revert_docs
Showing
docs/FAQ.md
0 → 100755
docs/README.md
0 → 100755
docs/apis/deploy.md
0 → 100755
docs/change_log.md
已删除
100644 → 0
docs/cv_solutions.md
0 → 100755
docs/data/format/detection.md
已删除
100644 → 0
docs/data/index.rst
已删除
100755 → 0
docs/datasets.md
0 → 100644
docs/deploy/index.rst
已删除
100755 → 0
docs/deploy/nvidia-jetson.md
已删除
100644 → 0
docs/deploy/openvino/linux.md
已删除
100644 → 0
docs/deploy/server/linux.md
已删除
100644 → 0
docs/deploy/server/windows.md
已删除
100644 → 0
docs/examples/index.rst
已删除
100755 → 0
docs/examples/solutions.md
已删除
100644 → 0
docs/images/00_loaddata.png
0 → 100755
{kind=link}
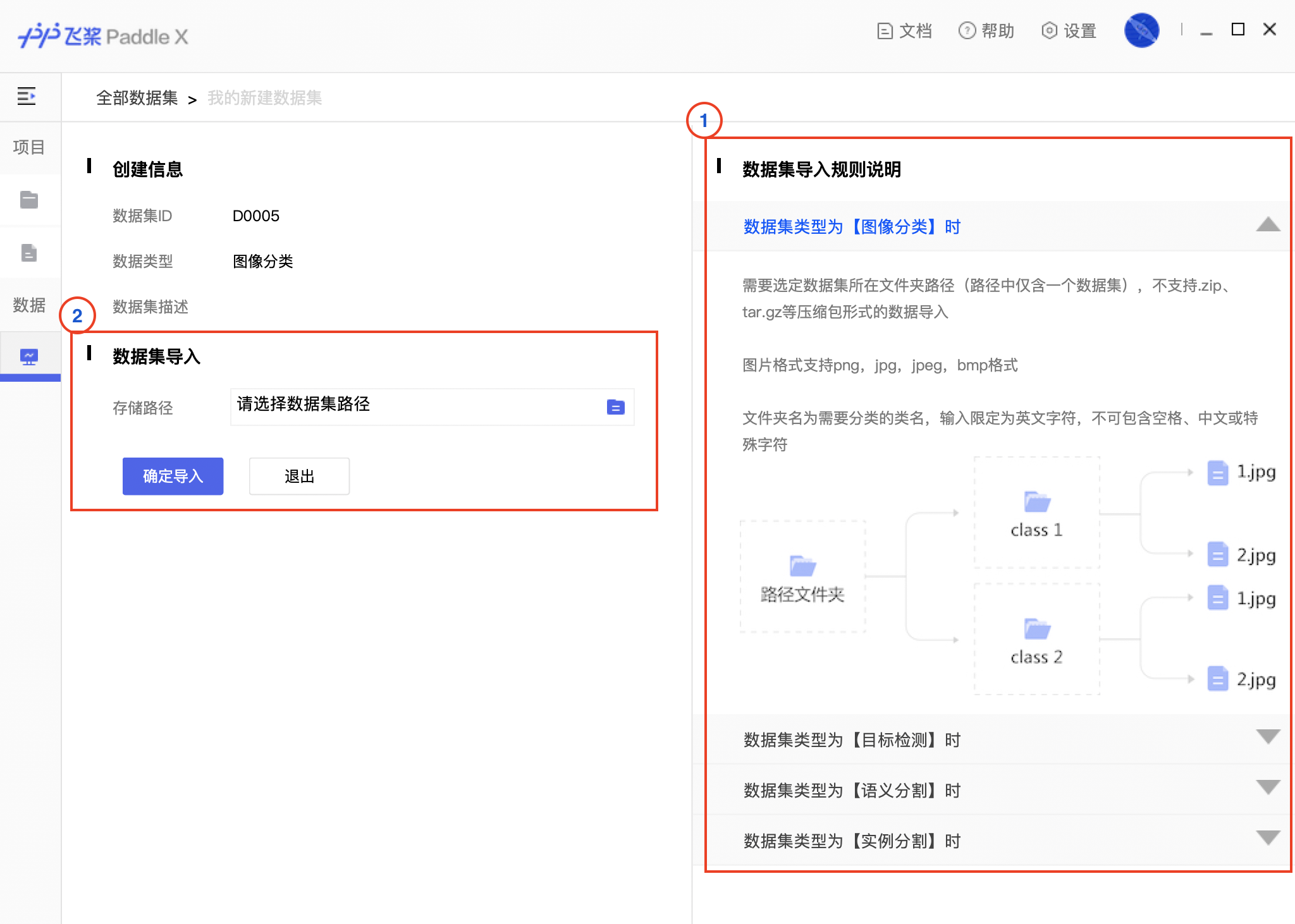
456.5 KB
docs/images/01_datasplit.png
0 → 100755
{kind=link}
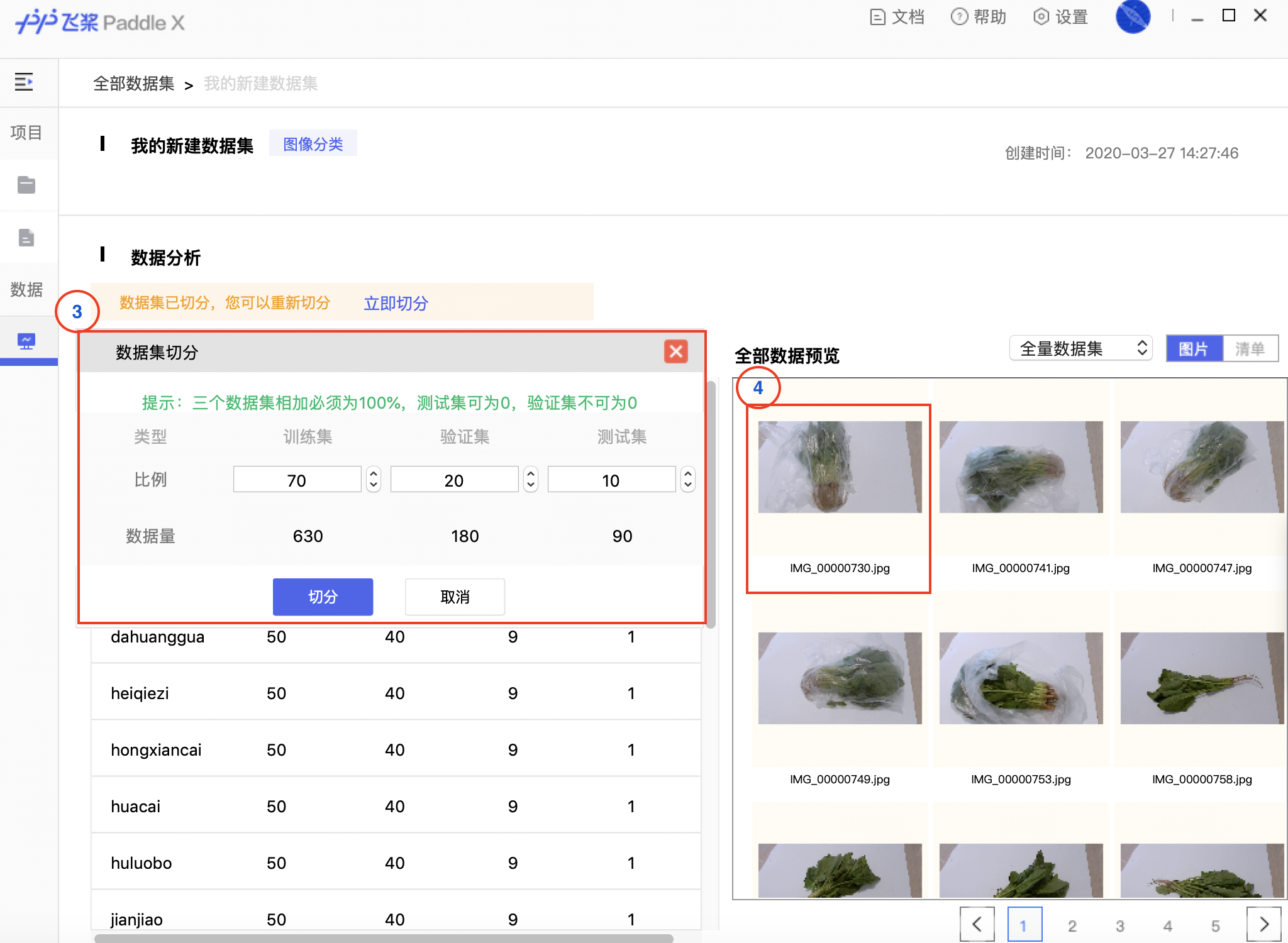
898.1 KB
docs/images/02_newproject.png
0 → 100755
{kind=link}
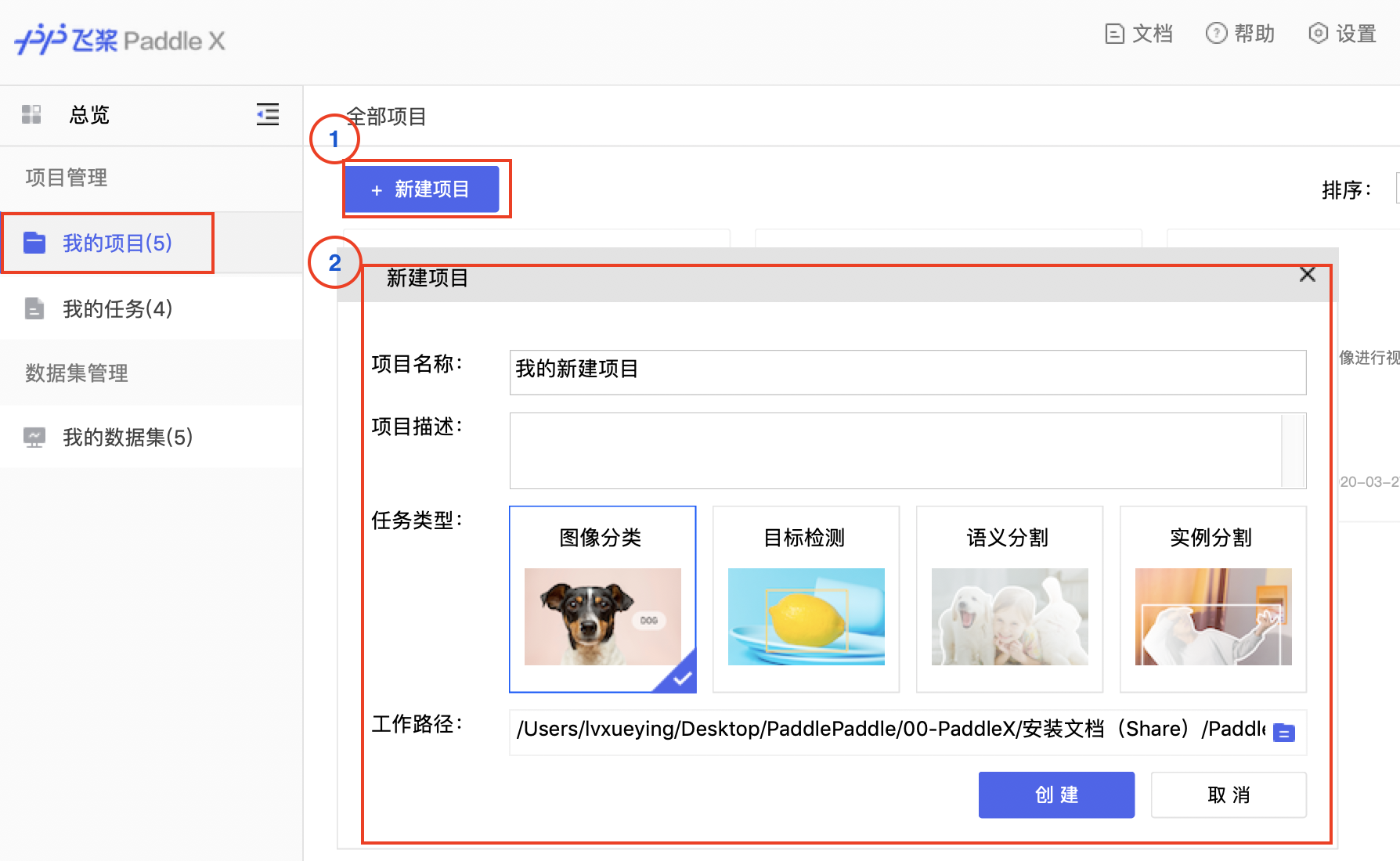
423.2 KB
docs/images/03_choosedata.png
