Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleX
提交
5394a320
P
PaddleX
项目概览
PaddlePaddle
/
PaddleX
通知
138
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
43
列表
看板
标记
里程碑
合并请求
5
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleX
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
43
Issue
43
列表
看板
标记
里程碑
合并请求
5
合并请求
5
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
5394a320
编写于
7月 11, 2020
作者:
F
FlyingQianMM
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
modify exmaples in docs
上级
7ce67e43
变更
14
隐藏空白更改
内联
并排
Showing
14 changed file
with
649 addition
and
62 deletion
+649
-62
docs/examples/human_segmentation.md
docs/examples/human_segmentation.md
+205
-0
docs/examples/human_segmentation/index.rst
docs/examples/human_segmentation/index.rst
+0
-5
docs/examples/images/MeterReader_Architecture.jpg
docs/examples/images/MeterReader_Architecture.jpg
+0
-0
docs/examples/images/PaddleX_Panorama.png
docs/examples/images/PaddleX_Panorama.png
+0
-0
docs/examples/images/image_classification.png
docs/examples/images/image_classification.png
+0
-0
docs/examples/images/instance_segmentation.png
docs/examples/images/instance_segmentation.png
+0
-0
docs/examples/images/object_detection.png
docs/examples/images/object_detection.png
+0
-0
docs/examples/images/semantic_segmentation.png
docs/examples/images/semantic_segmentation.png
+0
-0
docs/examples/index.rst
docs/examples/index.rst
+5
-3
docs/examples/meter_reader.md
docs/examples/meter_reader.md
+272
-0
docs/examples/meter_reading/index.rst
docs/examples/meter_reading/index.rst
+0
-5
docs/examples/solutions.md
docs/examples/solutions.md
+84
-0
docs/quick_start.md
docs/quick_start.md
+1
-1
examples/human_segmentation/README.md
examples/human_segmentation/README.md
+82
-48
未找到文件。
docs/examples/human_segmentation.md
0 → 100644
浏览文件 @
5394a320
# 人像分割模型
本教程基于PaddleX核心分割模型实现人像分割,开放预训练模型和测试数据、支持视频流人像分割、提供模型Fine-tune到Paddle-Lite移动端部署的全流程应用指南。
## 预训练模型和测试数据
#### 预训练模型
本案例开放了两个在大规模人像数据集上训练好的模型,以满足服务器端场景和移动端场景的需求。使用这些模型可以快速体验视频流人像分割,也可以部署到移动端进行实时人像分割,也可以用于完成模型Fine-tuning。
| 模型类型 | Checkpoint Parameter | Inference Model | Quant Inference Model | 备注 |
| --- | --- | --- | ---| --- |
| HumanSeg-server |
[
humanseg_server_params
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_server.pdparams
)
|
[
humanseg_server_inference
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_server_inference.zip
)
| -- | 高精度模型,适用于服务端GPU且背景复杂的人像场景, 模型结构为Deeplabv3+/Xcetion65, 输入大小(512, 512) |
| HumanSeg-mobile |
[
humanseg_mobile_params
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile.pdparams
)
|
[
humanseg_mobile_inference
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile_inference.zip
)
|
[
humanseg_mobile_quant
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile_quant.zip
)
| 轻量级模型, 适用于移动端或服务端CPU的前置摄像头场景,模型结构为HRNet_w18_samll_v1,输入大小(192, 192) |
> * Checkpoint Parameter为模型权重,用于Fine-tuning场景。
> * Inference Model和Quant Inference Model为预测部署模型,包含`__model__`计算图结构、`__params__`模型参数和`model.yaml`基础的模型配置信息。
> * 其中Inference Model适用于服务端的CPU和GPU预测部署,Qunat Inference Model为量化版本,适用于通过Paddle Lite进行移动端等端侧设备部署。
预训练模型的存储大小和推理时长如下所示,其中移动端模型的运行环境为cpu:骁龙855,内存:6GB,图片大小:192
*
192
| 模型 | 模型大小 | 计算耗时 |
| --- | --- | --- |
|humanseg_server_inference| 158M | - |
|humanseg_mobile_inference | 5.8 M | 42.35ms |
|humanseg_mobile_quant | 1.6M | 24.93ms |
执行以下脚本下载全部的预训练模型:
```
bash
python pretrain_weights/download_pretrain_weights.py
```
#### 测试数据
[
supervise.ly
](
https://supervise.ly/
)
发布了人像分割数据集
