fix the conflict
Showing
%20BDSZYF000132754-docs%20jiangjiajun$%20pwd%20:Users:jiangjiajun:Downloads:PaddleX-develop:docs:vdl1.png){kind=link}
%20BDSZYF000132754-docs%20jiangjiajun$%20pwd%20:Users:jiangjiajun:Downloads:PaddleX-develop:docs:vdl1.png)
210 字节
%20BDSZYF000132754-docs%20jiangjiajun$%20pwd%20:Users:jiangjiajun:Downloads:PaddleX-develop:docs:vdl1.png){kind=link}
%20BDSZYF000132754-docs%20jiangjiajun$%20pwd%20:Users:jiangjiajun:Downloads:PaddleX-develop:docs:vdl1.png)
43.5 KB
docs/paddlex_gui/images/QR.jpg
0 → 100644
{kind=link}
56.3 KB
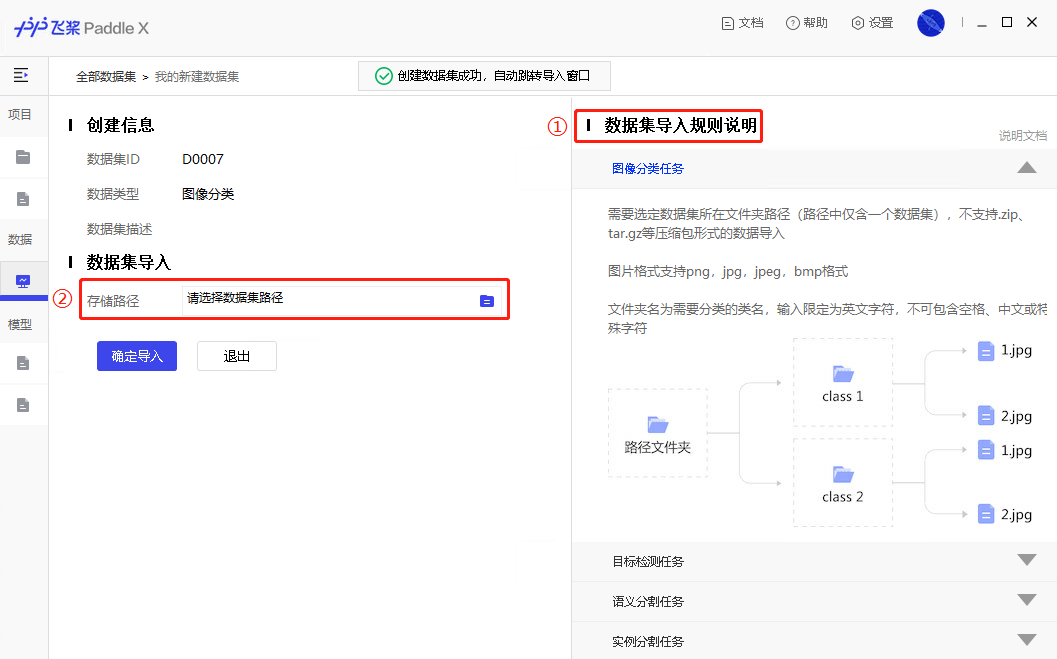
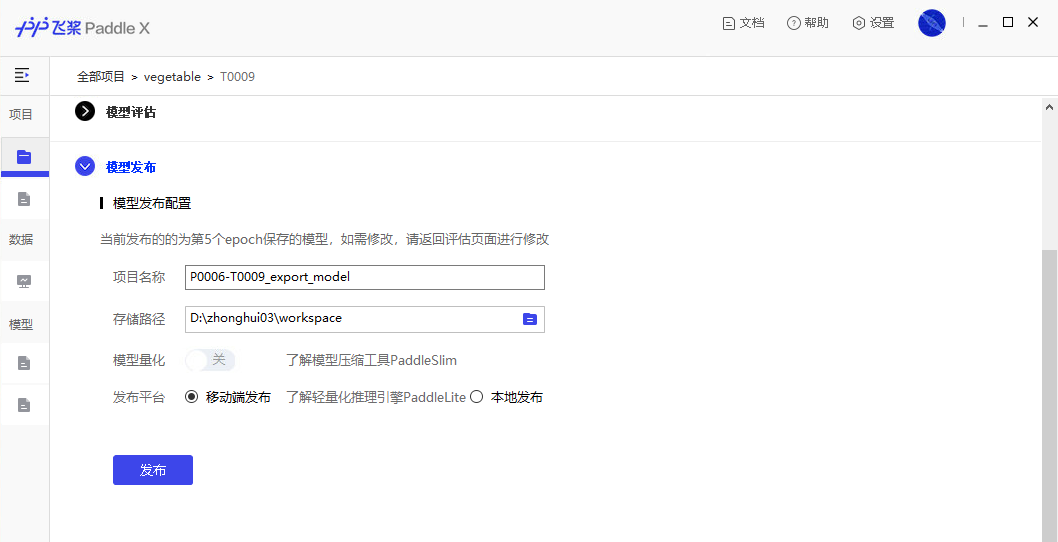
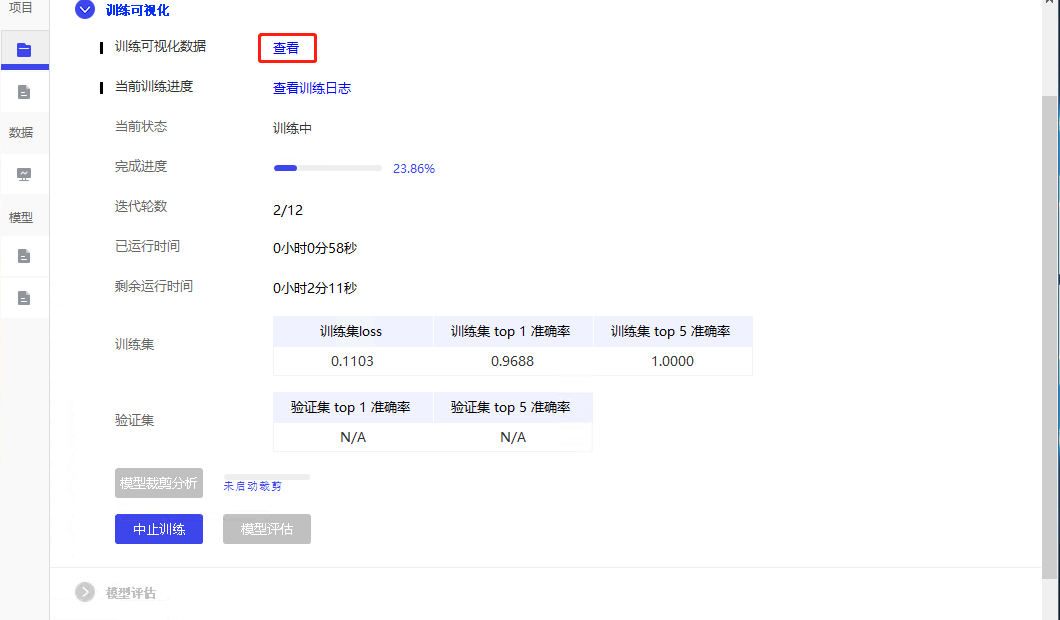
docs/paddlex_gui/images/ReadMe
0 → 100644
{kind=link}

258.2 KB
{kind=link}
73.3 KB
{kind=link}

37.0 KB
{kind=link}

54.0 KB
{kind=link}

102.4 KB
{kind=link}
41.3 KB
{kind=link}
38.5 KB
{kind=link}
34.0 KB
{kind=link}
36.4 KB
{kind=link}
54.7 KB
{kind=link}
47.3 KB
new_tutorials/train/README.md
0 → 100644