0 → 100755
{kind=link}
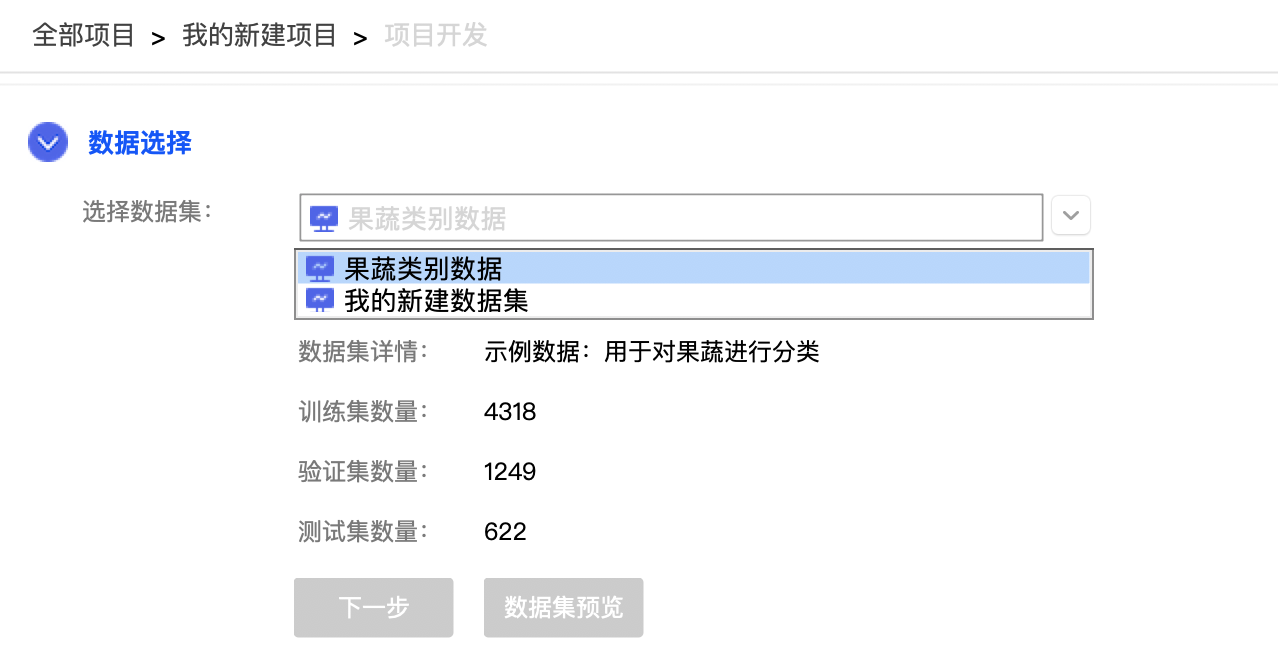
108.7 KB
docs/images/04_parameter.png
0 → 100755
{kind=link}
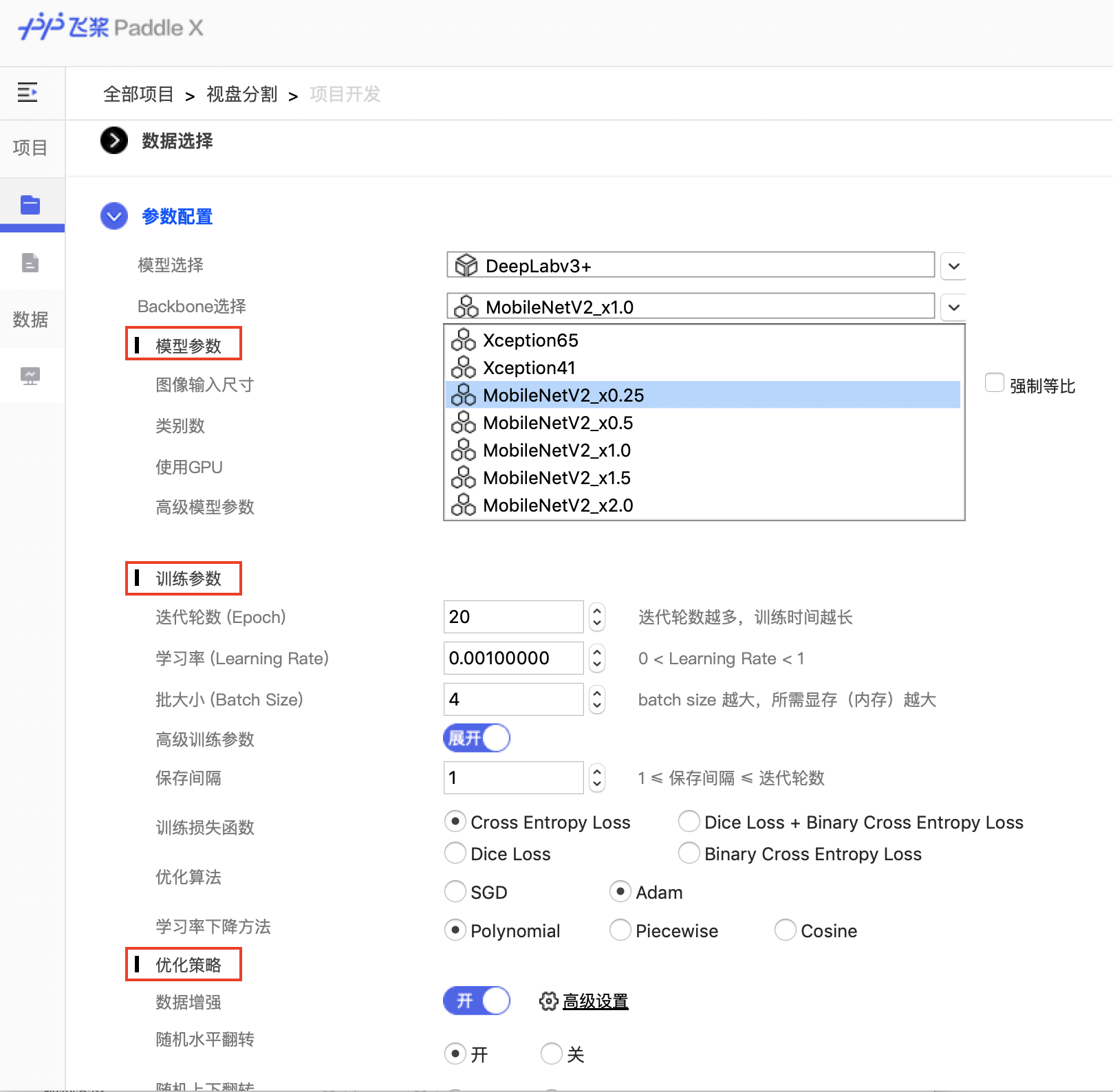
392.2 KB
docs/images/05_train.png
0 → 100755
{kind=link}
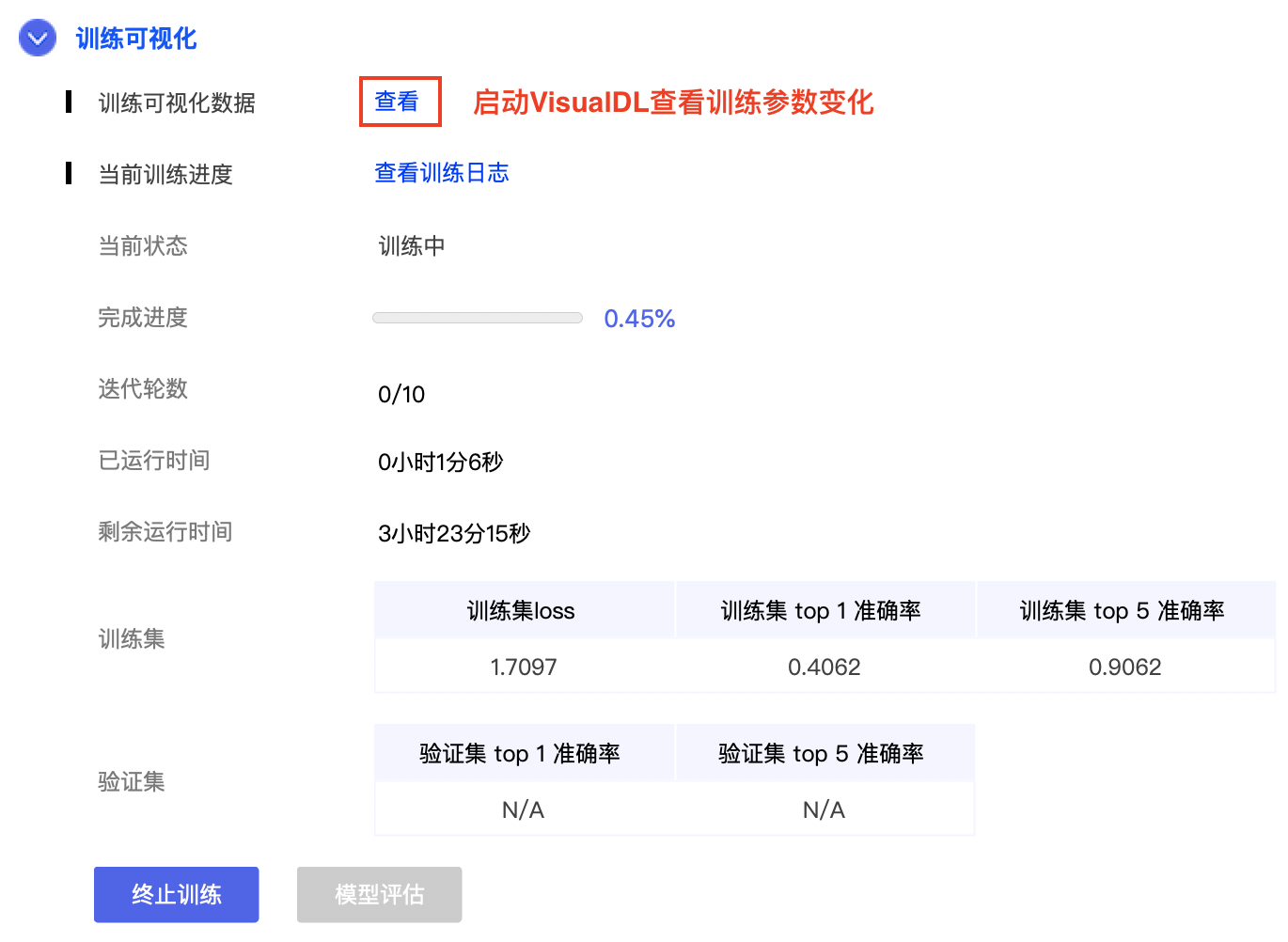
174.0 KB
docs/images/06_VisualDL.png
0 → 100755
{kind=link}
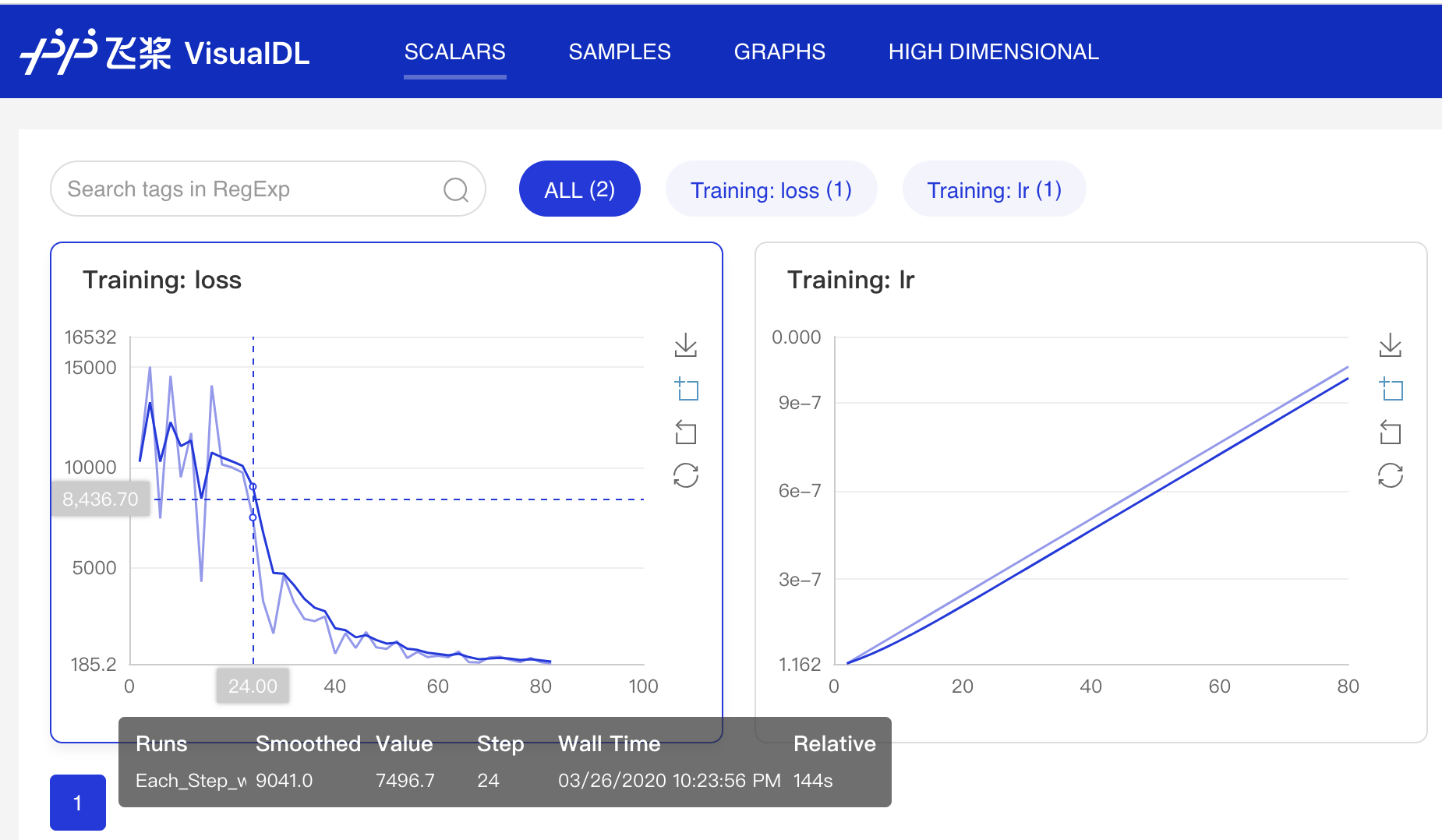
196.3 KB
docs/images/07_evaluate.png
0 → 100755
{kind=link}
