dataannotation
Showing
{kind=link}

20.0 KB
{kind=link}

27.1 KB
文件已添加
文件已添加
文件已添加
{kind=link}

2.6 KB
{kind=link}

3.5 KB
{kind=link}

2.8 KB
{kind=link}

25.6 KB
{kind=link}

19.3 KB
{kind=link}

26.9 KB
{kind=link}

20.4 KB
{kind=link}

193.5 KB
{kind=link}

26.4 KB
{kind=link}

144.0 KB
{kind=link}

106.1 KB
{kind=link}

133.8 KB
{kind=link}

45.4 KB
{kind=link}

28.6 KB
{kind=link}

43.9 KB
文件已添加
文件已添加
文件已添加
{kind=link}

3.1 KB
{kind=link}

3.6 KB
{kind=link}

2.6 KB
{kind=link}

27.0 KB
{kind=link}

21.6 KB
{kind=link}

28.4 KB
{kind=link}
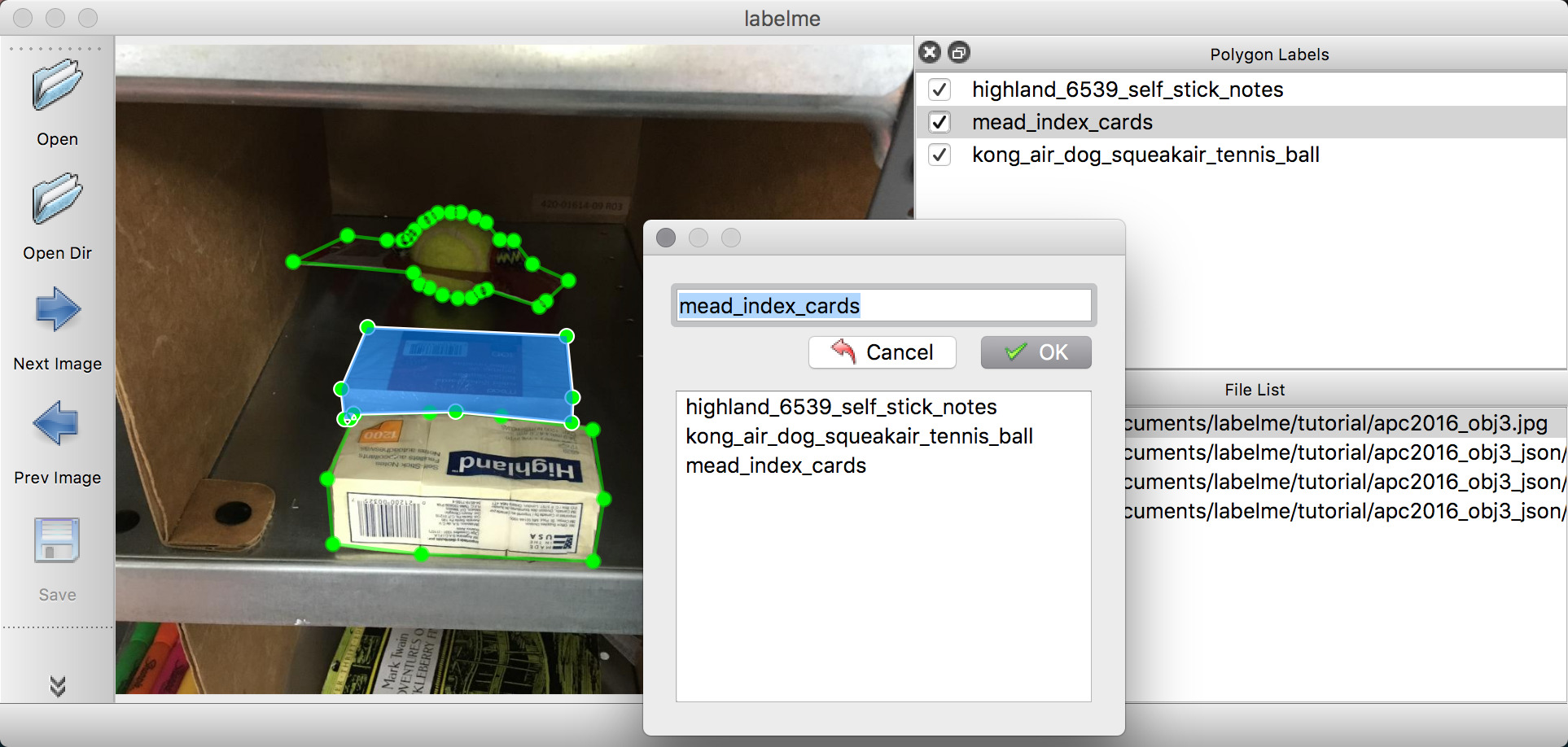
367.4 KB
{kind=link}

120.1 KB
{kind=link}

43.1 KB
{kind=link}

103.6 KB
此差异已折叠。
{kind=link}

851.9 KB
{kind=link}

8.4 KB
{kind=link}

575.7 KB
{kind=link}

376.7 KB
{kind=link}

372.4 KB
{kind=link}

1.4 MB
{kind=link}

125.1 KB
{kind=link}

125.1 KB
{kind=link}

125.1 KB
{kind=link}

124.7 KB
{kind=link}

124.2 KB
{kind=link}

126.1 KB
{kind=link}

126.1 KB
{kind=link}

126.1 KB
{kind=link}

125.7 KB
{kind=link}

125.1 KB
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
{kind=link}

3.2 KB
{kind=link}

3.2 KB
{kind=link}

3.2 KB
{kind=link}

3.2 KB
{kind=link}

3.2 KB
{kind=link}

85.7 KB
{kind=link}

85.7 KB
{kind=link}

85.7 KB
{kind=link}

85.5 KB
{kind=link}

85.3 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。