Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSlim
提交
71e0acb1
P
PaddleSlim
项目概览
PaddlePaddle
/
PaddleSlim
大约 2 年 前同步成功
通知
51
Star
1434
Fork
344
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
16
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSlim
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
16
合并请求
16
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
71e0acb1
编写于
9月 28, 2022
作者:
C
Chang Xu
提交者:
GitHub
9月 28, 2022
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add New Func in Quant Analysis (#1439)
上级
9650ce42
变更
12
隐藏空白更改
内联
并排
Showing
12 changed file
with
331 addition
and
58 deletion
+331
-58
example/post_training_quantization/analysis.md
example/post_training_quantization/analysis.md
+46
-4
example/post_training_quantization/detection/README.md
example/post_training_quantization/detection/README.md
+17
-0
example/post_training_quantization/detection/analysis.py
example/post_training_quantization/detection/analysis.py
+21
-4
example/post_training_quantization/detection/configs/picodet_s_analysis.yaml
...ng_quantization/detection/configs/picodet_s_analysis.yaml
+13
-7
example/post_training_quantization/detection/configs/ppyoloe_s_analysis.yaml
...ng_quantization/detection/configs/ppyoloe_s_analysis.yaml
+13
-9
example/post_training_quantization/detection/images/act_distribution.png
...aining_quantization/detection/images/act_distribution.png
+0
-0
example/post_training_quantization/pytorch_yolo_series/README.md
.../post_training_quantization/pytorch_yolo_series/README.md
+13
-0
example/post_training_quantization/pytorch_yolo_series/analysis.py
...ost_training_quantization/pytorch_yolo_series/analysis.py
+31
-4
example/post_training_quantization/pytorch_yolo_series/configs/yolov6s_analysis.yaml
...ization/pytorch_yolo_series/configs/yolov6s_analysis.yaml
+5
-0
example/post_training_quantization/pytorch_yolo_series/configs/yolov7_analysis.yaml
...tization/pytorch_yolo_series/configs/yolov7_analysis.yaml
+19
-0
example/post_training_quantization/pytorch_yolo_series/configs/yolov7_ptq.yaml
..._quantization/pytorch_yolo_series/configs/yolov7_ptq.yaml
+1
-1
paddleslim/quant/analysis.py
paddleslim/quant/analysis.py
+152
-29
未找到文件。
example/post_training_quantization/analysis.md
浏览文件 @
71e0acb1
...
...
@@ -2,8 +2,9 @@
## 1. 量化分析工具功能
1.
遍历模型所有层,依次量化该层,计算量化后精度。为所有只量化一层的模型精度排序,可视化不适合量化的层,以供量化时可选择性跳过不适合量化的层。
2.
可视化量化效果最好和最差的层的权重和激活分布图,以供分析模型量化效果的原因。
3.
【敬请期待】输入预期精度,直接产出符合预期精度的量化模型。
2.
可视化激活箱状图,以供分析每个可量化OP的激活分布对量化效果的影响。
3.
量化效果较好和较差的层的权重和激活直方分布图,以供分析其对量化效果的影响。
4.
输入预期精度,直接产出符合预期精度的量化模型。
## 2. paddleslim.quant.AnalysisQuant 可传入参数解析
```
yaml
...
...
@@ -30,7 +31,37 @@ ptq_config
## 3. 量化分析工具产出内容
## 3. 量化分析工具的使用
1.
创建量化分析工具:
```
analyzer = AnalysisQuant(
model_dir=config["model_dir"],
model_filename=config["model_filename"],
params_filename=config["params_filename"],
eval_function=eval_function,
data_loader=data_loader,
save_dir=config['save_dir'],
ptq_config=config['PTQ'])
```
2.