**Supervisely Persons**
, 本案例从中随机抽取一小部分数据并转化成PaddleX可直接加载的数据格式,运行以下代码可下载该数据、以及手机前置摄像头拍摄的人像测试视频
`video_test.mp4`
.
```
bash
python data/download_data.py
```
## 快速体验视频流人像分割
#### 前置依赖
*
PaddlePaddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
../../docs/install.md
)
### 光流跟踪辅助的视频流人像分割
本案例将DIS(Dense Inverse Search-basedmethod)光流跟踪算法的预测结果与PaddleX的分割结果进行融合,以此改善视频流人像分割的效果。运行以下代码进行体验:
*
通过电脑摄像头进行实时分割处理
```
bash
python video_infer.py
--model_dir
pretrain_weights/humanseg_mobile_inference
```
*
对离线人像视频进行分割处理
```
bash
python video_infer.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--video_path
data/video_test.mp4
```
视频分割结果如下所示:
<img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/video_test.gif"
width=
"20%"
height=
"20%"
><img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/result.gif"
width=
"20%"
height=
"20%"
>
### 人像背景替换
本案例还实现了人像背景替换功能,根据所选背景对人像的背景画面进行替换,背景可以是一张图片,也可以是一段视频。
*
通过电脑摄像头进行实时背景替换处理, 通过'--background_video_path'传入背景视频
```
bash
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--background_image_path
data/background.jpg
```
*
对人像视频进行背景替换处理, 通过'--background_video_path'传入背景视频
```
bash
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--video_path
data/video_test.mp4
--background_image_path
data/background.jpg
```
*
对单张图像进行背景替换
```
bash
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--image_path
data/human_image.jpg
--background_image_path
data/background.jpg
```
背景替换结果如下:
<img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/video_test.gif"
width=
"20%"
height=
"20%"
><img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/bg_replace.gif"
width=
"20%"
height=
"20%"
>
**注意**
:
*
视频分割处理时间需要几分钟,请耐心等待。
*
提供的模型适用于手机摄像头竖屏拍摄场景,宽屏效果会略差一些。
## 模型Fine-tune
#### 前置依赖
*
PaddlePaddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
../../docs/install.md
)
### 模型训练
使用下述命令进行基于预训练模型的模型训练,请确保选用的模型结构
`model_type`
与模型参数
`pretrain_weights`
匹配。如果不需要本案例提供的测试数据,可更换数据、选择合适的模型并调整训练参数。
```
bash
# 指定GPU卡号(以0号卡为例)
export
CUDA_VISIBLE_DEVICES
=
0
# 若不使用GPU,则将CUDA_VISIBLE_DEVICES指定为空
# export CUDA_VISIBLE_DEVICES=
python train.py
--model_type
HumanSegMobile
\
--save_dir
output/
\
--data_dir
data/mini_supervisely
\
--train_list
data/mini_supervisely/train.txt
\
--val_list
data/mini_supervisely/val.txt
\
--pretrain_weights
pretrain_weights/humanseg_mobile_params
\
--batch_size
8
\
--learning_rate
0.001
\
--num_epochs
10
\
--image_shape
192 192
```
其中参数含义如下:
*
`--model_type`
: 模型类型,可选项为:HumanSegServer和HumanSegMobile
*
`--save_dir`
: 模型保存路径
*
`--data_dir`
: 数据集路径
*
`--train_list`
: 训练集列表路径
*
`--val_list`
: 验证集列表路径
*
`--pretrain_weights`
: 预训练模型路径
*
`--batch_size`
: 批大小
*
`--learning_rate`
: 初始学习率
*
`--num_epochs`
: 训练轮数
*
`--image_shape`
: 网络输入图像大小(w, h)
更多命令行帮助可运行下述命令进行查看:
```
bash
python train.py
--help
```
**注意**
:可以通过更换
`--model_type`
变量与对应的
`--pretrain_weights`
使用不同的模型快速尝试。
### 评估
使用下述命令对模型在验证集上的精度进行评估:
```
bash
python eval.py
--model_dir
output/best_model
\
--data_dir
data/mini_supervisely
\
--val_list
data/mini_supervisely/val.txt
\
--image_shape
192 192
```
其中参数含义如下:
*
`--model_dir`
: 模型路径
*
`--data_dir`
: 数据集路径
*
`--val_list`
: 验证集列表路径
*
`--image_shape`
: 网络输入图像大小(w, h)
### 预测
使用下述命令对测试集进行预测,预测可视化结果默认保存在
`./output/result/`
文件夹中。
```
bash
python infer.py
--model_dir
output/best_model
\
--data_dir
data/mini_supervisely
\
--test_list
data/mini_supervisely/test.txt
\
--save_dir
output/result
\
--image_shape
192 192
```
其中参数含义如下:
*
`--model_dir`
: 模型路径
*
`--data_dir`
: 数据集路径
*
`--test_list`
: 测试集列表路径
*
`--image_shape`
: 网络输入图像大小(w, h)
### 模型导出
在服务端部署的模型需要首先将模型导出为inference格式模型,导出的模型将包括
