Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSlim
提交
e4e4a573
P
PaddleSlim
项目概览
PaddlePaddle
/
PaddleSlim
大约 2 年 前同步成功
通知
51
Star
1434
Fork
344
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
16
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSlim
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
16
合并请求
16
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
e4e4a573
编写于
8月 05, 2020
作者:
B
Bai Yifan
提交者:
GitHub
8月 05, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' into pact_clip
上级
72b9dcd8
d00373ae
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
158 addition
and
20 deletion
+158
-20
demo/deep_mutual_learning/README.md
demo/deep_mutual_learning/README.md
+23
-1
demo/deep_mutual_learning/cifar100_reader.py
demo/deep_mutual_learning/cifar100_reader.py
+1
-2
demo/deep_mutual_learning/dml_train.py
demo/deep_mutual_learning/dml_train.py
+17
-11
demo/deep_mutual_learning/images/dml_architect.png
demo/deep_mutual_learning/images/dml_architect.png
+0
-0
demo/quant/pact_quant_aware/train.py
demo/quant/pact_quant_aware/train.py
+3
-2
paddleslim/dist/dml.py
paddleslim/dist/dml.py
+15
-4
tests/test_deep_mutual_learning.py
tests/test_deep_mutual_learning.py
+99
-0
未找到文件。
demo/
DML
/README.md
→
demo/
deep_mutual_learning
/README.md
浏览文件 @
e4e4a573
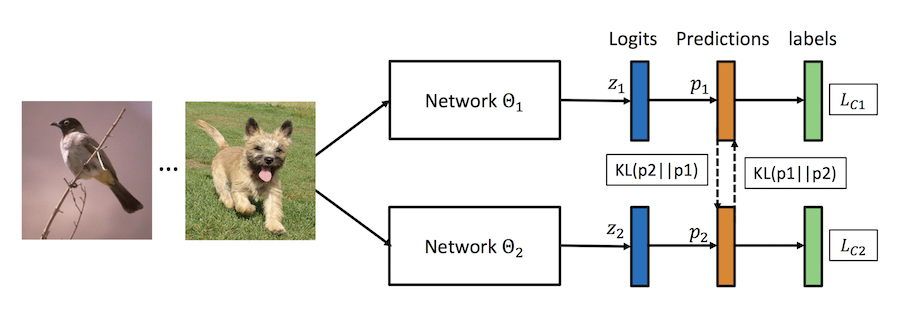
# 深度互学习DML(Deep Mutual Learning)
# 深度互学习DML(Deep Mutual Learning)
本示例介绍如何使用PaddleSlim的深度互学习DML方法训练模型,算法原理请参考论文
[
Deep Mutual Learning
](
https://arxiv.org/abs/1706.00384
)
本示例介绍如何使用PaddleSlim的深度互学习DML方法训练模型,算法原理请参考论文
[
Deep Mutual Learning
](
https://arxiv.org/abs/1706.00384
)

## 使用数据
## 使用数据
示例中使用cifar100数据集进行训练, 您可以在启动训练时等待自动下载,
示例中使用cifar100数据集进行训练, 您可以在启动训练时等待自动下载,
也可以在自行下载
[
数据集
](
https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
)
之后,放在当前目录的
`./dataset/cifar100`
路径下
也可以在自行下载
[
数据集
](
https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
)
之后,放在当前目录的
`./dataset/cifar100`
路径下
## 启动命令
## 启动命令
### 训练MobileNet-Mobilenet的组合
单卡训练, 以0号GPU为例:
单卡训练, 以0号GPU为例:
```
bash
```
bash
CUDA_VISIBLE_DEVICES
=
0 python dml_train.py
CUDA_VISIBLE_DEVICES
=
0 python dml_train.py
```
```
多卡训练, 以0-3号GPU为例:
多卡训练, 以0-3号GPU为例:
```
bash
```
bash
python
-m
paddle.distributed.launch
--selected_gpus
=
0,1,2,3
--log_dir
./mylog dml_train.py
--use_parallel
=
True
python
-m
paddle.distributed.launch
--selected_gpus
=
0,1,2,3
--log_dir
./mylog dml_train.py
--use_parallel
=
True
--init_lr
=
0.4
```
```
### 训练MobileNet-ResNet50的组合
单卡训练, 以0号GPU为例:
```
bash
CUDA_VISIBLE_DEVICES
=
0 python dml_train.py
--models
=
'mobilenet-resnet50'
```
多卡训练, 以0-3号GPU为例:
```
bash
python
-m
paddle.distributed.launch
--selected_gpus
=
0,1,2,3
--log_dir
./mylog dml_train.py
--use_parallel
=
True
--init_lr
=
0.4
--models
=
'mobilenet-resnet50'
```
## 实验结果
## 实验结果
以下实验结果可以由默认实验配置(学习率、优化器等)训练得到,仅调整了DML训练的模型组合
以下实验结果可以由默认实验配置(学习率、优化器等)训练得到,仅调整了DML训练的模型组合
...
