Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleX
提交
56f76f5f
P
PaddleX
项目概览
PaddlePaddle
/
PaddleX
通知
138
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
43
列表
看板
标记
里程碑
合并请求
5
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleX
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
43
Issue
43
列表
看板
标记
里程碑
合并请求
5
合并请求
5
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
56f76f5f
编写于
7月 11, 2020
作者:
J
Jason
提交者:
GitHub
7月 11, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #197 from FlyingQianMM/develop_qh
add meter reader and batch_predict
上级
c61b7bcd
bec41500
变更
28
隐藏空白更改
内联
并排
Showing
28 changed file
with
2898 addition
and
422 deletion
+2898
-422
examples/meter_reader/README.md
examples/meter_reader/README.md
+281
-0
examples/meter_reader/deploy/cpp/CMakeLists.txt
examples/meter_reader/deploy/cpp/CMakeLists.txt
+309
-0
examples/meter_reader/deploy/cpp/meter_reader/global.cpp
examples/meter_reader/deploy/cpp/meter_reader/global.cpp
+34
-0
examples/meter_reader/deploy/cpp/meter_reader/global.h
examples/meter_reader/deploy/cpp/meter_reader/global.h
+30
-0
examples/meter_reader/deploy/cpp/meter_reader/meter_reader.cpp
...les/meter_reader/deploy/cpp/meter_reader/meter_reader.cpp
+315
-0
examples/meter_reader/deploy/cpp/meter_reader/postprocess.cpp
...ples/meter_reader/deploy/cpp/meter_reader/postprocess.cpp
+190
-0
examples/meter_reader/deploy/cpp/meter_reader/postprocess.h
examples/meter_reader/deploy/cpp/meter_reader/postprocess.h
+42
-0
examples/meter_reader/deploy/python/reader_deploy.py
examples/meter_reader/deploy/python/reader_deploy.py
+360
-0
examples/meter_reader/image/MeterReader_Architecture.jpg
examples/meter_reader/image/MeterReader_Architecture.jpg
+0
-0
examples/meter_reader/reader_infer.py
examples/meter_reader/reader_infer.py
+360
-0
examples/meter_reader/train_detection.py
examples/meter_reader/train_detection.py
+60
-0
examples/meter_reader/train_segmentation.py
examples/meter_reader/train_segmentation.py
+56
-0
paddlex/cv/datasets/__init__.py
paddlex/cv/datasets/__init__.py
+2
-1
paddlex/cv/datasets/dataset.py
paddlex/cv/datasets/dataset.py
+38
-7
paddlex/cv/models/base.py
paddlex/cv/models/base.py
+24
-28
paddlex/cv/models/classifier.py
paddlex/cv/models/classifier.py
+95
-18
paddlex/cv/models/deeplabv3p.py
paddlex/cv/models/deeplabv3p.py
+103
-40
paddlex/cv/models/faster_rcnn.py
paddlex/cv/models/faster_rcnn.py
+121
-33
paddlex/cv/models/load_model.py
paddlex/cv/models/load_model.py
+3
-66
paddlex/cv/models/mask_rcnn.py
paddlex/cv/models/mask_rcnn.py
+108
-38
paddlex/cv/models/slim/prune_config.py
paddlex/cv/models/slim/prune_config.py
+26
-26
paddlex/cv/models/utils/pretrain_weights.py
paddlex/cv/models/utils/pretrain_weights.py
+4
-2
paddlex/cv/models/yolo_v3.py
paddlex/cv/models/yolo_v3.py
+111
-29
paddlex/cv/transforms/__init__.py
paddlex/cv/transforms/__init__.py
+82
-0
paddlex/cv/transforms/cls_transforms.py
paddlex/cv/transforms/cls_transforms.py
+10
-7
paddlex/cv/transforms/det_transforms.py
paddlex/cv/transforms/det_transforms.py
+13
-6
paddlex/cv/transforms/seg_transforms.py
paddlex/cv/transforms/seg_transforms.py
+4
-2
paddlex/deploy.py
paddlex/deploy.py
+117
-119
未找到文件。
examples/meter_reader/README.md
0 → 100644
浏览文件 @
56f76f5f
# MeterReader表计读数
本案例基于PaddleX实现对传统机械式指针表计的检测与自动读数功能,开放表计数据和预训练模型,并提供在windows系统的服务器端以及linux系统的jetson嵌入式设备上的部署指南。
## 目录
*
[
读数流程
](
#1
)
*
[
表计数据和预训练模型
](
#2
)
*
[
快速体验表盘读数
](
#3
)
*
[
推理部署
](
#4
)
*
[
模型训练
](
#5
)
## <h2 id="1">读数流程</h2>
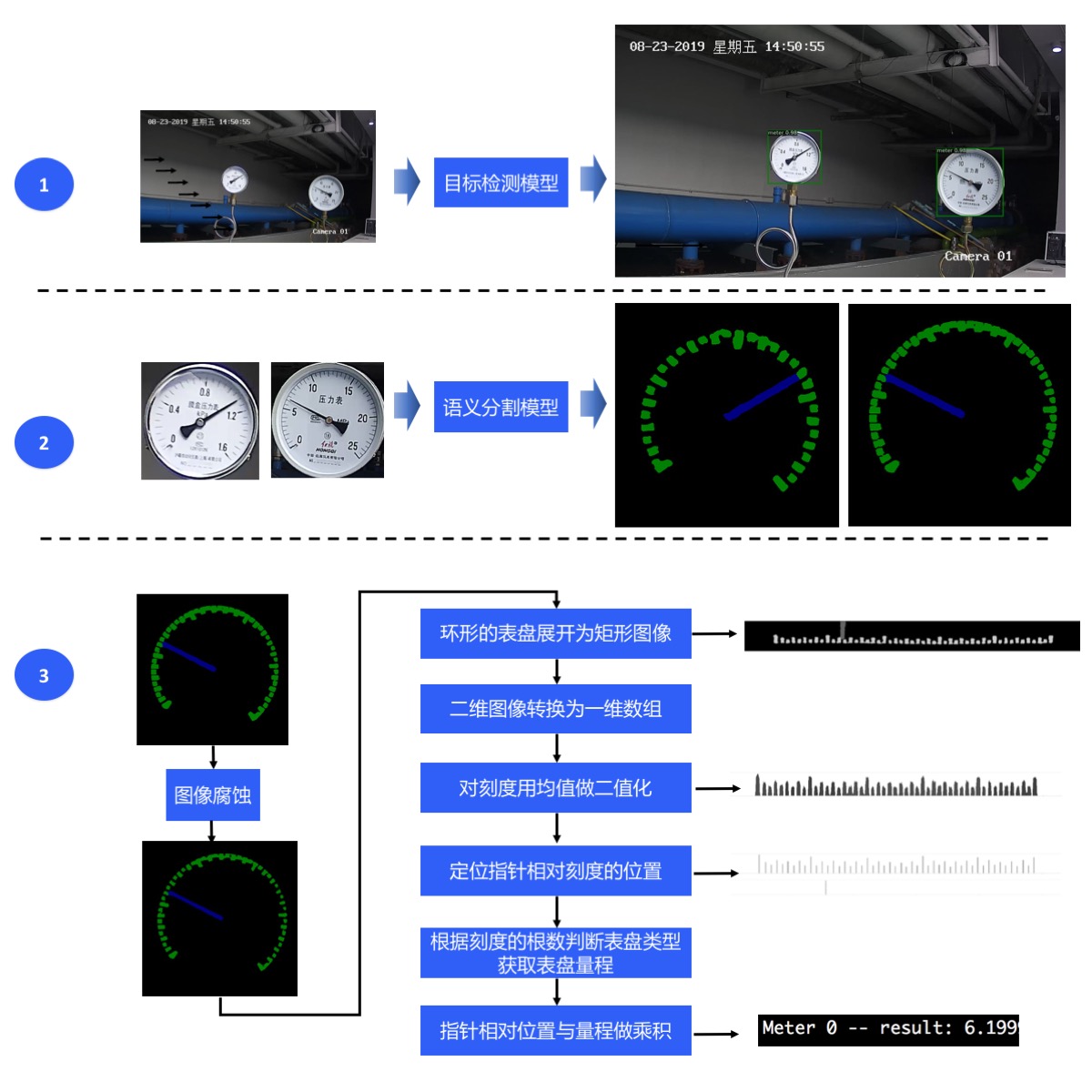
表计读数共分为三个步骤完成:
*
第一步,使用目标检测模型检测出图像中的表计
*
第二步,使用语义分割模型将各表具的指针和刻度分割出来
*
第三步,根据指针的相对位置和预知的量程计算出各表计的读数。

*
**表计检测**
:由于本案例中没有面积较小的表计,所以目标检测模型选择性能更优的
**YOLOv3**
。考虑到本案例主要在有GPU的设备上部署,所以骨干网路选择精度更高的
**DarkNet53**
。
*
**刻度和指针分割**
:考虑到刻度和指针均为细小区域,语义分割模型选择效果更好的
**DeepLapv3**
。
*
**读数后处理**
:首先,对语义分割的预测类别图进行图像腐蚀操作,以达到刻度细分的目的。然后把环形的表盘展开为矩形图像,根据图像中类别信息生成一维的刻度数组和一维的指针数组。接着计算刻度数组的均值,用均值对刻度数组进行二值化操作。最后定位出指针相对刻度的位置,根据刻度的根数判断表盘的类型以此获取表盘的量程,将指针相对位置与量程做乘积得到表盘的读数。
## <h2 id="2">表计数据和预训练模型</h2>
本案例开放了表计测试图片,用于体验表计读数的预测推理全流程。还开放了表计检测数据集、指针和刻度分割数据集,用户可以使用这些数据集重新训练模型。
| 表计测试图片 | 表计检测数据集 | 指针和刻度分割数据集 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
[
meter_test
](
https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_test.tar.gz
)
|
[
meter_det
](
https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_det.tar.gz
)
|
[
meter_seg
](
https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_seg.tar.gz
)
|
本案例开放了预先训练好的检测模型和语义分割模型,可以使用这些模型快速体验表计读数全流程,也可以直接将这些模型部署在服务器端或jetson嵌入式设备上进行推理预测。
| 表计检测模型 | 指针和刻度分割模型 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|
[
meter_det_inference_model
](
https://bj.bcebos.com/paddlex/examples/meter_reader/models/meter_det_inference_model.tar.gz
)
|
[
meter_seg_inference_model
](
https://bj.bcebos.com/paddlex/examples/meter_reader/models/meter_seg_inference_model.tar.gz
)
|
## <h2 id="3">快速体验表盘读数</h2>
可以使用本案例提供的预训练模型快速体验表计读数的自动预测全流程。如果不需要预训练模型,可以跳转至小节
`模型训练`
重新训练模型。
#### 前置依赖
*
Paddle paddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
https://paddlex.readthedocs.io/zh_CN/latest/install.html
)
#### 测试表计读数
1.
下载PaddleX源码:
```
git clone https://github.com/PaddlePaddle/PaddleX
```
2.
预测执行文件位于
`PaddleX/examples/meter_reader/`
,进入该目录:
```
cd PaddleX/examples/meter_reader/
```
预测执行文件为
`reader_infer.py`
,其主要参数说明如下:
| 参数 | 说明 |
| ---- | ---- |
| detector_dir | 表计检测模型路径 |
| segmenter_dir | 指针和刻度分割模型路径|
| image | 待预测的图片路径 |
| image_dir | 存储待预测图片的文件夹路径 |
| save_dir | 保存可视化结果的路径, 默认值为"output"|
| score_threshold | 检测模型输出结果中,预测得分低于该阈值的框将被滤除,默认值为0.5|
| seg_batch_size | 分割的批量大小,默认为2 |
| seg_thread_num | 分割预测的线程数,默认为cpu处理器个数 |
| use_camera | 是否使用摄像头采集图片,默认为False |
| camera_id | 摄像头设备ID,默认值为0 |
| use_erode | 是否使用图像腐蚀对分割预测图进行细分,默认为False |
| erode_kernel | 图像腐蚀操作时的卷积核大小,默认值为4 |
3.
预测
若要使用GPU,则指定GPU卡号(以0号卡为例):
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
```
若不使用GPU,则将CUDA_VISIBLE_DEVICES指定为空:
```
shell
export
CUDA_VISIBLE_DEVICES
=
```
*
预测单张图片
```
shell
python3 reader_infer.py
--detector_dir
/path/to/det_inference_model
--segmenter_dir
/path/to/seg_inference_model
--image
/path/to/meter_test/20190822_168.jpg
--save_dir
./output
--use_erode
```
*
预测多张图片
```
shell
python3 reader_infer.py
--detector_dir
/path/to/det_inference_model
--segmenter_dir
/path/to/seg_inference_model
--image_dir
/path/to/meter_test
--save_dir
./output
--use_erode
```
*
开启摄像头预测
```
shell
python3 reader_infer.py
--detector_dir
/path/to/det_inference_model
--segmenter_dir
/path/to/seg_inference_model
--save_dir
./output
--use_erode
--use_camera
```
## <h2 id="4">推理部署</h2>
### Windows系统的服务器端安全部署
#### c++部署
1.
下载PaddleX源码:
```
git clone https://github.com/PaddlePaddle/PaddleX
```
2.
将
`PaddleX\examples\meter_reader\deploy\cpp`
下的
`meter_reader`
文件夹和
`CMakeList.txt`
拷贝至
`PaddleX\deploy\cpp`
目录下,拷贝之前可以将
`PaddleX\deploy\cpp`
下原本的
`CMakeList.txt`
做好备份。
3.
按照
[
Windows平台部署
](
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/tutorials/deploy/deploy_server/deploy_cpp/deploy_cpp_win_vs2019.md
)
中的Step2至Step4完成C++预测代码的编译。
4.
编译成功后,可执行文件在
`out\build\x64-Release`
目录下,打开
`cmd`
,并切换到该目录:
```
cd PaddleX\deploy\cpp\out\build\x64-Release
```
预测程序为paddle_inference
\m
eter_reader.exe,其主要命令参数说明如下:
| 参数 | 说明 |
| ---- | ---- |
| det_model_dir | 表计检测模型路径 |
| seg_model_dir | 指针和刻度分割模型路径|
| image | 待预测的图片路径 |
| image_list | 按行存储图片路径的.txt文件 |
| use_gpu | 是否使用 GPU 预测, 支持值为0或1(默认值为0)|
| gpu_id | GPU 设备ID, 默认值为0 |
| save_dir | 保存可视化结果的路径, 默认值为"output"|
| det_key | 检测模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的检测模型 |
| seg_key | 分割模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的分割模型 |
| seg_batch_size | 分割的批量大小,默认为2 |
| thread_num | 分割预测的线程数,默认为cpu处理器个数 |
| use_camera | 是否使用摄像头采集图片,支持值为0或1(默认值为0) |
| camera_id | 摄像头设备ID,默认值为0 |
| use_erode | 是否使用图像腐蚀对分割预测图进行去噪,支持值为0或1(默认值为1) |
| erode_kernel | 图像腐蚀操作时的卷积核大小,默认值为4 |
| score_threshold | 检测模型输出结果中,预测得分低于该阈值的框将被滤除,默认值为0.5|
5.
推理预测:
用于部署推理的模型应为inference格式,本案例提供的预训练模型均为inference格式,如若是重新训练的模型,需参考
[
导出inference模型
](
https://paddlex.readthedocs.io/zh_CN/latest/tutorials/deploy/deploy_server/deploy_python.html#inference
)
将模型导出为inference格式。
*
使用未加密的模型对单张图片做预测
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\d
et_inference_model
--seg_model_dir
=
\p
ath
\t
o
\s
eg_inference_model
--image
=
\p
ath
\t
o
\m
eter_test
\2
0190822_168.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型对图像列表做预测
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\d
et_inference_model
--seg_model_dir
=
\p
ath
\t
o
\s
eg_inference_model
--image_list
=
\p
ath
\t
o
\m
eter_test
\i
mage_list.txt
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型开启摄像头做预测
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\d
et_inference_model
--seg_model_dir
=
\p
ath
\t
o
\s
eg_inference_model
--use_camera
=
1
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用加密后的模型对单张图片做预测
如果未对模型进行加密,请参考
[
加密PaddleX模型
](
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/tutorials/deploy/deploy_server/encryption.html#paddlex
)
对模型进行加密。例如加密后的检测模型所在目录为
`\path\to\encrypted_det_inference_model`
,密钥为
`yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0=`
;加密后的分割模型所在目录为
`\path\to\encrypted_seg_inference_model`
,密钥为
`DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY=`
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\e
ncrypted_det_inference_model
--seg_model_dir
=
\p
ath
\t
o
\e
ncrypted_seg_inference_model
--image
=
\p
ath
\t
o
\t
est.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
--det_key
yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0
=
--seg_key
DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY
=
```
### Linux系统的jeton嵌入式设备安全部署
#### c++部署
1.
下载PaddleX源码:
```
git clone https://github.com/PaddlePaddle/PaddleX
```
2.
将
`PaddleX/examples/meter_reader/deploy/cpp`
下的
`meter_reader`
文件夹和
`CMakeList.txt`
拷贝至
`PaddleX/deploy/cpp`
目录下,拷贝之前可以将
`PaddleX/deploy/cpp`
下原本的
`CMakeList.txt`
做好备份。
3.
按照
[
Nvidia-Jetson开发板部署
](
)中的Step2至Step3完成C++预测代码的编译。
4.
编译成功后,可执行程为
`build/meter_reader/meter_reader`
,其主要命令参数说明如下:
| 参数 | 说明 |
| ---- | ---- |
| det_model_dir | 表计检测模型路径 |
| seg_model_dir | 指针和刻度分割模型路径|
| image | 待预测的图片路径 |
| image_list | 按行存储图片路径的.txt文件 |
| use_gpu | 是否使用 GPU 预测, 支持值为0或1(默认值为0)|
| gpu_id | GPU 设备ID, 默认值为0 |
| save_dir | 保存可视化结果的路径, 默认值为"output"|
| det_key | 检测模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的检测模型 |
| seg_key | 分割模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的分割模型 |
| seg_batch_size | 分割的批量大小,默认为2 |
| thread_num | 分割预测的线程数,默认为cpu处理器个数 |
| use_camera | 是否使用摄像头采集图片,支持值为0或1(默认值为0) |
| camera_id | 摄像头设备ID,默认值为0 |
| use_erode | 是否使用图像腐蚀对分割预测图进行细分,支持值为0或1(默认值为1) |
| erode_kernel | 图像腐蚀操作时的卷积核大小,默认值为4 |
| score_threshold | 检测模型输出结果中,预测得分低于该阈值的框将被滤除,默认值为0.5|
5.
推理预测:
用于部署推理的模型应为inference格式,本案例提供的预训练模型均为inference格式,如若是重新训练的模型,需参考
[
导出inference模型
](
)将模型导出为inference格式。
*
使用未加密的模型对单张图片做预测
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/det_inference_model
--seg_model_dir
=
/path/to/seg_inference_model
--image
=
/path/to/meter_test/20190822_168.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型对图像列表做预测
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/det_inference_model
--seg_model_dir
=
/path/to/seg_inference_model
--image_list
=
/path/to/image_list.txt
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型开启摄像头做预测
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/det_inference_model
--seg_model_dir
=
/path/to/seg_inference_model
--use_camera
=
1
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用加密后的模型对单张图片做预测
如果未对模型进行加密,请参考
[
加密PaddleX模型
](
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/tutorials/deploy/deploy_server/encryption.html#paddlex
)
对模型进行加密。例如加密后的检测模型所在目录为
`/path/to/encrypted_det_inference_model`
,密钥为
`yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0=`
;加密后的分割模型所在目录为
`/path/to/encrypted_seg_inference_model`
,密钥为
`DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY=`
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/encrypted_det_inference_model
--seg_model_dir
=
/path/to/encrypted_seg_inference_model
--image
=
/path/to/test.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
--det_key
yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0
=
--seg_key
DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY
=
```
## <h2 id="5">模型训练</h2>
#### 前置依赖
*
Paddle paddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
https://paddlex.readthedocs.io/zh_CN/latest/install.html
)
#### 训练
*
表盘检测的训练
```
python3 /path/to/PaddleX/examples/meter_reader/train_detection.py
```
*
指针和刻度分割的训练
```
python3 /path/to/PaddleX/examples/meter_reader/train_segmentation.py
```
运行以上脚本可以训练本案例的检测模型和分割模型。如果不需要本案例的数据和模型参数,可更换数据,选择合适的模型并调整训练参数。
examples/meter_reader/deploy/cpp/CMakeLists.txt
0 → 100644
浏览文件 @
56f76f5f
cmake_minimum_required
(
VERSION 3.0
)
project
(
PaddleX CXX C
)
option
(
WITH_MKL
"Compile meter_reader with MKL/OpenBlas support,defaultuseMKL."
ON
)
option
(
WITH_GPU
"Compile meter_reader with GPU/CPU, default use CPU."
ON
)
option
(
WITH_STATIC_LIB
"Compile meter_reader with static/shared library, default use static."
OFF
)
option
(
WITH_TENSORRT
"Compile meter_reader with TensorRT."
OFF
)
option
(
WITH_ENCRYPTION
"Compile meter_reader with encryption tool."
OFF
)
SET
(
TENSORRT_DIR
""
CACHE PATH
"Location of libraries"
)
SET
(
PADDLE_DIR
""
CACHE PATH
"Location of libraries"
)
SET
(
OPENCV_DIR
""
CACHE PATH
"Location of libraries"
)
SET
(
ENCRYPTION_DIR
""
CACHE PATH
"Location of libraries"
)
SET
(
CUDA_LIB
""
CACHE PATH
"Location of libraries"
)
if
(
NOT WIN32
)
set
(
CMAKE_ARCHIVE_OUTPUT_DIRECTORY
${
CMAKE_BINARY_DIR
}
/lib
)
set
(
CMAKE_LIBRARY_OUTPUT_DIRECTORY
${
CMAKE_BINARY_DIR
}
/lib
)
set
(
CMAKE_RUNTIME_OUTPUT_DIRECTORY
${
CMAKE_BINARY_DIR
}
/meter_reader
)
else
()
set
(
CMAKE_ARCHIVE_OUTPUT_DIRECTORY
${
CMAKE_BINARY_DIR
}
/paddlex_inference
)
set
(
CMAKE_LIBRARY_OUTPUT_DIRECTORY
${
CMAKE_BINARY_DIR
}
/paddlex_inference
)
set
(
CMAKE_RUNTIME_OUTPUT_DIRECTORY
${
CMAKE_BINARY_DIR
}
/paddlex_inference
)
endif
()
if
(
NOT WIN32
)
SET
(
YAML_BUILD_TYPE ON CACHE BOOL
"yaml build shared library."
