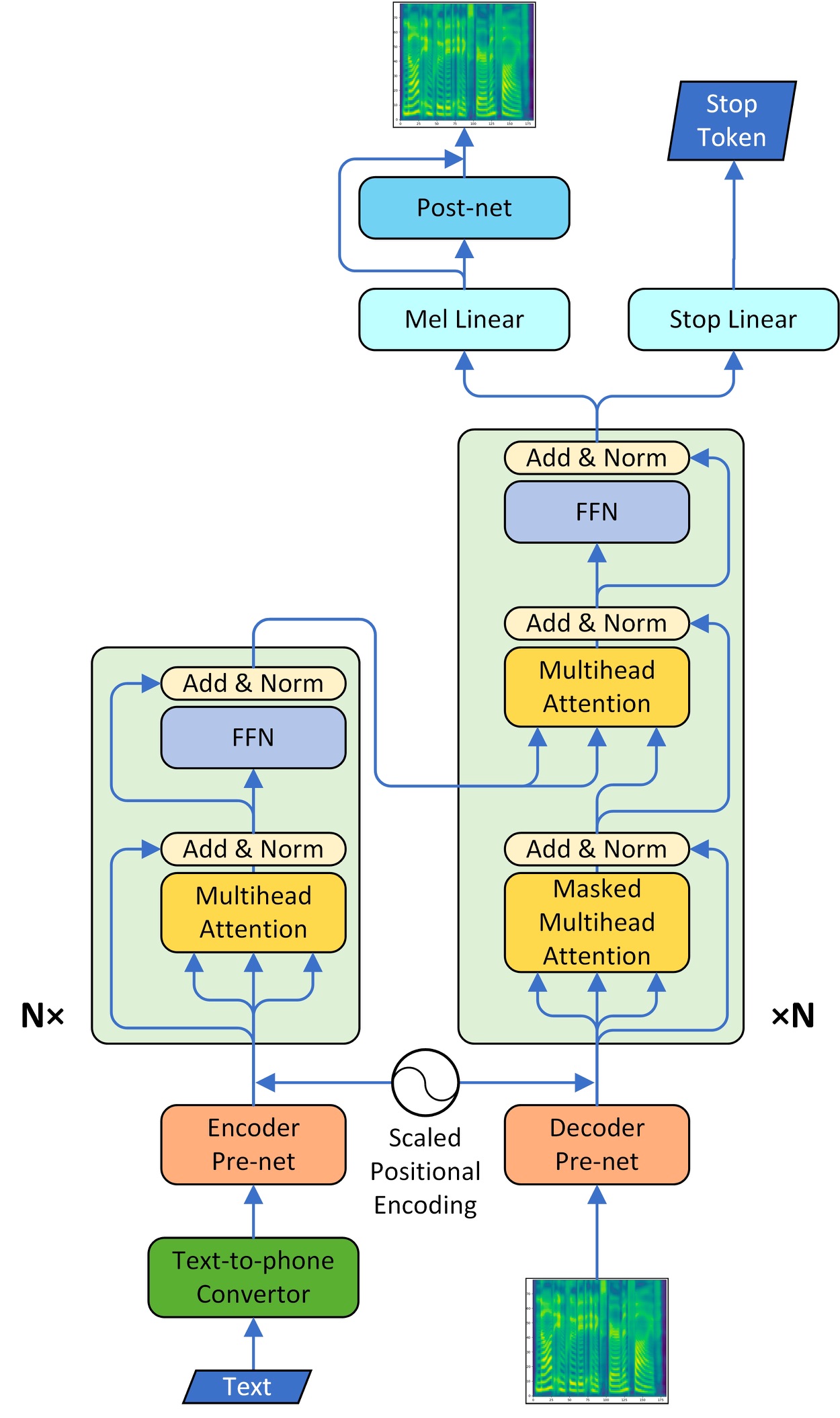
Paddle fluid implementation of TransformerTTS, a neural TTS with Transformer. The implementation is based on [Neural Speech Synthesis with Transformer Network](https://arxiv.org/abs/1809.08895).
We implement TransformerTTS model in paddle fluid with dynamic graph, which is convenient for flexible network architectures.
\ No newline at end of file
We implement TransformerTTS model in paddle fluid with dynamic graph, which is convenient for flexible network architectures.
## Installation
### Install paddlepaddle
This implementation requires the latest develop version of paddlepaddle. You can either download the compiled package or build paddle from source.
1. Install the compiled package, via pip, conda or docker. See [**Installation Mannuals**](https://www.paddlepaddle.org.cn/documentation/docs/en/beginners_guide/install/index_en.html) for more details.
2. Build paddlepaddle from source. See [**Compile From Source Code**](https://www.paddlepaddle.org.cn/documentation/docs/en/beginners_guide/install/compile/fromsource_en.html) for more details. Note that if you want to enable data parallel training for multiple GPUs, you should set `-DWITH_DISTRIBUTE=ON` with cmake.
### Install parakeet
You can choose to install via pypi or clone the repository and install manually.
1. Install via pypi.
```bash
pip install parakeet
```
2. Install manually.
```bash
git clone <url>
cd Parakeet/
pip install-e.
### Download cmudict for nltk
You also need to download cmudict for nltk, because convert text into phonemes with `cmudict`.
```python
import nltk
nltk.download("punkt")
nltk.download("cmudict")
```
If you have completed all the above installations, but still report an error at runtime:
``` OSError: sndfile library not found ```
You need to install ```libsndfile``` using your distribution’s package manager. e.g. install via:
``` sudo apt-get install libsndfile1 ```
## Dataset
We experiment with the LJSpeech dataset. Download and unzip [LJSpeech](https://keithito.com/LJ-Speech-Dataset/).

The model adapt the multi-head attention mechanism to replace the RNN structures and also the original attention mechanism in [Tacotron2](https://arxiv.org/abs/1712.05884). The model consists of two main parts, encoder and decoder. We also implemented CBHG model of tacotron as a vocoder part and converted the spectrogram into raw wave using griffin-lim algorithm.
## Project Structure
```text
├── config # yaml configuration files
├── data.py # dataset and dataloader settings for LJSpeech
├── synthesis.py # script to synthesize waveform from text
├── train_transformer.py # script for transformer model training
├── train_vocoder.py # script for vocoder model training
```
## Train Transformer
TransformerTTS model can train with ``train_transformer.py``.
```bash
python train_trasformer.py \
--use_gpu=1 \
--use_data_parallel=0 \
--data_path=${DATAPATH} \
--config_path='config/train_transformer.yaml' \
```
or you can run the script file directly.
```bash
sh train_transformer.sh
```
If you want to train on multiple GPUs, you must set ``--use_data_parallel=1``, and then start training as follow:
{kind=link}