绘制所有可量化层的激活箱状图
```
analyzer.plot_activation_distribution()
```
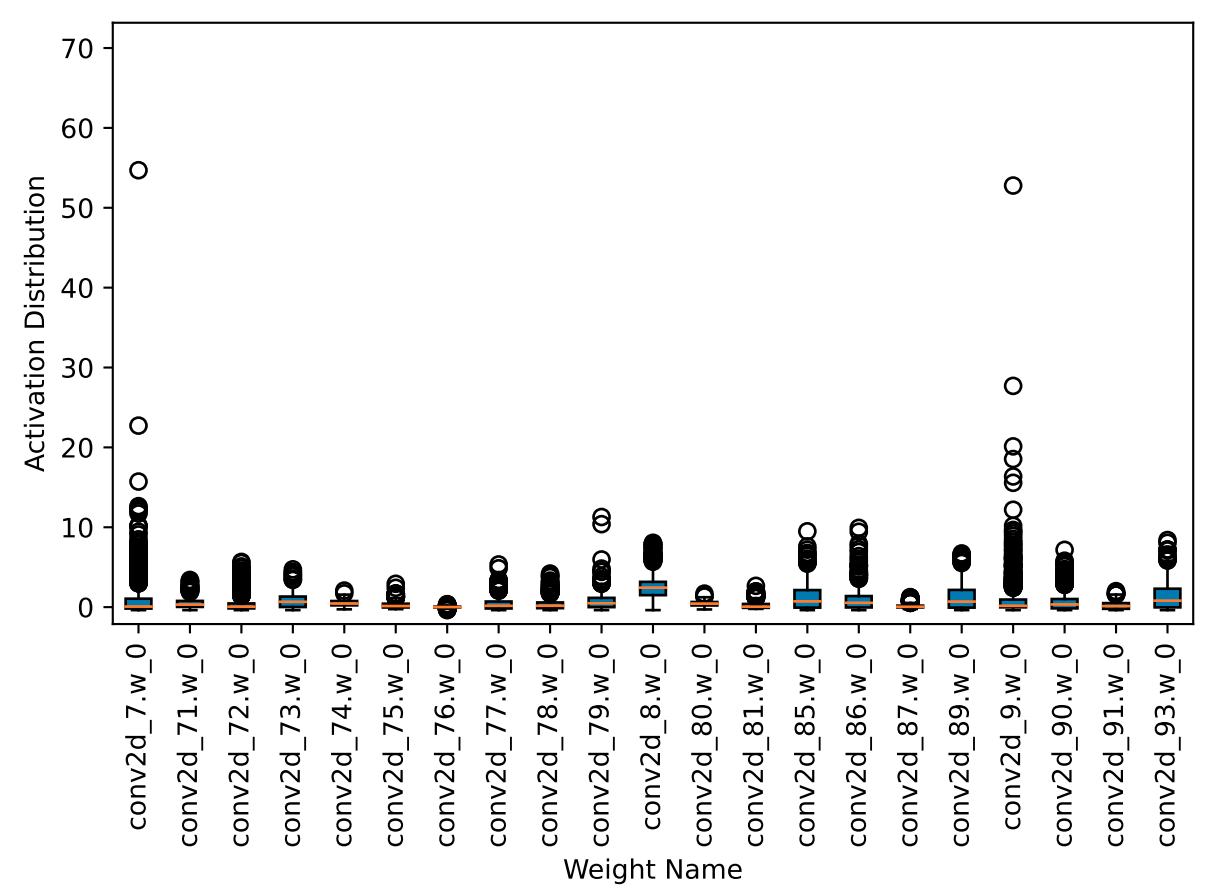
以检测模型中的picodet-s为例,从以下激活箱状图(部分层)中可以发现,
`conv2d_7.w_0`
,
`conv2d_9.w_0`
这两层的激活输入有大量离群点,会导致量化效果较差。
<p
align=
"center"
>
<img
src=
"./detection/images/act_distribution.png"
width=
849
hspace=
'10'
/>
<br
/>
</p>
3.
计算每层的量化敏感度并且绘制直方分布图
```
analyzer.compute_quant_sensitivity(plot_hist=True)
```
`plot_hist`
默认为True,如不需要获得量化效果较好和较差的层的权重和激活分布图,可设置为False。
量化分析工具会默认会产出以下目录:
```
...
...
@@ -41,9 +72,20 @@ analysis_results/
├── worst_weight_hist_result.pdf
├── worst_act_hist_result.pdf
```
-
所有只量化一层的模型精度排序,将默认保存在
`./analysis_results/analysis.txt`
中。
-
通过设置参数
`num_histogram_plots`
,可选择绘出该数量个量化效果最好和最差层的weight和activation的直方分布图,将以PDF形式保存在
`./analysis_results`
文件夹下, 分别保存为
`best_weight_hist_result.pdf`
,
`best_act_hist_result.pdf`
,
`worst_weight_hist_result.pdf`
和
`worst_act_hist_result.pdf`
中以供对比分析。
以检测模型中的picodet-s为例,从
`analysis.txt`
可以发现
`conv2d_1.w_0`
,
`conv2d_3.w_0`
,
`conv2d_5.w_0`
,
`conv2d_7.w_0`
,
`conv2d_9.w_0`
这些层会导致较大的精度损失。这一现象符合对激活箱状图的观察。
<p
align=
"center"
>
<img
src=
"./detection/images/picodet_analysis.png"
width=
849
hspace=
'10'
/>
<br
/>
</p>
4.