)
else
()
SET
(
YAML_BUILD_TYPE OFF CACHE BOOL
"yaml build shared library."
)
endif
()
include
(
cmake/yaml-cpp.cmake
)
include_directories
(
"
${
CMAKE_SOURCE_DIR
}
/"
)
include_directories
(
"
${
CMAKE_CURRENT_BINARY_DIR
}
/ext/yaml-cpp/src/ext-yaml-cpp/include"
)
link_directories
(
"
${
CMAKE_CURRENT_BINARY_DIR
}
/ext/yaml-cpp/lib"
)
macro
(
safe_set_static_flag
)
foreach
(
flag_var
CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE
CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO
)
if
(
${
flag_var
}
MATCHES
"/MD"
)
string
(
REGEX REPLACE
"/MD"
"/MT"
${
flag_var
}
"
${${
flag_var
}}
"
)
endif
(
${
flag_var
}
MATCHES
"/MD"
)
endforeach
(
flag_var
)
endmacro
()
if
(
WITH_ENCRYPTION
)
add_definitions
(
-DWITH_ENCRYPTION=
${
WITH_ENCRYPTION
}
)
endif
()
if
(
WITH_MKL
)
ADD_DEFINITIONS
(
-DUSE_MKL
)
endif
()
if
(
NOT DEFINED PADDLE_DIR OR
${
PADDLE_DIR
}
STREQUAL
""
)
message
(
FATAL_ERROR
"please set PADDLE_DIR with -DPADDLE_DIR=/path/paddle_influence_dir"
)
endif
()
if
(
NOT DEFINED OPENCV_DIR OR
${
OPENCV_DIR
}
STREQUAL
""
)
message
(
FATAL_ERROR
"please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv"
)
endif
()
include_directories
(
"
${
CMAKE_SOURCE_DIR
}
/"
)
include_directories
(
"
${
PADDLE_DIR
}
/"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/protobuf/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/glog/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/gflags/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/xxhash/include"
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappy/include"
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappystream/include"
)
endif
()
# zlib does not exist in 1.8.1
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/zlib/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/zlib/include"
)
endif
()
include_directories
(
"
${
PADDLE_DIR
}
/third_party/boost"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/eigen3"
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/zlib/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/zlib/lib"
)
endif
()
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/protobuf/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/glog/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/gflags/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/xxhash/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/paddle/lib/"
)
link_directories
(
"
${
CMAKE_CURRENT_BINARY_DIR
}
"
)
if
(
WIN32
)
include_directories
(
"
${
PADDLE_DIR
}
/paddle/fluid/inference"
)
include_directories
(
"
${
PADDLE_DIR
}
/paddle/include"
)
link_directories
(
"
${
PADDLE_DIR
}
/paddle/fluid/inference"
)
find_package
(
OpenCV REQUIRED PATHS
${
OPENCV_DIR
}
/build/ NO_DEFAULT_PATH
)
unset
(
OpenCV_DIR CACHE
)
else
()
find_package
(
OpenCV REQUIRED PATHS
${
OPENCV_DIR
}
/share/OpenCV NO_DEFAULT_PATH
)
include_directories
(
"
${
PADDLE_DIR
}
/paddle/include"
)
link_directories
(
"
${
PADDLE_DIR
}
/paddle/lib"
)
endif
()
include_directories
(
${
OpenCV_INCLUDE_DIRS
}
)
if
(
WIN32
)
add_definitions
(
"/DGOOGLE_GLOG_DLL_DECL="
)
find_package
(
OpenMP REQUIRED
)
if
(
OPENMP_FOUND
)
message
(
"OPENMP FOUND"
)
set
(
CMAKE_C_FLAGS_DEBUG
"
${
CMAKE_C_FLAGS_DEBUG
}
${
OpenMP_C_FLAGS
}
"
)
set
(
CMAKE_C_FLAGS_RELEASE
"
${
CMAKE_C_FLAGS_RELEASE
}
${
OpenMP_C_FLAGS
}
"
)
set
(
CMAKE_CXX_FLAGS_DEBUG
"
${
CMAKE_CXX_FLAGS_DEBUG
}
${
OpenMP_CXX_FLAGS
}
"
)
set
(
CMAKE_CXX_FLAGS_RELEASE
"
${
CMAKE_CXX_FLAGS_RELEASE
}
${
OpenMP_CXX_FLAGS
}
"
)
endif
()
set
(
CMAKE_C_FLAGS_DEBUG
"
${
CMAKE_C_FLAGS_DEBUG
}
/bigobj /MTd"
)
set
(
CMAKE_C_FLAGS_RELEASE
"
${
CMAKE_C_FLAGS_RELEASE
}
/bigobj /MT"
)
set
(
CMAKE_CXX_FLAGS_DEBUG
"
${
CMAKE_CXX_FLAGS_DEBUG
}
/bigobj /MTd"
)
set
(
CMAKE_CXX_FLAGS_RELEASE
"
${
CMAKE_CXX_FLAGS_RELEASE
}
/bigobj /MT"
)
if
(
WITH_STATIC_LIB
)
safe_set_static_flag
()
add_definitions
(
-DSTATIC_LIB
)
endif
()
else
()
set
(
CMAKE_CXX_FLAGS
"
${
CMAKE_CXX_FLAGS
}
-g -o2 -fopenmp -std=c++11"
)
set
(
CMAKE_STATIC_LIBRARY_PREFIX
""
)
endif
()
if
(
WITH_GPU
)
if
(
NOT DEFINED CUDA_LIB OR
${
CUDA_LIB
}
STREQUAL
""
)
message
(
FATAL_ERROR
"please set CUDA_LIB with -DCUDA_LIB=/path/cuda/lib64"
)
endif
()
if
(
NOT WIN32
)
if
(
NOT DEFINED CUDNN_LIB
)
message
(
FATAL_ERROR
"please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn/"
)
endif
()
endif
(
NOT WIN32
)
endif
()
if
(
NOT WIN32
)
if
(
WITH_TENSORRT AND WITH_GPU
)
include_directories
(
"
${
TENSORRT_DIR
}
/include"
)
link_directories
(
"
${
TENSORRT_DIR
}
/lib"
)
endif
()
endif
(
NOT WIN32
)
if
(
NOT WIN32
)
set
(
NGRAPH_PATH
"
${
PADDLE_DIR
}
/third_party/install/ngraph"
)
if
(
EXISTS
${
NGRAPH_PATH
}
)
include
(
GNUInstallDirs
)
include_directories
(
"
${
NGRAPH_PATH
}
/include"
)
link_directories
(
"
${
NGRAPH_PATH
}
/
${
CMAKE_INSTALL_LIBDIR
}
"
)
set
(
NGRAPH_LIB
${
NGRAPH_PATH
}
/
${
CMAKE_INSTALL_LIBDIR
}
/libngraph
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
WITH_MKL
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/mklml/include"
)
if
(
WIN32
)
set
(
MATH_LIB
${
PADDLE_DIR
}
/third_party/install/mklml/lib/mklml.lib
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5md.lib
)
else
()
set
(
MATH_LIB
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libmklml_intel
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
execute_process
(
COMMAND cp -r
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libmklml_intel
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
/usr/lib
)
endif
()
set
(
MKLDNN_PATH
"
${
PADDLE_DIR
}
/third_party/install/mkldnn"
)
if
(
EXISTS
${
MKLDNN_PATH
}
)
include_directories
(
"
${
MKLDNN_PATH
}
/include"
)
if
(
WIN32
)
set
(
MKLDNN_LIB
${
MKLDNN_PATH
}
/lib/mkldnn.lib
)
else
()
set
(
MKLDNN_LIB
${
MKLDNN_PATH
}
/lib/libmkldnn.so.0
)
endif
()
endif
()
else
()
set
(
MATH_LIB
${
PADDLE_DIR
}
/third_party/install/openblas/lib/libopenblas
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
if
(
WIN32
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/paddle/fluid/inference/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
"
)
set
(
DEPS
${
PADDLE_DIR
}
/paddle/fluid/inference/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
else
()
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
WITH_STATIC_LIB
)
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
else
()
if
(
NOT WIN32
)
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/libpaddle_fluid
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
else
()
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/paddle_fluid
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
NOT WIN32
)
set
(
DEPS
${
DEPS
}
${
MATH_LIB
}
${
MKLDNN_LIB
}
glog gflags protobuf z xxhash yaml-cpp
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
set
(
DEPS
${
DEPS
}
snappystream
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
set
(
DEPS
${
DEPS
}
snappy
)
endif
()
else
()
set
(
DEPS
${
DEPS
}
${
MATH_LIB
}
${
MKLDNN_LIB
}
glog gflags_static libprotobuf xxhash libyaml-cppmt
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/zlib/lib"
)
set
(
DEPS
${
DEPS
}
zlibstatic
)
endif
()
set
(
DEPS
${
DEPS
}
libcmt shlwapi
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
set
(
DEPS
${
DEPS
}
snappy
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
set
(
DEPS
${
DEPS
}
snappystream
)
endif
()
endif
(
NOT WIN32
)
if
(
WITH_GPU
)
if
(
NOT WIN32
)
if
(
WITH_TENSORRT
)
set
(
DEPS
${
DEPS
}
${
TENSORRT_DIR
}
/lib/libnvinfer
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
TENSORRT_DIR
}
/lib/libnvinfer_plugin
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
endif
()
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/libcudart
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
CUDNN_LIB
}
/libcudnn
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
else
()
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/cudart
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/cublas
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/cudnn
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
WITH_ENCRYPTION
)
if
(
NOT WIN32
)
include_directories
(
"
${
ENCRYPTION_DIR
}
/include"
)
link_directories
(
"
${
ENCRYPTION_DIR
}
/lib"
)
set
(
DEPS
${
DEPS
}
${
ENCRYPTION_DIR
}
/lib/libpmodel-decrypt
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
else
()
include_directories
(
"
${
ENCRYPTION_DIR
}
/include"
)
link_directories
(
"
${
ENCRYPTION_DIR
}
/lib"
)
set
(
DEPS
${
DEPS
}
${
ENCRYPTION_DIR
}
/lib/pmodel-decrypt
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
NOT WIN32
)
set
(
EXTERNAL_LIB
"-ldl -lrt -lgomp -lz -lm -lpthread"
)
set
(
DEPS
${
DEPS
}
${
EXTERNAL_LIB
}
)
endif
()
set
(
DEPS
${
DEPS
}
${
OpenCV_LIBS
}
)
add_library
(
paddlex_inference SHARED src/visualize src/transforms.cpp src/paddlex.cpp
)
ADD_DEPENDENCIES
(
paddlex_inference ext-yaml-cpp
)
target_link_libraries
(
paddlex_inference
${
DEPS
}
)
add_executable
(
meter_reader meter_reader/meter_reader.cpp meter_reader/global.cpp meter_reader/postprocess.cpp src/transforms.cpp src/paddlex.cpp src/visualize.cpp
)
ADD_DEPENDENCIES
(
meter_reader ext-yaml-cpp
)
target_link_libraries
(
meter_reader
${
DEPS
}
)
if
(
WIN32 AND WITH_MKL
)
add_custom_command
(
TARGET meter_reader POST_BUILD
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/mklml.dll ./mklml.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
)
# for encryption
if
(
EXISTS
"
${
ENCRYPTION_DIR
}
/lib/pmodel-decrypt.dll"
)
add_custom_command
(
TARGET meter_reader POST_BUILD
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
ENCRYPTION_DIR
}
/lib/pmodel-decrypt.dll ./pmodel-decrypt.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
ENCRYPTION_DIR
}
/lib/pmodel-decrypt.dll ./release/pmodel-decrypt.dll
)
endif
()
endif
()
file
(
COPY
"
${
CMAKE_SOURCE_DIR
}
/include/paddlex/visualize.h"
DESTINATION
"
${
CMAKE_BINARY_DIR
}
/include/"
)
file
(
COPY
"
${
CMAKE_SOURCE_DIR
}
/include/paddlex/config_parser.h"
DESTINATION
"
${
CMAKE_BINARY_DIR
}
/include/"
)
file
(
COPY
"
${
CMAKE_SOURCE_DIR
}
/include/paddlex/transforms.h"
DESTINATION
"
${
CMAKE_BINARY_DIR
}
/include/"
)
file
(
COPY
"
${
CMAKE_SOURCE_DIR
}
/include/paddlex/results.h"
DESTINATION
"
${
CMAKE_BINARY_DIR
}
/include/"
)
file
(
COPY
"
${
CMAKE_SOURCE_DIR
}
/include/paddlex/paddlex.h"
DESTINATION
"
${
CMAKE_BINARY_DIR
}
/include/"
)
examples/meter_reader/deploy/cpp/meter_reader/global.cpp
0 → 100644
浏览文件 @
56f76f5f
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <iostream>
#include <vector>
#include <limits>
#include <opencv2/opencv.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/core/core.hpp>
#include "meter_reader/global.h"
std
::
vector
<
int
>
IMAGE_SHAPE
=
{
1920
,
1080
};
std
::
vector
<
int
>
RESULT_SHAPE
=
{
1280
,
720
};
std
::
vector
<
int
>
METER_SHAPE
=
{
512
,
512
};
#define METER_TYPE_NUM 2
MeterConfig_T
meter_config
[
METER_TYPE_NUM
]
=
{
{
25.0
f
/
50.0
f
,
25.0
f
,
"(MPa)"
},
{
1.6
f
/
32.0
f
,
1.6
f
,
"(MPa)"
}
};
examples/meter_reader/deploy/cpp/meter_reader/global.h
0 → 100644
浏览文件 @
56f76f5f
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <vector>
typedef
struct
MeterConfig
{
float
scale_value
;
float
range
;
char
str
[
10
];
}
MeterConfig_T
;
extern
std
::
vector
<
int
>
IMAGE_SHAPE
;
extern
std
::
vector
<
int
>
RESULT_SHAPE
;
extern
std
::
vector
<
int
>
METER_SHAPE
;
extern
MeterConfig_T
meter_config
[];
#define TYPE_THRESHOLD 40
examples/meter_reader/deploy/cpp/meter_reader/meter_reader.cpp
0 → 100644
浏览文件 @
56f76f5f
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <glog/logging.h>
#include <omp.h>
#include <algorithm>
#include <chrono> // NOLINT
#include <iostream>
#include <vector>
#include <utility>
#include <limits>
#include <opencv2/opencv.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/core/core.hpp>
#include "meter_reader/global.h"
#include "meter_reader/postprocess.h"
#include "include/paddlex/paddlex.h"
#include "include/paddlex/visualize.h"
using
namespace
std
::
chrono
;
// NOLINT
DEFINE_string
(
det_model_dir
,
""
,
"Path of detection inference model"
);
DEFINE_string
(
seg_model_dir
,
""
,
"Path of segmentation inference model"
);
DEFINE_bool
(
use_gpu
,
false
,
"Infering with GPU or CPU"
);
DEFINE_bool
(
use_trt
,
false
,
"Infering with TensorRT"
);
DEFINE_bool
(
use_camera
,
false
,
"Infering with Camera"
);
DEFINE_bool
(
use_erode
,
true
,
"Eroding predicted label map"
);
DEFINE_int32
(
gpu_id
,
0
,
"GPU card id"
);
DEFINE_int32
(
camera_id
,
0
,
"Camera id"
);
DEFINE_int32
(
thread_num
,
omp_get_num_procs
(),
"Number of preprocessing threads"
);
DEFINE_int32
(
erode_kernel
,
true
,
"Eroding kernel size"
);
DEFINE_int32
(
seg_batch_size
,
2
,
"Batch size of segmentation infering"
);
DEFINE_string
(
det_key
,
""
,
"Detector key of encryption"
);
DEFINE_string
(
seg_key
,
""
,
"Segmenter model key of encryption"
);
DEFINE_string
(
image
,
""
,
"Path of test image file"
);
DEFINE_string
(
image_list
,
""
,
"Path of test image list file"
);
DEFINE_string
(
save_dir
,
"output"
,
"Path to save visualized image"
);
DEFINE_double
(
score_threshold
,
0.5
,
"Detected bbox whose score is lower than this threshlod is filtered"
);
void
predict
(
const
cv
::
Mat
&
input_image
,
PaddleX
::
Model
*
det_model
,
PaddleX
::
Model
*
seg_model
,
const
std
::
string
save_dir
,
const
std
::
string
image_path
,
const
bool
use_erode
,
const
int
erode_kernel
,
const
int
thread_num
,
const
int
seg_batch_size
,
const
double
threshold
)
{
PaddleX
::
DetResult
det_result
;
det_model
->
predict
(
input_image
,
&
det_result
);
PaddleX
::
DetResult
filter_result
;
int
num_bboxes
=
det_result
.
boxes
.
size
();
for
(
int
i
=
0
;
i
<
num_bboxes
;
++
i
)
{
double
score
=
det_result
.
boxes
[
i
].
score
;
if
(
score
>
threshold
||
score
==
threshold
)
{
PaddleX
::
Box
box
;
box
.
category_id
=
det_result
.
boxes
[
i
].
category_id
;
box
.
category
=
det_result
.
boxes
[
i
].
category
;
box
.
score
=
det_result
.
boxes
[
i
].
score
;
box
.
coordinate
=
det_result
.
boxes
[
i
].
coordinate
;
filter_result
.
boxes
.
push_back
(
std
::
move
(
box
));
}
}
int
meter_num
=
filter_result
.
boxes
.
size
();
if
(
!
meter_num
)
{
std
::
cout
<<
"Don't find any meter."
<<
std
::
endl
;
return
;
}
std
::
vector
<
std
::
vector
<
int64_t
>>
seg_result
(
meter_num
);
for
(
int
i
=
0
;
i
<
meter_num
;
i
+=
seg_batch_size
)
{
int
im_vec_size
=
std
::
min
(
static_cast
<
int
>
(
meter_num
),
i
+
seg_batch_size
);
std
::
vector
<
cv
::
Mat
>
meters_image
(
im_vec_size
-
i
);
int
batch_thread_num
=
std
::
min
(
thread_num
,
im_vec_size
-
i
);
#pragma omp parallel for num_threads(batch_thread_num)
for
(
int
j
=
i
;
j
<
im_vec_size
;
++
j
)
{
int
left
=
static_cast
<
int
>
(
filter_result
.
boxes
[
j
].
coordinate
[
0
]);
int
top
=
static_cast
<
int
>
(
filter_result
.
boxes
[
j
].
coordinate
[
1
]);
int
width
=
static_cast
<
int
>
(
filter_result
.
boxes
[
j
].
coordinate
[
2
]);
int
height
=
static_cast
<
int
>
(
filter_result
.
boxes
[
j
].
coordinate
[
3
]);
int
right
=
left
+
width
-
1
;
int
bottom
=
top
+
height
-
1
;
cv
::
Mat
sub_image
=
input_image
(
cv
::
Range
(
top
,
bottom
+
1
),
cv
::
Range
(
left
,
right
+
1
));
float
scale_x
=
static_cast
<
float
>
(
METER_SHAPE
[
0
])
/
static_cast
<
float
>
(
sub_image
.
cols
);
float
scale_y
=
static_cast
<
float
>
(
METER_SHAPE
[
1
])
/
static_cast
<
float
>
(
sub_image
.
rows
);
cv
::
resize
(
sub_image
,
sub_image
,
cv
::
Size
(),
scale_x
,
scale_y
,
cv
::
INTER_LINEAR
);
meters_image
[
j
-
i
]
=
std
::
move
(
sub_image
);
}
std
::
vector
<
PaddleX
::
SegResult
>
batch_result
(
im_vec_size
-
i
);
seg_model
->
predict
(
meters_image
,
&
batch_result
,
batch_thread_num
);
#pragma omp parallel for num_threads(batch_thread_num)
for
(
int
j
=
i
;
j
<
im_vec_size
;
++
j
)
{
if
(
use_erode
)
{
cv
::
Mat
kernel
(
4
,
4
,
CV_8U
,
cv
::
Scalar
(
1
));
std
::
vector
<
uint8_t
>
label_map
(
batch_result
[
j
-
i
].
label_map
.
data
.
begin
(),
batch_result
[
j
-
i
].
label_map
.
data
.
end
());
cv
::
Mat
mask
(
batch_result
[
j
-
i
].
label_map
.
shape
[
0
],
batch_result
[
j
-
i
].
label_map
.
shape
[
1
],
CV_8UC1
,
label_map
.
data
());
cv
::
erode
(
mask
,
mask
,
kernel
);
std
::
vector
<
int64_t
>
map
;
if
(
mask
.
isContinuous
())
{
map
.
assign
(
mask
.
data
,
mask
.
data
+
mask
.
total
()
*
mask
.
channels
());
}
else
{
for
(
int
r
=
0
;
r
<
mask
.
rows
;
r
++
)
{
map
.
insert
(
map
.
end
(),
mask
.
ptr
<
int64_t
>
(
r
),
mask
.
ptr
<
int64_t
>
(
r
)
+
mask
.
cols
*
mask
.
channels
());
}
}
seg_result
[
j
]
=
std
::
move
(
map
);
}
else
{
seg_result
[
j
]
=
std
::
move
(
batch_result
[
j
-
i
].
label_map
.
data
);
}
}
}
std
::
vector
<
READ_RESULT
>
read_results
(
meter_num
);
int
all_thread_num
=
std
::
min
(
thread_num
,
meter_num
);
read_process
(
seg_result
,
&
read_results
,
all_thread_num
);
cv
::
Mat
output_image
=
input_image
.
clone
();
for
(
int
i
=
0
;
i
<
meter_num
;
i
++
)
{
float
result
=
0
;;
if
(
read_results
[
i
].
scale_num
>
TYPE_THRESHOLD
)
{
result
=
read_results
[
i
].
scales
*
meter_config
[
0
].
scale_value
;
}
else
{
result
=
read_results
[
i
].
scales
*
meter_config
[
1
].
scale_value
;
}
std
::
cout
<<
"-- Meter "
<<
i
<<
" -- result: "
<<
result
<<
" --"
<<
std
::
endl
;
int
lx
=
static_cast
<
int
>
(
filter_result
.
boxes
[
i
].
coordinate
[
0
]);
int
ly
=
static_cast
<
int
>
(
filter_result
.
boxes
[
i
].
coordinate
[
1
]);
int
w
=
static_cast
<
int
>
(
filter_result
.
boxes
[
i
].
coordinate
[
2
]);
int
h
=
static_cast
<
int
>
(
filter_result
.
boxes
[
i
].
coordinate
[
3
]);
cv
::
Rect
bounding_box
=
cv
::
Rect
(
lx
,
ly
,
w
,
h
)
&
cv
::
Rect
(
0
,
0
,
output_image
.
cols
,
output_image
.
rows
);
if
(
w
>
0
&&
h
>
0
)
{
cv
::
Scalar
color
=
cv
::
Scalar
(
237
,
189
,
101
);
cv
::
rectangle
(
output_image
,
bounding_box
,
color
);
cv
::
rectangle
(
output_image
,
cv
::
Point2d
(
lx
,
ly
),
cv
::
Point2d
(
lx
+
w
,
ly
-
30
),
color
,
-
1
);
std
::
string
class_name
=
"Meter"
;
cv
::
putText
(
output_image
,
class_name
+
" "
+
std
::
to_string
(
result
),
cv
::
Point2d
(
lx
,
ly
-
5
),
cv
::
FONT_HERSHEY_SIMPLEX
,
1
,
cv
::
Scalar
(
255
,
255
,
255
),
2
);
}
}
cv
::
Mat
result_image
;
cv
::
Size
resize_size
(
RESULT_SHAPE
[
0
],
RESULT_SHAPE
[
1
]);
cv
::
resize
(
output_image
,
result_image
,
resize_size
,
0
,
0
,
cv
::
INTER_LINEAR
);
std
::
string
save_path
=
PaddleX
::
generate_save_path
(
save_dir
,
image_path
);
cv
::
imwrite
(
save_path
,
result_image
);
return
;
}
int
main
(
int
argc
,
char
**
argv
)
{
google
::
ParseCommandLineFlags
(
&
argc
,
&
argv
,
true
);
if
(
FLAGS_det_model_dir
==
""
)
{
std
::
cerr
<<
"--det_model_dir need to be defined"
<<
std
::
endl
;
return
-
1
;
}
if
(
FLAGS_seg_model_dir
==
""
)
{
std
::
cerr
<<
"--seg_model_dir need to be defined"
<<
std
::
endl
;
return
-
1
;
}
if
(
FLAGS_image
==
""
&
FLAGS_image_list
==
""
&
FLAGS_use_camera
==
false
)
{
std
::
cerr
<<
"--image or --image_list need to be defined "
<<
"when the camera is not been used"
<<
std
::
endl
;
return
-
1
;
}
// 加载模型
PaddleX
::
Model
det_model
;
det_model
.