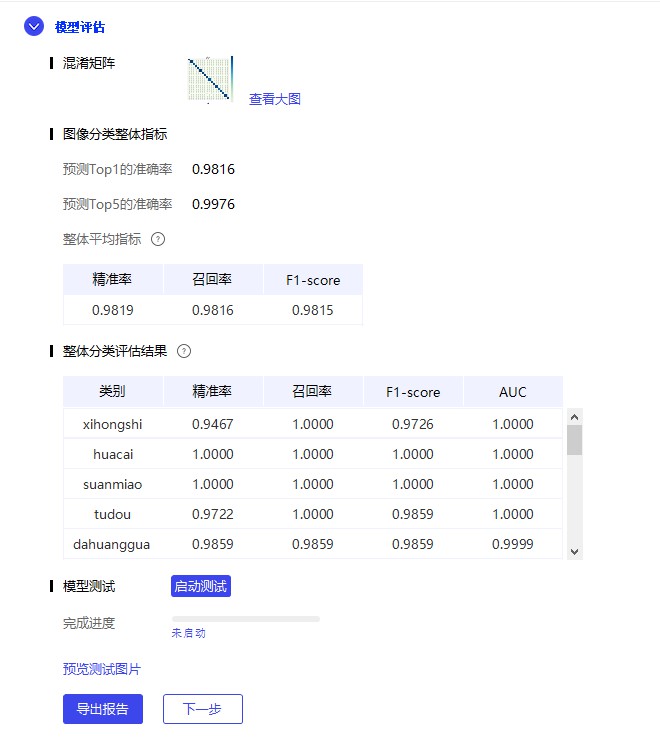
59.7 KB
docs/images/08_deploy.png
0 → 100755
{kind=link}
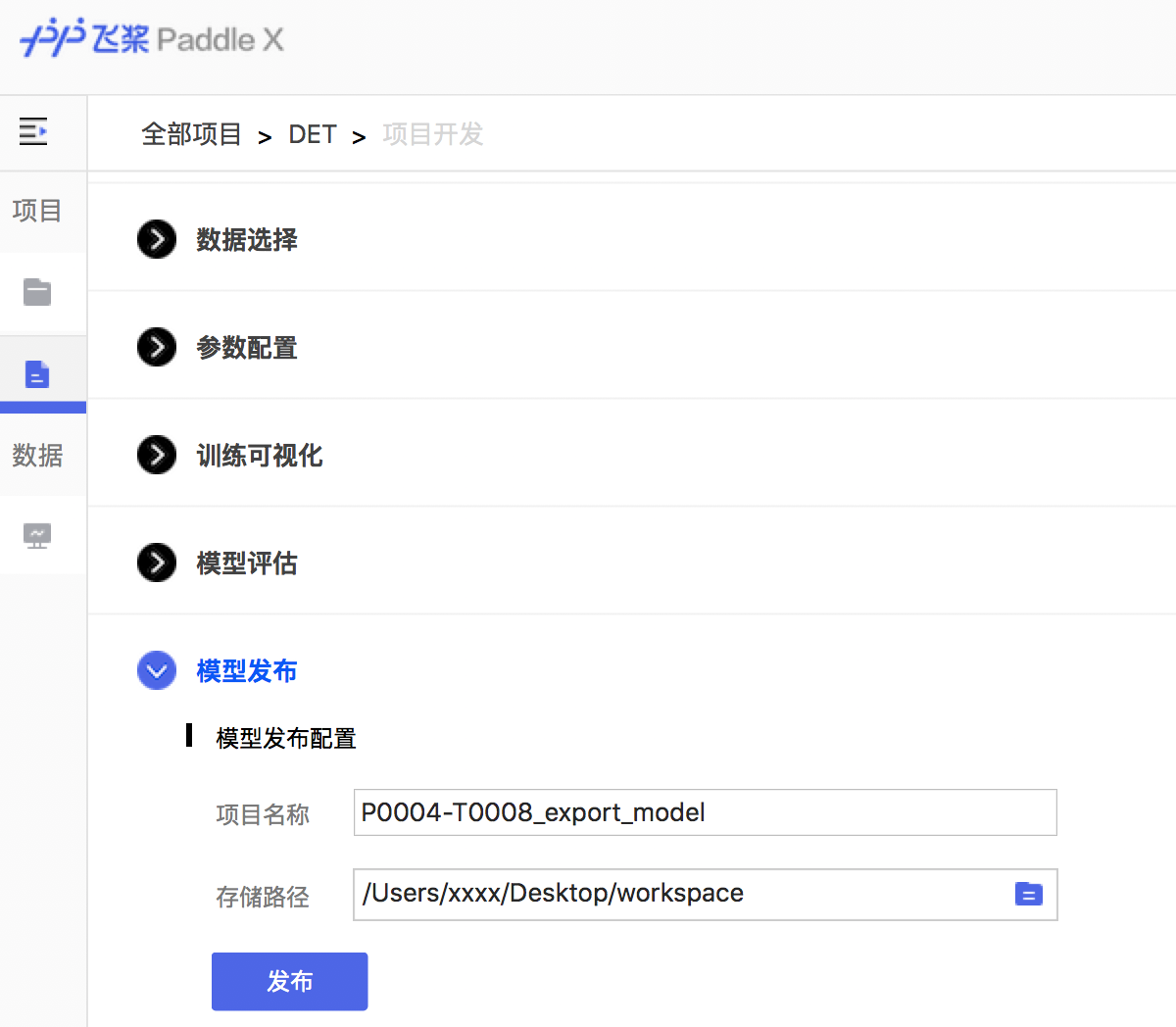
194.1 KB
docs/images/PaddleX-Pipe-Line.png
0 → 100755
{kind=link}
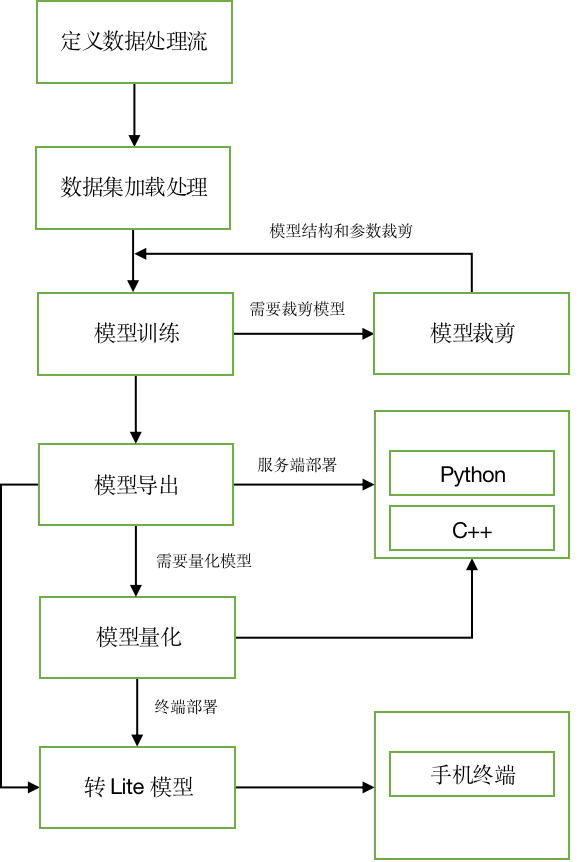
48.4 KB
docs/images/QQGroup.jpeg
0 → 100755
{kind=link}
38.3 KB
docs/images/anaconda_windows.png
0 → 100755
{kind=link}
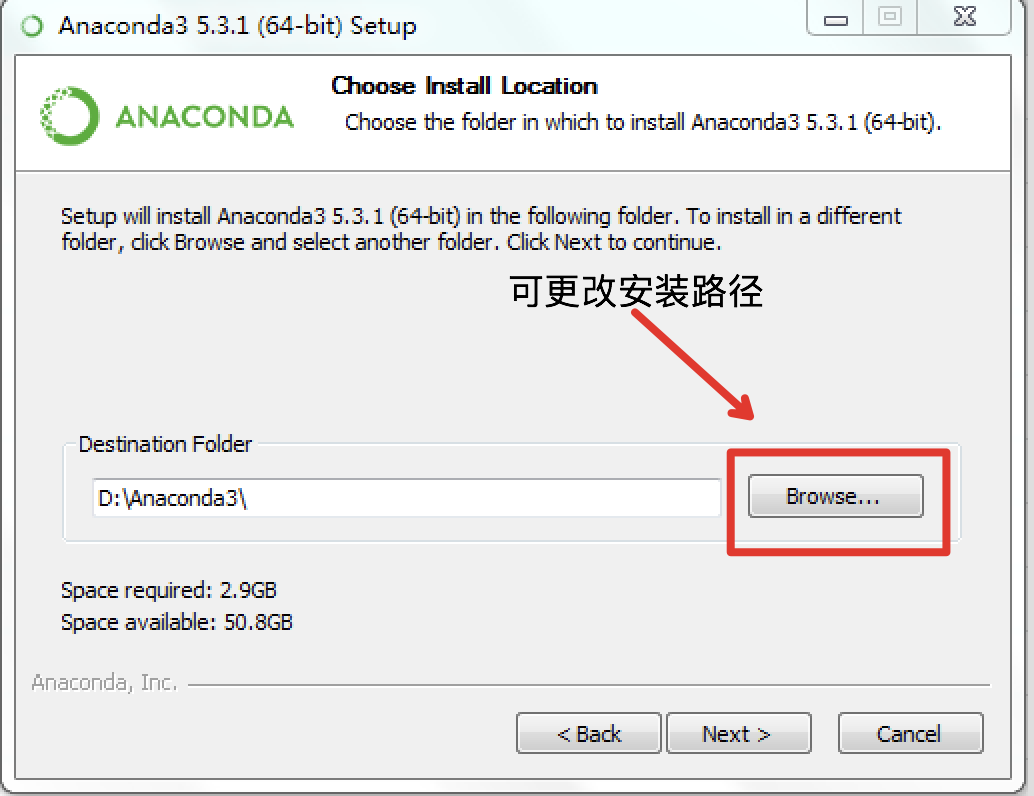
74.6 KB
docs/images/cls_eval.png
0 → 100755
{kind=link}