`__model__`
、
`__params__`
和
`model.yml`
三个文名,分别为模型的网络结构,模型权重和模型的配置文件(包括数据预处理参数等等)。在安装完PaddleX后,在命令行终端使用如下命令完成模型导出:
```
bash
paddlex
--export_inference
--model_dir
output/best_model
\
--save_dir
output/export
```
其中参数含义如下:
*
`--model_dir`
: 模型路径
*
`--save_dir`
: 导出模型保存路径
### 离线量化
```
bash
python quant_offline.py
--model_dir
output/best_model
\
--data_dir
data/mini_supervisely
\
--quant_list
data/mini_supervisely/val.txt
\
--save_dir
output/quant_offline
\
--image_shape
192 192
```
其中参数含义如下:
*
`--model_dir`
: 待量化模型路径
*
`--data_dir`
: 数据集路径
*
`--quant_list`
: 量化数据集列表路径,一般直接选择训练集或验证集
*
`--save_dir`
: 量化模型保存路径
*
`--image_shape`
: 网络输入图像大小(w, h)
## Paddle-Lite移动端部署
docs/examples/human_segmentation/index.rst
已删除
100755 → 0
浏览文件 @
7ce67e43
人像分割案例
=======================================
这里面写人像分割案例,可根据需求拆分为多个文档
docs/examples/images/MeterReader_Architecture.jpg
0 → 100644
浏览文件 @
5394a320
206.2 KB
docs/examples/images/PaddleX_Panorama.png
0 → 100644
浏览文件 @
5394a320
468.2 KB
docs/examples/images/image_classification.png
0 → 100644
浏览文件 @
5394a320
176.2 KB
docs/examples/images/instance_segmentation.png
0 → 100644
浏览文件 @
5394a320
213.8 KB
docs/examples/images/object_detection.png
0 → 100644
浏览文件 @
5394a320
214.7 KB
docs/examples/images/semantic_segmentation.png
0 → 100644
浏览文件 @
5394a320
212.3 KB
docs/examples/index.rst
浏览文件 @
5394a320
产业案例集
产业案例集
=======================================
=======================================
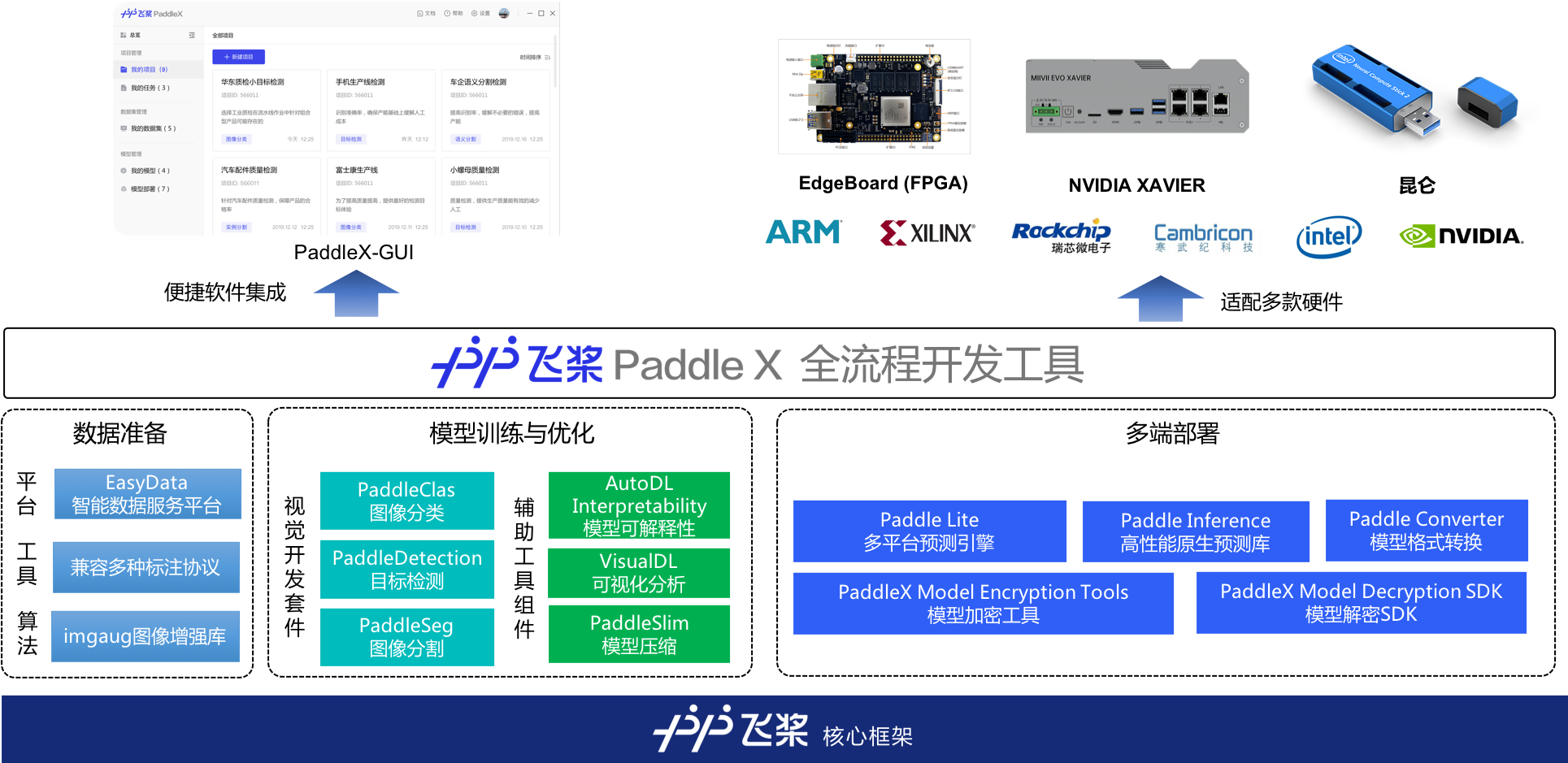
PaddleX精选飞桨视觉开发套件在产业实践中的成熟模型结构,提供统一易用的全流程API和模型部署SDK,打通模型在各种硬件设备上的部署流程,开放从模型训练到多端安全部署的全流程案例实践教程。
.. figure:: images/PaddleX_Panorama.png
.. toctree::
.. toctree::
:maxdepth: 2
:maxdepth: 2
:caption: 文档目录:
:caption: 文档目录:
solutions.md
solutions.md
meter_reading/index
meter_reader.md
human_segmentation/index
human_segmentation.md
remote_sensing/index
docs/examples/meter_reader.md
0 → 100644
浏览文件 @
5394a320
# 工业表计读数
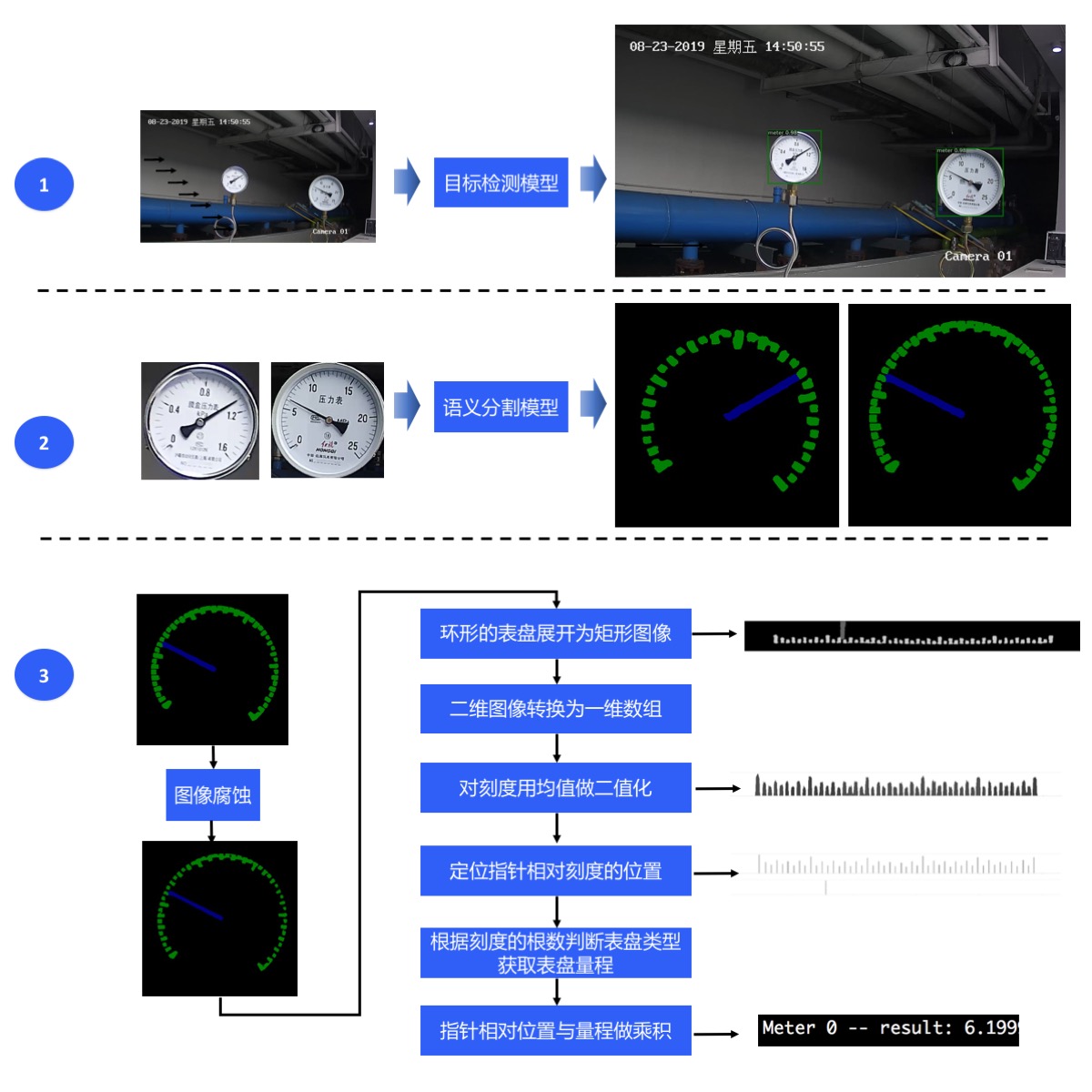
本案例基于PaddleX实现对传统机械式指针表计的检测与自动读数功能,开放表计数据和预训练模型,并提供在windows系统的服务器端以及linux系统的jetson嵌入式设备上的部署指南。
## 读数流程
表计读数共分为三个步骤完成:
*
第一步,使用目标检测模型检测出图像中的表计
*
第二步,使用语义分割模型将各表计的指针和刻度分割出来
*
第三步,根据指针的相对位置和预知的量程计算出各表计的读数

*
**表计检测**
:由于本案例中没有面积较小的表计,所以目标检测模型选择性能更优的
**YOLOv3**
。考虑到本案例主要在有GPU的设备上部署,所以骨干网路选择精度更高的
**DarkNet53**
。
*
**刻度和指针分割**
:考虑到刻度和指针均为细小区域,语义分割模型选择效果更好的
**DeepLapv3**
。
*
**读数后处理**
:首先,对语义分割的预测类别图进行图像腐蚀操作,以达到刻度细分的目的。然后把环形的表盘展开为矩形图像,根据图像中类别信息生成一维的刻度数组和一维的指针数组。接着计算刻度数组的均值,用均值对刻度数组进行二值化操作。最后定位出指针相对刻度的位置,根据刻度的根数判断表盘的类型以此获取表盘的量程,将指针相对位置与量程做乘积得到表盘的读数。
## 表计数据和预训练模型
本案例开放了表计测试图片,用于体验表计读数的预测推理全流程。还开放了表计检测数据集、指针和刻度分割数据集,用户可以使用这些数据集重新训练模型。
| 表计测试图片 | 表计检测数据集 | 指针和刻度分割数据集 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
[
meter_test
](
https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_test.tar.gz
)
|
[
meter_det
](
https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_det.tar.gz
)
|
[
meter_seg
](
https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_seg.tar.gz
)
|
本案例开放了预先训练好的检测模型和语义分割模型,可以使用这些模型快速体验表计读数全流程,也可以直接将这些模型部署在服务器端或jetson嵌入式设备上进行推理预测。
| 表计检测模型 | 指针和刻度分割模型 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|
[
meter_det_inference_model
](
https://bj.bcebos.com/paddlex/examples/meter_reader/models/meter_det_inference_model.tar.gz
)
|
[
meter_seg_inference_model
](
https://bj.bcebos.com/paddlex/examples/meter_reader/models/meter_seg_inference_model.tar.gz
)
|
## 快速体验表盘读数
可以使用本案例提供的预训练模型快速体验表计读数的自动预测全流程。如果不需要预训练模型,可以跳转至小节
`模型训练`
重新训练模型。
#### 前置依赖
*
Paddle paddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
../install.md
)
#### 测试表计读数
1.