...
demo/
DML
/cifar100_reader.py
→
demo/
deep_mutual_learning
/cifar100_reader.py
浏览文件 @
e4e4a573
...
@@ -102,8 +102,7 @@ def cifar100_reader(file_name, data_name, is_shuffle):
...
@@ -102,8 +102,7 @@ def cifar100_reader(file_name, data_name, is_shuffle):
for
name
in
names
:
for
name
in
names
:
print
(
"Reading file "
+
name
)
print
(
"Reading file "
+
name
)
try
:
try
:
batch
=
cPickle
.
load
(
batch
=
cPickle
.
load
(
f
.
extractfile
(
name
),
encoding
=
'iso-8859-1'
)
f
.
extractfile
(
name
),
encoding
=
'iso-8859-1'
)
except
:
except
:
batch
=
cPickle
.
load
(
f
.
extractfile
(
name
))
batch
=
cPickle
.
load
(
f
.
extractfile
(
name
))
data
=
batch
[
'data'
]
data
=
batch
[
'data'
]
...
...
demo/
DML
/dml_train.py
→
demo/
deep_mutual_learning
/dml_train.py
浏览文件 @
e4e4a573
...
@@ -26,6 +26,7 @@ from paddle.fluid.dygraph.base import to_variable
...
@@ -26,6 +26,7 @@ from paddle.fluid.dygraph.base import to_variable
from
paddleslim.common
import
AvgrageMeter
,
get_logger
from
paddleslim.common
import
AvgrageMeter
,
get_logger
from
paddleslim.dist
import
DML
from
paddleslim.dist
import
DML
from
paddleslim.models.dygraph
import
MobileNetV1
from
paddleslim.models.dygraph
import
MobileNetV1
from
paddleslim.models.dygraph
import
ResNet
import
cifar100_reader
as
reader
import
cifar100_reader
as
reader
sys
.
path
[
0
]
=
os
.
path
.
join
(
os
.
path
.
dirname
(
"__file__"
),
os
.
path
.
pardir
)
sys
.
path
[
0
]
=
os
.
path
.
join
(
os
.
path
.
dirname
(
"__file__"
),
os
.
path
.
pardir
)
from
utility
import
add_arguments
,
print_arguments
from
utility
import
add_arguments
,
print_arguments
...
@@ -37,6 +38,7 @@ add_arg = functools.partial(add_arguments, argparser=parser)
...
@@ -37,6 +38,7 @@ add_arg = functools.partial(add_arguments, argparser=parser)
# yapf: disable
# yapf: disable
add_arg
(
'log_freq'
,
int
,
100
,
"Log frequency."
)
add_arg
(
'log_freq'
,
int
,
100
,
"Log frequency."
)
add_arg
(
'models'
,
str
,
"mobilenet-mobilenet"
,
"model."
)
add_arg
(
'batch_size'
,
int
,
256
,
"Minibatch size."
)
add_arg
(
'batch_size'
,
int
,
256
,
"Minibatch size."
)
add_arg
(
'init_lr'
,
float
,
0.1
,
"The start learning rate."
)
add_arg
(
'init_lr'
,
float
,
0.1
,
"The start learning rate."
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether use GPU."
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether use GPU."
)
...
@@ -44,7 +46,6 @@ add_arg('epochs', int, 200, "Epoch number.")
