remove docs
Showing
docs/Makefile
已删除
100755 → 0
docs/README.md
已删除
100644 → 0
docs/_templates/layout.html
已删除
100644 → 0
docs/apis/datasets.md
已删除
100644 → 0
.png){kind=link}
.png)
708.9 KB
docs/apis/index.rst
已删除
100755 → 0
docs/apis/interpret.md
已删除
100644 → 0
docs/apis/load_model.md
已删除
100755 → 0
docs/apis/models/detection.md
已删除
100755 → 0
docs/apis/models/index.rst
已删除
100755 → 0
docs/apis/slim.md
已删除
100755 → 0
docs/apis/visualize.md
已删除
100755 → 0
{kind=link}
74.6 KB
{kind=link}

80.4 KB
{kind=link}

94.6 KB
{kind=link}
263.2 KB
{kind=link}

165.5 KB
docs/appendix/images/lime.png
已删除
100644 → 0
{kind=link}

423.0 KB
{kind=link}
288.0 KB
{kind=link}

197.1 KB
{kind=link}

277.0 KB
{kind=link}

84.1 KB
{kind=link}

85.5 KB
{kind=link}

37.7 KB
{kind=link}

111.4 KB
docs/appendix/index.rst
已删除
100755 → 0
docs/appendix/interpret.md
已删除
100644 → 0
docs/appendix/metrics.md
已删除
100755 → 0
docs/appendix/model_zoo.md
已删除
100644 → 0