Init
(
FLAGS_det_model_dir
,
FLAGS_use_gpu
,
FLAGS_use_trt
,
FLAGS_gpu_id
,
FLAGS_det_key
);
PaddleX
::
Model
seg_model
;
seg_model
.
Init
(
FLAGS_seg_model_dir
,
FLAGS_use_gpu
,
FLAGS_use_trt
,
FLAGS_gpu_id
,
FLAGS_seg_key
);
double
total_running_time_s
=
0.0
;
double
total_imread_time_s
=
0.0
;
int
imgs
=
1
;
if
(
FLAGS_use_camera
)
{
cv
::
VideoCapture
cap
(
FLAGS_camera_id
);
cap
.
set
(
CV_CAP_PROP_FRAME_WIDTH
,
IMAGE_SHAPE
[
0
]);
cap
.
set
(
CV_CAP_PROP_FRAME_HEIGHT
,
IMAGE_SHAPE
[
1
]);
if
(
!
cap
.
isOpened
())
{
std
::
cout
<<
"Open the camera unsuccessfully."
<<
std
::
endl
;
return
-
1
;
}
std
::
cout
<<
"Open the camera successfully."
<<
std
::
endl
;
while
(
1
)
{
auto
start
=
system_clock
::
now
();
cv
::
Mat
im
;
cap
>>
im
;
auto
imread_end
=
system_clock
::
now
();
std
::
cout
<<
"-------------------------"
<<
std
::
endl
;
std
::
cout
<<
"Got a camera image."
<<
std
::
endl
;
std
::
string
ext_name
=
".jpg"
;
predict
(
im
,
&
det_model
,
&
seg_model
,
FLAGS_save_dir
,
std
::
to_string
(
imgs
)
+
ext_name
,
FLAGS_use_erode
,
FLAGS_erode_kernel
,
FLAGS_thread_num
,
FLAGS_seg_batch_size
,
FLAGS_score_threshold
);
imgs
++
;
auto
imread_duration
=
duration_cast
<
microseconds
>
(
imread_end
-
start
);
total_imread_time_s
+=
static_cast
<
double
>
(
imread_duration
.
count
())
*
microseconds
::
period
::
num
/
microseconds
::
period
::
den
;
auto
end
=
system_clock
::
now
();
auto
duration
=
duration_cast
<
microseconds
>
(
end
-
start
);
total_running_time_s
+=
static_cast
<
double
>
(
duration
.
count
())
*
microseconds
::
period
::
num
/
microseconds
::
period
::
den
;
}
cap
.
release
();
cv
::
destroyAllWindows
();
}
else
{
if
(
FLAGS_image_list
!=
""
)
{
std
::
ifstream
inf
(
FLAGS_image_list
);
if
(
!
inf
)
{
std
::
cerr
<<
"Fail to open file "
<<
FLAGS_image_list
<<
std
::
endl
;
return
-
1
;
}
std
::
string
image_path
;
while
(
getline
(
inf
,
image_path
))
{
auto
start
=
system_clock
::
now
();
cv
::
Mat
im
=
cv
::
imread
(
image_path
,
1
);
imgs
++
;
auto
imread_end
=
system_clock
::
now
();
predict
(
im
,
&
det_model
,
&
seg_model
,
FLAGS_save_dir
,
image_path
,
FLAGS_use_erode
,
FLAGS_erode_kernel
,
FLAGS_thread_num
,
FLAGS_seg_batch_size
,
FLAGS_score_threshold
);
auto
imread_duration
=
duration_cast
<
microseconds
>
(
imread_end
-
start
);
total_imread_time_s
+=
static_cast
<
double
>
(
imread_duration
.
count
())
*
microseconds
::
period
::
num
/
microseconds
::
period
::
den
;
auto
end
=
system_clock
::
now
();
auto
duration
=
duration_cast
<
microseconds
>
(
end
-
start
);
total_running_time_s
+=
static_cast
<
double
>
(
duration
.
count
())
*
microseconds
::
period
::
num
/
microseconds
::
period
::
den
;
}
}
else
{
auto
start
=
system_clock
::
now
();
cv
::
Mat
im
=
cv
::
imread
(
FLAGS_image
,
1
);
auto
imread_end
=
system_clock
::
now
();
predict
(
im
,
&
det_model
,
&
seg_model
,
FLAGS_save_dir
,
FLAGS_image
,
FLAGS_use_erode
,
FLAGS_erode_kernel
,
FLAGS_thread_num
,
FLAGS_seg_batch_size
,
FLAGS_score_threshold
);
auto
imread_duration
=
duration_cast
<
microseconds
>
(
imread_end
-
start
);
total_imread_time_s
+=
static_cast
<
double
>
(
imread_duration
.
count
())
*
microseconds
::
period
::
num
/
microseconds
::
period
::
den
;
auto
end
=
system_clock
::
now
();
auto
duration
=
duration_cast
<
microseconds
>
(
end
-
start
);
total_running_time_s
+=
static_cast
<
double
>
(
duration
.
count
())
*
microseconds
::
period
::
num
/
microseconds
::
period
::
den
;
}
}
std
::
cout
<<
"Total running time: "
<<
total_running_time_s
<<
" s, average running time: "
<<
total_running_time_s
/
imgs
<<
" s/img, total read img time: "
<<
total_imread_time_s
<<
" s, average read time: "
<<
total_imread_time_s
/
imgs
<<
" s/img"
<<
std
::
endl
;
return
0
;
}
examples/meter_reader/deploy/cpp/meter_reader/postprocess.cpp
0 → 100644
浏览文件 @
56f76f5f
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <iostream>
#include <vector>
#include <utility>
#include <limits>
#include <cmath>
#include <chrono> // NOLINT
#include <opencv2/opencv.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/core/core.hpp>
#include "meter_reader/global.h"
#include "meter_reader/postprocess.h"
using
namespace
std
::
chrono
;
// NOLINT
#define SEG_IMAGE_SIZE 512
#define LINE_HEIGHT 120
#define LINE_WIDTH 1570
#define CIRCLE_RADIUS 250
const
float
pi
=
3.1415926536
f
;
const
int
circle_center
[]
=
{
256
,
256
};
void
creat_line_image
(
const
std
::
vector
<
int64_t
>
&
seg_image
,
std
::
vector
<
unsigned
char
>
*
output
)
{
float
theta
;
int
rho
;
int
image_x
;
int
image_y
;
for
(
int
row
=
0
;
row
<
LINE_HEIGHT
;
row
++
)
{
for
(
int
col
=
0
;
col
<
LINE_WIDTH
;
col
++
)
{
theta
=
pi
*
2
/
LINE_WIDTH
*
(
col
+
1
);
rho
=
CIRCLE_RADIUS
-
row
-
1
;
image_x
=
static_cast
<
int
>
(
circle_center
[
0
]
+
rho
*
cos
(
theta
)
+
0.5
);
image_y
=
static_cast
<
int
>
(
circle_center
[
1
]
-
rho
*
sin
(
theta
)
+
0.5
);
(
*
output
)[
row
*
LINE_WIDTH
+
col
]
=
seg_image
[
image_x
*
SEG_IMAGE_SIZE
+
image_y
];
}
}
return
;
}
void
convert_1D_data
(
const
std
::
vector
<
unsigned
char
>
&
line_image
,
std
::
vector
<
unsigned
int
>
*
scale_data
,
std
::
vector
<
unsigned
int
>
*
pointer_data
)
{
for
(
int
col
=
0
;
col
<
LINE_WIDTH
;
col
++
)
{
(
*
scale_data
)[
col
]
=
0
;
(
*
pointer_data
)[
col
]
=
0
;
for
(
int
row
=
0
;
row
<
LINE_HEIGHT
;
row
++
)
{
if
(
line_image
[
row
*
LINE_WIDTH
+
col
]
==
1
)
{
(
*
pointer_data
)[
col
]
++
;
}
else
if
(
line_image
[
row
*
LINE_WIDTH
+
col
]
==
2
)
{
(
*
scale_data
)[
col
]
++
;
}
}
}
return
;
}
void
scale_mean_filtration
(
const
std
::
vector
<
unsigned
int
>
&
scale_data
,
std
::
vector
<
unsigned
int
>
*
scale_mean_data
)
{
int
sum
=
0
;
float
mean
=
0
;
int
size
=
scale_data
.
size
();
for
(
int
i
=
0
;
i
<
size
;
i
++
)
{
sum
=
sum
+
scale_data
[
i
];
}
mean
=
static_cast
<
float
>
(
sum
)
/
static_cast
<
float
>
(
size
);
for
(
int
i
=
0
;
i
<
size
;
i
++
)
{
if
(
static_cast
<
float
>
(
scale_data
[
i
])
>=
mean
)
{
(
*
scale_mean_data
)[
i
]
=
scale_data
[
i
];
}
}
return
;
}
void
get_meter_reader
(
const
std
::
vector
<
unsigned
int
>
&
scale
,
const
std
::
vector
<
unsigned
int
>
&
pointer
,
READ_RESULT
*
result
)
{
std
::
vector
<
float
>
scale_location
;
float
one_scale_location
=
0
;
bool
scale_flag
=
0
;
unsigned
int
one_scale_start
=
0
;
unsigned
int
one_scale_end
=
0
;
float
pointer_location
=
0
;
bool
pointer_flag
=
0
;
unsigned
int
one_pointer_start
=
0
;
unsigned
int
one_pointer_end
=
0
;
for
(
int
i
=
0
;
i
<
LINE_WIDTH
;
i
++
)
{
// scale location
if
(
scale
[
i
]
>
0
&&
scale
[
i
+
1
]
>
0
)
{
if
(
scale_flag
==
0
)
{
one_scale_start
=
i
;
scale_flag
=
1
;
}
}
if
(
scale_flag
==
1
)
{
if
(
scale
[
i
]
==
0
&&
scale
[
i
+
1
]
==
0
)
{
one_scale_end
=
i
-
1
;
one_scale_location
=
(
one_scale_start
+
one_scale_end
)
/
2.
;
scale_location
.
push_back
(
one_scale_location
);
one_scale_start
=
0
;
one_scale_end
=
0
;
scale_flag
=
0
;
}
}
// pointer location
if
(
pointer
[
i
]
>
0
&&
pointer
[
i
+
1
]
>
0
)
{
if
(
pointer_flag
==
0
)
{
one_pointer_start
=
i
;
pointer_flag
=
1
;
}
}
if
(
pointer_flag
==
1
)
{
if
((
pointer
[
i
]
==
0
)
&&
(
pointer
[
i
+
1
]
==
0
))
{
one_pointer_end
=
i
-
1
;
pointer_location
=
(
one_pointer_start
+
one_pointer_end
)
/
2.
;
one_pointer_start
=
0
;
one_pointer_end
=
0
;
pointer_flag
=
0
;
}
}
}
int
scale_num
=
scale_location
.
size
();
result
->
scale_num
=
scale_num
;
result
->
scales
=
-
1
;
result
->
ratio
=
-
1
;
if
(
scale_num
>
0
)
{
for
(
int
i
=
0
;
i
<
scale_num
-
1
;
i
++
)
{
if
(
scale_location
[
i
]
<=
pointer_location
&&
pointer_location
<
scale_location
[
i
+
1
])
{
result
->
scales
=
i
+
1
+
(
pointer_location
-
scale_location
[
i
])
/
(
scale_location
[
i
+
1
]
-
scale_location
[
i
]
+
1e-05
);
}
}
result
->
ratio
=
(
pointer_location
-
scale_location
[
0
])
/
(
scale_location
[
scale_num
-
1
]
-
scale_location
[
0
]
+
1e-05
);
}
return
;
}
void
read_process
(
const
std
::
vector
<
std
::
vector
<
int64_t
>>
&
seg_image
,
std
::
vector
<
READ_RESULT
>
*
read_results
,
const
int
thread_num
)
{
int
read_num
=
seg_image
.
size
();
#pragma omp parallel for num_threads(thread_num)
for
(
int
i_read
=
0
;
i_read
<
read_num
;
i_read
++
)
{
std
::
vector
<
unsigned
char
>
line_result
(
LINE_WIDTH
*
LINE_HEIGHT
,
0
);
creat_line_image
(
seg_image
[
i_read
],
&
line_result
);
std
::
vector
<
unsigned
int
>
scale_data
(
LINE_WIDTH
);
std
::
vector
<
unsigned
int
>
pointer_data
(
LINE_WIDTH
);
convert_1D_data
(
line_result
,
&
scale_data
,
&
pointer_data
);
std
::
vector
<
unsigned
int
>
scale_mean_data
(
LINE_WIDTH
);
scale_mean_filtration
(
scale_data
,
&
scale_mean_data
);
READ_RESULT
result
;
get_meter_reader
(
scale_mean_data
,
pointer_data
,
&
result
);
(
*
read_results
)[
i_read
]
=
std
::
move
(
result
);
}
return
;
}
examples/meter_reader/deploy/cpp/meter_reader/postprocess.h
0 → 100644
浏览文件 @
56f76f5f
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <vector>
struct
READ_RESULT
{
int
scale_num
;
float
scales
;
float
ratio
;
};
void
creat_line_image
(
const
std
::
vector
<
int64_t
>
&
seg_image
,
std
::
vector
<
unsigned
char
>
*
output
);
void
convert_1D_data
(
const
std
::
vector
<
unsigned
char
>
&
line_image
,
std
::
vector
<
unsigned
int
>
*
scale_data
,
std
::
vector
<
unsigned
int
>
*
pointer_data
);
void
scale_mean_filtration
(
const
std
::
vector
<
unsigned
int
>
&
scale_data
,
std
::
vector
<
unsigned
int
>
*
scale_mean_data
);
void
get_meter_reader
(
const
std
::
vector
<
unsigned
int
>
&
scale
,
const
std
::
vector
<
unsigned
int
>
&
pointer
,
READ_RESULT
*
result
);
void
read_process
(
const
std
::
vector
<
std
::
vector
<
int64_t
>>
&
seg_image
,
std
::
vector
<
READ_RESULT
>
*
read_results
,
const
int
thread_num
);
examples/meter_reader/deploy/python/reader_deploy.py
0 → 100644
浏览文件 @
56f76f5f
# coding: utf8
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
os
import
os.path
as
osp
import
numpy
as
np
import
math
import
cv2
import
argparse
from
paddlex.seg
import
transforms
import
paddlex
as
pdx
METER_SHAPE
=
512
CIRCLE_CENTER
=
[
256
,
256
]
CIRCLE_RADIUS
=
250
PI
=
3.1415926536
LINE_HEIGHT
=
120
LINE_WIDTH
=
1570
TYPE_THRESHOLD
=
40
METER_CONFIG
=
[{
'scale_value'
:
25.0
/
50.0
,
'range'
:
25.0
,
'unit'
:
"(MPa)"
},
{
'scale_value'
:
1.6
/
32.0
,
'range'
:
1.6
,
'unit'
:
"(MPa)"
}]
def
parse_args
():
parser
=
argparse
.
ArgumentParser
(
description
=
'Meter Reader Infering'
)
parser
.
add_argument
(
'--detector_dir'
,
dest
=
'detector_dir'
,
help
=
'The directory of models to do detection'
,
type
=
str
)
parser
.
add_argument
(
'--segmenter_dir'
,
dest
=
'segmenter_dir'
,
help
=
'The directory of models to do segmentation'
,
type
=
str
)
parser
.
add_argument
(
'--image_dir'
,
dest
=
'image_dir'
,
help
=
'The directory of images to be infered'
,
type
=
str
,
default
=
None
)
parser
.
add_argument
(
'--image'
,
dest
=
'image'
,
help
=
'The image to be infered'
,
type
=
str
,
default
=
None
)
parser
.
add_argument
(
'--use_camera'
,
dest
=
'use_camera'
,
help
=
'Whether use camera or not'
,
action
=
'store_true'
)
parser
.
add_argument
(
'--camera_id'
,
dest
=
'camera_id'
,
type
=
int
,
help
=
'The camera id'
,
default
=
0
)
parser
.
add_argument
(
'--use_erode'
,
dest
=
'use_erode'
,
help
=
'Whether erode the predicted lable map'
,
action
=
'store_true'
)
parser
.
add_argument
(
'--erode_kernel'
,
dest
=
'erode_kernel'
,
help
=
'Erode kernel size'
,
type
=
int
,
default
=
4
)
parser
.
add_argument
(
'--save_dir'
,
dest
=
'save_dir'
,
help
=
'The directory for saving the inference results'
,
type
=
str
,
default
=
'./output/result'
)
parser
.
add_argument
(
'--score_threshold'
,
dest
=
'score_threshold'
,
help
=
"Detected bbox whose score is lower than this threshlod is filtered"
,
type
=
float
,
default
=
0.5
)
parser
.
add_argument
(
'--seg_batch_size'
,
dest
=
'seg_batch_size'
,
help
=
"Segmentation batch size"
,
type
=
int
,
default
=
2
)
parser
.
add_argument
(
'--seg_thread_num'
,
dest
=
'seg_thread_num'
,
help
=
"Thread number of segmentation preprocess"
,
type
=
int
,
default
=
2
)
return
parser
.
parse_args
()
def
is_pic
(
img_name
):
valid_suffix
=
[
'JPEG'
,
'jpeg'
,
'JPG'
,
'jpg'
,
'BMP'
,
'bmp'
,
'PNG'
,
'png'
]
suffix
=
img_name
.
split
(
'.'
)[
-
1
]
if
suffix
not
in
valid_suffix
:
return
False
return
True
class
MeterReader
:
def
__init__
(
self
,
detector_dir
,
segmenter_dir
):
if
not
osp
.
exists
(
detector_dir
):
raise
Exception
(
"Model path {} does not exist"
.
format
(
detector_dir
))
if
not
osp
.
exists
(
segmenter_dir
):
raise
Exception
(
"Model path {} does not exist"
.
format
(
segmenter_dir
))
self
.
detector
=
pdx
.
deploy
.
Predictor
(
detector_dir
)
self
.
segmenter
=
pdx
.
deploy
.
Predictor
(
segmenter_dir
)
# Because we will resize images with (METER_SHAPE, METER_SHAPE) before fed into the segmenter,
# here the transform is composed of normalization only.
self
.
seg_transforms
=
transforms
.
Compose
([
transforms
.
Normalize
()])
def
predict
(
self
,
im_file
,
save_dir
=
'./'
,
use_erode
=
True
,
erode_kernel
=
4
,
score_threshold
=
0.5
,
seg_batch_size
=
2
,
seg_thread_num
=
2
):
if
isinstance
(
im_file
,
str
):
im
=
cv2
.
imread
(
im_file
).
astype
(
'float32'
)
else
:
im
=
im_file
.
copy
()
# Get detection results
det_results
=
self
.
detector
.
predict
(
im
)
# Filter bbox whose score is lower than score_threshold
filtered_results
=
list
()
for
res
in
det_results
:
if
res
[
'score'
]
>
score_threshold
:
filtered_results
.
append
(
res
)
resized_meters
=
list
()
for
res
in
filtered_results
:
# Crop the bbox area
xmin
,
ymin
,
w
,
h
=
res
[
'bbox'
]
xmin
=
max
(
0
,
int
(
xmin
))
ymin
=
max
(
0
,
int
(
ymin
))
xmax
=
min
(
im
.
shape
[
1
],
int
(
xmin
+
w
-
1
))
ymax
=
min
(
im
.
shape
[
0
],
int
(
ymin
+
h
-
1
))
sub_image
=
im
[
ymin
:(
ymax
+
1
),
xmin
:(
xmax
+
1
),
:]
# Resize the image with shape (METER_SHAPE, METER_SHAPE)
meter_shape
=
sub_image
.
shape
scale_x
=
float
(
METER_SHAPE
)
/
float
(
meter_shape
[
1
])
scale_y
=
float
(
METER_SHAPE
)
/
float
(
meter_shape
[
0
])
meter_meter
=
cv2
.
resize
(
sub_image
,
None
,
None
,
fx
=
scale_x
,
fy
=
scale_y
,
interpolation
=
cv2
.