...
@@ -44,7 +46,6 @@ add_arg('epochs', int, 200, "Epoch number.")
add_arg
(
'class_num'
,
int
,
100
,
"Class number of dataset."
)
add_arg
(
'class_num'
,
int
,
100
,
"Class number of dataset."
)
add_arg
(
'trainset_num'
,
int
,
50000
,
"Images number of trainset."
)
add_arg
(
'trainset_num'
,
int
,
50000
,
"Images number of trainset."
)
add_arg
(
'model_save_dir'
,
str
,
'saved_models'
,
"The path to save model."
)
add_arg
(
'model_save_dir'
,
str
,
'saved_models'
,
"The path to save model."
)
add_arg
(
'use_multiprocess'
,
bool
,
True
,
"Whether use multiprocess reader."
)
add_arg
(
'use_parallel'
,
bool
,
False
,
"Whether to use data parallel mode to train the model."
)
add_arg
(
'use_parallel'
,
bool
,
False
,
"Whether to use data parallel mode to train the model."
)
# yapf: enable
# yapf: enable
...
@@ -78,13 +79,9 @@ def create_reader(place, args):
...
@@ -78,13 +79,9 @@ def create_reader(place, args):
train_reader
=
fluid
.
contrib
.
reader
.
distributed_batch_reader
(
train_reader
=
fluid
.
contrib
.
reader
.
distributed_batch_reader
(
train_reader
)
train_reader
)
train_loader
=
fluid
.
io
.
DataLoader
.
from_generator
(
train_loader
=
fluid
.
io
.
DataLoader
.
from_generator
(
capacity
=
1024
,
capacity
=
1024
,
return_list
=
True
)
return_list
=
True
,
use_multiprocess
=
args
.
use_multiprocess
)
valid_loader
=
fluid
.
io
.
DataLoader
.
from_generator
(
valid_loader
=
fluid
.
io
.
DataLoader
.
from_generator
(
capacity
=
1024
,
capacity
=
1024
,
return_list
=
True
)
return_list
=
True
,
use_multiprocess
=
args
.
use_multiprocess
)
train_loader
.
set_batch_generator
(
train_reader
,
places
=
place
)
train_loader
.
set_batch_generator
(
train_reader
,
places
=
place
)
valid_loader
.
set_batch_generator
(
valid_reader
,
places
=
place
)
valid_loader
.
set_batch_generator
(
valid_reader
,
places
=
place
)
return
train_loader
,
valid_loader
return
train_loader
,
valid_loader
...
@@ -160,10 +157,19 @@ def main(args):
...
@@ -160,10 +157,19 @@ def main(args):
train_loader
,
valid_loader
=
create_reader
(
place
,
args
)
train_loader
,
valid_loader
=
create_reader
(
place
,
args
)
# 2. Define neural network
# 2. Define neural network
models
=
[
if
args
.
models
==
"mobilenet-mobilenet"
:
MobileNetV1
(
class_dim
=
args
.
class_num
),
models
=
[
MobileNetV1
(
class_dim
=
args
.
class_num
)
MobileNetV1
(
class_dim
=
args
.
class_num
),
]
MobileNetV1
(
class_dim
=
args
.
class_num
)
]
elif
args
.
models
==
"mobilenet-resnet50"
:
models
=
[
MobileNetV1
(
class_dim
=
args
.
class_num
),
ResNet
(
class_dim
=
args
.
class_num
)
]
else
:
logger
.
info
(
"You can define the model as you wish"
)
return
optimizers
=
create_optimizer
(
models
,
args
)
optimizers
=
create_optimizer
(
models
,
args
)
# 3. Use PaddleSlim DML strategy
# 3. Use PaddleSlim DML strategy
...
...
demo/deep_mutual_learning/images/dml_architect.png
0 → 100755
浏览文件 @
e4e4a573
163.1 KB
demo/quant/pact_quant_aware/train.py
浏览文件 @
e4e4a573
...
@@ -8,8 +8,9 @@ import math
...