80.4 KB
docs/images/cls_train.png
0 → 100755
{kind=link}

94.6 KB
docs/images/faster_eval.png
0 → 100755
{kind=link}
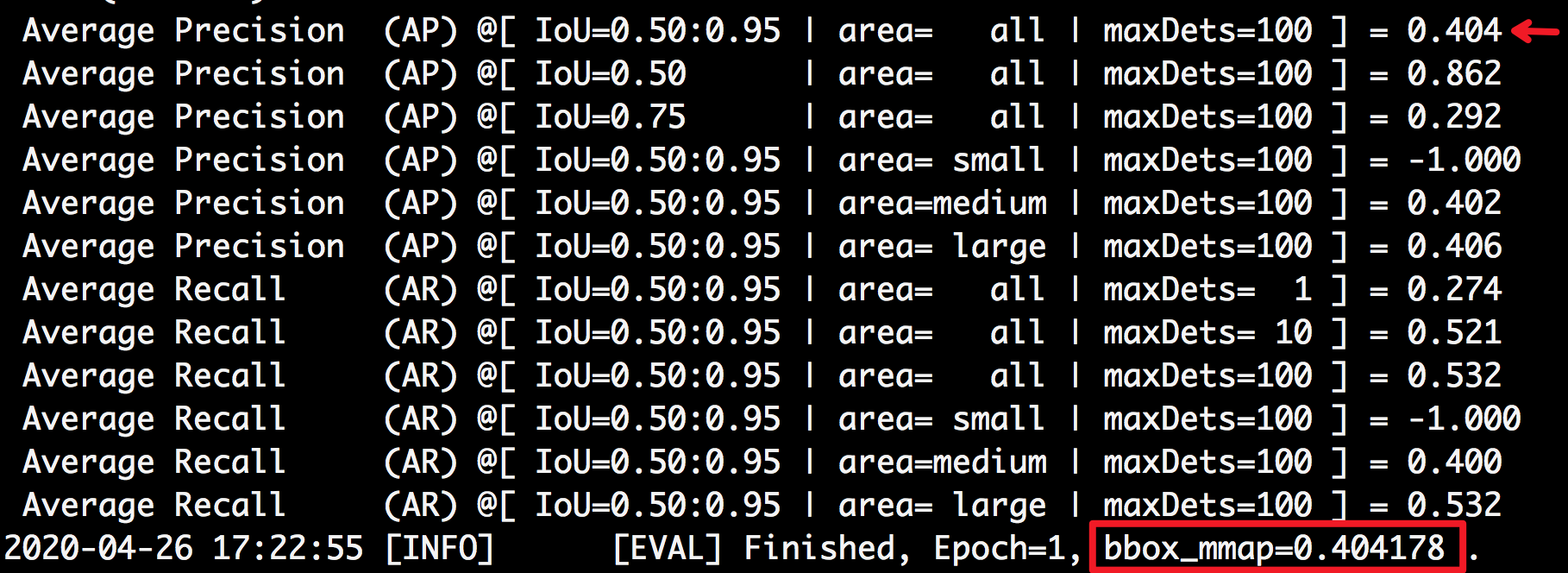
263.2 KB
docs/images/faster_train.png
0 → 100755
{kind=link}