下载PaddleX源码:
```
git clone https://github.com/PaddlePaddle/PaddleX
```
2.
预测执行文件位于
`PaddleX/examples/meter_reader/`
,进入该目录:
```
cd PaddleX/examples/meter_reader/
```
预测执行文件为
`reader_infer.py`
,其主要参数说明如下:
| 参数 | 说明 |
| ---- | ---- |
| detector_dir | 表计检测模型路径 |
| segmenter_dir | 指针和刻度分割模型路径|
| image | 待预测的图片路径 |
| image_dir | 存储待预测图片的文件夹路径 |
| save_dir | 保存可视化结果的路径, 默认值为"output"|
| score_threshold | 检测模型输出结果中,预测得分低于该阈值的框将被滤除,默认值为0.5|
| seg_batch_size | 分割的批量大小,默认为2 |
| seg_thread_num | 分割预测的线程数,默认为cpu处理器个数 |
| use_camera | 是否使用摄像头采集图片,默认为False |
| camera_id | 摄像头设备ID,默认值为0 |
| use_erode | 是否使用图像腐蚀对分割预测图进行细分,默认为False |
| erode_kernel | 图像腐蚀操作时的卷积核大小,默认值为4 |
3.
预测
若要使用GPU,则指定GPU卡号(以0号卡为例):
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
```
若不使用GPU,则将CUDA_VISIBLE_DEVICES指定为空:
```
shell
export
CUDA_VISIBLE_DEVICES
=
```
*
预测单张图片
```
shell
python3 reader_infer.py
--detector_dir
/path/to/det_inference_model
--segmenter_dir
/path/to/seg_inference_model
--image
/path/to/meter_test/20190822_168.jpg
--save_dir
./output
--use_erode
```
*
预测多张图片
```
shell
python3 reader_infer.py
--detector_dir
/path/to/det_inference_model
--segmenter_dir
/path/to/seg_inference_model
--image_dir
/path/to/meter_test
--save_dir
./output
--use_erode
```
*
开启摄像头预测
```
shell
python3 reader_infer.py
--detector_dir
/path/to/det_inference_model
--segmenter_dir
/path/to/seg_inference_model
--save_dir
./output
--use_erode
--use_camera
```
## 推理部署
### Windows系统的服务器端安全部署
#### c++部署
1.
下载PaddleX源码:
```
git clone https://github.com/PaddlePaddle/PaddleX
```
2.
将
`PaddleX\examples\meter_reader\deploy\cpp`
下的
`meter_reader`
文件夹和
`CMakeList.txt`
拷贝至
`PaddleX\deploy\cpp`
目录下,拷贝之前可以将
`PaddleX\deploy\cpp`
下原本的
`CMakeList.txt`
做好备份。
3.
按照
[
Windows平台部署
](
../deploy/server/cpp/windows.md
)
中的Step2至Step4完成C++预测代码的编译。
4.
编译成功后,可执行文件在
`out\build\x64-Release`
目录下,打开
`cmd`
,并切换到该目录:
```
cd PaddleX\deploy\cpp\out\build\x64-Release
```
预测程序为paddle_inference
\m
eter_reader.exe,其主要命令参数说明如下:
| 参数 | 说明 |
| ---- | ---- |
| det_model_dir | 表计检测模型路径 |
| seg_model_dir | 指针和刻度分割模型路径|
| image | 待预测的图片路径 |
| image_list | 按行存储图片路径的.txt文件 |
| use_gpu | 是否使用 GPU 预测, 支持值为0或1(默认值为0)|
| gpu_id | GPU 设备ID, 默认值为0 |
| save_dir | 保存可视化结果的路径, 默认值为"output"|
| det_key | 检测模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的检测模型 |
| seg_key | 分割模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的分割模型 |
| seg_batch_size | 分割的批量大小,默认为2 |
| thread_num | 分割预测的线程数,默认为cpu处理器个数 |
| use_camera | 是否使用摄像头采集图片,支持值为0或1(默认值为0) |
| camera_id | 摄像头设备ID,默认值为0 |
| use_erode | 是否使用图像腐蚀对分割预测图进行去噪,支持值为0或1(默认值为1) |
| erode_kernel | 图像腐蚀操作时的卷积核大小,默认值为4 |
| score_threshold | 检测模型输出结果中,预测得分低于该阈值的框将被滤除,默认值为0.5|
5.
推理预测:
用于部署推理的模型应为inference格式,本案例提供的预训练模型均为inference格式,如若是重新训练的模型,需参考
[
部署模型导出
](
../deploy/export_model.md
)
将模型导出为inference格式。
*
使用未加密的模型对单张图片做预测
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\d
et_inference_model
--seg_model_dir
=
\p
ath
\t
o
\s
eg_inference_model
--image
=
\p
ath
\t
o
\m
eter_test
\2
0190822_168.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型对图像列表做预测
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\d
et_inference_model
--seg_model_dir
=
\p
ath
\t
o
\s
eg_inference_model
--image_list
=
\p
ath
\t
o
\m
eter_test
\i
mage_list.txt
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型开启摄像头做预测
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\d
et_inference_model
--seg_model_dir
=
\p
ath
\t
o
\s
eg_inference_model
--use_camera
=
1
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用加密后的模型对单张图片做预测
如果未对模型进行加密,请参考
[
加密PaddleX模型
](
../deploy/server/encryption.html#paddlex
)
对模型进行加密。例如加密后的检测模型所在目录为
`\path\to\encrypted_det_inference_model`
,密钥为
`yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0=`
;加密后的分割模型所在目录为
`\path\to\encrypted_seg_inference_model`
,密钥为
`DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY=`
```
shell
.