INTER_LINEAR
)
meter_meter
=
meter_meter
.
astype
(
'float32'
)
resized_meters
.
append
(
meter_meter
)
meter_num
=
len
(
resized_meters
)
seg_results
=
list
()
for
i
in
range
(
0
,
meter_num
,
seg_batch_size
):
im_size
=
min
(
meter_num
,
i
+
seg_batch_size
)
meter_images
=
list
()
for
j
in
range
(
i
,
im_size
):
meter_images
.
append
(
resized_meters
[
j
-
i
])
result
=
self
.
segmenter
.
batch_predict
(
transforms
=
self
.
seg_transforms
,
img_file_list
=
meter_images
,
thread_num
=
seg_thread_num
)
if
use_erode
:
kernel
=
np
.
ones
((
erode_kernel
,
erode_kernel
),
np
.
uint8
)
for
i
in
range
(
len
(
result
)):
result
[
i
][
'label_map'
]
=
cv2
.
erode
(
result
[
i
][
'label_map'
],
kernel
)
seg_results
.
extend
(
result
)
results
=
list
()
for
i
,
seg_result
in
enumerate
(
seg_results
):
result
=
self
.
read_process
(
seg_result
[
'label_map'
])
results
.
append
(
result
)
meter_values
=
list
()
for
i
,
result
in
enumerate
(
results
):
if
result
[
'scale_num'
]
>
TYPE_THRESHOLD
:
value
=
result
[
'scales'
]
*
METER_CONFIG
[
0
][
'scale_value'
]
else
:
value
=
result
[
'scales'
]
*
METER_CONFIG
[
1
][
'scale_value'
]
meter_values
.
append
(
value
)
print
(
"-- Meter {} -- result: {} --
\n
"
.
format
(
i
,
value
))
# visualize the results
visual_results
=
list
()
for
i
,
res
in
enumerate
(
filtered_results
):
# Use `score` to represent the meter value
res
[
'score'
]
=
meter_values
[
i
]
visual_results
.
append
(
res
)
pdx
.
det
.
visualize
(
im_file
,
visual_results
,
-
1
,
save_dir
=
save_dir
)
def
read_process
(
self
,
label_maps
):
# Convert the circular meter into rectangular meter
line_images
=
self
.
creat_line_image
(
label_maps
)
# Convert the 2d meter into 1d meter
scale_data
,
pointer_data
=
self
.
convert_1d_data
(
line_images
)
# Fliter scale data whose value is lower than the mean value
self
.
scale_mean_filtration
(
scale_data
)
# Get scale_num, scales and ratio of meters
result
=
self
.
get_meter_reader
(
scale_data
,
pointer_data
)
return
result
def
creat_line_image
(
self
,
meter_image
):
line_image
=
np
.
zeros
((
LINE_HEIGHT
,
LINE_WIDTH
),
dtype
=
np
.
uint8
)
for
row
in
range
(
LINE_HEIGHT
):
for
col
in
range
(
LINE_WIDTH
):
theta
=
PI
*
2
/
LINE_WIDTH
*
(
col
+
1
)
rho
=
CIRCLE_RADIUS
-
row
-
1
x
=
int
(
CIRCLE_CENTER
[
0
]
+
rho
*
math
.
cos
(
theta
)
+
0.5
)
y
=
int
(
CIRCLE_CENTER
[
1
]
-
rho
*
math
.
sin
(
theta
)
+
0.5
)
line_image
[
row
,
col
]
=
meter_image
[
x
,
y
]
return
line_image
def
convert_1d_data
(
self
,
meter_image
):
scale_data
=
np
.
zeros
((
LINE_WIDTH
),
dtype
=
np
.
uint8
)
pointer_data
=
np
.
zeros
((
LINE_WIDTH
),
dtype
=
np
.
uint8
)
for
col
in
range
(
LINE_WIDTH
):
for
row
in
range
(
LINE_HEIGHT
):
if
meter_image
[
row
,
col
]
==
1
:
pointer_data
[
col
]
+=
1
elif
meter_image
[
row
,
col
]
==
2
:
scale_data
[
col
]
+=
1
return
scale_data
,
pointer_data
def
scale_mean_filtration
(
self
,
scale_data
):
mean_data
=
np
.
mean
(
scale_data
)
for
col
in
range
(
LINE_WIDTH
):
if
scale_data
[
col
]
<
mean_data
:
scale_data
[
col
]
=
0
def
get_meter_reader
(
self
,
scale_data
,
pointer_data
):
scale_flag
=
False
pointer_flag
=
False
one_scale_start
=
0
one_scale_end
=
0
one_pointer_start
=
0
one_pointer_end
=
0
scale_location
=
list
()
pointer_location
=
0
for
i
in
range
(
LINE_WIDTH
-
1
):
if
scale_data
[
i
]
>
0
and
scale_data
[
i
+
1
]
>
0
:
if
scale_flag
==
False
:
one_scale_start
=
i
scale_flag
=
True
if
scale_flag
:
if
scale_data
[
i
]
==
0
and
scale_data
[
i
+
1
]
==
0
:
one_scale_end
=
i
-
1
one_scale_location
=
(
one_scale_start
+
one_scale_end
)
/
2
scale_location
.
append
(
one_scale_location
)
one_scale_start
=
0
one_scale_end
=
0
scale_flag
=
False
if
pointer_data
[
i
]
>
0
and
pointer_data
[
i
+
1
]
>
0
:
if
pointer_flag
==
False
:
one_pointer_start
=
i
pointer_flag
=
True
if
pointer_flag
:
if
pointer_data
[
i
]
==
0
and
pointer_data
[
i
+
1
]
==
0
:
one_pointer_end
=
i
-
1
pointer_location
=
(
one_pointer_start
+
one_pointer_end
)
/
2
one_pointer_start
=
0
one_pointer_end
=
0
pointer_flag
=
False
scale_num
=
len
(
scale_location
)
scales
=
-
1
ratio
=
-
1
if
scale_num
>
0
:
for
i
in
range
(
scale_num
-
1
):
if
scale_location
[
i
]
<=
pointer_location
and
pointer_location
<
scale_location
[
i
+
1
]:
scales
=
i
+
(
pointer_location
-
scale_location
[
i
])
/
(
scale_location
[
i
+
1
]
-
scale_location
[
i
]
+
1e-05
)
+
1
ratio
=
(
pointer_location
-
scale_location
[
0
])
/
(
scale_location
[
scale_num
-
1
]
-
scale_location
[
0
]
+
1e-05
)
result
=
{
'scale_num'
:
scale_num
,
'scales'
:
scales
,
'ratio'
:
ratio
}
return
result
def
infer
(
args
):
image_lists
=
list
()
if
args
.
image
is
not
None
:
if
not
osp
.
exists
(
args
.
image
):
raise
Exception
(
"Image {} does not exist."
.
format
(
args
.
image
))
if
not
is_pic
(
args
.
image
):
raise
Exception
(
"{} is not a picture."
.
format
(
args
.
image
))
image_lists
.
append
(
args
.
image
)
elif
args
.
image_dir
is
not
None
:
if
not
osp
.
exists
(
args
.
image_dir
):
raise
Exception
(
"Directory {} does not exist."
.
format
(
args
.
image_dir
))
for
im_file
in
os
.
listdir
(
args
.
image_dir
):
if
not
is_pic
(
im_file
):
continue
im_file
=
osp
.
join
(
args
.
image_dir
,
im_file
)
image_lists
.
append
(
im_file
)
meter_reader
=
MeterReader
(
args
.
detector_dir
,
args
.
segmenter_dir
)
if
len
(
image_lists
)
>
0
:
for
im_file
in
image_lists
:
meter_reader
.
predict
(
im_file
,
args
.
save_dir
,
args
.
use_erode
,
args
.
erode_kernel
,
args
.
score_threshold
,
args
.
seg_batch_size
,
args
.
seg_thread_num
)
elif
args
.
with_camera
:
cap_video
=
cv2
.
VideoCapture
(
args
.
camera_id
)
if
not
cap_video
.
isOpened
():
raise
Exception
(
"Error opening video stream, please make sure the camera is working"
)
while
cap_video
.
isOpened
():
ret
,
frame
=
cap_video
.
read
()
if
ret
:
meter_reader
.
predict
(
frame
,
args
.
save_dir
,
args
.
use_erode
,
args
.
erode_kernel
,
args
.
score_threshold
,
args
.
seg_batch_size
,
args
.
seg_thread_num
)
if
cv2
.
waitKey
(
1
)
&
0xFF
==
ord
(
'q'
):
break
else
:
break
cap_video
.
release
()
if
__name__
==
'__main__'
:
args
=
parse_args
()
infer
(
args
)
examples/meter_reader/image/MeterReader_Architecture.jpg
0 → 100644
浏览文件 @
56f76f5f
206.2 KB
examples/meter_reader/reader_infer.py
0 → 100644
浏览文件 @
56f76f5f
# coding: utf8
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
os
import
os.path
as
osp
import
numpy
as
np
import
math
import
cv2
import
argparse
from
paddlex.seg
import
transforms
import
paddlex
as
pdx
METER_SHAPE
=
512
CIRCLE_CENTER
=
[
256
,
256
]
CIRCLE_RADIUS
=
250
PI
=
3.1415926536
LINE_HEIGHT
=
120
LINE_WIDTH
=
1570
TYPE_THRESHOLD
=
40
METER_CONFIG
=
[{
'scale_value'
:
25.0
/
50.0
,
'range'
:
25.0
,
'unit'
:
"(MPa)"
},
{
'scale_value'
:
1.6
/
32.0
,
'range'
:
1.6
,
'unit'
:
"(MPa)"
}]
def
parse_args
():
parser
=
argparse
.
ArgumentParser
(
description
=
'Meter Reader Infering'
)
parser
.
add_argument
(
'--detector_dir'
,
dest
=
'detector_dir'
,
help
=
'The directory of models to do detection'
,
type
=
str
)
parser
.
add_argument
(
'--segmenter_dir'
,
dest
=
'segmenter_dir'
,
help
=
'The directory of models to do segmentation'
,
type
=
str
)
parser
.
add_argument
(
'--image_dir'
,
dest
=
'image_dir'
,
help
=
'The directory of images to be infered'
,
type
=
str
,
default
=
None
)
parser
.
add_argument
(
'--image'
,
dest
=
'image'
,
help
=
'The image to be infered'
,
type
=
str
,
default
=
None
)
parser
.
add_argument
(
'--use_camera'
,
dest
=
'use_camera'
,
help
=
'Whether use camera or not'
,
action
=
'store_true'
)
parser
.
add_argument
(
'--camera_id'
,
dest
=
'camera_id'
,
type
=
int
,
help
=
'The camera id'
,
default
=
0
)
parser
.
add_argument
(
'--use_erode'
,
dest
=
'use_erode'
,
help
=
'Whether erode the predicted lable map'
,
action
=
'store_true'
)
parser
.
add_argument
(
'--erode_kernel'
,
dest
=
'erode_kernel'
,
help
=
'Erode kernel size'
,
type
=
int
,
default
=
4
)
parser
.
add_argument
(
'--save_dir'
,
dest
=
'save_dir'
,
help
=
'The directory for saving the inference results'
,
type
=
str
,
default
=
'./output/result'
)
parser
.
add_argument
(
'--score_threshold'
,
dest
=
'score_threshold'
,
help
=
"Detected bbox whose score is lower than this threshlod is filtered"
,
type
=
float
,
default
=
0.5
)
parser
.
add_argument
(
'--seg_batch_size'
,
dest
=
'seg_batch_size'
,
help
=
"Segmentation batch size"
,
type
=
int
,
default
=
2
)
parser
.
add_argument
(
'--seg_thread_num'
,
dest
=
'seg_thread_num'
,
help
=
"Thread number of segmentation preprocess"
,
type
=
int
,
default
=
2
)
return
parser
.
parse_args
()
def
is_pic
(
img_name
):
valid_suffix
=
[
'JPEG'
,
'jpeg'
,
'JPG'
,
'jpg'
,
'BMP'
,
'bmp'
,
'PNG'
,
'png'
]
suffix
=
img_name
.
split
(
'.'
)[
-
1
]
if
suffix
not
in
valid_suffix
:
return
False
return
True
class
MeterReader
:
def
__init__
(
self
,
detector_dir
,
segmenter_dir
):
if
not
osp
.
exists
(
detector_dir
):
raise
Exception
(
"Model path {} does not exist"
.
format
(
detector_dir
))
if
not
osp
.
exists
(
segmenter_dir
):
raise
Exception
(
"Model path {} does not exist"
.
format
(
segmenter_dir
))
self
.
detector
=
pdx
.
load_model
(
detector_dir
)
self
.
segmenter
=
pdx
.
load_model
(
segmenter_dir
)
# Because we will resize images with (METER_SHAPE, METER_SHAPE) before fed into the segmenter,
# here the transform is composed of normalization only.
self
.
seg_transforms
=
transforms
.
Compose
([
transforms
.
Normalize
()])
def
predict
(
self
,
im_file
,
save_dir
=
'./'
,
use_erode
=
True
,
erode_kernel
=
4
,
score_threshold
=
0.5
,
seg_batch_size
=
2
,
seg_thread_num
=
2
):
if
isinstance
(
im_file
,
str
):
im
=
cv2
.
imread
(
im_file
).
astype
(
'float32'
)
else
:
im
=
im_file
.
copy
()
# Get detection results
det_results
=
self
.
detector
.
predict
(
im
)
# Filter bbox whose score is lower than score_threshold
filtered_results
=
list
()
for
res
in
det_results
:
if
res
[
'score'
]
>
score_threshold
:
filtered_results
.
append
(
res
)
resized_meters
=
list
()
for
res
in
filtered_results
:
# Crop the bbox area
xmin
,
ymin
,
w
,
h
=
res
[
'bbox'
]
xmin
=
max
(
0
,
int
(
xmin
))
ymin
=
max
(
0
,
int
(
ymin
))
xmax
=
min
(
im
.
shape
[
1
],
int
(
xmin
+
w
-
1
))
ymax
=
min
(
im
.
shape
[
0
],
int
(
ymin
+
h
-
1
))
sub_image
=
im
[
ymin
:(
ymax
+
1
),
xmin
:(
xmax
+
1
),
:]
# Resize the image with shape (METER_SHAPE, METER_SHAPE)
meter_shape
=
sub_image
.
shape
scale_x
=
float
(
METER_SHAPE
)
/
float
(
meter_shape
[
1
])
scale_y
=
float
(
METER_SHAPE
)
/
float
(
meter_shape
[
0
])
meter_meter
=
cv2
.
resize
(
sub_image
,
None
,
None
,
fx
=
scale_x
,
fy
=
scale_y
,
interpolation
=
cv2
.
INTER_LINEAR
)
meter_meter
=
meter_meter
.
astype
(
'float32'
)
resized_meters
.
append
(
meter_meter
)
meter_num
=
len
(
resized_meters
)
seg_results
=
list
()
for
i
in
range
(
0
,
meter_num
,
seg_batch_size
):
im_size
=
min
(
meter_num
,
i
+
seg_batch_size
)
meter_images
=
list
()
for
j
in
range
(
i
,
im_size
):
meter_images
.
append
(
resized_meters
[
j
-
i
])
result
=
self
.
segmenter
.
batch_predict
(
transforms
=
self
.
seg_transforms
,
img_file_list
=
meter_images
,
thread_num
=
seg_thread_num
)
if
use_erode
:
kernel
=
np
.
ones
((
erode_kernel
,
erode_kernel
),
np
.
uint8
)
for
i
in
range
(
len
(
result
)):
result
[
i
][
'label_map'
]
=
cv2
.
erode
(
result
[
i
][
'label_map'
],
kernel
)
seg_results
.
extend
(
result
)
results
=
list
()
for
i
,
seg_result
in
enumerate
(
seg_results
):
result
=
self
.
read_process
(
seg_result
[
'label_map'
])
results
.
append
(
result
)
meter_values
=
list
()
for
i
,
result
in
enumerate
(
results
):
if
result
[
'scale_num'
]
>
TYPE_THRESHOLD
:
value
=
result
[
'scales'
]
*
METER_CONFIG
[
0
][
'scale_value'
]
else
:
value
=
result
[
'scales'
]
*
METER_CONFIG
[
1
][
'scale_value'
]
meter_values
.
append
(
value
)
print
(
"-- Meter {} -- result: {} --
\n
"
.
format
(
i
,
value
))
# visualize the results
visual_results
=
list
()
for
i
,
res
in
enumerate
(
filtered_results
):
# Use `score` to represent the meter value
res
[
'score'
]
=
meter_values
[
i
]
visual_results
.
append
(
res
)
pdx
.
det
.
visualize
(
im_file
,
visual_results
,
-
1
,
save_dir
=
save_dir
)
def
read_process
(
self
,
label_maps
):
# Convert the circular meter into rectangular meter
line_images
=
self
.
creat_line_image
(
label_maps
)
# Convert the 2d meter into 1d meter
scale_data
,
pointer_data
=
self
.
convert_1d_data
(
line_images
)
# Fliter scale data whose value is lower than the mean value
self
.
scale_mean_filtration
(
scale_data
)
# Get scale_num, scales and ratio of meters
result
=
self
.
get_meter_reader
(
scale_data
,
pointer_data
)
return
result
def
creat_line_image
(
self
,
meter_image
):
line_image
=
np
.
zeros
((
LINE_HEIGHT
,
LINE_WIDTH
),
dtype
=
np
.
uint8
)
for
row
in
range
(
LINE_HEIGHT
):
for
col
in
range
(
LINE_WIDTH
):
theta
=
PI
*
2
/
LINE_WIDTH
*
(
col
+
1
)
rho
=
CIRCLE_RADIUS
-
row
-
1
x
=
int
(
CIRCLE_CENTER
[
0
]
+
rho
*
math
.
cos
(
theta
)
+
0.5
)
y
=
int
(
CIRCLE_CENTER
[
1
]
-
rho
*
math
.
sin
(
theta
)
+
0.5
)
line_image
[
row
,
col
]
=
meter_image
[
x
,
y
]
return
line_image
def
convert_1d_data
(
self
,
meter_image
):
scale_data
=
np
.
zeros
((
LINE_WIDTH
),
dtype
=
np
.
uint8
)
pointer_data
=
np
.
zeros
((
LINE_WIDTH
),
dtype
=
np
.
uint8
)
for
col
in
range
(
LINE_WIDTH
):
for
row
in
range
(
LINE_HEIGHT
):
if
meter_image
[
row
,
col
]
==
1
:
pointer_data
[
col
]
+=
1
elif
meter_image
[
row
,
col
]
==
2
:
scale_data
[
col
]
+=
1
return
scale_data
,
pointer_data
def
scale_mean_filtration
(
self
,
scale_data
):
mean_data
=
np
.
mean
(
scale_data
)
for
col
in
range
(
LINE_WIDTH
):
if
scale_data
[
col
]
<
mean_data
:
scale_data
[
col
]
=
0
def
get_meter_reader
(
self
,
scale_data
,
pointer_data
):
scale_flag
=
False
pointer_flag
=
False
one_scale_start
=
0
one_scale_end
=
0
one_pointer_start
=
0
one_pointer_end
=
0
scale_location
=
list
()
pointer_location
=
0
for
i
in
range
(
LINE_WIDTH
-
1
):
if
scale_data
[
i
]
>
0
and
scale_data
[
i
+
1
]
>
0
:
if
scale_flag
==
False
:
one_scale_start
=
i
scale_flag
=
True
if
scale_flag
:
if
scale_data
[
i
]
==
0
and
scale_data
[
i
+
1
]
==
0
:
one_scale_end
=
i
-
1
one_scale_location
=
(
one_scale_start
+
one_scale_end
)
/
2
scale_location
.
append
(
one_scale_location
)
one_scale_start
=
0
one_scale_end
=
0
scale_flag
=
False
if
pointer_data
[
i
]
>
0
and
pointer_data
[
i
+
1
]
>
0
:
if
pointer_flag
==
False
:
one_pointer_start
=
i
pointer_flag
=
True
if
pointer_flag
:
if
pointer_data
[
i
]
==
0
and
pointer_data
[
i
+
1
]
==
0
:
one_pointer_end
=
i
-
1
pointer_location
=
(
one_pointer_start
+
one_pointer_end
)
/
2
one_pointer_start
=
0
one_pointer_end
=
0
pointer_flag
=
False
scale_num
=
len
(
scale_location
)
scales
=
-
1
ratio
=
-
1
if
scale_num
>
0
:
for
i
in
range
(
scale_num
-
1
):
if
scale_location
[
i
]
<=
pointer_location
and
pointer_location
<
scale_location
[
i
+
1
]:
scales
=
i
+
(
pointer_location
-
scale_location
[
i
])
/
(
scale_location
[
i
+
1
]
-
scale_location
[
i
]
+
1e-05
)
+
1
ratio
=
(
pointer_location
-
scale_location
[
0
])
/
(
scale_location
[
scale_num
-
1
]
-
scale_location
[
0
]
+
1e-05
)
result
=
{
'scale_num'
:
scale_num
,
'scales'
:
scales
,
'ratio'
:
ratio
}
return
result
def
infer
(
args
):
image_lists
=
list
()
if
args
.
image
is
not
None
:
if
not
osp
.
exists
(
args
.
image
):
raise
Exception
(
"Image {} does not exist."
.
format
(
args
.
image
))
if
not
is_pic
(
args
.
image
):
raise
Exception
(
"{} is not a picture."
.
format
(
args
.
image
))
image_lists
.
append
(
args
.
image
)
elif
args
.
image_dir
is
not
None
:
if
not
osp
.
exists
(
args
.
image_dir
):
raise
Exception
(
"Directory {} does not exist."
.
format
(
args
.
image_dir
))
for
im_file
in
os
.
listdir
(
args
.
image_dir
):
if
not
is_pic
(
im_file
):
continue
im_file
=
osp
.
join
(
args
.
image_dir
,
im_file
)
image_lists
.
append
(
im_file
)
meter_reader
=
MeterReader
(
args
.
detector_dir
,
args
.
segmenter_dir
)
if
len
(
image_lists
)
>
0
:
for
im_file
in
image_lists
:
meter_reader
.
predict
(
im_file
,
args
.
save_dir
,
args
.
use_erode
,
args
.
erode_kernel
,
args
.
score_threshold
,
args
.
seg_batch_size
,
args
.
seg_thread_num
)
elif
args
.
with_camera
:
cap_video
=
cv2
.