@@ -8,8 +8,9 @@ import math
import
time
import
time
import
numpy
as
np
import
numpy
as
np
import
paddle.fluid
as
fluid
import
paddle.fluid
as
fluid
sys
.
path
[
0
]
=
os
.
path
.
join
(
sys
.
path
.
append
(
os
.
path
.
dirname
(
"__file__"
))
os
.
path
.
dirname
(
"__file__"
),
os
.
path
.
pardir
,
os
.
path
.
pardir
)
sys
.
path
.
append
(
os
.
path
.
join
(
os
.
path
.
dirname
(
"__file__"
),
os
.
path
.
pardir
,
os
.
path
.
pardir
))
from
paddleslim.common
import
get_logger
,
get_distribution
,
pdf
from
paddleslim.common
import
get_logger
,
get_distribution
,
pdf
from
paddleslim.analysis
import
flops
from
paddleslim.analysis
import
flops
from
paddleslim.quant
import
quant_aware
,
quant_post
,
convert
from
paddleslim.quant
import
quant_aware
,
quant_post
,
convert
...
...
paddleslim/dist/dml.py
浏览文件 @
e4e4a573
...
@@ -17,11 +17,19 @@ from __future__ import division
...
@@ -17,11 +17,19 @@ from __future__ import division
from
__future__
import
print_function
from
__future__
import
print_function
import
copy
import
copy
import
paddle
import
paddle.fluid
as
fluid
import
paddle.fluid
as
fluid
PADDLE_VERSION
=
1.8
try
:
from
paddle.fluid.layers
import
log_softmax
except
:
from
paddle.nn
import
LogSoftmax
PADDLE_VERSION
=
2.0
class
DML
(
fluid
.
dygraph
.
Layer
):
class
DML
(
fluid
.
dygraph
.
Layer
):
def
__init__
(
self
,
model
,
use_parallel
):
def
__init__
(
self
,
model
,
use_parallel
=
False
):
super
(
DML
,
self
).
__init__
()
super
(
DML
,
self
).
__init__
()
self
.
model
=
model
self
.
model
=
model
self
.
use_parallel
=
use_parallel
self
.
use_parallel
=
use_parallel
...
@@ -54,8 +62,7 @@ class DML(fluid.dygraph.Layer):
...
@@ -54,8 +62,7 @@ class DML(fluid.dygraph.Layer):
for
i
in
range
(
self
.
model_num
):
for
i
in
range
(
self
.
model_num
):
ce_losses
.
append
(
ce_losses
.
append
(
fluid
.
layers
.
mean
(
fluid
.
layers
.
mean
(
fluid
.
layers
.
softmax_with_cross_entropy
(
logits
[
i
],
fluid
.
layers
.
softmax_with_cross_entropy
(
logits
[
i
],
labels
)))
labels
)))
return
ce_losses
return
ce_losses
def
kl_loss
(
self
,
logits
):
def
kl_loss
(
self
,
logits
):
...
@@ -69,7 +76,11 @@ class DML(fluid.dygraph.Layer):
...
@@ -69,7 +76,11 @@ class DML(fluid.dygraph.Layer):
cur_kl_loss
=
0
cur_kl_loss
=
0
for
j
in
range
(
self
.
model_num
):
for
j
in
range
(
self
.
model_num
):
if
i
!=
j
:
if
i
!=
j
:
x
=
fluid
.
layers
.
log_softmax
(
logits
[
i
],
axis
=
1
)
if
PADDLE_VERSION
==
2.0
:
log_softmax
=
LogSoftmax
(
axis
=
1
)
x
=
log_softmax
(
logits
[
i
])
else
:
x
=
fluid
.
layers
.
log_softmax
(
logits
[
i
],
axis
=
1
)
y
=
fluid
.
layers
.
softmax
(
logits
[
j
],
axis
=
1
)
y
=
fluid
.
layers
.
softmax
(
logits
[
j
],
axis
=
1
)
cur_kl_loss
+=
fluid
.
layers
.
kldiv_loss
(
cur_kl_loss
+=
fluid
.
layers
.
kldiv_loss
(
x
,
y
,
reduction
=
'batchmean'
)
x
,
y
,
reduction
=
'batchmean'
)
...