\p
addlex_inference
\m
eter_reader.exe
--det_model_dir
=
\p
ath
\t
o
\e
ncrypted_det_inference_model
--seg_model_dir
=
\p
ath
\t
o
\e
ncrypted_seg_inference_model
--image
=
\p
ath
\t
o
\t
est.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
--det_key
yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0
=
--seg_key
DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY
=
```
### Linux系统的jeton嵌入式设备安全部署
#### c++部署
1.
下载PaddleX源码:
```
git clone https://github.com/PaddlePaddle/PaddleX
```
2.
将
`PaddleX/examples/meter_reader/deploy/cpp`
下的
`meter_reader`
文件夹和
`CMakeList.txt`
拷贝至
`PaddleX/deploy/cpp`
目录下,拷贝之前可以将
`PaddleX/deploy/cpp`
下原本的
`CMakeList.txt`
做好备份。
3.
按照
[
Nvidia-Jetson开发板部署
](
)中的Step2至Step3完成C++预测代码的编译。
4.
编译成功后,可执行程为
`build/meter_reader/meter_reader`
,其主要命令参数说明如下:
| 参数 | 说明 |
| ---- | ---- |
| det_model_dir | 表计检测模型路径 |
| seg_model_dir | 指针和刻度分割模型路径|
| image | 待预测的图片路径 |
| image_list | 按行存储图片路径的.txt文件 |
| use_gpu | 是否使用 GPU 预测, 支持值为0或1(默认值为0)|
| gpu_id | GPU 设备ID, 默认值为0 |
| save_dir | 保存可视化结果的路径, 默认值为"output"|
| det_key | 检测模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的检测模型 |
| seg_key | 分割模型加密过程中产生的密钥信息,默认值为""表示加载的是未加密的分割模型 |
| seg_batch_size | 分割的批量大小,默认为2 |
| thread_num | 分割预测的线程数,默认为cpu处理器个数 |
| use_camera | 是否使用摄像头采集图片,支持值为0或1(默认值为0) |
| camera_id | 摄像头设备ID,默认值为0 |
| use_erode | 是否使用图像腐蚀对分割预测图进行细分,支持值为0或1(默认值为1) |
| erode_kernel | 图像腐蚀操作时的卷积核大小,默认值为4 |
| score_threshold | 检测模型输出结果中,预测得分低于该阈值的框将被滤除,默认值为0.5|
5.
推理预测:
用于部署推理的模型应为inference格式,本案例提供的预训练模型均为inference格式,如若是重新训练的模型,需参考
[
部署模型导出
](
../deploy/export_model.md
)
将模型导出为inference格式。
*
使用未加密的模型对单张图片做预测
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/det_inference_model
--seg_model_dir
=
/path/to/seg_inference_model
--image
=
/path/to/meter_test/20190822_168.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型对图像列表做预测
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/det_inference_model
--seg_model_dir
=
/path/to/seg_inference_model
--image_list
=
/path/to/image_list.txt
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用未加密的模型开启摄像头做预测
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/det_inference_model
--seg_model_dir
=
/path/to/seg_inference_model
--use_camera
=
1
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
```
*
使用加密后的模型对单张图片做预测
如果未对模型进行加密,请参考
[
加密PaddleX模型
](
../deploy/server/encryption.html#paddlex
)
对模型进行加密。例如加密后的检测模型所在目录为
`/path/to/encrypted_det_inference_model`
,密钥为
`yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0=`
;加密后的分割模型所在目录为
`/path/to/encrypted_seg_inference_model`
,密钥为
`DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY=`
```
shell
./build/meter_reader/meter_reader
--det_model_dir
=
/path/to/encrypted_det_inference_model
--seg_model_dir
=
/path/to/encrypted_seg_inference_model
--image
=
/path/to/test.jpg
--use_gpu
=
1
--use_erode
=
1
--save_dir
=
output
--det_key
yEBLDiBOdlj+5EsNNrABhfDuQGkdcreYcHcncqwdbx0
=
--seg_key
DbVS64I9pFRo5XmQ8MNV2kSGsfEr4FKA6OH9OUhRrsY
=
```
## 模型训练
#### 前置依赖
*
Paddle paddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
../install.md
)
#### 训练
*
表盘检测的训练
```
python3 /path/to/PaddleX/examples/meter_reader/train_detection.py
```
*
指针和刻度分割的训练
```
python3 /path/to/PaddleX/examples/meter_reader/train_segmentation.py
```
运行以上脚本可以训练本案例的检测模型和分割模型。如果不需要本案例的数据和模型参数,可更换数据,选择合适的模型并调整训练参数。
docs/examples/meter_reading/index.rst
已删除
100755 → 0
浏览文件 @
7ce67e43
工业表计读数案例
=======================================
这里面写表计读数案例,可根据需求拆分为多个文档
docs/examples/solutions.md
浏览文件 @
5394a320
# PaddleX模型介绍
# PaddleX模型介绍
PaddleX针对图像分类、目标检测、实例分割和语义分割4种视觉任务提供了丰富的模型算法,用户根据在实际场景中的需求选择合适的模型。
## 图像分类
图像分类任务指的是输入一张图片,模型预测图片的类别,如识别为风景、动物、车等。

对于图像分类任务,针对不同的应用场景,PaddleX提供了百度改进的模型,见下表所示:
> 表中GPU预测速度是使用PaddlePaddle Python预测接口测试得到(测试GPU型号为Nvidia Tesla P40)。
> 表中CPU预测速度 (测试CPU型号为)。
> 表中骁龙855预测速度是使用处理器为骁龙855的手机测试得到。
> 测速时模型输入大小为224 x 224,Top1准确率为ImageNet-1000数据集上评估所得。
| 模型 | 模型特点 | 存储体积 | GPU预测速度(毫秒) | CPU(x86)预测速度(毫秒) | 骁龙855(ARM)预测速度 (毫秒)| Top1准确率 |
| :--------- | :------ | :---------- | :-----------| :------------- | :------------- |:--- |
| MobileNetV3_small_ssld | 轻量高速,适用于追求高速的实时移动端场景 | 12.5MB | 7.08837 | - | 6.546 | 71.3.0% |