VideoCapture
(
args
.
camera_id
)
if
not
cap_video
.
isOpened
():
raise
Exception
(
"Error opening video stream, please make sure the camera is working"
)
while
cap_video
.
isOpened
():
ret
,
frame
=
cap_video
.
read
()
if
ret
:
meter_reader
.
predict
(
frame
,
args
.
save_dir
,
args
.
use_erode
,
args
.
erode_kernel
,
args
.
score_threshold
,
args
.
seg_batch_size
,
args
.
seg_thread_num
)
if
cv2
.
waitKey
(
1
)
&
0xFF
==
ord
(
'q'
):
break
else
:
break
cap_video
.
release
()
if
__name__
==
'__main__'
:
args
=
parse_args
()
infer
(
args
)
examples/meter_reader/train_detection.py
0 → 100644
浏览文件 @
56f76f5f
import
os
# 选择使用0号卡
os
.
environ
[
'CUDA_VISIBLE_DEVICES'
]
=
'0'
from
paddlex.det
import
transforms
import
paddlex
as
pdx
# 下载和解压表计检测数据集
meter_det_dataset
=
'https://bj.bcebos.com/paddlex/meterreader/datasets/meter_det.tar.gz'
pdx
.
utils
.
download_and_decompress
(
meter_det_dataset
,
path
=
'./'
)
# 定义训练和验证时的transforms
train_transforms
=
transforms
.
Compose
([
transforms
.
MixupImage
(
mixup_epoch
=
250
),
transforms
.
RandomDistort
(),
transforms
.
RandomExpand
(),
transforms
.
RandomCrop
(),
transforms
.
Resize
(
target_size
=
608
,
interp
=
'RANDOM'
),
transforms
.
RandomHorizontalFlip
(),
transforms
.
Normalize
(),
])
eval_transforms
=
transforms
.
Compose
([
transforms
.
Resize
(
target_size
=
608
,
interp
=
'CUBIC'
),
transforms
.
Normalize
(),
])
# 定义训练和验证所用的数据集
train_dataset
=
pdx
.
datasets
.
CocoDetection
(
data_dir
=
'meter_det/train/'
,
ann_file
=
'meter_det/annotations/instance_train.json'
,
transforms
=
train_transforms
,
shuffle
=
True
)
eval_dataset
=
pdx
.
datasets
.
CocoDetection
(
data_dir
=
'meter_det/test/'
,
ann_file
=
'meter_det/annotations/instance_test.json'
,
transforms
=
eval_transforms
)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标
# VisualDL启动方式: visualdl --logdir output/yolov3_darknet/vdl_log --port 8001
# 浏览器打开 https://0.0.0.0:8001即可
# 其中0.0.0.0为本机访问,如为远程服务, 改成相应机器IP
# API说明: https://paddlex.readthedocs.io/zh_CN/latest/apis/models/detection.html#yolov3
num_classes
=
len
(
train_dataset
.
labels
)
model
=
pdx
.
det
.
YOLOv3
(
num_classes
=
num_classes
,
backbone
=
'DarkNet53'
,
label_smooth
=
True
)
model
.
train
(
num_epochs
=
270
,
train_dataset
=
train_dataset
,
train_batch_size
=
8
,
eval_dataset
=
eval_dataset
,
learning_rate
=
0.001
,
warmup_steps
=
4000
,
lr_decay_epochs
=
[
210
,
240
],
save_dir
=
'output/meter_det'
,
use_vdl
=
True
)
examples/meter_reader/train_segmentation.py
0 → 100644
浏览文件 @
56f76f5f
import
os
# 选择使用0号卡
os
.
environ
[
'CUDA_VISIBLE_DEVICES'
]
=
'0'
import
paddlex
as
pdx
from
paddlex.seg
import
transforms
# 下载和解压表盘分割数据集
meter_seg_dataset
=
'https://bj.bcebos.com/paddlex/meterreader/datasets/meter_seg.tar.gz'
pdx
.
utils
.
download_and_decompress
(
meter_seg_dataset
,
path
=
'./'
)
# 定义训练和验证时的transforms
train_transforms
=
transforms
.
Compose
([
transforms
.
Resize
([
512
,
512
]),
transforms
.
RandomHorizontalFlip
(
prob
=
0.5
),
transforms
.
Normalize
(),
])
eval_transforms
=
transforms
.
Compose
([
transforms
.
Resize
([
512
,
512
]),
transforms
.
Normalize
(),
])
# 定义训练和验证所用的数据集
# API说明: https://paddlex.readthedocs.io/zh_CN/latest/apis/datasets/semantic_segmentation.html#segdataset
train_dataset
=
pdx
.
datasets
.
SegDataset
(
data_dir
=
'meter_seg/'
,
file_list
=
'meter_seg/train.txt'
,
label_list
=
'meter_seg/labels.txt'
,
transforms
=
train_transforms
,
shuffle
=
True
)
eval_dataset
=
pdx
.
datasets
.
SegDataset
(
data_dir
=
'meter_seg/'
,
file_list
=
'meter_seg/val.txt'
,
label_list
=
'meter_seg/labels.txt'
,
transforms
=
eval_transforms
)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标
# VisualDL启动方式: visualdl --logdir output/deeplab/vdl_log --port 8001
# 浏览器打开 https://0.0.0.0:8001即可
# 其中0.0.0.0为本机访问,如为远程服务, 改成相应机器IP
#
# API说明: https://paddlex.readthedocs.io/zh_CN/latest/apis/models/semantic_segmentation.html#deeplabv3p
model
=
pdx
.
seg
.
DeepLabv3p
(
num_classes
=
len
(
train_dataset
.
labels
),
backbone
=
'Xception65'
)
model
.
train
(
num_epochs
=
20
,
train_dataset
=
train_dataset
,
train_batch_size
=
4
,
eval_dataset
=
eval_dataset
,
learning_rate
=
0.1
,
pretrain_weights
=
'COCO'
,
save_interval_epochs
=
5
,
save_dir
=
'output/meter_seg'
,
use_vdl
=
True
)
paddlex/cv/datasets/__init__.py
浏览文件 @
56f76f5f
...
...
@@ -18,4 +18,5 @@ from .coco import CocoDetection
from
.seg_dataset
import
SegDataset
from
.easydata_cls
import
EasyDataCls
from
.easydata_det
import
EasyDataDet
from
.easydata_seg
import
EasyDataSeg
\ No newline at end of file
from
.easydata_seg
import
EasyDataSeg
from
.dataset
import
generate_minibatch
paddlex/cv/datasets/dataset.py
浏览文件 @
56f76f5f
...
...
@@ -115,7 +115,7 @@ def multithread_reader(mapper,
while
not
isinstance
(
sample
,
EndSignal
):
batch_data
.
append
(
sample
)
if
len
(
batch_data
)
==
batch_size
:
batch_data
=
GenerateMiniB
atch
(
batch_data
)
batch_data
=
generate_minib
atch
(
batch_data
)
yield
batch_data
batch_data
=
[]
sample
=
out_queue
.
get
()
...
...
@@ -127,11 +127,11 @@ def multithread_reader(mapper,
else
:
batch_data
.
append
(
sample
)
if
len
(
batch_data
)
==
batch_size
:
batch_data
=
GenerateMiniB
atch
(
batch_data
)
batch_data
=
generate_minib
atch
(
batch_data
)
yield
batch_data
batch_data
=
[]
if
not
drop_last
and
len
(
batch_data
)
!=
0
:
batch_data
=
GenerateMiniB
atch
(
batch_data
)
batch_data
=
generate_minib
atch
(
batch_data
)
yield
batch_data
batch_data
=
[]
...
...
@@ -188,32 +188,63 @@ def multiprocess_reader(mapper,
else
:
batch_data
.
append
(
sample
)
if
len
(
batch_data
)
==
batch_size
:
batch_data
=
GenerateMiniB
atch
(
batch_data
)
batch_data
=
generate_minib
atch
(
batch_data
)
yield
batch_data
batch_data
=
[]
if
len
(
batch_data
)
!=
0
and
not
drop_last
:
batch_data
=
GenerateMiniB
atch
(
batch_data
)
batch_data
=
generate_minib
atch
(
batch_data
)
yield
batch_data
batch_data
=
[]
return
queue_reader
def
GenerateMiniBatch
(
batch_data
):
def
generate_minibatch
(
batch_data
,
label_padding_value
=
255
):
# if batch_size is 1, do not pad the image
if
len
(
batch_data
)
==
1
:
return
batch_data
width
=
[
data
[
0
].
shape
[
2
]
for
data
in
batch_data
]
height
=
[
data
[
0
].
shape
[
1
]
for
data
in
batch_data
]
# if the sizes of images in a mini-batch are equal,
# do not pad the image
if
len
(
set
(
width
))
==
1
and
len
(
set
(
height
))
==
1
:
return
batch_data
max_shape
=
np
.
array
([
data
[
0
].
shape
for
data
in
batch_data
]).
max
(
axis
=
0
)
padding_batch
=
[]
for
data
in
batch_data
:
# pad the image to a same size
im_c
,
im_h
,
im_w
=
data
[
0
].
shape
[:]
padding_im
=
np
.
zeros
(
(
im_c
,
max_shape
[
1
],
max_shape
[
2
]),
dtype
=
np
.
float32
)
padding_im
[:,
:
im_h
,
:
im_w
]
=
data
[
0
]
padding_batch
.
append
((
padding_im
,
)
+
data
[
1
:])
if
len
(
data
)
>
1
:
if
isinstance
(
data
[
1
],
np
.
ndarray
):
# padding the image and label of segmentation
# during the training and evaluating phase
padding_label
=
np
.
zeros
(
(
1
,
max_shape
[
1
],
max_shape
[
2
]
)).
astype
(
'int64'
)
+
label_padding_value
_
,
label_h
,
label_w
=
data
[
1
].
shape
padding_label
[:,
:
label_h
,
:
label_w
]
=
data
[
1
]
padding_batch
.
append
((
padding_im
,
padding_label
))
elif
len
(
data
[
1
])
==
0
or
isinstance
(
data
[
1
][
0
],
tuple
)
and
data
[
1
][
0
][
0
]
in
[
'resize'
,
'padding'
]:
# padding the image and insert 'padding' into `im_info`
# of segmentation during the infering phase
if
len
(
data
[
1
])
==
0
or
'padding'
not
in
[
data
[
1
][
i
][
0
]
for
i
in
range
(
len
(
data
[
1
]))
]:
data
[
1
].
append
((
'padding'
,
[
im_h
,
im_w
]))
padding_batch
.
append
((
padding_im
,
)
+
tuple
(
data
[
1
:]))
else
:
# padding the image of detection, or
# padding the image of classification during the trainging
# and evaluating phase
padding_batch
.
append
((
padding_im
,
)
+
tuple
(
data
[
1
:]))
else
:
# padding the image of classification during the infering phase
padding_batch
.
append
((
padding_im
))
return
padding_batch
...
...
paddlex/cv/models/base.py
浏览文件 @
56f76f5f
...
...
@@ -26,6 +26,7 @@ import functools
import
paddlex.utils.logging
as
logging
from
paddlex.utils
import
seconds_to_hms
from
paddlex.utils.utils
import
EarlyStop
from
paddlex.cv.transforms
import
arrange_transforms
import
paddlex
from
collections
import
OrderedDict
from
os
import
path
as
osp
...
...
@@ -102,23 +103,6 @@ class BaseAPI:
mode
=
'test'
)
self
.
test_prog
=
self
.
test_prog
.
clone
(
for_test
=
True
)
def
arrange_transforms
(
self
,
transforms
,
mode
=
'train'
):
# 给transforms添加arrange操作
if
self
.
model_type
==
'classifier'
:
arrange_transform
=
paddlex
.
cls
.
transforms
.
ArrangeClassifier
elif
self
.
model_type
==
'segmenter'
:
arrange_transform
=
paddlex
.
seg
.
transforms
.
ArrangeSegmenter
elif
self
.
model_type
==
'detector'
:
arrange_name
=
'Arrange{}'
.
format
(
self
.
__class__
.
__name__
)
arrange_transform
=
getattr
(
paddlex
.
det
.
transforms
,
arrange_name
)
else
:
raise
Exception
(
"Unrecognized model type: {}"
.
format
(
self
.
model_type
))
if
type
(
transforms
.
transforms
[
-
1
]).
__name__
.
startswith
(
'Arrange'
):
transforms
.
transforms
[
-
1
]
=
arrange_transform
(
mode
=
mode
)
else
:
transforms
.
transforms
.
append
(
arrange_transform
(
mode
=
mode
))
def
build_train_data_loader
(
self
,
dataset
,
batch_size
):
# 初始化data_loader
if
self
.
train_data_loader
is
None
:
...
...
@@ -140,7 +124,11 @@ class BaseAPI:
batch_size
=
1
,
batch_num
=
10
,
cache_dir
=
"./temp"
):
self
.
arrange_transforms
(
transforms
=
dataset
.
transforms
,
mode
=
'quant'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
dataset
.
transforms
,
mode
=
'quant'
)
dataset
.
num_samples
=
batch_size
*
batch_num
try
:
from
.slim.post_quantization
import
PaddleXPostTrainingQuantization
...
...
@@ -249,8 +237,8 @@ class BaseAPI:
logging
.
info
(
"Load pretrain weights from {}."
.
format
(
pretrain_weights
),
use_color
=
True
)
paddlex
.
utils
.
utils
.
load_pretrain_weights
(
self
.
exe
,
self
.
train_prog
,
pretrain_weights
,
fuse_bn
)
paddlex
.
utils
.
utils
.
load_pretrain_weights
(
self
.
exe
,
self
.
train_prog
,
pretrain_weights
,
fuse_bn
)
# 进行裁剪
if
sensitivities_file
is
not
None
:
import
paddleslim
...
...
@@ -354,7 +342,9 @@ class BaseAPI:
logging
.
info
(
"Model saved in {}."
.
format
(
save_dir
))
def
export_inference_model
(
self
,
save_dir
):
test_input_names
=
[
var
.
name
for
var
in
list
(
self
.
test_inputs
.
values
())]
test_input_names
=
[
var
.
name
for
var
in
list
(
self
.
test_inputs
.
values
())
]
test_outputs
=
list
(
self
.
test_outputs
.
values
())
with
fluid
.
scope_guard
(
self
.
scope
):
if
self
.
__class__
.
__name__
==
'MaskRCNN'
:
...
...
@@ -392,7 +382,8 @@ class BaseAPI:
# 模型保存成功的标志
open
(
osp
.
join
(
save_dir
,
'.success'
),
'w'
).
close
()
logging
.
info
(
"Model for inference deploy saved in {}."
.
format
(
save_dir
))
logging
.
info
(
"Model for inference deploy saved in {}."
.
format
(
save_dir
))
def
train_loop
(
self
,
num_epochs
,
...
...
@@ -416,8 +407,11 @@ class BaseAPI:
from
visualdl
import
LogWriter
vdl_logdir
=
osp
.
join
(
save_dir
,
'vdl_log'
)
# 给transform添加arrange操作
self
.
arrange_transforms
(
transforms
=
train_dataset
.
transforms
,
mode
=
'train'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
train_dataset
.
transforms
,
mode
=
'train'
)
# 构建train_data_loader
self
.
build_train_data_loader
(
dataset
=
train_dataset
,
batch_size
=
train_batch_size
)
...
...
@@ -516,11 +510,13 @@ class BaseAPI:
eta
=
((
num_epochs
-
i
)
*
total_num_steps
-
step
-
1
)
*
avg_step_time
if
time_eval_one_epoch
is
not
None
:
eval_eta
=
(
total_eval_times
-
i
//
save_interval_epochs
)
*
time_eval_one_epoch
eval_eta
=
(
total_eval_times
-
i
//
save_interval_epochs
)
*
time_eval_one_epoch
else
:
eval_eta
=
(
total_eval_times
-
i
//
save_interval_epochs
)
*
total_num_steps_eval
*
avg_step_time
eval_eta
=
(
total_eval_times
-
i
//
save_interval_epochs
)
*
total_num_steps_eval
*
avg_step_time
eta_str
=
seconds_to_hms
(
eta
+
eval_eta
)
logging
.
info
(
...
...
paddlex/cv/models/classifier.py
浏览文件 @
56f76f5f
...
...
@@ -17,10 +17,13 @@ import numpy as np
import
time
import
math
import
tqdm
from
multiprocessing.pool
import
ThreadPool
import
paddle.fluid
as
fluid
import
paddlex.utils.logging
as
logging
from
paddlex.utils
import
seconds_to_hms
import
paddlex
from
paddlex.cv.transforms
import
arrange_transforms
from
paddlex.cv.datasets
import
generate_minibatch
from
collections
import
OrderedDict
from
.base
import
BaseAPI
...
...
@@ -54,7 +57,8 @@ class BaseClassifier(BaseAPI):
input_shape
=
[
None
,
3
,
self
.
fixed_input_shape
[
1
],
self
.
fixed_input_shape
[
0
]
]
image
=
fluid
.
data
(
dtype
=
'float32'
,
shape
=
input_shape
,
name
=
'image'
)
image
=
fluid
.
data
(
dtype
=
'float32'
,
shape
=
input_shape
,
name
=
'image'
)
else
:
image
=
fluid
.
data
(
dtype
=
'float32'
,
shape
=
[
None
,
3
,
None
,
None
],
name
=
'image'
)
...
...
@@ -219,7 +223,11 @@ class BaseClassifier(BaseAPI):
tuple (metrics, eval_details): 当return_details为True时,增加返回dict,
包含关键字:'true_labels'、'pred_scores',分别代表真实类别id、每个类别的预测得分。
"""
self
.
arrange_transforms
(
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
data_generator
=
eval_dataset
.
generator
(
batch_size
=
batch_size
,
drop_last
=
False
)
k
=
min
(
5
,
self
.
num_classes
)
...
...
@@ -232,8 +240,9 @@ class BaseClassifier(BaseAPI):
self
.
test_prog
).
with_data_parallel
(
share_vars_from
=
self
.
parallel_train_prog
)
batch_size_each_gpu
=
self
.
_get_single_card_bs
(
batch_size
)
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
for
step
,
data
in
tqdm
.
tqdm
(
enumerate
(
data_generator
()),
total
=
total_steps
):
images
=
np
.
array
([
d
[
0
]
for
d
in
data
]).
astype
(
'float32'
)
...
...
@@ -269,38 +278,106 @@ class BaseClassifier(BaseAPI):
return
metrics
,
eval_details
return
metrics
@
staticmethod
def
_preprocess
(
images
,
transforms
,
model_type
,
class_name
,
thread_num
=
1
):
arrange_transforms
(
model_type
=
model_type
,
class_name
=
class_name
,
transforms
=
transforms
,
mode
=
'test'
)
pool
=
ThreadPool
(
thread_num
)
batch_data
=
pool
.
map
(
transforms
,
images
)
pool
.
close
()
pool
.
join
()
padding_batch
=
generate_minibatch
(
batch_data
)
im
=
np
.
array
([
data
[
0
]
for
data
in
padding_batch
])
return
im
@
staticmethod
def
_postprocess
(
results
,
true_topk
,
labels
):
preds
=
list
()
for
i
,
pred
in
enumerate
(
results
[
0
]):
pred_label
=
np
.
argsort
(
pred
)[::
-
1
][:
true_topk
]
preds
.
append
([{
'category_id'
:
l
,
'category'
:
labels
[
l
],
'score'
:
results
[
0
][
i
][
l
]
}
for
l
in
pred_label
])
return
preds
def
predict
(
self
,
img_file
,
transforms
=
None
,
topk
=
1
):
"""预测。
Args:
img_file (str
): 预测图像路径
。
img_file (str
|np.ndarray): 预测图像路径,或者是解码后的排列格式为(H, W, C)且类型为float32且为BGR格式的数组
。
transforms (paddlex.cls.transforms): 数据预处理操作。
topk (int): 预测时前k个最大值。
Returns:
list: 其中元素均为字典。字典的关键字为'category_id'、'category'、'score',
分别对应预测类别id、预测类别标签、预测得分。
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
true_topk
=
min
(
self
.
num_classes
,
topk
)
if
transforms
is
not
None
:
self
.
arrange_transforms
(
transforms
=
transforms
,
mode
=
'test'
)
im
=
transforms
(
img_file
)
if
isinstance
(
img_file
,
(
str
,
np
.
ndarray
)):
images
=
[
img_file
]
else
:
self
.
arrange_transforms
(
transforms
=
self
.
test_transforms
,
mode
=
'test'
)
im
=
self
.
test_transforms
(
img_file
)
raise
Exception
(
"img_file must be str/np.ndarray"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
=
BaseClassifier
.
_preprocess
(
images
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
use_program_cache
=
True
)
pred_label
=
np
.
argsort
(
result
[
0
][
0
])[::
-
1
][:
true_topk
]
res
=
[{
'category_id'
:
l
,
'category'
:
self
.
labels
[
l
],
'score'
:
result
[
0
][
0
][
l
]
}
for
l
in
pred_label
]
return
res
preds
=
BaseClassifier
.
_postprocess
(
result
,
true_topk
,
self
.
labels
)
return
preds
[
0
]
def
batch_predict
(
self
,
img_file_list
,
transforms
=
None
,
topk
=
1
,
thread_num
=
2
):
"""预测。
Args:
img_file_list(list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是图像路径
也可以是解码后的排列格式为(H,W,C)且类型为float32且为BGR格式的数组。
transforms (paddlex.cls.transforms): 数据预处理操作。
topk (int): 预测时前k个最大值。
thread_num (int): 并发执行各图像预处理时的线程数。
Returns:
list: 每个元素都为列表,表示各图像的预测结果。在各图像的预测列表中,其中元素均为字典。字典的关键字为'category_id'、'category'、'score',
分别对应预测类别id、预测类别标签、预测得分。
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
true_topk
=
min
(
self
.
num_classes
,
topk
)
if
not
isinstance
(
img_file_list
,
(
list
,
tuple
)):
raise
Exception
(
"im_file must be list/tuple"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
=
BaseClassifier
.
_preprocess
(
img_file_list
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
,
thread_num
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
use_program_cache
=
True
)
preds
=
BaseClassifier
.
_postprocess
(
result
,
true_topk
,
self
.
labels
)
return
preds
class
ResNet18
(
BaseClassifier
):
...
...
paddlex/cv/models/deeplabv3p.py
浏览文件 @
56f76f5f
...
...
@@ -18,9 +18,12 @@ import numpy as np
import
tqdm
import
math
import
cv2
from
multiprocessing.pool
import
ThreadPool
import
paddle.fluid
as
fluid
import
paddlex.utils.logging
as
logging
import
paddlex
from
paddlex.cv.transforms
import
arrange_transforms
from
paddlex.cv.datasets
import
generate_minibatch
from
collections
import
OrderedDict
from
.base
import
BaseAPI
from
.utils.seg_eval
import
ConfusionMatrix
...