直接产出符合预期精度的量化模型
```
analyzer.get_target_quant_model(target_metric)
```
##
3
. 根据分析结果执行离线量化
##
4
. 根据分析结果执行离线量化
执行完量化分析工具后,可根据
`analysis.txt`
中的精度排序,在量化中去掉效果较差的层,具体操作为:在调用
`paddleslim.quant.quant_post_static`
时加入参数
`skip_tensor_list`
,将需要去掉的层传入即可。
example/post_training_quantization/detection/README.md
浏览文件 @
71e0acb1
...
...
@@ -138,18 +138,35 @@ python eval.py --config_path=./configs/ppyoloe_s_ptq.yaml
python analysis.py
--config_path
=
./configs/picodet_s_analysis.yaml
```
如下图,经过量化分析之后,可以发现
`conv2d_1.w_0`
,
`conv2d_3.w_0`
,
`conv2d_5.w_0`
,
`conv2d_7.w_0`
,
`conv2d_9.w_0`
这些层会导致较大的精度损失,这些层均为主干网络中靠前部分的
`depthwise_conv`
。
<p
align=
"center"
>
<img
src=
"./images/picodet_analysis.png"
width=
849
hspace=
'10'
/>
<br
/>
</p>
在保存的
`activation_distribution.pdf`
中,也可以发现以上这些层的
`activation`
存在较多离群点,导致量化效果较差。
<p
align=
"center"
>
<img
src=
"./images/act_distribution.png"
width=
849
hspace=
'10'
/>
<br
/>
</p>
经此分析,在进行离线量化时,可以跳过这些导致精度下降较多的层,可使用
[
picodet_s_analyzed_ptq.yaml
](
./configs/picodet_s_analyzed_ptq.yaml
)
,然后再次进行离线量化。跳过这些层后,离线量化精度上升24.9个点。
```
shell
python post_quant.py
--config_path
=
./configs/picodet_s_analyzed_ptq.yaml
--save_dir
=
./picodet_s_analyzed_ptq_out
```
如想分析之后直接产出符合目标精度的量化模型,可在
`picodet_s_analysis.yaml`
中将
`get_target_quant_model`
设置为True,并填写
`target_metric`
,注意
`target_metric`
不能比原模型精度高。
**加速分析过程**
使用量化分析工具时,因需要逐层量化模型并进行验证,因此过程可能较慢,若想加速分析过程,可以在配置文件中设置
`FastEvalDataset`
,输入一个图片数量较少的annotation文件路径。注意,用少量数据验证的模型精度不一定等于全量数据验证的模型精度,若只需分析时获得不同层量化效果的相对排序,可以使用少量数据集;若要求准确精度,请使用全量验证数据集。如需要全量验证数据,将
`FastEvalDataset`
字段删掉即可。
注:分析之后若需要直接产出符合目标精度的量化模型,demo代码不会使用少量数据集验证,会自动使用全量验证数据。
量化分析工具详细介绍见
[
量化分析工具介绍
](
../analysis.md
)
## 4.预测部署
预测部署可参考
[
Detection模型自动压缩示例
](
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/detection
)
...
...
example/post_training_quantization/detection/analysis.py
浏览文件 @
71e0acb1
...
...
@@ -126,12 +126,16 @@ def main():
config
=
load_config
(
FLAGS
.
config_path
)
ptq_config
=
config
[
'PTQ'
]
# val dataset is sufficient for PTQ
data_loader
=
create
(
'EvalReader'
)(
config
[
'EvalDataset'
],
config
[
'worker_num'
],
return_list
=
True
)
data_loader
=
reader_wrapper
(
data_loader
,
config
[
'input_list'
])
ptq_
data_loader
=
reader_wrapper
(
data_loader
,
config
[
'input_list'
])
dataset
=
config
[
'EvalDataset'
]
# fast_val_anno_path, such as annotation path of several pictures can accelerate analysis
dataset
=
config
[
'FastEvalDataset'
]
if
'FastEvalDataset'
in
config
else
config
[
'EvalDataset'
]
global
val_loader
_eval_batch_sampler
=
paddle
.
io
.
BatchSampler
(
dataset
,
batch_size
=
config
[
'EvalReader'
][
'batch_size'
])
...
...