docs/appendix/parameters.md
已删除
100644 → 0
docs/change_log.md
已删除
100644 → 0
docs/conf.py
已删除
100755 → 0
docs/data/annotation.md
已删除
100755 → 0
docs/data/format/detection.md
已删除
100644 → 0
docs/data/format/index.rst
已删除
100755 → 0
docs/data/index.rst
已删除
100755 → 0
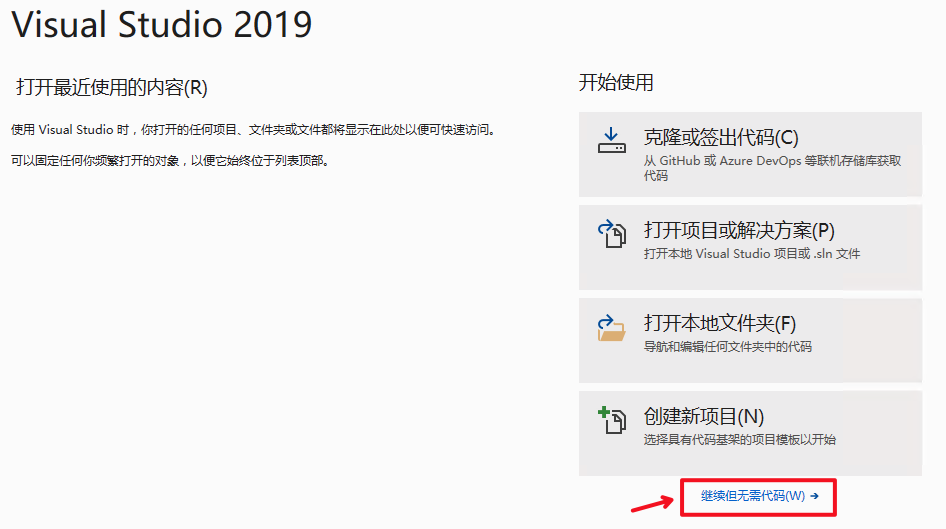
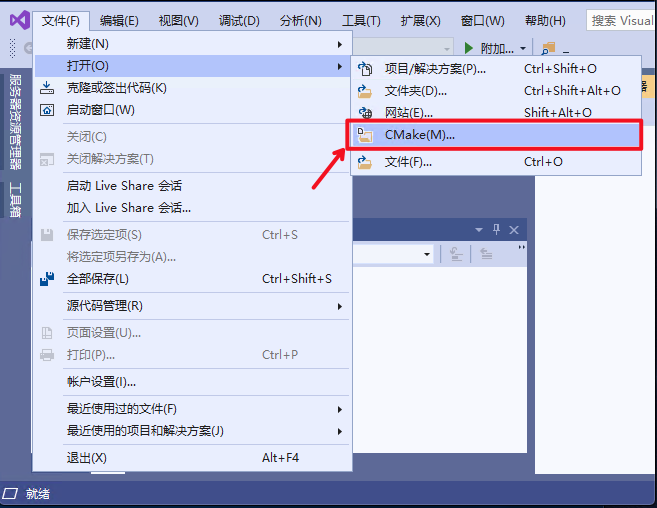
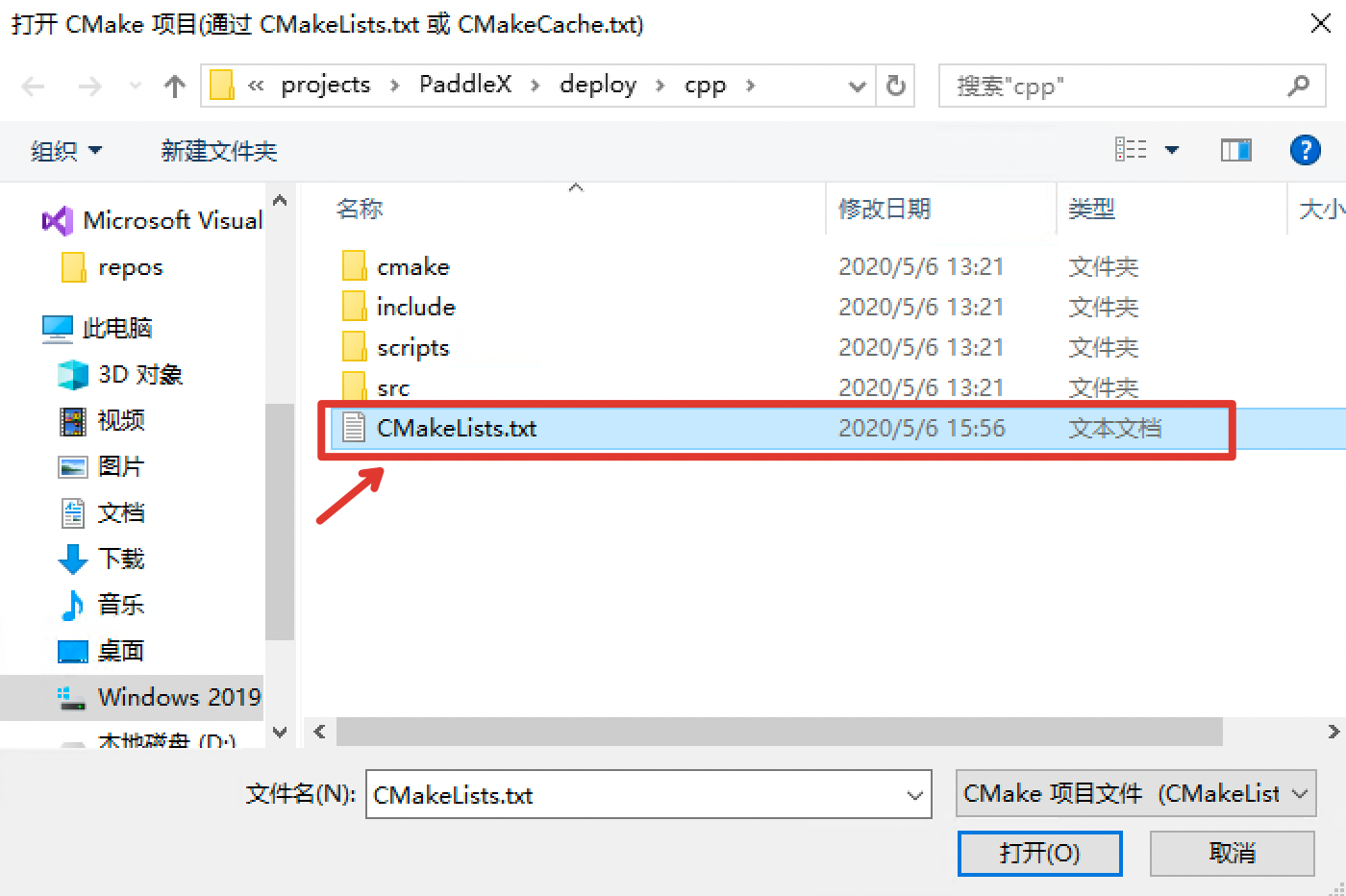
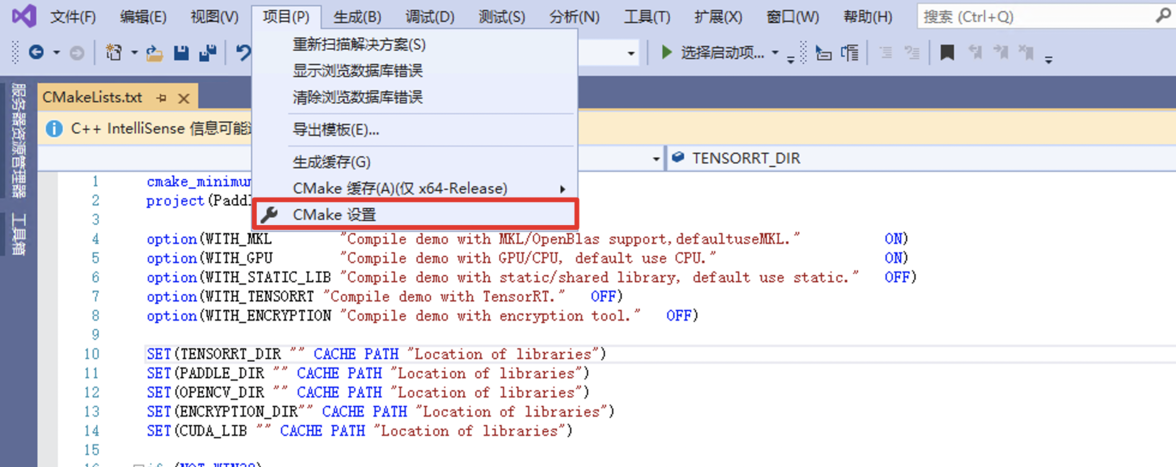
docs/deploy/export_model.md
已删除
100644 → 0
{kind=link}