165.5 KB
docs/images/garbage.bmp
0 → 100755
{kind=link}

918.1 KB
{kind=link}

176.2 KB
{kind=link}

213.8 KB
docs/images/lime.png
0 → 100644
{kind=link}

423.0 KB
docs/images/mask_eval.png
0 → 100755
{kind=link}
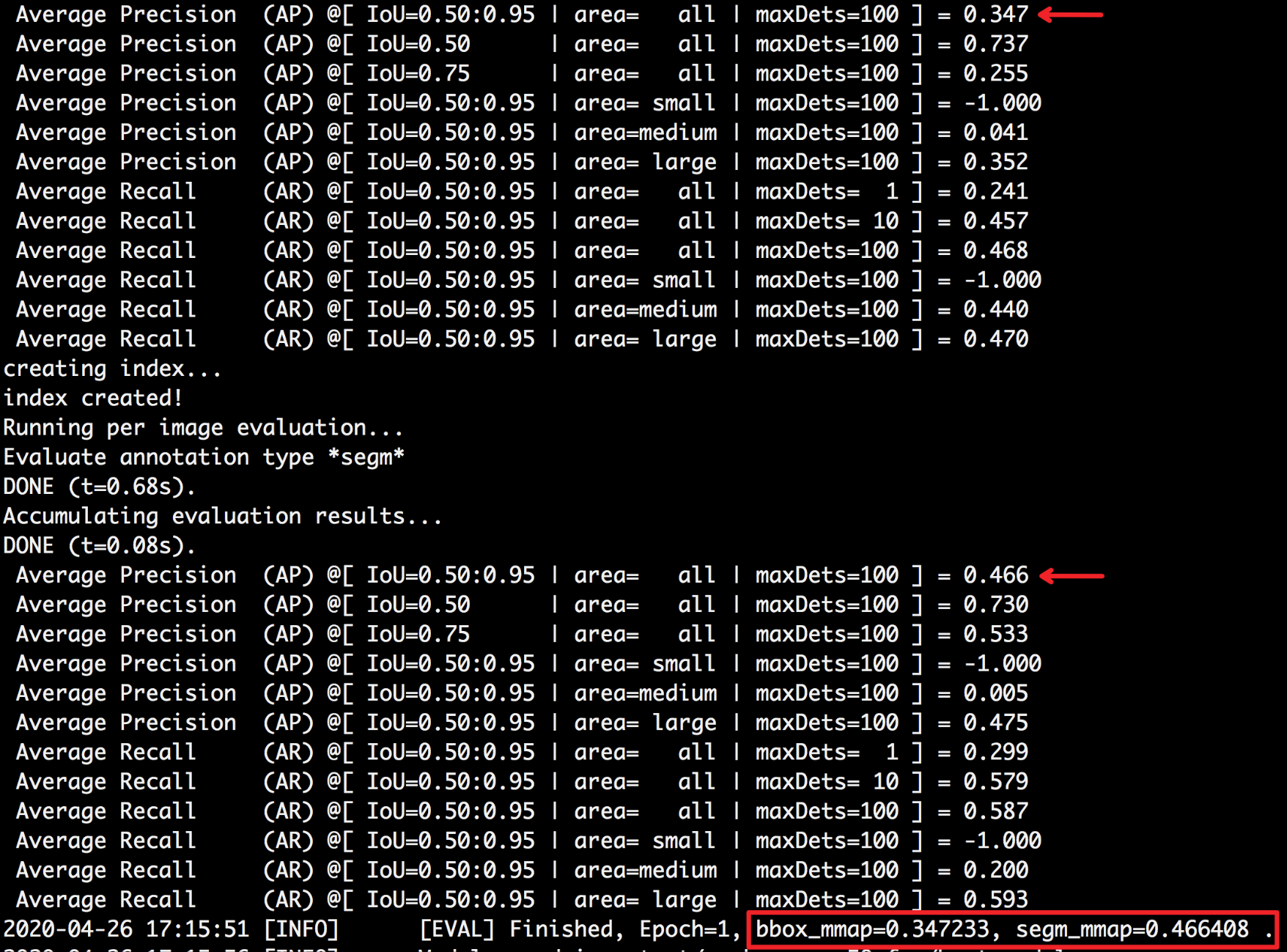
1.0 MB
docs/images/mask_train.png
0 → 100755
{kind=link}

197.1 KB
docs/images/normlime.png
0 → 100644
{kind=link}

546.2 KB
docs/images/object_detection.png
0 → 100644
{kind=link}

214.7 KB
docs/images/paddlex.jpg
0 → 100755
{kind=link}

105.2 KB
docs/images/paddlex.png
0 → 100755
{kind=link}

92.3 KB
docs/images/seg_eval.png
0 → 100755
{kind=link}

84.1 KB
docs/images/seg_train.png
0 → 100755
{kind=link}

85.5 KB
{kind=link}

212.3 KB
docs/images/vdl1.jpg
0 → 100644
{kind=link}
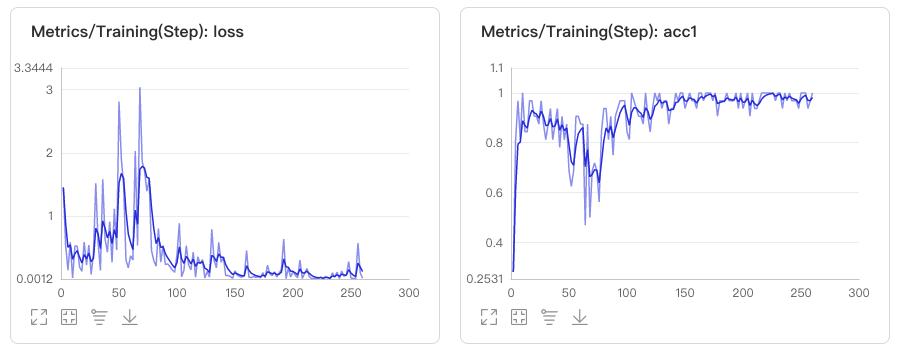
47.0 KB
docs/images/vdl2.jpg
0 → 100644
{kind=link}
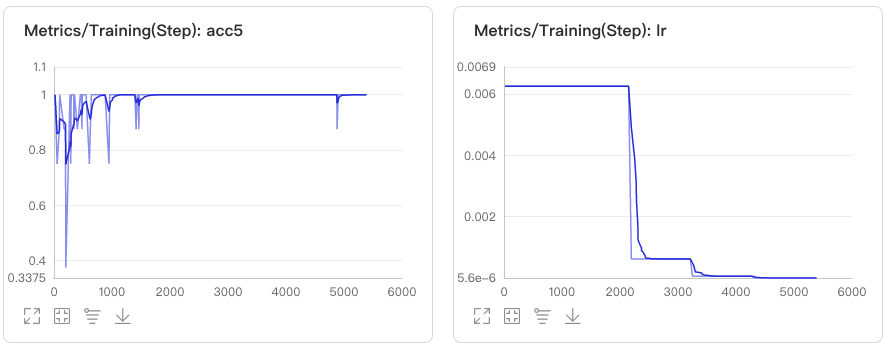
28.2 KB
docs/images/vdl3.jpg
0 → 100644
{kind=link}
29.8 KB
{kind=link}
27.3 KB
{kind=link}

