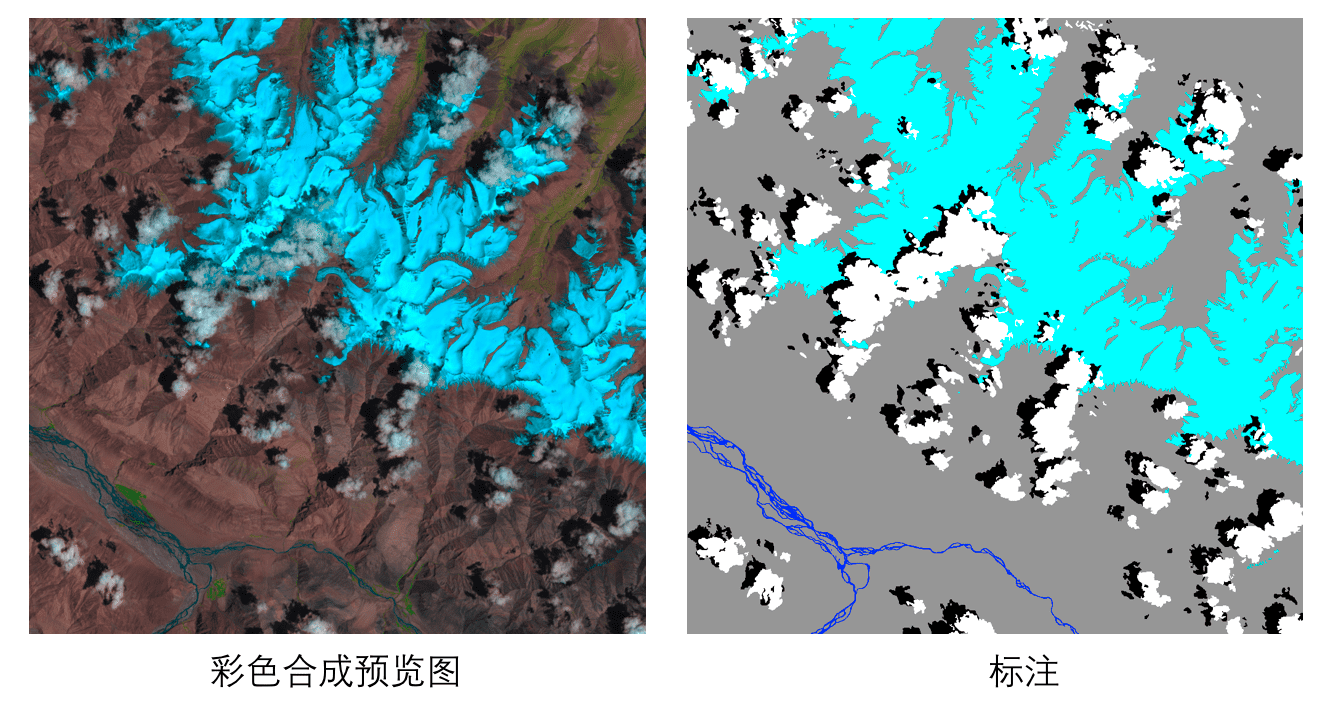
本案例使用[L8 SPARCS公开数据集](https://www.usgs.gov/land-resources/nli/landsat/spatial-procedures-automated-removal-cloud-and-shadow-sparcs-validation)进行云雪分割,该数据集包含80张卫星影像,涵盖10个波段。原始标注图片包含7个类别,分别是`cloud`, `cloud shadow`, `shadow over water`, `snow/ice`, `water`, `land`和`flooded`。由于`flooded`和`shadow over water`2个类别占比仅为`1.8%`和`0.24%`,我们将其进行合并,`flooded`归为`land`,`shadow over water`归为`shadow`,合并后标注包含5个类别。
本案例使用[L8 SPARCS公开数据集](https://www.usgs.gov/land-resources/nli/landsat/spatial-procedures-automated-removal-cloud-and-shadow-sparcs-validation)进行云雪分割,该数据集包含80张卫星影像,涵盖10个波段。原始标注图片包含7个类别,分别是`cloud`, `cloud shadow`, `shadow over water`, `snow/ice`, `water`, `land`和`flooded`。由于`flooded`和`shadow over water`2个类别占比仅为`1.8%`和`0.24%`,我们将其进行合并,`flooded`归为`land`,`shadow over water`归为`shadow`,合并后标注包含5个类别。
"Elements in transforms should be defined in 'paddlex.seg.transforms' or class of imgaug.augmenters.Augmenter, see docs here: https://paddlex.readthedocs.io/zh_CN/latest/apis/transforms/"
)
@staticmethod
defread_img(img_path):
img_format=imghdr.what(img_path)
name,ext=osp.splitext(img_path)
ifimg_format=='tiff'orext=='.img':
importgdal
gdal.UseExceptions()
gdal.PushErrorHandler('CPLQuietErrorHandler')
try:
dataset=gdal.Open(img_path)
except:
logging.error(gdal.GetLastErrorMsg())
ifdataset==None:
raiseException('Can not open',img_path)
im_data=dataset.ReadAsArray()
returnim_data.transpose((1,2,0))
elifimg_format=='png':
returnnp.asarray(Image.open(img_path))
elifext=='.npy':
returnnp.load(img_path)
else:
raiseException('Image format {} is not supported!'.format(ext))
@staticmethod
defdecode_image(im,label):
ifisinstance(im,np.ndarray):
...
...
@@ -69,7 +95,7 @@ class Compose(SegTransform):
format(len(im.shape)))
else:
try:
im=cv2.imread(im)
im=Compose.read_img(im)
except:
raiseValueError('Can\'t read The image file {}!'.format(im))
im=im.astype('float32')
...
...
@@ -85,11 +111,11 @@ class Compose(SegTransform):
label=np.asarray(Image.open(label))
except:
ValueError('Can\'t read The label file {}!'.format(label))
im_height,im_width,_=im.shape
label_height,label_width=label.shape
ifim_height!=label_heightorim_width!=label_width:
raiseException(
"The height or width of the image is not same as the label")
im_height,im_width,_=im.shape
label_height,label_width=label.shape
ifim_height!=label_heightorim_width!=label_width:
raiseException(
"The height or width of the image is not same as the label")
return(im,label)
def__call__(self,im,im_info=None,label=None):
...
...
@@ -570,12 +596,15 @@ class ResizeStepScaling(SegTransform):
{kind=link}
{kind=link}
{kind=link}