...
tests/test_deep_mutual_learning.py
0 → 100755
浏览文件 @
e4e4a573
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
sys
sys
.
path
.
append
(
"../"
)
import
unittest
import
logging
import
numpy
as
np
import
paddle
import
paddle.fluid
as
fluid
import
paddle.dataset.mnist
as
reader
from
paddle.fluid.dygraph.base
import
to_variable
from
paddleslim.models.dygraph
import
MobileNetV1
from
paddleslim.dist
import
DML
from
paddleslim.common
import
get_logger
logger
=
get_logger
(
__name__
,
level
=
logging
.
INFO
)
class
Model
(
fluid
.
dygraph
.
Layer
):
def
__init__
(
self
):
super
(
Model
,
self
).
__init__
()
self
.
conv
=
fluid
.
dygraph
.
nn
.
Conv2D
(
num_channels
=
1
,
num_filters
=
256
,
filter_size
=
3
,
stride
=
1
,
padding
=
1
,
use_cudnn
=
False
)
self
.
pool2d_avg
=
fluid
.
dygraph
.
nn
.
Pool2D
(
pool_type
=
'avg'
,
global_pooling
=
True
)
self
.
out
=
fluid
.
dygraph
.
nn
.
Linear
(
256
,
10
)
def
forward
(
self
,
inputs
):
inputs
=
fluid
.
layers
.
reshape
(
inputs
,
shape
=
[
0
,
1
,
28
,
28
])
y
=
self
.
conv
(
inputs
)
y
=
self
.
pool2d_avg
(
y
)
y
=
fluid
.
layers
.
reshape
(
y
,
shape
=
[
-
1
,
256
])
y
=
self
.
out
(
y
)
return
y
class
TestDML
(
unittest
.
TestCase
):
def
test_dml
(
self
):
place
=
fluid
.
CUDAPlace
(
0
)
if
fluid
.
is_compiled_with_cuda
(
)
else
fluid
.
CPUPlace
()
with
fluid
.
dygraph
.
guard
(
place
):
train_reader
=
paddle
.
fluid
.
io
.
batch
(
paddle
.
dataset
.
mnist
.
train
(),
batch_size
=
256
)
train_loader
=
fluid
.
io
.
DataLoader
.
from_generator
(
capacity
=
1024
,
return_list
=
True
)
train_loader
.
set_sample_list_generator
(
train_reader
,
places
=
place
)
models
=
[
Model
(),
Model
()]
optimizers
=
[]
for
cur_model
in
models
:
opt
=
fluid
.
optimizer
.
MomentumOptimizer
(
0.1
,
0.9
,
parameter_list
=
cur_model
.
parameters
())
optimizers
.
append
(
opt
)
dml_model
=
DML
(
models
)
dml_optimizer
=
dml_model
.
opt
(
optimizers
)
def
train
(
train_loader
,
dml_model
,
dml_optimizer
):
dml_model
.
train
()
for
step_id
,
(
images
,
labels
)
in
enumerate
(
train_loader
):
images
,
labels
=
to_variable
(
images
),
to_variable
(
labels
)
labels
=
fluid
.
layers
.
reshape
(
labels
,
[
0
,
1
])
logits
=
dml_model
.
forward
(
images
)
precs
=
[
fluid
.
layers
.
accuracy
(
input
=
l
,
label
=
labels
,
k
=
1
).
numpy
()
for
l
in
logits
]
losses
=
dml_model
.
loss
(
logits
,
labels
)
dml_optimizer
.
minimize
(
losses
)
if
step_id
%
10
==
0
:
print
(
step_id
,
precs
)
for
epoch_id
in
range
(
10
):
current_step_lr
=
dml_optimizer
.
get_lr
()
lr_msg
=
"Epoch {}"
.
format
(
epoch_id
)
for
model_id
,
lr
in
enumerate
(
current_step_lr
):
lr_msg
+=
", {} lr: {:.6f}"
.
format
(
dml_model
.
full_name
()[
model_id
],
lr
)
logger
.
info
(
lr_msg
)
train
(
train_loader
,
dml_model
,
dml_optimizer
)
if
__name__
==
'__main__'
:
unittest
.
main
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}