...
@@ -317,7 +320,11 @@ class DeepLabv3p(BaseAPI):
tuple (metrics, eval_details):当return_details为True时,增加返回dict (eval_details),
包含关键字:'confusion_matrix',表示评估的混淆矩阵。
"""
self
.
arrange_transforms
(
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
total_steps
=
math
.
ceil
(
eval_dataset
.
num_samples
*
1.0
/
batch_size
)
conf_mat
=
ConfusionMatrix
(
self
.
num_classes
,
streaming
=
True
)
data_generator
=
eval_dataset
.
generator
(
...
...
@@ -327,21 +334,13 @@ class DeepLabv3p(BaseAPI):
self
.
parallel_test_prog
=
fluid
.
CompiledProgram
(
self
.
test_prog
).
with_data_parallel
(
share_vars_from
=
self
.
parallel_train_prog
)
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
for
step
,
data
in
tqdm
.
tqdm
(
enumerate
(
data_generator
()),
total
=
total_steps
):
images
=
np
.
array
([
d
[
0
]
for
d
in
data
])
_
,
_
,
im_h
,
im_w
=
images
.
shape
labels
=
list
()
for
d
in
data
:
padding_label
=
np
.
zeros
(
(
1
,
im_h
,
im_w
)).
astype
(
'int64'
)
+
self
.
ignore_index
_
,
label_h
,
label_w
=
d
[
1
].
shape
padding_label
[:,
:
label_h
,
:
label_w
]
=
d
[
1
]
labels
.
append
(
padding_label
)
labels
=
np
.
array
(
labels
)
labels
=
np
.
array
([
d
[
1
]
for
d
in
data
])
num_samples
=
images
.
shape
[
0
]
if
num_samples
<
batch_size
:
...
...
@@ -379,10 +378,56 @@ class DeepLabv3p(BaseAPI):
return
metrics
,
eval_details
return
metrics
def
predict
(
self
,
im_file
,
transforms
=
None
):
@
staticmethod
def
_preprocess
(
images
,
transforms
,
model_type
,
class_name
,
thread_num
=
1
):
arrange_transforms
(
model_type
=
model_type
,
class_name
=
class_name
,
transforms
=
transforms
,
mode
=
'test'
)
pool
=
ThreadPool
(
thread_num
)
batch_data
=
pool
.
map
(
transforms
,
images
)
pool
.
close
()
pool
.
join
()
padding_batch
=
generate_minibatch
(
batch_data
)
im
=
np
.
array
(
[
data
[
0
]
for
data
in
padding_batch
],
dtype
=
padding_batch
[
0
][
0
].
dtype
)
im_info
=
[
data
[
1
]
for
data
in
padding_batch
]
return
im
,
im_info
@
staticmethod
def
_postprocess
(
results
,
im_info
):
pred_list
=
list
()
logit_list
=
list
()
for
i
,
(
pred
,
logit
)
in
enumerate
(
zip
(
results
[
0
],
results
[
1
])):
pred
=
pred
.
astype
(
'uint8'
)
pred
=
np
.
squeeze
(
pred
).
astype
(
'uint8'
)
logit
=
np
.
transpose
(
logit
,
(
1
,
2
,
0
))
for
info
in
im_info
[
i
][::
-
1
]:
if
info
[
0
]
==
'resize'
:
w
,
h
=
info
[
1
][
1
],
info
[
1
][
0
]
pred
=
cv2
.
resize
(
pred
,
(
w
,
h
),
cv2
.
INTER_NEAREST
)
logit
=
cv2
.
resize
(
logit
,
(
w
,
h
),
cv2
.
INTER_LINEAR
)
elif
info
[
0
]
==
'padding'
:
w
,
h
=
info
[
1
][
1
],
info
[
1
][
0
]
pred
=
pred
[
0
:
h
,
0
:
w
]
logit
=
logit
[
0
:
h
,
0
:
w
,
:]
else
:
raise
Exception
(
"Unexpected info '{}' in im_info"
.
format
(
info
[
0
]))
pred_list
.
append
(
pred
)
logit_list
.
append
(
logit
)
preds
=
list
()
for
pred
,
logit
in
zip
(
pred_list
,
logit_list
):
preds
.
append
({
'label_map'
:
pred
,
'score_map'
:
logit
})
return
preds
def
predict
(
self
,
img_file
,
transforms
=
None
):
"""预测。
Args:
img_file(str
): 预测图像路径
。
img_file(str
|np.ndarray): 预测图像路径,或者是解码后的排列格式为(H, W, C)且类型为float32且为BGR格式的数组
。
transforms(paddlex.cv.transforms): 数据预处理操作。
Returns:
...
...
@@ -392,34 +437,52 @@ class DeepLabv3p(BaseAPI):
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
transforms
is
not
None
:
self
.
arrange_transforms
(
transforms
=
transforms
,
mode
=
'test'
)
im
,
im_info
=
transforms
(
im_file
)
if
isinstance
(
img_file
,
(
str
,
np
.
ndarray
)):
images
=
[
img_file
]
else
:
self
.
arrange_transforms
(
transforms
=
self
.
test_transforms
,
mode
=
'test'
)
im
,
im_info
=
self
.
test_transforms
(
im_file
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
)
raise
Exception
(
"img_file must be str/np.ndarray"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_info
=
DeepLabv3p
.
_preprocess
(
images
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
use_program_cache
=
True
)
pred
=
result
[
0
]
pred
=
np
.
squeeze
(
pred
).
astype
(
'uint8'
)
logit
=
result
[
1
]
logit
=
np
.
squeeze
(
logit
)
logit
=
np
.
transpose
(
logit
,
(
1
,
2
,
0
))
for
info
in
im_info
[::
-
1
]:
if
info
[
0
]
==
'resize'
:
w
,
h
=
info
[
1
][
1
],
info
[
1
][
0
]
pred
=
cv2
.
resize
(
pred
,
(
w
,
h
),
cv2
.
INTER_NEAREST
)
logit
=
cv2
.
resize
(
logit
,
(
w
,
h
),
cv2
.
INTER_LINEAR
)
elif
info
[
0
]
==
'padding'
:
w
,
h
=
info
[
1
][
1
],
info
[
1
][
0
]
pred
=
pred
[
0
:
h
,
0
:
w
]
logit
=
logit
[
0
:
h
,
0
:
w
,
:]
else
:
raise
Exception
(
"Unexpected info '{}' in im_info"
.
format
(
info
[
0
]))
return
{
'label_map'
:
pred
,
'score_map'
:
logit
}
preds
=
DeepLabv3p
.
_postprocess
(
result
,
im_info
)
return
preds
[
0
]
def
batch_predict
(
self
,
img_file_list
,
transforms
=
None
,
thread_num
=
2
):
"""预测。
Args:
img_file_list(list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是图像路径
也可以是解码后的排列格式为(H,W,C)且类型为float32且为BGR格式的数组。
transforms(paddlex.cv.transforms): 数据预处理操作。
Returns:
list: 每个元素都为列表,表示各图像的预测结果。各图像的预测结果用字典表示,包含关键字'label_map'和'score_map', 'label_map'存储预测结果灰度图,
像素值表示对应的类别,'score_map'存储各类别的概率,shape=(h, w, num_classes)
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
not
isinstance
(
img_file_list
,
(
list
,
tuple
)):
raise
Exception
(
"im_file must be list/tuple"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_info
=
DeepLabv3p
.
_preprocess
(
img_file_list
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
,
thread_num
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
use_program_cache
=
True
)
preds
=
DeepLabv3p
.
_postprocess
(
result
,
im_info
)
return
preds
paddlex/cv/models/faster_rcnn.py
浏览文件 @
56f76f5f
...
...
@@ -16,11 +16,14 @@ from __future__ import absolute_import
import
math
import
tqdm
import
numpy
as
np
from
multiprocessing.pool
import
ThreadPool
import
paddle.fluid
as
fluid
import
paddlex.utils.logging
as
logging
import
paddlex
import
os.path
as
osp
import
copy
from
paddlex.cv.transforms
import
arrange_transforms
from
paddlex.cv.datasets
import
generate_minibatch
from
.base
import
BaseAPI
from
collections
import
OrderedDict
from
.utils.detection_eval
import
eval_results
,
bbox2out
...
...
@@ -291,7 +294,11 @@ class FasterRCNN(BaseAPI):
eval_details为dict,包含关键字:'bbox',对应元素预测结果列表,每个预测结果由图像id、
预测框类别id、预测框坐标、预测框得分;’gt‘:真实标注框相关信息。
"""
self
.
arrange_transforms
(
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
if
metric
is
None
:
if
hasattr
(
self
,
'metric'
)
and
self
.
metric
is
not
None
:
metric
=
self
.
metric
...
...
@@ -310,12 +317,14 @@ class FasterRCNN(BaseAPI):
logging
.
warning
(
"Faster RCNN supports batch_size=1 only during evaluating, so batch_size is forced to be set to 1."
)
dataset
=
eval_dataset
.
generator
(
batch_size
=
batch_size
,
drop_last
=
False
)
dataset
=
eval_dataset
.
generator
(
batch_size
=
batch_size
,
drop_last
=
False
)
total_steps
=
math
.
ceil
(
eval_dataset
.
num_samples
*
1.0
/
batch_size
)
results
=
list
()
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
for
step
,
data
in
tqdm
.
tqdm
(
enumerate
(
dataset
()),
total
=
total_steps
):
images
=
np
.
array
([
d
[
0
]
for
d
in
data
]).
astype
(
'float32'
)
im_infos
=
np
.
array
([
d
[
1
]
for
d
in
data
]).
astype
(
'float32'
)
...
...
@@ -366,11 +375,42 @@ class FasterRCNN(BaseAPI):
return
metrics
,
eval_details
return
metrics
@
staticmethod
def
_preprocess
(
images
,
transforms
,
model_type
,
class_name
,
thread_num
=
1
):
arrange_transforms
(
model_type
=
model_type
,
class_name
=
class_name
,
transforms
=
transforms
,
mode
=
'test'
)
pool
=
ThreadPool
(
thread_num
)
batch_data
=
pool
.
map
(
transforms
,
images
)
pool
.
close
()
pool
.
join
()
padding_batch
=
generate_minibatch
(
batch_data
)
im
=
np
.
array
([
data
[
0
]
for
data
in
padding_batch
])
im_resize_info
=
np
.
array
([
data
[
1
]
for
data
in
padding_batch
])
im_shape
=
np
.
array
([
data
[
2
]
for
data
in
padding_batch
])
return
im
,
im_resize_info
,
im_shape
@
staticmethod
def
_postprocess
(
res
,
batch_size
,
num_classes
,
labels
):
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
num_classes
)})
xywh_results
=
bbox2out
([
res
],
clsid2catid
)
preds
=
[[]
for
i
in
range
(
batch_size
)]
for
xywh_res
in
xywh_results
:
image_id
=
xywh_res
[
'image_id'
]
del
xywh_res
[
'image_id'
]
xywh_res
[
'category'
]
=
labels
[
xywh_res
[
'category_id'
]]
preds
[
image_id
].
append
(
xywh_res
)
return
preds
def
predict
(
self
,
img_file
,
transforms
=
None
):
"""预测。
Args:
img_file
(str): 预测图像路径
。
img_file
(str|np.ndarray): 预测图像路径,或者是解码后的排列格式为(H, W, C)且类型为float32且为BGR格式的数组
。
transforms (paddlex.det.transforms): 数据预处理操作。
Returns:
...
...
@@ -380,36 +420,84 @@ class FasterRCNN(BaseAPI):
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
transforms
is
not
None
:
self
.
arrange_transforms
(
transforms
=
transforms
,
mode
=
'test'
)
im
,
im_resize_info
,
im_shape
=
transforms
(
img_file
)
if
isinstance
(
img_file
,
(
str
,
np
.
ndarray
)):
images
=
[
img_file
]
else
:
self
.
arrange_transforms
(
transforms
=
self
.
test_transforms
,
mode
=
'test'
)
im
,
im_resize_info
,
im_shape
=
self
.
test_transforms
(
img_file
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
)
im_resize_info
=
np
.
expand_dims
(
im_resize_info
,
axis
=
0
)
im_shape
=
np
.
expand_dims
(
im_shape
,
axis
=
0
)
raise
Exception
(
"img_file must be str/np.ndarray"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_resize_info
,
im_shape
=
FasterRCNN
.
_preprocess
(
images
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
)
with
fluid
.
scope_guard
(
self
.
scope
):
outputs
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_info'
:
im_resize_info
,
'im_shape'
:
im_shape
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_info'
:
im_resize_info
,
'im_shape'
:
im_shape
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
res
=
{
k
:
(
np
.
array
(
v
),
v
.
recursive_sequence_lengths
())
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
outputs
)
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
result
)
}
res
[
'im_id'
]
=
(
np
.
array
([[
0
]]).
astype
(
'int32'
),
[])
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
self
.
num_classes
)})
xywh_results
=
bbox2out
([
res
],
clsid2catid
)
results
=
list
()
for
xywh_res
in
xywh_results
:
del
xywh_res
[
'image_id'
]
xywh_res
[
'category'
]
=
self
.
labels
[
xywh_res
[
'category_id'
]]
results
.
append
(
xywh_res
)
return
results
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
len
(
images
))]).
astype
(
'int32'
),
[])
preds
=
FasterRCNN
.
_postprocess
(
res
,
len
(
images
),
self
.
num_classes
,
self
.
labels
)
return
preds
[
0
]
def
batch_predict
(
self
,
img_file_list
,
transforms
=
None
,
thread_num
=
2
):
"""预测。
Args:
img_file_list(list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是图像路径
也可以是解码后的排列格式为(H,W,C)且类型为float32且为BGR格式的数组。
transforms (paddlex.det.transforms): 数据预处理操作。
thread_num (int): 并发执行各图像预处理时的线程数。
Returns:
list: 每个元素都为列表,表示各图像的预测结果。在各图像的预测结果列表中,每个预测结果由预测框类别标签、
预测框类别名称、预测框坐标(坐标格式为[xmin, ymin, w, h])、
预测框得分组成。
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
not
isinstance
(
img_file_list
,
(
list
,
tuple
)):
raise
Exception
(
"im_file must be list/tuple"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_resize_info
,
im_shape
=
FasterRCNN
.
_preprocess
(
img_file_list
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
,
thread_num
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_info'
:
im_resize_info
,
'im_shape'
:
im_shape
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
res
=
{
k
:
(
np
.
array
(
v
),
v
.
recursive_sequence_lengths
())
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
result
)
}
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
len
(
img_file_list
))]).
astype
(
'int32'
),
[])
preds
=
FasterRCNN
.
_postprocess
(
res
,
len
(
img_file_list
),
self
.
num_classes
,
self
.
labels
)
return
preds
paddlex/cv/models/load_model.py
浏览文件 @
56f76f5f
...
...
@@ -21,6 +21,7 @@ import paddle.fluid as fluid
from
paddle.fluid.framework
import
Parameter
import
paddlex
import
paddlex.utils.logging
as
logging
from
paddlex.cv.transforms
import
build_transforms
,
build_transforms_v1
def
load_model
(
model_dir
,
fixed_input_shape
=
None
):
...
...
@@ -100,8 +101,8 @@ def load_model(model_dir, fixed_input_shape=None):
model
.
model_type
,
info
[
'Transforms'
],
info
[
'BatchTransforms'
])
model
.
eval_transforms
=
copy
.
deepcopy
(
model
.
test_transforms
)
else
:
model
.
test_transforms
=
build_transforms
(
model
.
model_type
,
info
[
'Transforms'
],
to_rgb
)
model
.
test_transforms
=
build_transforms
(
model
.
model_type
,
info
[
'Transforms'
],
to_rgb
)
model
.
eval_transforms
=
copy
.
deepcopy
(
model
.
test_transforms
)
if
'_Attributes'
in
info
:
...
...
@@ -128,67 +129,3 @@ def fix_input_shape(info, fixed_input_shape=None):
padding
[
'Padding'
][
'target_size'
]
=
list
(
fixed_input_shape
)
info
[
'Transforms'
].
append
(
resize
)
info
[
'Transforms'
].
append
(
padding
)
def
build_transforms
(
model_type
,
transforms_info
,
to_rgb
=
True
):
if
model_type
==
"classifier"
:
import
paddlex.cv.transforms.cls_transforms
as
T
elif
model_type
==
"detector"
:
import
paddlex.cv.transforms.det_transforms
as
T
elif
model_type
==
"segmenter"
:
import
paddlex.cv.transforms.seg_transforms
as
T
transforms
=
list
()
for
op_info
in
transforms_info
:
op_name
=
list
(
op_info
.
keys
())[
0
]
op_attr
=
op_info
[
op_name
]
if
not
hasattr
(
T
,
op_name
):
raise
Exception
(
"There's no operator named '{}' in transforms of {}"
.
format
(
op_name
,
model_type
))
transforms
.
append
(
getattr
(
T
,
op_name
)(
**
op_attr
))
eval_transforms
=
T
.
Compose
(
transforms
)
eval_transforms
.
to_rgb
=
to_rgb
return
eval_transforms
def
build_transforms_v1
(
model_type
,
transforms_info
,
batch_transforms_info
):
""" 老版本模型加载,仅支持PaddleX前端导出的模型
"""
logging
.
debug
(
"Use build_transforms_v1 to reconstruct transforms"
)
if
model_type
==
"classifier"
:
import
paddlex.cv.transforms.cls_transforms
as
T
elif
model_type
==
"detector"
:
import
paddlex.cv.transforms.det_transforms
as
T
elif
model_type
==
"segmenter"
:
import
paddlex.cv.transforms.seg_transforms
as
T
transforms
=
list
()
for
op_info
in
transforms_info
:
op_name
=
op_info
[
0
]
op_attr
=
op_info
[
1
]
if
op_name
==
'DecodeImage'
:
continue
if
op_name
==
'Permute'
:
continue
if
op_name
==
'ResizeByShort'
:
op_attr_new
=
dict
()
if
'short_size'
in
op_attr
:
op_attr_new
[
'short_size'
]
=
op_attr
[
'short_size'
]
else
:
op_attr_new
[
'short_size'
]
=
op_attr
[
'target_size'
]
op_attr_new
[
'max_size'
]
=
op_attr
.
get
(
'max_size'
,
-
1
)
op_attr
=
op_attr_new
if
op_name
.
startswith
(
'Arrange'
):
continue
if
not
hasattr
(
T
,
op_name
):
raise
Exception
(
"There's no operator named '{}' in transforms of {}"
.
format
(
op_name
,
model_type
))
transforms
.
append
(
getattr
(
T
,
op_name
)(
**
op_attr
))
if
model_type
==
"detector"
and
len
(
batch_transforms_info
)
>
0
:
op_name
=
batch_transforms_info
[
0
][
0
]
op_attr
=
batch_transforms_info
[
0
][
1
]
assert
op_name
==
"PaddingMiniBatch"
,
"Only PaddingMiniBatch transform is supported for batch transform"
padding
=
T
.
Padding
(
coarsest_stride
=
op_attr
[
'coarsest_stride'
])
transforms
.
append
(
padding
)
eval_transforms
=
T
.
Compose
(
transforms
)
return
eval_transforms
paddlex/cv/models/mask_rcnn.py
浏览文件 @
56f76f5f
...
...
@@ -16,11 +16,13 @@ from __future__ import absolute_import
import
math
import
tqdm
import
numpy
as
np
from
multiprocessing.pool
import
ThreadPool
import
paddle.fluid
as
fluid
import
paddlex.utils.logging
as
logging
import
paddlex
import
copy
import
os.path
as
osp
from
paddlex.cv.transforms
import
arrange_transforms
from
collections
import
OrderedDict
from
.faster_rcnn
import
FasterRCNN
from
.utils.detection_eval
import
eval_results
,
bbox2out
,
mask2out
...
...
@@ -253,7 +255,11 @@ class MaskRCNN(FasterRCNN):
预测框坐标、预测框得分;'mask',对应元素预测区域结果列表,每个预测结果由图像id、
预测区域类别id、预测区域坐标、预测区域得分;’gt‘:真实标注框和标注区域相关信息。
"""
self
.
arrange_transforms
(
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
if
metric
is
None
:
if
hasattr
(
self
,
'metric'
)
and
self
.
metric
is
not
None
:
metric
=
self
.
metric
...
...
@@ -274,8 +280,9 @@ class MaskRCNN(FasterRCNN):
total_steps
=
math
.
ceil
(
eval_dataset
.
num_samples
*
1.0
/
batch_size
)
results
=
list
()
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
for
step
,
data
in
tqdm
.
tqdm
(
enumerate
(
data_generator
()),
total
=
total_steps
):
images
=
np
.
array
([
d
[
0
]
for
d
in
data
]).
astype
(
'float32'
)
...
...
@@ -319,7 +326,8 @@ class MaskRCNN(FasterRCNN):
zip
([
'bbox_map'
,
'segm_map'
],
[
ap_stats
[
0
][
1
],
ap_stats
[
1
][
1
]]))
else
:
metrics
=
OrderedDict
(
zip
([
'bbox_map'
,
'segm_map'
],
[
0.0
,
0.0
]))
metrics
=
OrderedDict
(
zip
([
'bbox_map'
,
'segm_map'
],
[
0.0
,
0.0
]))
elif
metric
==
'COCO'
:
if
isinstance
(
ap_stats
[
0
],
np
.
ndarray
)
and
isinstance
(
ap_stats
[
1
],
np
.
ndarray
):
...
...