114.4 KB
{kind=link}

188.2 KB
docs/images/voc_eval.png
0 → 100755
{kind=link}

37.7 KB
docs/images/yolo_train.png
0 → 100755
{kind=link}

111.4 KB
docs/metrics.md
0 → 100644
docs/model_zoo.md
0 → 100644
docs/paddlex_gui/download.md
0 → 100644
docs/paddlex_gui/how_to_use.md
0 → 100644
docs/paddlex_gui/images/QR.jpg
0 → 100644
{kind=link}
56.3 KB
docs/paddlex_gui/images/ReadMe
0 → 100644
{kind=link}
258.2 KB
{kind=link}
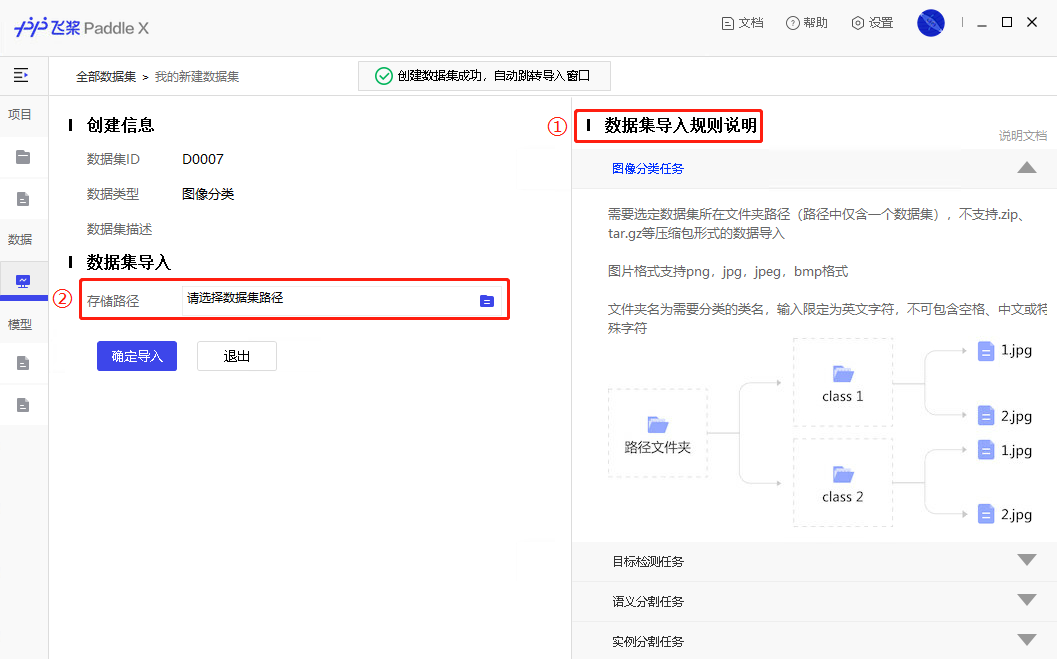
73.3 KB
{kind=link}
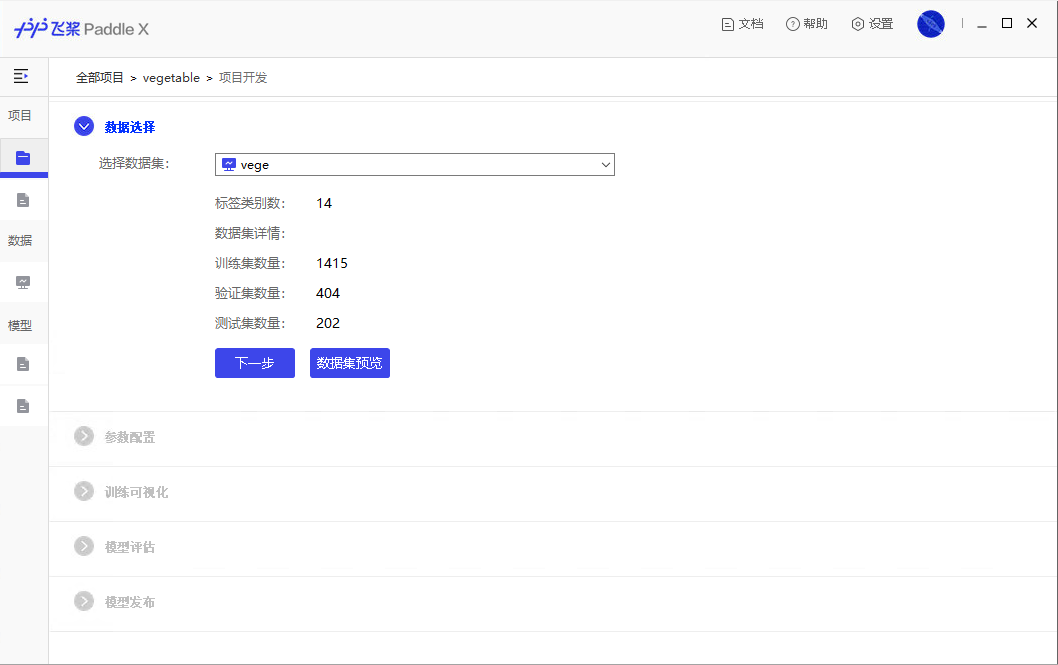
37.0 KB
{kind=link}
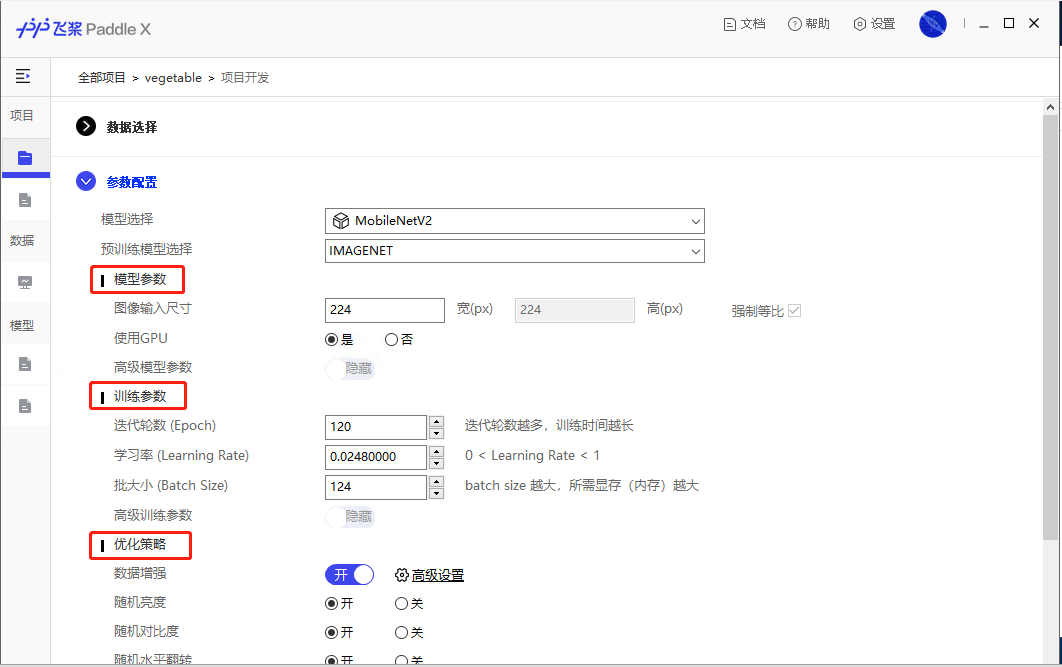
54.0 KB
{kind=link}
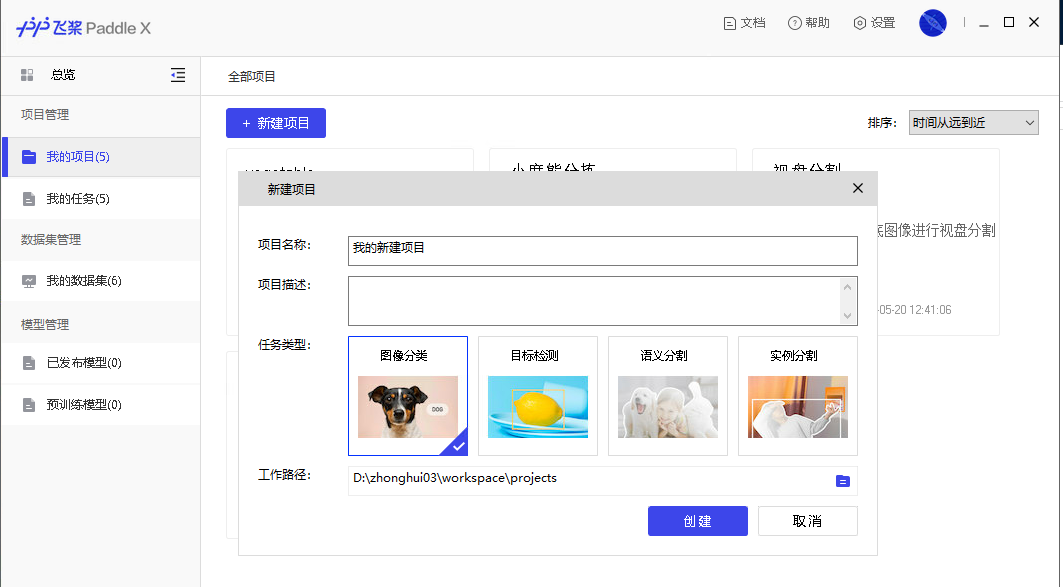
102.4 KB
{kind=link}
41.3 KB
{kind=link}
38.5 KB
{kind=link}
34.0 KB
{kind=link}
36.4 KB
{kind=link}
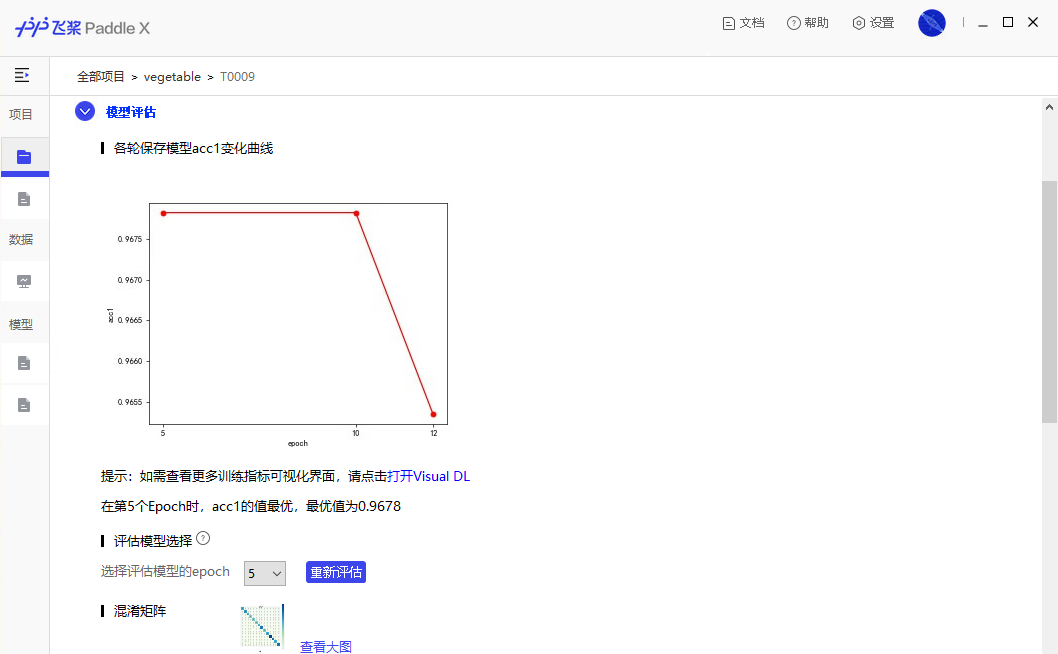
54.7 KB
{kind=link}
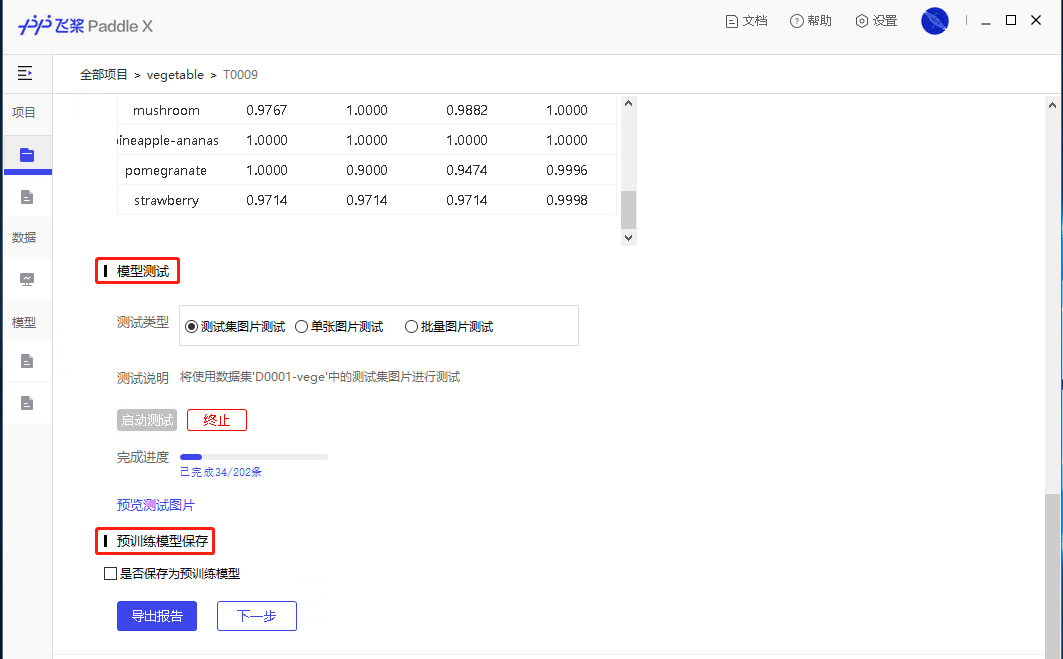
47.3 KB
docs/paddlex_gui/xx.md
0 → 100644
docs/slim/prune.md
0 → 100644
docs/slim/quant.md
0 → 100644
docs/test.cpp
0 → 100644
docs/train/classification.md
已删除
100644 → 0
docs/train/index.rst
已删除
100755 → 0
docs/train/prediction.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/tuning_strategy/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/tutorials/dataset_prepare.md
0 → 100644
此差异已折叠。
docs/tutorials/datasets.md
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/tutorials/deploy/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
docs/tutorials/index.rst
0 → 100755
此差异已折叠。
此差异已折叠。
docs/tutorials/train/detection.md
0 → 100755
此差异已折叠。
docs/tutorials/train/index.rst
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/tutorials/train/visualdl.md
0 → 100755
此差异已折叠。
docs/update.md
0 → 100644
此差异已折叠。