| ShuffleNetV2 | 轻量级模型,精度相对偏低,适用于要求更小存储体积的实时移动端场景 | 10.2MB | 15.40 | - | 10.941 | 68.8% |
| MobileNetV3_large_ssld | 轻量级模型,在存储方面优势不大,在速度和精度上表现适中,适合于移动端场景 | 22.8MB | 8.06651 | - | 19.803 | 79.0% |
| MobileNetV2 | 轻量级模型,适用于使用GPU预测的移动端场景 | 15.0MB | 5.92667 | - | 23.318| 72.2 % |
| ResNet50_vd_ssld | 高精度模型,预测时间较短,适用于大多数的服务器端场景 | 103.5MB | 7.79264 | - | - | 82.4% |
| ResNet101_vd_ssld | 超高精度模型,预测时间相对较长,适用于有大数据量时的服务器端场景 | 180.5MB | 13.34580 | - | -| 83.7% |
| Xception65 | 超高精度模型,预测时间更长,在处理较大数据量时有较高的精度,适用于服务器端场景 | 161.6MB | 13.87017 | - | - | 80.3% |
包括上述模型,PaddleX支持近20种图像分类模型,其余模型可参考
[
PaddleX模型库
](
../appendix/model_zoo.md
)
## 目标检测
目标检测任务指的是输入图像,模型识别出图像中物体的位置(用矩形框框出来,并给出框的位置),和物体的类别,如在手机等零件质检中,用于检测外观上的瑕疵等。

对于目标检测,针对不同的应用场景,PaddleX提供了主流的YOLOv3模型和Faster-RCNN模型,见下表所示
> 表中GPU预测速度是使用PaddlePaddle Python预测接口测试得到(测试GPU型号为Nvidia Tesla P40)。
> 表中CPU预测速度 (测试CPU型号为)。
> 表中骁龙855预测速度是使用处理器为骁龙855的手机测试得到。
> 测速时YOLOv3的输入大小为608 x 608,FasterRCNN的输入大小为800 x 1333,Box mmAP为COCO2017数据集上评估所得。
| 模型 | 模型特点 | 存储体积 | GPU预测速度 | CPU(x86)预测速度(毫秒) | 骁龙855(ARM)预测速度 (毫秒)| Box mmAP |
| :------- | :------- | :--------- | :---------- | :------------- | :------------- |:--- |
| YOLOv3-MobileNetV3_larget | 适用于追求高速预测的移动端场景 | 100.7MB | 143.322 | - | - | 31.6 |
| YOLOv3-MobileNetV1 | 精度相对偏低,适用于追求高速预测的服务器端场景 | 99.2MB| 15.422 | - | - | 29.3 |
| YOLOv3-DarkNet53 | 在预测速度和模型精度上都有较好的表现,适用于大多数的服务器端场景| 249.2MB | 42.672 | - | - | 38.9 |
| FasterRCNN-ResNet50-FPN | 经典的二阶段检测器,预测速度相对较慢,适用于重视模型精度的服务器端场景 | 167.MB | 83.189 | - | -| 37.2 |
| FasterRCNN-HRNet_W18-FPN | 适用于对图像分辨率较为敏感、对目标细节预测要求更高的服务器端场景 | 115.5MB | 81.592 | - | - | 36 |
| FasterRCNN-ResNet101_vd-FPN | 超高精度模型,预测时间更长,在处理较大数据量时有较高的精度,适用于服务器端场景 | 244.3MB | 156.097 | - | - | 40.5 |
除上述模型外,YOLOv3和Faster RCNN还支持其他backbone,详情可参考
[
PaddleX模型库
](
../appendix/model_zoo.md
)
### 实例分割
在目标检测中,模型识别出图像中物体的位置和物体的类别。而实例分割则是在目标检测的基础上,做了像素级的分类,将框内的属于目标物体的像素识别出来。

PaddleX目前提供了实例分割MaskRCNN模型,支持5种不同的backbone网络,详情可参考
[
PaddleX模型库
](
../appendix/model_zoo.md
)
> 表中GPU预测速度是使用PaddlePaddle Python预测接口测试得到(测试GPU型号为Nvidia Tesla P40)。
> 表中CPU预测速度 (测试CPU型号为)。
> 表中骁龙855预测速度是使用处理器为骁龙855的手机测试得到。
> 测速时MaskRCNN的输入大小为800 x 1333,Box mmAP和Seg mmAP为COCO2017数据集上评估所得。
| 模型 | 模型特点 | 存储体积 | GPU预测速度 | CPU(x86)预测速度(毫秒) | 骁龙855(ARM)预测速度 (毫秒)| Box mmAP | Seg mmAP |
| :---- | :------- | :---------- | :---------- | :----- | :----- | :--- |:--- |
| MaskRCNN-HRNet_W18-FPN | 适用于对图像分辨率较为敏感、对目标细节预测要求更高的服务器端场景 | - | - | - | - | 37.0 | 33.4 |
| MaskRCNN-ResNet50-FPN | 精度较高,适合大多数的服务器端场景| 185.5M | - | - | - | 37.9 | 34.2 |
| MaskRCNN-ResNet101_vd-FPN | 高精度但预测时间更长,在处理较大数据量时有较高的精度,适用于服务器端场景 | 268.6M | - | - | - | 41.4 | 36.8 |
## 语义分割
语义分割用于对图像做像素级的分类,应用在人像分类、遥感图像识别等场景。

对于语义分割,PaddleX也针对不同的应用场景,提供了不同的模型选择,如下表所示
> 表中GPU预测速度是使用PaddlePaddle Python预测接口测试得到(测试GPU型号为Nvidia Tesla P40)。
> 表中CPU预测速度 (测试CPU型号为)。
> 表中骁龙855预测速度是使用处理器为骁龙855的手机测试得到。
> 测速时模型的输入大小为1024 x 2048,mIOU为Cityscapes数据集上评估所得。
| 模型 | 模型特点 | 存储体积 | GPU预测速度 | CPU(x86)预测速度(毫秒) | 骁龙855(ARM)预测速度 (毫秒)| mIOU |
| :---- | :------- | :---------- | :---------- | :----- | :----- |:--- |
| DeepLabv3p-MobileNetV2_x1.0 | 轻量级模型,适用于移动端场景| - | - | - | 69.8% |
| HRNet_W18_Small_v1 | 轻量高速,适用于移动端场景 | - | - | - | - |
| FastSCNN | 轻量高速,适用于追求高速预测的移动端或服务器端场景 | - | - | - | 69.64 |
| HRNet_W18 | 高精度模型,适用于对图像分辨率较为敏感、对目标细节预测要求更高的服务器端场景| - | - | - | 79.36 |
| DeepLabv3p-Xception65 | 高精度但预测时间更长,在处理较大数据量时有较高的精度,适用于服务器且背景复杂的场景| - | - | - | 79.3% |
docs/quick_start.md
浏览文件 @
5394a320
...
@@ -121,4 +121,4 @@ Predict Result: Predict Result: [{'score': 0.9999393, 'category': 'bocai', 'cate
...
@@ -121,4 +121,4 @@ Predict Result: Predict Result: [{'score': 0.9999393, 'category': 'bocai', 'cate
-
1.
[
目标检测模型训练
](
tutorials/train/detection.md
)
-
1.
[
目标检测模型训练
](
tutorials/train/detection.md
)
-
2.
[
语义分割模型训练
](
tutorials/train/segmentation.md
)
-
2.
[
语义分割模型训练
](
tutorials/train/segmentation.md
)
-
3.
[
实例分割模型训练
](
tutorials/train/instance_segmentation.md
)
-
3.
[
实例分割模型训练
](
tutorials/train/instance_segmentation.md
)
-
3
.
[
模型太大,想要更小的模型,试试模型裁剪吧!
](
tutorials/compress/classification.md
)
-
4
.
[
模型太大,想要更小的模型,试试模型裁剪吧!