@@ -333,56 +341,118 @@ class MaskRCNN(FasterRCNN):
return
metrics
,
eval_details
return
metrics
@
staticmethod
def
_postprocess
(
res
,
batch_size
,
num_classes
,
mask_head_resolution
,
labels
):
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
num_classes
)})
xywh_results
=
bbox2out
([
res
],
clsid2catid
)
segm_results
=
mask2out
([
res
],
clsid2catid
,
mask_head_resolution
)
preds
=
[[]
for
i
in
range
(
batch_size
)]
import
pycocotools.mask
as
mask_util
for
index
,
xywh_res
in
enumerate
(
xywh_results
):
image_id
=
xywh_res
[
'image_id'
]
del
xywh_res
[
'image_id'
]
xywh_res
[
'mask'
]
=
mask_util
.
decode
(
segm_results
[
index
][
'segmentation'
])
xywh_res
[
'category'
]
=
labels
[
xywh_res
[
'category_id'
]]
preds
[
image_id
].
append
(
xywh_res
)
return
preds
def
predict
(
self
,
img_file
,
transforms
=
None
):
"""预测。
Args:
img_file
(str): 预测图像路径
。
img_file
(str|np.ndarray): 预测图像路径,或者是解码后的排列格式为(H, W, C)且类型为float32且为BGR格式的数组
。
transforms (paddlex.det.transforms): 数据预处理操作。
Returns:
d
ict: 预测结果列表,每个预测结果由预测框类别标签、预测框类别名称、
l
ict: 预测结果列表,每个预测结果由预测框类别标签、预测框类别名称、
预测框坐标(坐标格式为[xmin, ymin, w, h])、
原图大小的预测二值图(1表示预测框类别,0表示背景类)、
预测框得分组成。
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
transforms
is
not
None
:
self
.
arrange_transforms
(
transforms
=
transforms
,
mode
=
'test'
)
im
,
im_resize_info
,
im_shape
=
transforms
(
img_file
)
if
isinstance
(
img_file
,
(
str
,
np
.
ndarray
)):
images
=
[
img_file
]
else
:
self
.
arrange_transforms
(
transforms
=
self
.
test_transforms
,
mode
=
'test'
)
im
,
im_resize_info
,
im_shape
=
self
.
test_transforms
(
img_file
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
)
im_resize_info
=
np
.
expand_dims
(
im_resize_info
,
axis
=
0
)
im_shape
=
np
.
expand_dims
(
im_shape
,
axis
=
0
)
raise
Exception
(
"img_file must be str/np.ndarray"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_resize_info
,
im_shape
=
FasterRCNN
.
_preprocess
(
images
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
)
with
fluid
.
scope_guard
(
self
.
scope
):
outputs
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_info'
:
im_resize_info
,
'im_shape'
:
im_shape
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_info'
:
im_resize_info
,
'im_shape'
:
im_shape
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
res
=
{
k
:
(
np
.
array
(
v
),
v
.
recursive_sequence_lengths
())
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
outputs
)
for
k
,
v
in
zip
(
list
s
(
self
.
test_outputs
.
keys
()),
result
)
}
res
[
'im_id'
]
=
(
np
.
array
([[
0
]]).
astype
(
'int32'
),
[])
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
len
(
images
))]).
astype
(
'int32'
),
[])
res
[
'im_shape'
]
=
(
np
.
array
(
im_shape
),
[])
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
self
.
num_classes
)})
xywh_results
=
bbox2out
([
res
],
clsid2catid
)
segm_results
=
mask2out
([
res
],
clsid2catid
,
self
.
mask_head_resolution
)
results
=
list
()
import
pycocotools.mask
as
mask_util
for
index
,
xywh_res
in
enumerate
(
xywh_results
):
del
xywh_res
[
'image_id'
]
xywh_res
[
'mask'
]
=
mask_util
.
decode
(
segm_results
[
index
][
'segmentation'
])
xywh_res
[
'category'
]
=
self
.
labels
[
xywh_res
[
'category_id'
]]
results
.
append
(
xywh_res
)
return
results
preds
=
MaskRCNN
.
_postprocess
(
res
,
len
(
images
),
self
.
num_classes
,
self
.
mask_head_resolution
,
self
.
labels
)
return
preds
[
0
]
def
batch_predict
(
self
,
img_file_list
,
transforms
=
None
,
thread_num
=
2
):
"""预测。
Args:
img_file_list(list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是图像路径
也可以是解码后的排列格式为(H,W,C)且类型为float32且为BGR格式的数组。
transforms (paddlex.det.transforms): 数据预处理操作。
thread_num (int): 并发执行各图像预处理时的线程数。
Returns:
dict: 每个元素都为列表,表示各图像的预测结果。在各图像的预测结果列表中,每个预测结果由预测框类别标签、预测框类别名称、
预测框坐标(坐标格式为[xmin, ymin, w, h])、
原图大小的预测二值图(1表示预测框类别,0表示背景类)、
预测框得分组成。
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
not
isinstance
(
img_file_list
,
(
list
,
tuple
)):
raise
Exception
(
"im_file must be list/tuple"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_resize_info
,
im_shape
=
FasterRCNN
.
_preprocess
(
img_file_list
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
,
thread_num
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_info'
:
im_resize_info
,
'im_shape'
:
im_shape
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
res
=
{
k
:
(
np
.
array
(
v
),
v
.
recursive_sequence_lengths
())
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
result
)
}
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
len
(
img_file_list
))]).
astype
(
'int32'
),
[])
res
[
'im_shape'
]
=
(
np
.
array
(
im_shape
),
[])
preds
=
MaskRCNN
.
_postprocess
(
res
,
len
(
img_file_list
),
self
.
num_classes
,
self
.
mask_head_resolution
,
self
.
labels
)
return
preds
paddlex/cv/models/slim/prune_config.py
浏览文件 @
56f76f5f
...
...
@@ -67,8 +67,7 @@ sensitivities_data = {
'https://bj.bcebos.com/paddlex/slim_prune/yolov3_darknet53.sensitivities'
,
'YOLOv3_ResNet34'
:
'https://bj.bcebos.com/paddlex/slim_prune/yolov3_resnet34.sensitivities'
,
'UNet'
:
'https://bj.bcebos.com/paddlex/slim_prune/unet.sensitivities'
,
'UNet'
:
'https://bj.bcebos.com/paddlex/slim_prune/unet.sensitivities'
,
'DeepLabv3p_MobileNetV2_x0.25'
:
'https://bj.bcebos.com/paddlex/slim_prune/deeplab_mobilenetv2_x0.25_no_aspp_decoder.sensitivities'
,
'DeepLabv3p_MobileNetV2_x0.5'
:
...
...
@@ -103,8 +102,8 @@ def get_sensitivities(flag, model, save_dir):
model_type
=
model_name
+
'_'
+
model
.
backbone
if
model_type
.
startswith
(
'DeepLabv3p_Xception'
):
model_type
=
model_type
+
'_'
+
'aspp'
+
'_'
+
'decoder'
elif
hasattr
(
model
,
'encoder_with_aspp'
)
or
hasattr
(
model
,
'enable_decoder'
):
elif
hasattr
(
model
,
'encoder_with_aspp'
)
or
hasattr
(
model
,
'enable_decoder'
):
model_type
=
model_type
+
'_'
+
'aspp'
+
'_'
+
'decoder'
if
osp
.
isfile
(
flag
):
return
flag
...
...
@@ -116,7 +115,6 @@ def get_sensitivities(flag, model, save_dir):
paddlex
.
utils
.
download
(
url
,
path
=
save_dir
)
return
osp
.
join
(
save_dir
,
fname
)
# try:
# hub.download(fname, save_path=save_dir)
# except Exception as e:
...
...
@@ -126,7 +124,7 @@ def get_sensitivities(flag, model, save_dir):
# model_type, fname))
# elif isinstance(e, hub.ServerConnectionError):
# raise Exception(
# "Cannot get reource for model {}(key='{}'), please check your internet connec
g
tion"
# "Cannot get reource for model {}(key='{}'), please check your internet connection"
# .format(model_type, fname))
# else:
# raise Exception(
...
...
@@ -162,27 +160,29 @@ def get_prune_params(model):
if
model_type
==
'AlexNet'
:
prune_names
.
remove
(
'conv5_weights'
)
if
model_type
==
'ShuffleNetV2'
:
not_prune_names
=
[
'stage_2_1_conv5_weights'
,
'stage_2_1_conv3_weights'
,
'stage_2_2_conv3_weights'
,
'stage_2_3_conv3_weights'
,
'stage_2_4_conv3_weights'
,
'stage_3_1_conv5_weights'
,
'stage_3_1_conv3_weights'
,
'stage_3_2_conv3_weights'
,
'stage_3_3_conv3_weights'
,
'stage_3_4_conv3_weights'
,
'stage_3_5_conv3_weights'
,
'stage_3_6_conv3_weights'
,
'stage_3_7_conv3_weights'
,
'stage_3_8_conv3_weights'
,
'stage_4_1_conv5_weights'
,
'stage_4_1_conv3_weights'
,
'stage_4_2_conv3_weights'
,
'stage_4_3_conv3_weights'
,
'stage_4_4_conv3_weights'
,]
not_prune_names
=
[
'stage_2_1_conv5_weights'
,
'stage_2_1_conv3_weights'
,
'stage_2_2_conv3_weights'
,
'stage_2_3_conv3_weights'
,
'stage_2_4_conv3_weights'
,
'stage_3_1_conv5_weights'
,
'stage_3_1_conv3_weights'
,
'stage_3_2_conv3_weights'
,
'stage_3_3_conv3_weights'
,
'stage_3_4_conv3_weights'
,
'stage_3_5_conv3_weights'
,
'stage_3_6_conv3_weights'
,
'stage_3_7_conv3_weights'
,
'stage_3_8_conv3_weights'
,
'stage_4_1_conv5_weights'
,
'stage_4_1_conv3_weights'
,
'stage_4_2_conv3_weights'
,
'stage_4_3_conv3_weights'
,
'stage_4_4_conv3_weights'
,
]
for
name
in
not_prune_names
:
prune_names
.
remove
(
name
)
prune_names
.
remove
(
name
)
elif
model_type
==
"MobileNetV1"
:
prune_names
.
append
(
"conv1_weights"
)
for
param
in
program
.
global_block
().
all_parameters
():
...
...
paddlex/cv/models/utils/pretrain_weights.py
浏览文件 @
56f76f5f
...
...
@@ -65,6 +65,8 @@ image_pretrain = {
'https://paddle-imagenet-models-name.bj.bcebos.com/HRNet_W32_C_pretrained.tar'
,
'HRNet_W40'
:
'https://paddle-imagenet-models-name.bj.bcebos.com/HRNet_W40_C_pretrained.tar'
,
'HRNet_W44'
:
'https://paddle-imagenet-models-name.bj.bcebos.com/HRNet_W44_C_pretrained.tar'
,
'HRNet_W48'
:
'https://paddle-imagenet-models-name.bj.bcebos.com/HRNet_W48_C_pretrained.tar'
,
'HRNet_W60'
:
...
...
@@ -201,7 +203,7 @@ def get_pretrain_weights(flag, class_name, backbone, save_dir):
backbone
))
elif
isinstance
(
e
,
hub
.
ServerConnectionError
):
raise
Exception
(
"Cannot get reource for backbone {}, please check your internet connec
g
tion"
"Cannot get reource for backbone {}, please check your internet connection"
.
format
(
backbone
))
else
:
raise
Exception
(
...
...
@@ -229,7 +231,7 @@ def get_pretrain_weights(flag, class_name, backbone, save_dir):
backbone
))
elif
isinstance
(
hub
.
ServerConnectionError
):
raise
Exception
(
"Cannot get reource for backbone {}, please check your internet connec
g
tion"
"Cannot get reource for backbone {}, please check your internet connection"
.
format
(
backbone
))
else
:
raise
Exception
(
...
...
paddlex/cv/models/yolo_v3.py
浏览文件 @
56f76f5f
...
...
@@ -17,13 +17,16 @@ import math
import
tqdm
import
os.path
as
osp
import
numpy
as
np
from
multiprocessing.pool
import
ThreadPool
import
paddle.fluid
as
fluid
import
paddlex.utils.logging
as
logging
import
paddlex
import
copy
from
paddlex.cv.transforms
import
arrange_transforms
from
paddlex.cv.datasets
import
generate_minibatch
from
.base
import
BaseAPI
from
collections
import
OrderedDict
from
.utils.detection_eval
import
eval_results
,
bbox2out
import
copy
class
YOLOv3
(
BaseAPI
):
...
...
@@ -286,7 +289,11 @@ class YOLOv3(BaseAPI):
eval_details为dict,包含关键字:'bbox',对应元素预测结果列表,每个预测结果由图像id、
预测框类别id、预测框坐标、预测框得分;’gt‘:真实标注框相关信息。
"""
self
.
arrange_transforms
(
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
arrange_transforms
(
model_type
=
self
.
model_type
,
class_name
=
self
.
__class__
.
__name__
,
transforms
=
eval_dataset
.
transforms
,
mode
=
'eval'
)
if
metric
is
None
:
if
hasattr
(
self
,
'metric'
)
and
self
.
metric
is
not
None
:
metric
=
self
.
metric
...
...
@@ -306,8 +313,9 @@ class YOLOv3(BaseAPI):
data_generator
=
eval_dataset
.
generator
(
batch_size
=
batch_size
,
drop_last
=
False
)
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
logging
.
info
(
"Start to evaluating(total_samples={}, total_steps={})..."
.
format
(
eval_dataset
.
num_samples
,
total_steps
))
for
step
,
data
in
tqdm
.
tqdm
(
enumerate
(
data_generator
()),
total
=
total_steps
):
images
=
np
.
array
([
d
[
0
]
for
d
in
data
])
...
...
@@ -345,11 +353,43 @@ class YOLOv3(BaseAPI):
return
evaluate_metrics
,
eval_details
return
evaluate_metrics
@
staticmethod
def
_preprocess
(
images
,
transforms
,
model_type
,
class_name
,
thread_num
=
1
):
arrange_transforms
(
model_type
=
model_type
,
class_name
=
class_name
,
transforms
=
transforms
,
mode
=
'test'
)
pool
=
ThreadPool
(
thread_num
)
batch_data
=
pool
.
map
(
transforms
,
images
)
pool
.
close
()
pool
.
join
()
padding_batch
=
generate_minibatch
(
batch_data
)
im
=
np
.
array
(
[
data
[
0
]
for
data
in
padding_batch
],
dtype
=
padding_batch
[
0
][
0
].
dtype
)
im_size
=
np
.
array
([
data
[
1
]
for
data
in
padding_batch
],
dtype
=
np
.
int32
)
return
im
,
im_size
@
staticmethod
def
_postprocess
(
res
,
batch_size
,
num_classes
,
labels
):
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
num_classes
)})
xywh_results
=
bbox2out
([
res
],
clsid2catid
)
preds
=
[[]
for
i
in
range
(
batch_size
)]
for
xywh_res
in
xywh_results
:
image_id
=
xywh_res
[
'image_id'
]
del
xywh_res
[
'image_id'
]
xywh_res
[
'category'
]
=
labels
[
xywh_res
[
'category_id'
]]
preds
[
image_id
].
append
(
xywh_res
)
return
preds
def
predict
(
self
,
img_file
,
transforms
=
None
):
"""预测。
Args:
img_file (str
): 预测图像路径
。
img_file (str
|np.ndarray): 预测图像路径,或者是解码后的排列格式为(H, W, C)且类型为float32且为BGR格式的数组
。
transforms (paddlex.det.transforms): 数据预处理操作。
Returns:
...
...
@@ -359,32 +399,74 @@ class YOLOv3(BaseAPI):
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
transforms
is
not
None
:
self
.
arrange_transforms
(
transforms
=
transforms
,
mode
=
'test'
)
im
,
im_size
=
transforms
(
img_file
)
if
isinstance
(
img_file
,
(
str
,
np
.
ndarray
)):
images
=
[
img_file
]
else
:
self
.
arrange_transforms
(
transforms
=
self
.
test_transforms
,
mode
=
'test'
)
im
,
im_size
=
self
.
test_transforms
(
img_file
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
)
im_size
=
np
.
expand_dims
(
im_size
,
axis
=
0
)
raise
Exception
(
"img_file must be str/np.ndarray"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_size
=
YOLOv3
.
_preprocess
(
images
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
)
with
fluid
.
scope_guard
(
self
.
scope
):
outputs
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_size'
:
im_size
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_size'
:
im_size
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
res
=
{
k
:
(
np
.
array
(
v
),
v
.
recursive_sequence_lengths
())
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
outputs
)
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
result
)
}
res
[
'im_id'
]
=
(
np
.
array
([[
0
]]).
astype
(
'int32'
),
[])
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
self
.
num_classes
)})
xywh_results
=
bbox2out
([
res
],
clsid2catid
)
results
=
list
()
for
xywh_res
in
xywh_results
:
del
xywh_res
[
'image_id'
]
xywh_res
[
'category'
]
=
self
.
labels
[
xywh_res
[
'category_id'
]]
results
.
append
(
xywh_res
)
return
results
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
len
(
images
))]).
astype
(
'int32'
),
[[]])
preds
=
YOLOv3
.
_postprocess
(
res
,
len
(
images
),
self
.
num_classes
,
self
.
labels
)
return
preds
[
0
]
def
batch_predict
(
self
,
img_file_list
,
transforms
=
None
,
thread_num
=
2
):
"""预测。
Args:
img_file_list (list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是图像路径,也可以是解码后的排列格式为(H,W,C)
且类型为float32且为BGR格式的数组。
transforms (paddlex.det.transforms): 数据预处理操作。
thread_num (int): 并发执行各图像预处理时的线程数。
Returns:
list: 每个元素都为列表,表示各图像的预测结果。在各图像的预测结果列表中,每个预测结果由预测框类别标签、
预测框类别名称、预测框坐标(坐标格式为[xmin, ymin, w, h])、
预测框得分组成。
"""
if
transforms
is
None
and
not
hasattr
(
self
,
'test_transforms'
):
raise
Exception
(
"transforms need to be defined, now is None."
)
if
not
isinstance
(
img_file_list
,
(
list
,
tuple
)):
raise
Exception
(
"im_file must be list/tuple"
)
if
transforms
is
None
:
transforms
=
self
.
test_transforms
im
,
im_size
=
YOLOv3
.
_preprocess
(
img_file_list
,
transforms
,
self
.
model_type
,
self
.
__class__
.
__name__
,
thread_num
)
with
fluid
.
scope_guard
(
self
.
scope
):
result
=
self
.
exe
.
run
(
self
.
test_prog
,
feed
=
{
'image'
:
im
,
'im_size'
:
im_size
},
fetch_list
=
list
(
self
.
test_outputs
.
values
()),
return_numpy
=
False
,
use_program_cache
=
True
)
res
=
{
k
:
(
np
.
array
(
v
),
v
.
recursive_sequence_lengths
())
for
k
,
v
in
zip
(
list
(
self
.
test_outputs
.
keys
()),
result
)
}
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
len
(
img_file_list
))]).
astype
(
'int32'
),
[[]])
preds
=
YOLOv3
.
_postprocess
(
res
,
len
(
img_file_list
),
self
.
num_classes
,
self
.
labels
)
return
preds
paddlex/cv/transforms/__init__.py
浏览文件 @
56f76f5f
...
...
@@ -15,5 +15,87 @@
from
.
import
cls_transforms
from
.
import
det_transforms
from
.
import
seg_transforms
from
.
import
visualize
visualize
=
visualize
.
visualize
def
build_transforms
(
model_type
,
transforms_info
,
to_rgb
=
True
):
if
model_type
==
"classifier"
:
from
.
import
cls_transforms
as
T
elif
model_type
==
"detector"
:
from
.
import
det_transforms
as
T
elif
model_type
==
"segmenter"
:
from
.
import
seg_transforms
as
T
transforms
=
list
()
for
op_info
in
transforms_info
:
op_name
=
list
(
op_info
.
keys
())[
0
]
op_attr
=
op_info
[
op_name
]
if
not
hasattr
(
T
,
op_name
):
raise
Exception
(
"There's no operator named '{}' in transforms of {}"
.
format
(
op_name
,
model_type
))
transforms
.
append
(
getattr
(
T
,
op_name
)(
**
op_attr
))
eval_transforms
=
T
.
Compose
(
transforms
)
eval_transforms
.
to_rgb
=
to_rgb
return
eval_transforms
def
build_transforms_v1
(
model_type
,
transforms_info
,
batch_transforms_info
):
""" 老版本模型加载,仅支持PaddleX前端导出的模型
"""
logging
.
debug
(
"Use build_transforms_v1 to reconstruct transforms"
)
if
model_type
==
"classifier"
:
from
.
import
cls_transforms
as
T
elif
model_type
==
"detector"
:
from
.
import
det_transforms
as
T
elif
model_type
==
"segmenter"
:
from
.
import
seg_transforms
as
T
transforms
=
list
()
for
op_info
in
transforms_info
:
op_name
=
op_info
[
0
]
op_attr
=
op_info
[
1
]
if
op_name
==
'DecodeImage'
:
continue
if
op_name
==
'Permute'
:
continue
if
op_name
==
'ResizeByShort'
:
op_attr_new
=
dict
()
if
'short_size'
in
op_attr
:
op_attr_new
[
'short_size'
]
=
op_attr
[
'short_size'
]
else
:
op_attr_new
[
'short_size'
]
=
op_attr
[
'target_size'
]
op_attr_new
[
'max_size'
]
=
op_attr
.
get
(
'max_size'
,
-
1
)
op_attr
=
op_attr_new
if
op_name
.
startswith
(
'Arrange'
):
continue
if
not
hasattr
(
T
,
op_name
):
raise
Exception
(
"There's no operator named '{}' in transforms of {}"
.
format
(
op_name
,
model_type
))
transforms
.
append
(
getattr
(
T
,
op_name
)(
**
op_attr
))
if
model_type
==
"detector"
and
len
(
batch_transforms_info
)
>
0
:
op_name
=
batch_transforms_info
[
0
][
0
]
op_attr
=
batch_transforms_info
[
0
][
1
]
assert
op_name
==
"PaddingMiniBatch"
,
"Only PaddingMiniBatch transform is supported for batch transform"
padding
=
T
.
Padding
(
coarsest_stride
=
op_attr
[
'coarsest_stride'
])
transforms
.
append
(
padding
)
eval_transforms
=
T
.
Compose
(
transforms
)
return
eval_transforms
def
arrange_transforms
(
model_type
,
class_name
,
transforms
,
mode
=
'train'
):
# 给transforms添加arrange操作
if
model_type
==
'classifier'
:
arrange_transform
=
cls_transforms
.
ArrangeClassifier
elif
model_type
==
'segmenter'
:
arrange_transform
=
seg_transforms
.
ArrangeSegmenter
elif
model_type
==
'detector'
:
arrange_name
=
'Arrange{}'
.
format
(
class_name
)
arrange_transform
=
getattr
(
det_transforms
,
arrange_name
)
else
:
raise
Exception
(
"Unrecognized model type: {}"
.
format
(
self
.
model_type
))
if
type
(
transforms
.
transforms
[
-
1
]).
