Merge pull request #18 from Channingss/develop
add cpp deploy module&docs
Showing
deploy/cpp/.clang-format
0 → 100644
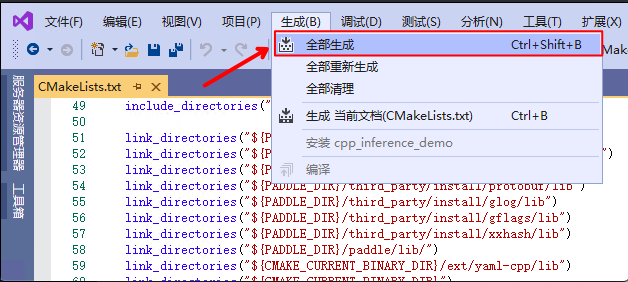
deploy/cpp/CMakeLists.txt
0 → 100644
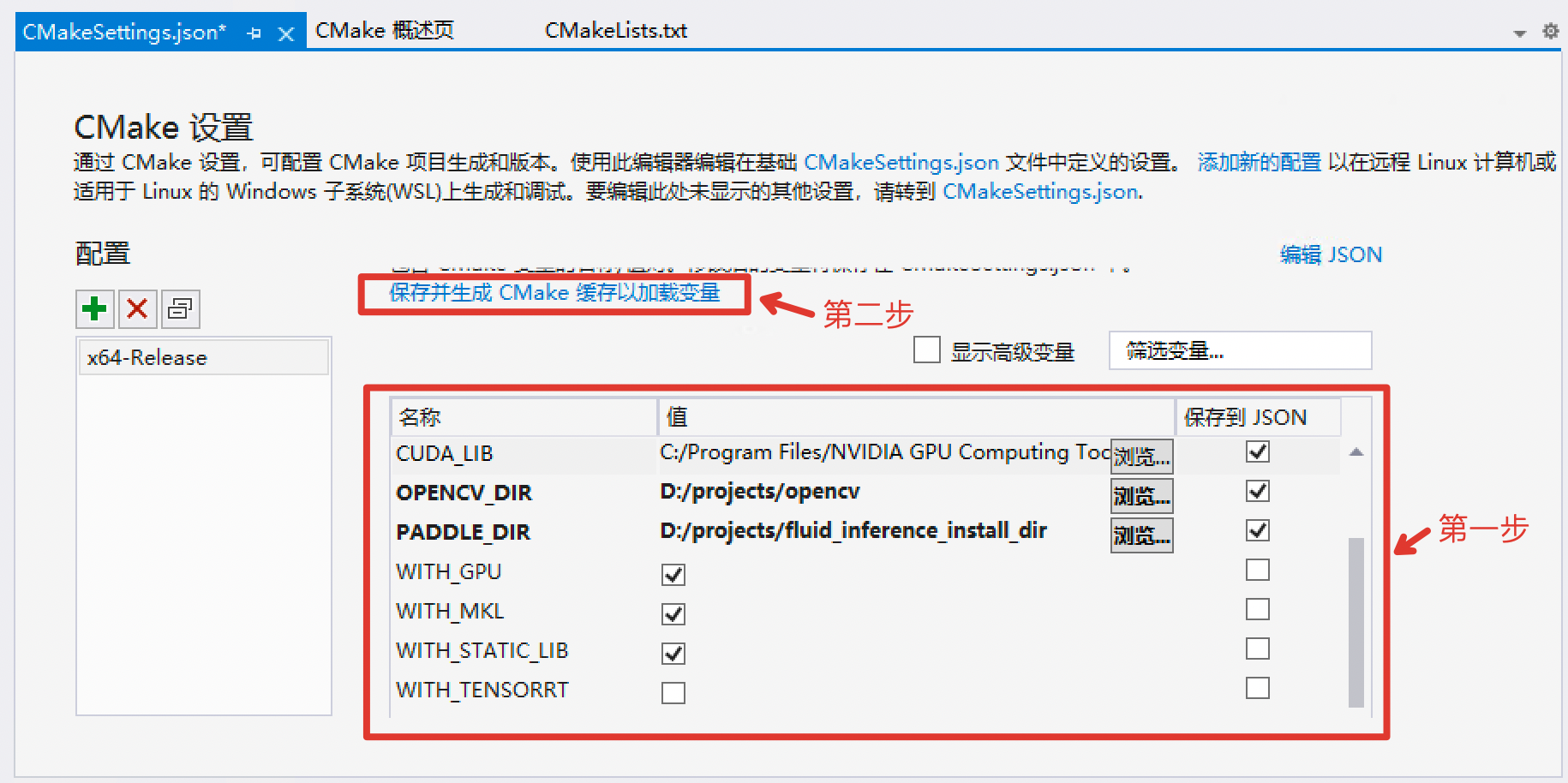
deploy/cpp/CMakeSettings.json
0 → 100644
deploy/cpp/cmake/yaml-cpp.cmake
0 → 100644
deploy/cpp/scripts/bootstrap.sh
0 → 100644
deploy/cpp/scripts/build.sh
0 → 100644
deploy/cpp/src/classifier.cpp
0 → 100644
deploy/cpp/src/detector.cpp
0 → 100644
deploy/cpp/src/paddlex.cpp
0 → 100644
deploy/cpp/src/segmenter.cpp
0 → 100644
deploy/cpp/src/transforms.cpp
0 → 100644
deploy/cpp/src/visualize.cpp
0 → 100644
docs/deploy.md
已删除
100644 → 0
docs/deploy/deploy.md
0 → 100644
docs/deploy/deploy_cpp_linux.md
0 → 100644
{kind=link}
75.3 KB
{kind=link}
84.3 KB
{kind=link}
381.3 KB
{kind=link}
396.6 KB
{kind=link}
427.5 KB
{kind=link}
83.3 KB