](
tutorials/compress/classification.md
)
examples/human_segmentation/README.md
浏览文件 @
5394a320
# HumanSeg人像分割模型
# HumanSeg人像分割模型
本教程基于PaddleX核心分割
网络,提供针对人像分割场景从预训练模型、Fine-tune、视频分割预测
部署的全流程应用指南。
本教程基于PaddleX核心分割
模型实现人像分割,开放预训练模型和测试数据、支持视频流人像分割、提供模型Fine-tune到Paddle-Lite移动端
部署的全流程应用指南。
##
安装
##
目录
**前置依赖**
*
[
预训练模型和测试数据
](
#1
)
*
paddlepaddle >= 1.8.0
*
[
快速体验视频流人像分割
](
#2
)
*
python >= 3.5
*
[
模型Fine-tune
](
#3
)
*
[
Paddle-Lite移动端部署
](
#4
)
```
pip install paddlex -i https://mirror.baidu.com/pypi/simple
```
安装的相关问题参考
[
PaddleX安装
](
https://paddlex.readthedocs.io/zh_CN/latest/install.html
)
## 预训练模型
## <h2 id="1">预训练模型和测试数据</h2>
HumanSeg开放了在大规模人像数据上训练的两个预训练模型,满足多种使用场景的需求
#### 预训练模型
本案例开放了两个在大规模人像数据集上训练好的模型,以满足服务器端场景和移动端场景的需求。使用这些模型可以快速体验视频流人像分割,也可以部署到移动端进行实时人像分割,也可以用于完成模型Fine-tuning。
| 模型类型 | Checkpoint Parameter | Inference Model | Quant Inference Model | 备注 |
| 模型类型 | Checkpoint Parameter | Inference Model | Quant Inference Model | 备注 |
| --- | --- | --- | ---| --- |
| --- | --- | --- | ---| --- |
| HumanSeg-server |
[
humanseg_server_params
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_server.pdparams
)
|
[
humanseg_server_inference
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_server_inference.zip
)
| -- | 高精度模型,适用于服务端GPU且背景复杂的人像场景, 模型结构为Deeplabv3+/Xcetion65, 输入大小(512, 512) |
| HumanSeg-server |
[
humanseg_server_params
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_server.pdparams
)
|
[
humanseg_server_inference
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_server_inference.zip
)
| -- | 高精度模型,适用于服务端GPU且背景复杂的人像场景, 模型结构为Deeplabv3+/Xcetion65, 输入大小(512, 512) |
| HumanSeg-mobile |
[
humanseg_mobile_params
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile.pdparams
)
|
[
humanseg_mobile_inference
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile_inference.zip
)
|
[
humanseg_mobile_quant
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile_quant.zip
)
| 轻量级模型, 适用于移动端或服务端CPU的前置摄像头场景,模型结构为HRNet_w18_samll_v1,输入大小(192, 192) |
| HumanSeg-mobile |
[
humanseg_mobile_params
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile.pdparams
)
|
[
humanseg_mobile_inference
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile_inference.zip
)
|
[
humanseg_mobile_quant
](
https://paddlex.bj.bcebos.com/humanseg/models/humanseg_mobile_quant.zip
)
| 轻量级模型, 适用于移动端或服务端CPU的前置摄像头场景,模型结构为HRNet_w18_samll_v1,输入大小(192, 192) |
> * Checkpoint Parameter为模型权重,用于Fine-tuning场景。
> * Inference Model和Quant Inference Model为预测部署模型,包含`__model__`计算图结构、`__params__`模型参数和`model.yaml`基础的模型配置信息。
> * 其中Inference Model适用于服务端的CPU和GPU预测部署,Qunat Inference Model为量化版本,适用于通过Paddle Lite进行移动端等端侧设备部署。
模型性能
预训练模型的存储大小和推理时长如下所示,其中移动端模型的运行环境为cpu:骁龙855,内存:6GB,图片大小:192
*
192
| 模型 | 模型大小 | 计算耗时 |
| 模型 | 模型大小 | 计算耗时 |
| --- | --- | --- |
| --- | --- | --- |
...
@@ -30,68 +34,91 @@ HumanSeg开放了在大规模人像数据上训练的两个预训练模型,满
...
@@ -30,68 +34,91 @@ HumanSeg开放了在大规模人像数据上训练的两个预训练模型,满
|humanseg_mobile_inference | 5.8 M | 42.35ms |
|humanseg_mobile_inference | 5.8 M | 42.35ms |
|humanseg_mobile_quant | 1.6M | 24.93ms |
|humanseg_mobile_quant | 1.6M | 24.93ms |
计算耗时运行环境: 小米,cpu:骁龙855, 内存:6GB, 图片大小:192
*
192
执行以下脚本下载全部的预训练模型:
**NOTE:**
其中Checkpoint Parameter为模型权重,用于Fine-tuning场景。
*
Inference Model和Quant Inference Model为预测部署模型,包含
`__model__`
计算图结构、
`__params__`
模型参数和
`model.yaml`
基础的模型配置信息。
*
其中Inference Model适用于服务端的CPU和GPU预测部署,Qunat Inference Model为量化版本,适用于通过Paddle Lite进行移动端等端侧设备部署。
执行以下脚本进行HumanSeg预训练模型的下载
```
bash
```
bash
python pretrain_weights/download_pretrain_weights.py
python pretrain_weights/download_pretrain_weights.py
```
```
## 下载测试数据
#### 测试数据
我们提供了
[
supervise.ly
](
https://supervise.ly/
)
发布人像分割数据集
**Supervisely Persons**
, 从中随机抽取一小部分并转化成PaddleX可直接加载数据格式。通过运行以下代码进行快速下载,其中包含手机前置摄像头的人像测试视频
`video_test.mp4`
.
[
supervise.ly
](
https://supervise.ly/
)
发布了人像分割数据集
**Supervisely Persons**
, 本案例从中随机抽取一小部分数据并转化成PaddleX可直接加载的数据格式,运行以下代码可下载该数据、以及手机前置摄像头拍摄的人像测试视频
`video_test.mp4`
.