__name__
.
startswith
(
'Arrange'
):
transforms
.
transforms
[
-
1
]
=
arrange_transform
(
mode
=
mode
)
else
:
transforms
.
transforms
.
append
(
arrange_transform
(
mode
=
mode
))
paddlex/cv/transforms/cls_transforms.py
浏览文件 @
56f76f5f
...
...
@@ -68,13 +68,14 @@ class Compose(ClsTransform):
if
isinstance
(
im
,
np
.
ndarray
):
if
len
(
im
.
shape
)
!=
3
:
raise
Exception
(
"im should be 3-dimension, but now is {}-dimensions"
.
format
(
len
(
im
.
shape
)))
"im should be 3-dimension, but now is {}-dimensions"
.
format
(
len
(
im
.
shape
)))
else
:
try
:
im
=
cv2
.
imread
(
im
)
.
astype
(
'float32'
)
im
=
cv2
.
imread
(
im
)
except
:
raise
TypeError
(
'Can
\'
t read The image file {}!'
.
format
(
im
))
im
=
im
.
astype
(
'float32'
)
im
=
cv2
.
cvtColor
(
im
,
cv2
.
COLOR_BGR2RGB
)
for
op
in
self
.
transforms
:
if
isinstance
(
op
,
ClsTransform
):
...
...
@@ -139,8 +140,8 @@ class RandomCrop(ClsTransform):
tuple: 当label为空时,返回的tuple为(im, ),对应图像np.ndarray数据;
当label不为空时,返回的tuple为(im, label),分别对应图像np.ndarray数据、图像类别id。
"""
im
=
random_crop
(
im
,
self
.
crop_size
,
self
.
lower_scale
,
self
.
lower_ratio
,
self
.
upper_ratio
)
im
=
random_crop
(
im
,
self
.
crop_size
,
self
.
lower_scale
,
self
.
lower_ratio
,
self
.
upper_ratio
)
if
label
is
None
:
return
(
im
,
)
else
:
...
...
@@ -270,12 +271,14 @@ class ResizeByShort(ClsTransform):
im_short_size
=
min
(
im
.
shape
[
0
],
im
.
shape
[
1
])
im_long_size
=
max
(
im
.
shape
[
0
],
im
.
shape
[
1
])
scale
=
float
(
self
.
short_size
)
/
im_short_size
if
self
.
max_size
>
0
and
np
.
round
(
scale
*
im_long_size
)
>
self
.
max_size
:
if
self
.
max_size
>
0
and
np
.
round
(
scale
*
im_long_size
)
>
self
.
max_size
:
scale
=
float
(
self
.
max_size
)
/
float
(
im_long_size
)
resized_width
=
int
(
round
(
im
.
shape
[
1
]
*
scale
))
resized_height
=
int
(
round
(
im
.
shape
[
0
]
*
scale
))
im
=
cv2
.
resize
(
im
,
(
resized_width
,
resized_height
),
interpolation
=
cv2
.
INTER_LINEAR
)
im
,
(
resized_width
,
resized_height
),
interpolation
=
cv2
.
INTER_LINEAR
)
if
label
is
None
:
return
(
im
,
)
...
...
paddlex/cv/transforms/det_transforms.py
浏览文件 @
56f76f5f
...
...
@@ -108,10 +108,11 @@ class Compose(DetTransform):
im
=
im_file
else
:
try
:
im
=
cv2
.
imread
(
im_file
)
.
astype
(
'float32'
)
im
=
cv2
.
imread
(
im_file
)
except
:
raise
TypeError
(
'Can
\'
t read The image file {}!'
.
format
(
im_file
))
im
=
im
.
astype
(
'float32'
)
im
=
cv2
.
cvtColor
(
im
,
cv2
.
COLOR_BGR2RGB
)
# make default im_info with [h, w, 1]
im_info
[
'im_resize_info'
]
=
np
.
array
(
...
...
@@ -220,13 +221,15 @@ class ResizeByShort(DetTransform):
im_short_size
=
min
(
im
.
shape
[
0
],
im
.
shape
[
1
])
im_long_size
=
max
(
im
.
shape
[
0
],
im
.
shape
[
1
])
scale
=
float
(
self
.
short_size
)
/
im_short_size
if
self
.
max_size
>
0
and
np
.
round
(
scale
*
im_long_size
)
>
self
.
max_size
:
if
self
.
max_size
>
0
and
np
.
round
(
scale
*
im_long_size
)
>
self
.
max_size
:
scale
=
float
(
self
.
max_size
)
/
float
(
im_long_size
)
resized_width
=
int
(
round
(
im
.
shape
[
1
]
*
scale
))
resized_height
=
int
(
round
(
im
.
shape
[
0
]
*
scale
))
im_resize_info
=
[
resized_height
,
resized_width
,
scale
]
im
=
cv2
.
resize
(
im
,
(
resized_width
,
resized_height
),
interpolation
=
cv2
.
INTER_LINEAR
)
im
,
(
resized_width
,
resized_height
),
interpolation
=
cv2
.
INTER_LINEAR
)
im_info
[
'im_resize_info'
]
=
np
.
array
(
im_resize_info
).
astype
(
np
.
float32
)
if
label_info
is
None
:
return
(
im
,
im_info
)
...
...
@@ -266,7 +269,8 @@ class Padding(DetTransform):
if
not
isinstance
(
target_size
,
tuple
)
and
not
isinstance
(
target_size
,
list
):
raise
TypeError
(
"Padding: Type of target_size must in (int|list|tuple)."
)
"Padding: Type of target_size must in (int|list|tuple)."
)
elif
len
(
target_size
)
!=
2
:
raise
ValueError
(
"Padding: Length of target_size must equal 2."
)
...
...
@@ -451,7 +455,8 @@ class RandomHorizontalFlip(DetTransform):
ValueError: 数据长度不匹配。
"""
if
not
isinstance
(
im
,
np
.
ndarray
):
raise
TypeError
(
"RandomHorizontalFlip: image is not a numpy array."
)
raise
TypeError
(
"RandomHorizontalFlip: image is not a numpy array."
)
if
len
(
im
.
shape
)
!=
3
:
raise
ValueError
(
"RandomHorizontalFlip: image is not 3-dimensional."
)
...
...
@@ -782,7 +787,9 @@ class RandomExpand(DetTransform):
fill_value (list): 扩张图像的初始填充值(0-255)。默认为[123.675, 116.28, 103.53]。
"""
def
__init__
(
self
,
ratio
=
4.
,
prob
=
0.5
,
def
__init__
(
self
,
ratio
=
4.
,
prob
=
0.5
,
fill_value
=
[
123.675
,
116.28
,
103.53
]):
super
(
RandomExpand
,
self
).
__init__
()
assert
ratio
>
1.01
,
"expand ratio must be larger than 1.01"
...
...
paddlex/cv/transforms/seg_transforms.py
浏览文件 @
56f76f5f
...
...
@@ -81,9 +81,10 @@ class Compose(SegTransform):
format
(
len
(
im
.
shape
)))
else
:
try
:
im
=
cv2
.
imread
(
im
)
.
astype
(
'float32'
)
im
=
cv2
.
imread
(
im
)
except
:
raise
ValueError
(
'Can
\'
t read The image file {}!'
.
format
(
im
))
im
=
im
.
astype
(
'float32'
)
if
self
.
to_rgb
:
im
=
cv2
.
cvtColor
(
im
,
cv2
.
COLOR_BGR2RGB
)
if
label
is
not
None
:
...
...
@@ -399,7 +400,8 @@ class ResizeByShort(SegTransform):
im_short_size
=
min
(
im
.
shape
[
0
],
im
.
shape
[
1
])
im_long_size
=
max
(
im
.
shape
[
0
],
im
.
shape
[
1
])
scale
=
float
(
self
.
short_size
)
/
im_short_size
if
self
.
max_size
>
0
and
np
.
round
(
scale
*
im_long_size
)
>
self
.
max_size
:
if
self
.
max_size
>
0
and
np
.
round
(
scale
*
im_long_size
)
>
self
.
max_size
:
scale
=
float
(
self
.
max_size
)
/
float
(
im_long_size
)
resized_width
=
int
(
round
(
im
.
shape
[
1
]
*
scale
))
resized_height
=
int
(
round
(
im
.
shape
[
0
]
*
scale
))
...
...
paddlex/deploy.py
浏览文件 @
56f76f5f
...
...
@@ -18,6 +18,8 @@ import numpy as np
import
yaml
import
paddlex
import
paddle.fluid
as
fluid
from
paddlex.cv.transforms
import
build_transforms
from
paddlex.cv.models
import
BaseClassifier
,
YOLOv3
,
FasterRCNN
,
MaskRCNN
,
DeepLabv3p
class
Predictor
:
...
...
@@ -68,8 +70,8 @@ class Predictor:
to_rgb
=
True
else
:
to_rgb
=
False
self
.
transforms
=
self
.
build_transforms
(
self
.
info
[
'Transforms'
]
,
to_rgb
)
self
.
transforms
=
build_transforms
(
self
.
model_type
,
self
.
info
[
'Transforms'
],
to_rgb
)
self
.
predictor
=
self
.
create_predictor
(
use_gpu
,
gpu_id
,
use_mkl
,
use_trt
,
use_glog
,
memory_optimize
)
...
...
@@ -105,77 +107,101 @@ class Predictor:
predictor
=
fluid
.
core
.
create_paddle_predictor
(
config
)
return
predictor
def
build_transforms
(
self
,
transforms_info
,
to_rgb
=
True
):
if
self
.
model_type
==
"classifier"
:
from
paddlex.cls
import
transforms
elif
self
.
model_type
==
"detector"
:
from
paddlex.det
import
transforms
elif
self
.
model_type
==
"segmenter"
:
from
paddlex.seg
import
transforms
op_list
=
list
()
for
op_info
in
transforms_info
:
op_name
=
list
(
op_info
.
keys
())[
0
]
op_attr
=
op_info
[
op_name
]
if
not
hasattr
(
transforms
,
op_name
):
raise
Exception
(
"There's no operator named '{}' in transforms of {}"
.
format
(
op_name
,
self
.
model_type
))
op_list
.
append
(
getattr
(
transforms
,
op_name
)(
**
op_attr
))
eval_transforms
=
transforms
.
Compose
(
op_list
)
if
hasattr
(
eval_transforms
,
'to_rgb'
):
eval_transforms
.
to_rgb
=
to_rgb
self
.
arrange_transforms
(
eval_transforms
)
return
eval_transforms
def
arrange_transforms
(
self
,
transforms
):
if
self
.
model_type
==
'classifier'
:
arrange_transform
=
paddlex
.
cls
.
transforms
.
ArrangeClassifier
elif
self
.
model_type
==
'segmenter'
:
arrange_transform
=
paddlex
.
seg
.
transforms
.
ArrangeSegmenter
elif
self
.
model_type
==
'detector'
:
arrange_name
=
'Arrange{}'
.
format
(
self
.
model_name
)
arrange_transform
=
getattr
(
paddlex
.
det
.
transforms
,
arrange_name
)
else
:
raise
Exception
(
"Unrecognized model type: {}"
.
format
(
self
.
model_type
))
if
type
(
transforms
.
transforms
[
-
1
]).
__name__
.
startswith
(
'Arrange'
):
transforms
.
transforms
[
-
1
]
=
arrange_transform
(
mode
=
'test'
)
else
:
transforms
.
transforms
.
append
(
arrange_transform
(
mode
=
'test'
))
def
preprocess
(
self
,
image
):
def
preprocess
(
self
,
image
,
thread_num
=
1
):
""" 对图像做预处理
Args:
image(str|np.ndarray): 图片路径或np.ndarray,如为后者,要求是BGR格式
image(list|tuple): 数组中的元素可以是图像路径,也可以是解码后的排列格式为(H,W,C)
且类型为float32且为BGR格式的数组。
"""
res
=
dict
()
if
self
.
model_type
==
"classifier"
:
im
,
=
self
.
transforms
(
image
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
).
copy
()
im
=
BaseClassifier
.
_preprocess
(
image
,
self
.
transforms
,
self
.
model_type
,
self
.
model_name
,
thread_num
=
thread_num
)
res
[
'image'
]
=
im
elif
self
.
model_type
==
"detector"
:
if
self
.
model_name
==
"YOLOv3"
:
im
,
im_shape
=
self
.
transforms
(
image
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
).
copy
()
im_shape
=
np
.
expand_dims
(
im_shape
,
axis
=
0
).
copy
()
im
,
im_size
=
YOLOv3
.
_preprocess
(
image
,
self
.
transforms
,
self
.
model_type
,
self
.
model_name
,
thread_num
=
thread_num
)
res
[
'image'
]
=
im
res
[
'im_size'
]
=
im_s
hap
e
res
[
'im_size'
]
=
im_s
iz
e
if
self
.
model_name
.
count
(
'RCNN'
)
>
0
:
im
,
im_resize_info
,
im_shape
=
self
.
transforms
(
image
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
).
copy
()
im_resize_info
=
np
.
expand_dims
(
im_resize_info
,
axis
=
0
).
copy
()
im_shape
=
np
.
expand_dims
(
im_shape
,
axis
=
0
).
copy
()
im
,
im_resize_info
,
im_shape
=
FasterRCNN
.
_preprocess
(
image
,
self
.
transforms
,
self
.
model_type
,
self
.
model_name
,
thread_num
=
thread_num
)
res
[
'image'
]
=
im
res
[
'im_info'
]
=
im_resize_info
res
[
'im_shape'
]
=
im_shape
elif
self
.
model_type
==
"segmenter"
:
im
,
im_info
=
self
.
transforms
(
image
)
im
=
np
.
expand_dims
(
im
,
axis
=
0
).
copy
()
im
,
im_info
=
DeepLabv3p
.
_preprocess
(
image
,
self
.
transforms
,
self
.
model_type
,
self
.
model_name
,
thread_num
=
thread_num
)
res
[
'image'
]
=
im
res
[
'im_info'
]
=
im_info
return
res
def
postprocess
(
self
,
results
,
topk
=
1
,
batch_size
=
1
,
im_shape
=
None
,
im_info
=
None
):
""" 对预测结果做后处理
Args:
results (list): 预测结果
topk (int): 分类预测时前k个最大值
batch_size (int): 预测时图像批量大小
im_shape (list): MaskRCNN的图像输入大小
im_info (list):RCNN系列和分割网络的原图大小
"""
def
offset_to_lengths
(
lod
):
offset
=
lod
[
0
]
lengths
=
[
offset
[
i
+
1
]
-
offset
[
i
]
for
i
in
range
(
len
(
offset
)
-
1
)
]
return
[
lengths
]
if
self
.
model_type
==
"classifier"
:
true_topk
=
min
(
self
.
num_classes
,
topk
)
preds
=
BaseClassifier
.
_postprocess
([
results
[
0
][
0
]],
true_topk
,
self
.
labels
)
elif
self
.
model_type
==
"detector"
:
res
=
{
'bbox'
:
(
results
[
0
][
0
],
offset_to_lengths
(
results
[
0
][
1
])),
}
res
[
'im_id'
]
=
(
np
.
array
(
[[
i
]
for
i
in
range
(
batch_size
)]).
astype
(
'int32'
),
[[]])
if
self
.
model_name
==
"YOLOv3"
:
preds
=
YOLOv3
.
_postprocess
(
res
,
batch_size
,
self
.
num_classes
,
self
.
labels
)
elif
self
.
model_name
==
"FasterRCNN"
:
preds
=
FasterRCNN
.
_postprocess
(
res
,
batch_size
,
self
.
num_classes
,
self
.
labels
)
elif
self
.
model_name
==
"MaskRCNN"
:
res
[
'mask'
]
=
(
results
[
1
][
0
],
offset_to_lengths
(
results
[
1
][
1
]))
res
[
'im_shape'
]
=
(
im_shape
,
[])
preds
=
MaskRCNN
.
_postprocess
(
res
,
batch_size
,
self
.
num_classes
,
self
.
mask_head_resolution
,
self
.
labels
)
elif
self
.
model_type
==
"segmenter"
:
res
=
[
results
[
0
][
0
],
results
[
1
][
0
]]
preds
=
DeepLabv3p
.
_postprocess
(
res
,
im_info
)
return
preds
def
raw_predict
(
self
,
inputs
):
""" 接受预处理过后的数据进行预测
...
...
@@ -193,82 +219,54 @@ class Predictor:
output_results
=
list
()
for
name
in
output_names
:
output_tensor
=
self
.
predictor
.
get_output_tensor
(
name
)
output_results
.
append
(
output_tensor
.
copy_to_cpu
())
output_tensor_lod
=
output_tensor
.
lod
()
output_results
.
append
(
[
output_tensor
.
copy_to_cpu
(),
output_tensor_lod
])
return
output_results
def
classifier_postprocess
(
self
,
preds
,
topk
=
1
):
""" 对分类模型的预测结果做后处理
"""
true_topk
=
min
(
self
.
num_classes
,
topk
)
pred_label
=
np
.
argsort
(
preds
[
0
][
0
])[::
-
1
][:
true_topk
]
result
=
[{
'category_id'
:
l
,
'category'
:
self
.
labels
[
l
],
'score'
:
preds
[
0
][
0
,
l
],
}
for
l
in
pred_label
]
return
result
def
predict
(
self
,
image
,
topk
=
1
):
""" 图片预测
def
segmenter_postprocess
(
self
,
preds
,
preprocessed_inputs
):
""" 对语义分割结果做后处理
Args:
image(str|np.ndarray): 图像路径;或者是解码后的排列格式为(H, W, C)且类型为float32且为BGR格式的数组。
topk(int): 分类预测时使用,表示预测前topk的结果
"""
label_map
=
np
.
squeeze
(
preds
[
0
]).
astype
(
'uint8'
)
score_map
=
np
.
squeeze
(
preds
[
1
])
score_map
=
np
.
transpose
(
score_map
,
(
1
,
2
,
0
))
im_info
=
preprocessed_inputs
[
'im_info'
]
for
info
in
im_info
[::
-
1
]:
if
info
[
0
]
==
'resize'
:
w
,
h
=
info
[
1
][
1
],
info
[
1
][
0
]
label_map
=
cv2
.
resize
(
label_map
,
(
w
,
h
),
cv2
.
INTER_NEAREST
)
score_map
=
cv2
.
resize
(
score_map
,
(
w
,
h
),
cv2
.
INTER_LINEAR
)
elif
info
[
0
]
==
'padding'
:
w
,
h
=
info
[
1
][
1
],
info
[
1
][
0
]
label_map
=
label_map
[
0
:
h
,
0
:
w
]
score_map
=
score_map
[
0
:
h
,
0
:
w
,
:]
else
:
raise
Exception
(
"Unexpected info '{}' in im_info"
.
format
(
info
[
0
]))
return
{
'label_map'
:
label_map
,
'score_map'
:
score_map
}
preprocessed_input
=
self
.
preprocess
([
image
])
model_pred
=
self
.
raw_predict
(
preprocessed_input
)
im_shape
=
None
if
'im_shape'
not
in
preprocessed_input
else
preprocessed_input
[
'im_shape'
]
im_info
=
None
if
'im_info'
not
in
preprocessed_input
else
preprocessed_input
[
'im_info'
]
results
=
self
.
postprocess
(
model_pred
,
topk
=
topk
,
batch_size
=
1
,
im_shape
=
im_shape
,
im_info
=
im_info
)
def
detector_postprocess
(
self
,
preds
,
preprocessed_inputs
):
""" 对目标检测和实例分割结果做后处理
"""
bboxes
=
{
'bbox'
:
(
np
.
array
(
preds
[
0
]),
[[
len
(
preds
[
0
])]])}
bboxes
[
'im_id'
]
=
(
np
.
array
([[
0
]]).
astype
(
'int32'
),
[])
clsid2catid
=
dict
({
i
:
i
for
i
in
range
(
self
.
num_classes
)})
xywh_results
=
paddlex
.
cv
.
models
.
utils
.
detection_eval
.
bbox2out
(
[
bboxes
],
clsid2catid
)
results
=
list
()
for
xywh_res
in
xywh_results
:
del
xywh_res
[
'image_id'
]
xywh_res
[
'category'
]
=
self
.
labels
[
xywh_res
[
'category_id'
]]
results
.
append
(
xywh_res
)
if
len
(
preds
)
>
1
:
im_shape
=
preprocessed_inputs
[
'im_shape'
]
bboxes
[
'im_shape'
]
=
(
im_shape
,
[])
bboxes
[
'mask'
]
=
(
np
.
array
(
preds
[
1
]),
[[
len
(
preds
[
1
])]])
segm_results
=
paddlex
.
cv
.
models
.
utils
.
detection_eval
.
mask2out
(
[
bboxes
],
clsid2catid
,
self
.
mask_head_resolution
)
import
pycocotools.mask
as
mask_util
for
i
in
range
(
len
(
results
)):
results
[
i
][
'mask'
]
=
mask_util
.
decode
(
segm_results
[
i
][
'segmentation'
])
return
results
return
results
[
0
]
def
predict
(
self
,
image
,
topk
=
1
,
threshold
=
0.5
):
def
batch_predict
(
self
,
image_list
,
topk
=
1
,
thread_num
=
2
):
""" 图片预测
Args:
image(str|np.ndarray): 图片路径或np.ndarray格式,如果后者,要求为BGR输入格式
image_list(list|tuple): 对列表(或元组)中的图像同时进行预测,列表中的元素可以是图像路径
也可以是解码后的排列格式为(H,W,C)且类型为float32且为BGR格式的数组。
thread_num (int): 并发执行各图像预处理时的线程数。
topk(int): 分类预测时使用,表示预测前topk的结果
"""
preprocessed_input
=
self
.
preprocess
(
image
)
preprocessed_input
=
self
.
preprocess
(
image
_list
)
model_pred
=
self
.
raw_predict
(
preprocessed_input
)
im_shape
=
None
if
'im_shape'
not
in
preprocessed_input
else
preprocessed_input
[
'im_shape'
]
im_info
=
None
if
'im_info'
not
in
preprocessed_input
else
preprocessed_input
[
'im_info'
]
results
=
self
.
postprocess
(
model_pred
,
topk
=
topk
,
batch_size
=
len
(
image_list
),
im_shape
=
im_shape
,
im_info
=
im_info
)
if
self
.
model_type
==
"classifier"
:
results
=
self
.
classifier_postprocess
(
model_pred
,
topk
)
elif
self
.
model_type
==
"detector"
:
results
=
self
.
detector_postprocess
(
model_pred
,
preprocessed_input
)
elif
self
.
model_type
==
"segmenter"
:
results
=
self
.
segmenter_postprocess
(
model_pred
,
preprocessed_input
)
return
results
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}