46.0 KB
{kind=link}
113.7 KB
{kind=link}
75.3 KB
{kind=link}
84.3 KB
{kind=link}
381.3 KB
{kind=link}
294.1 KB
{kind=link}
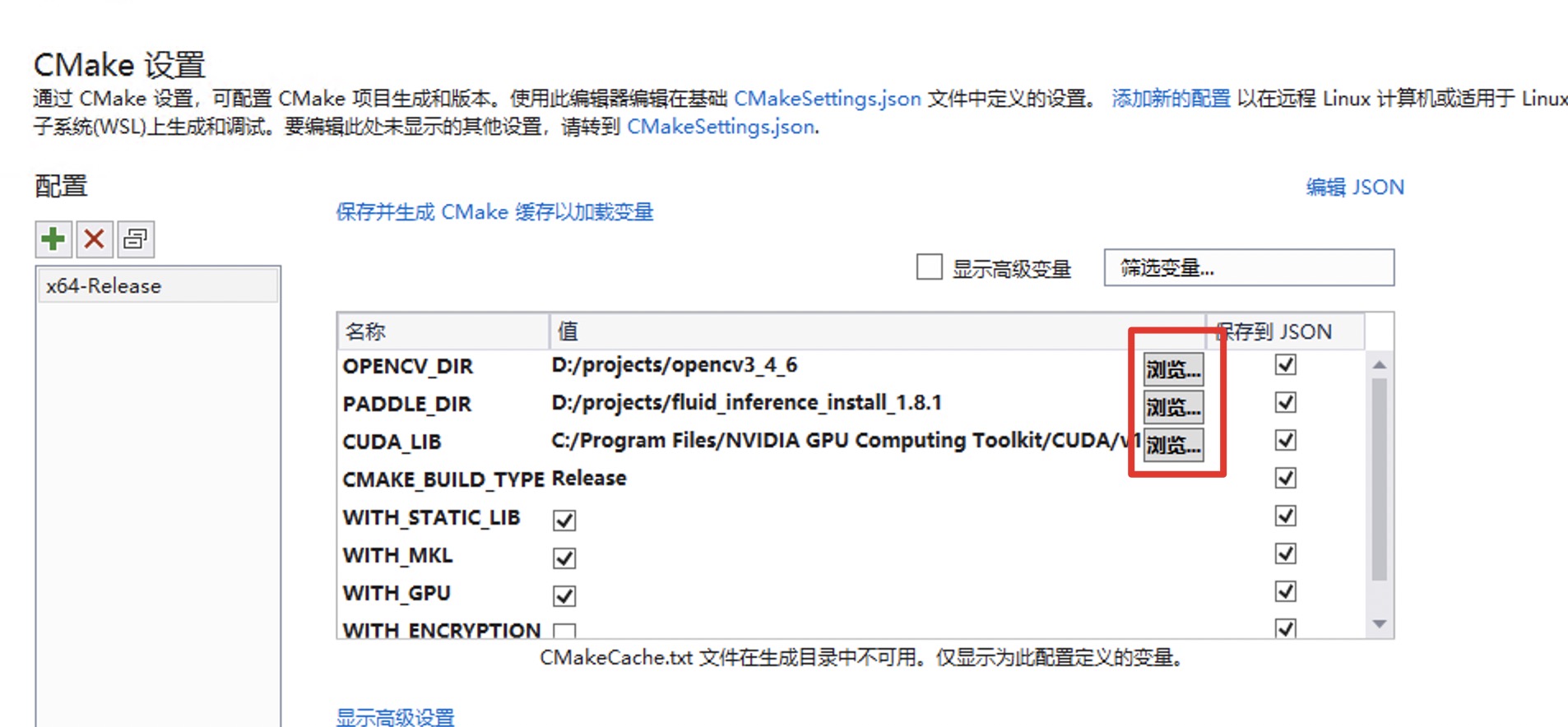
215.3 KB
{kind=link}
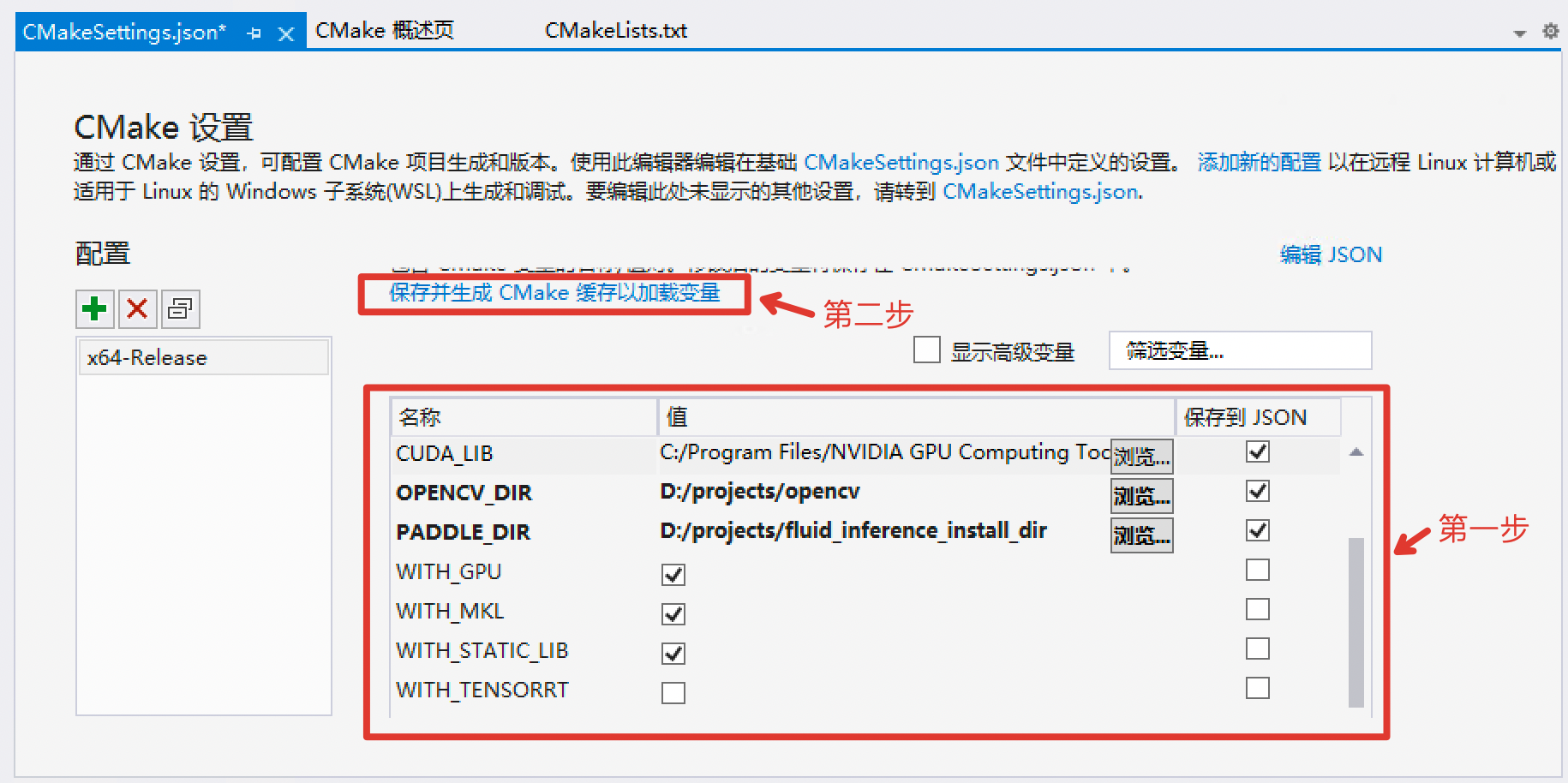
427.5 KB
{kind=link}
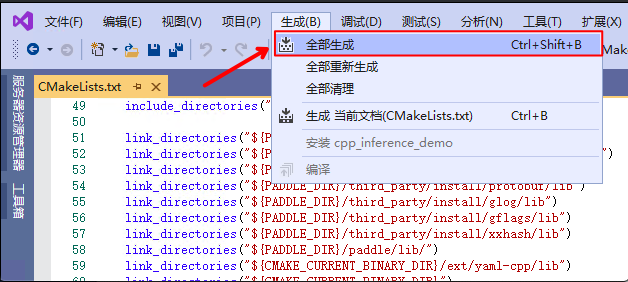
83.3 KB
{kind=link}
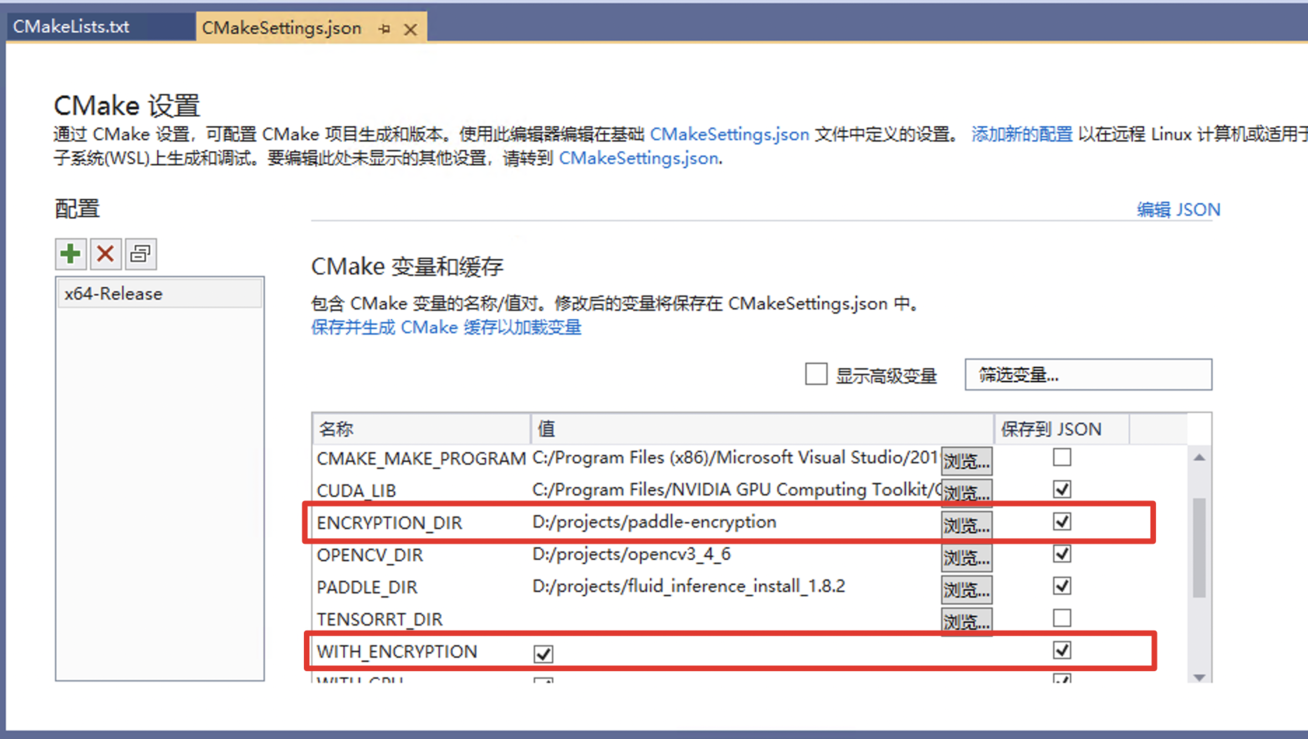
397.9 KB
docs/deploy/index.rst
已删除
100755 → 0
docs/deploy/nvidia-jetson.md
已删除
100644 → 0
docs/deploy/openvino/linux.md
已删除
100644 → 0
docs/deploy/server/index.rst
已删除
100755 → 0
docs/deploy/server/python.md
已删除
100644 → 0
docs/examples/index.rst
已删除
100755 → 0
docs/examples/solutions.md
已删除
100644 → 0
docs/gui/index.rst
已删除
100755 → 0
docs/index.rst
已删除
100755 → 0
docs/install.md
已删除
100755 → 0
docs/make.bat
已删除
100755 → 0
docs/paddlex.png
已删除
100644 → 0
{kind=link}

4.9 KB
docs/quick_start.md
已删除
100644 → 0
docs/requirements.txt
已删除
100755 → 0
docs/train/classification.md
已删除
100644 → 0
docs/train/index.rst
已删除
100755 → 0
docs/train/prediction.md
已删除
100644 → 0