```
bash
```
bash
python data/download_data.py
python data/download_data.py
```
```
## 快速体验视频流人像分割
## <h2 id="2">快速体验视频流人像分割</h2>
结合DIS(Dense Inverse Search-basedmethod)光流算法预测结果与分割结果,改善视频流人像分割
#### 前置依赖
*
PaddlePaddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
../../docs/install.md
)
### 光流跟踪辅助的视频流人像分割
本案例将DIS(Dense Inverse Search-basedmethod)光流跟踪算法的预测结果与PaddleX的分割结果进行融合,以此改善视频流人像分割的效果。运行以下代码进行体验:
*
通过电脑摄像头进行实时分割处理
```
bash
```
bash
# 通过电脑摄像头进行实时分割处理
python video_infer.py
--model_dir
pretrain_weights/humanseg_mobile_inference
python video_infer.py
--model_dir
pretrain_weights/humanseg_mobile_inference
```
*
对离线人像视频进行分割处理
# 对人像视频进行分割处理
```
bash
python video_infer.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--video_path
data/video_test.mp4
python video_infer.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--video_path
data/video_test.mp4
```
```
视频分割结果如下:
视频分割结果如下
所示
:
<img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/video_test.gif"
width=
"20%"
height=
"20%"
><img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/result.gif"
width=
"20%"
height=
"20%"
>
<img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/video_test.gif"
width=
"20%"
height=
"20%"
><img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/result.gif"
width=
"20%"
height=
"20%"
>
根据所选背景进行背景替换,背景可以是一张图片,也可以是一段视频。
### 人像背景替换
本案例还实现了人像背景替换功能,根据所选背景对人像的背景画面进行替换,背景可以是一张图片,也可以是一段视频。
*
通过电脑摄像头进行实时背景替换处理, 通过'--background_video_path'传入背景视频
```
bash
```
bash
# 通过电脑摄像头进行实时背景替换处理, 也可通过'--background_video_path'传入背景视频
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--background_image_path
data/background.jpg
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--background_image_path
data/background.jpg
```
# 对人像视频进行背景替换处理, 也可通过'--background_video_path'传入背景视频
*
对人像视频进行背景替换处理, 通过'--background_video_path'传入背景视频
```
bash
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--video_path
data/video_test.mp4
--background_image_path
data/background.jpg
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--video_path
data/video_test.mp4
--background_image_path
data/background.jpg
```
# 对单张图像进行背景替换
*
对单张图像进行背景替换
```
bash
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--image_path
data/human_image.jpg
--background_image_path
data/background.jpg
python bg_replace.py
--model_dir
pretrain_weights/humanseg_mobile_inference
--image_path
data/human_image.jpg
--background_image_path
data/background.jpg
```
```
背景替换结果如下:
背景替换结果如下:
<img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/video_test.gif"
width=
"20%"
height=
"20%"
><img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/bg_replace.gif"
width=
"20%"
height=
"20%"
>
<img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/video_test.gif"
width=
"20%"
height=
"20%"
><img
src=
"https://paddleseg.bj.bcebos.com/humanseg/data/bg_replace.gif"
width=
"20%"
height=
"20%"
>
**注意**
:
*
视频分割处理时间需要几分钟,请耐心等待。
*
提供的模型适用于手机摄像头竖屏拍摄场景,宽屏效果会略差一些。
**NOTE**
:
## <h2 id="3">模型Fine-tune</h2>
视频分割处理时间需要几分钟,请耐心等待。
#### 前置依赖
提供的模型适用于手机摄像头竖屏拍摄场景,宽屏效果会略差一些。
*
PaddlePaddle >= 1.8.0
*
Python >= 3.5
*
PaddleX >= 1.0.0
安装的相关问题参考
[
PaddleX安装
](
../../docs/install.md
)
### 模型训练
使用下述命令进行基于预训练模型的模型训练,请确保选用的模型结构
`model_type`
与模型参数
`pretrain_weights`
匹配。如果不需要本案例提供的测试数据,可更换数据、选择合适的模型并调整训练参数。
## 训练
使用下述命令基于与训练模型进行Fine-tuning,请确保选用的模型结构
`model_type`
与模型参数
`pretrain_weights`
匹配。
```
bash
```
bash
# 指定GPU卡号(以0号卡为例)
# 指定GPU卡号(以0号卡为例)
export
CUDA_VISIBLE_DEVICES
=
0
export
CUDA_VISIBLE_DEVICES
=
0
...
@@ -124,11 +151,12 @@ python train.py --model_type HumanSegMobile \
...
@@ -124,11 +151,12 @@ python train.py --model_type HumanSegMobile \
```
bash
```
bash
python train.py
--help
python train.py
--help
```
```
**NOTE**
**注意**
:可以通过更换
`--model_type`
变量与对应的
`--pretrain_weights`
使用不同的模型快速尝试。
可通过更换
`--model_type`
变量与对应的
`--pretrain_weights`
使用不同的模型快速尝试。
### 评估
使用下述命令对模型在验证集上的精度进行评估:
## 评估
使用下述命令进行评估
```
bash
```
bash
python eval.py
--model_dir
output/best_model
\
python eval.py
--model_dir
output/best_model
\
--data_dir
data/mini_supervisely
\
--data_dir
data/mini_supervisely
\
...
@@ -141,8 +169,9 @@ python eval.py --model_dir output/best_model \
...
@@ -141,8 +169,9 @@ python eval.py --model_dir output/best_model \
*
`--val_list`
: 验证集列表路径
*
`--val_list`
: 验证集列表路径
*
`--image_shape`
: 网络输入图像大小(w, h)
*
`--image_shape`
: 网络输入图像大小(w, h)
## 预测
### 预测
使用下述命令进行预测, 预测结果默认保存在
`./output/result/`
文件夹中。
使用下述命令对测试集进行预测,预测可视化结果默认保存在
`./output/result/`
文件夹中。
```
bash
```
bash
python infer.py
--model_dir
output/best_model
\
python infer.py
--model_dir
output/best_model
\
--data_dir
data/mini_supervisely
\
--data_dir
data/mini_supervisely
\
...
@@ -156,7 +185,10 @@ python infer.py --model_dir output/best_model \
...
@@ -156,7 +185,10 @@ python infer.py --model_dir output/best_model \
*
`--test_list`
: 测试集列表路径
*
`--test_list`
: 测试集列表路径
*
`--image_shape`
: 网络输入图像大小(w, h)
*
`--image_shape`
: 网络输入图像大小(w, h)
## 模型导出
### 模型导出
在服务端部署的模型需要首先将模型导出为inference格式模型,导出的模型将包括
`__model__`
、
`__params__`
和
`model.yml`
三个文名,分别为模型的网络结构,模型权重和模型的配置文件(包括数据预处理参数等等)。在安装完PaddleX后,在命令行终端使用如下命令完成模型导出:
```
bash
```
bash
paddlex
--export_inference
--model_dir
output/best_model
\
paddlex
--export_inference
--model_dir
output/best_model
\
--save_dir
output/export
--save_dir
output/export
...
@@ -165,7 +197,7 @@ paddlex --export_inference --model_dir output/best_model \
...
@@ -165,7 +197,7 @@ paddlex --export_inference --model_dir output/best_model \
*
`--model_dir`
: 模型路径
*
`--model_dir`
: 模型路径
*
`--save_dir`
: 导出模型保存路径
*
`--save_dir`
: 导出模型保存路径
## 离线量化
##
#
离线量化
```
bash
```
bash
python quant_offline.py
--model_dir
output/best_model
\
python quant_offline.py
--model_dir
output/best_model
\
--data_dir
data/mini_supervisely
\
--data_dir
data/mini_supervisely
\
...
@@ -179,3 +211,5 @@ python quant_offline.py --model_dir output/best_model \
...
@@ -179,3 +211,5 @@ python quant_offline.py --model_dir output/best_model \
*
`--quant_list`
: 量化数据集列表路径,一般直接选择训练集或验证集
*
`--quant_list`
: 量化数据集列表路径,一般直接选择训练集或验证集
*
`--save_dir`
: 量化模型保存路径
*
`--save_dir`
: 量化模型保存路径
*
`--image_shape`
: 网络输入图像大小(w, h)
*
`--image_shape`
: 网络输入图像大小(w, h)
## <h2 id="4">Paddle-Lite移动端部署</h2>
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}