@@ -162,10 +166,23 @@ def main():
model_filename
=
config
[
"model_filename"
],
params_filename
=
config
[
"params_filename"
],
eval_function
=
eval_function
,
data_loader
=
data_loader
,
data_loader
=
ptq_
data_loader
,
save_dir
=
config
[
'save_dir'
],
ptq_config
=
ptq_config
)
analyzer
.
analysis
()
# plot the boxplot of activations of quantizable weights
analyzer
.
plot_activation_distribution
()
# get the rank of sensitivity of each quantized layer
# plot the histogram plot of best and worst activations and weights if plot_hist is True
analyzer
.
compute_quant_sensitivity
(
plot_hist
=
config
[
'plot_hist'
])
if
config
[
'get_target_quant_model'
]:
if
'FastEvalDataset'
in
config
:
# change fast_val_loader to full val_loader
val_loader
=
data_loader
# get the quantized model that satisfies target metric you set
analyzer
.
get_target_quant_model
(
target_metric
=
config
[
'target_metric'
])
if
__name__
==
'__main__'
:
...
...
example/post_training_quantization/detection/configs/picodet_s_analysis.yaml
浏览文件 @
71e0acb1
...
...
@@ -5,6 +5,9 @@ params_filename: model.pdiparams
save_dir
:
./analysis_results
metric
:
COCO
num_classes
:
80
plot_hist
:
True
get_target_quant_model
:
False
target_metric
:
None
PTQ
:
quantizable_op_type
:
[
"
conv2d"
,
"
depthwise_conv2d"
]
...
...
@@ -15,18 +18,21 @@ PTQ:
batch_nums
:
10
# Datset configuration
TrainDataset
:
!COCODataSet
image_dir
:
train2017
anno_path
:
annotations/instances_train2017.json
dataset_dir
:
/dataset/coco/
EvalDataset
:
!COCODataSet
image_dir
:
val2017
anno_path
:
annotations/instances_val2017.json
dataset_dir
:
/dataset/coco/
# Small Dataset to accelerate analysis
# If not exist, delete the dict of FastEvalDataset
FastEvalDataset
:
!COCODataSet
image_dir
:
val2017
anno_path
:
annotations/small_instances_val2017.json
dataset_dir
:
/dataset/coco/
eval_height
:
&eval_height
416
eval_width
:
&eval_width
416
eval_size
:
&eval_size
[
*eval_height
,
*eval_width
]
...
...
@@ -41,7 +47,7 @@ EvalReader:
-
Resize
:
{
interp
:
2
,
target_size
:
*eval_size
,
keep_ratio
:
False
}
-
NormalizeImage
:
{
is_scale
:
true
,
mean
:
[
0.485
,
0.456
,
0.406
],
std
:
[
0.229
,
0.224
,
0.225
]}
-
Permute
:
{}
batch_size
:
32
batch_size
:
1
example/post_training_quantization/detection/configs/ppyoloe_s_analysis.yaml
浏览文件 @
71e0acb1
input_list
:
[
'
image'
]
arch
:
PPYOLOE
# When export exclude_nms=True, need set arch: PPYOLOE
arch
:
PPYOLOE
# When export exclude_nms=True, need set arch: PPYOLOE
model_dir
:
./ppyoloe_crn_s_300e_coco
model_filename
:
model.pdmodel
params_filename
:
model.pdiparams
save_dir
:
./analysis_results_ppyoloe
metric
:
COCO
num_classes
:
80
plot_hist
:
True
get_target_quant_model
:
False
target_metric
:
None
PTQ
:
quantizable_op_type
:
[
"
conv2d"
,
"
depthwise_conv2d"
]
...
...
@@ -14,19 +17,20 @@ PTQ:
is_full_quantize
:
False
batch_size
:
32
batch_nums
:
10
# Datset configuration
TrainDataset
:
!COCODataSet
image_dir
:
train2017
anno_path
:
annotations/instances_train2017.json
dataset_dir
:
/dataset/coco/
EvalDataset
:
!COCODataSet
image_dir
:
val2017
anno_path
:
annotations/instances_val2017.json
dataset_dir
:
/paddle/dataset/coco/
# Small Dataset to accelerate analysis
# If not exist, delete the dict of FastEvalDataset
FastEvalDataset
:
!COCODataSet
image_dir
:
val2017
anno_path
:
annotations/small_instances_val2017.json
dataset_dir
:
/dataset/coco/
worker_num
:
0
...
...
@@ -38,4 +42,4 @@ EvalReader:
-
Resize
:
{
target_size
:
[
640
,
640
],
keep_ratio
:
False
,
interp
:
2
}
-
NormalizeImage
:
{
mean
:
[
0.485
,
0.456
,
0.406
],
std
:
[
0.229
,
0.224
,
0.225
],
is_scale
:
True
}
-
Permute
:
{}
batch_size
:
32
\ No newline at end of file
batch_size
:
1
\ No newline at end of file
example/post_training_quantization/detection/images/act_distribution.png
0 → 100644
浏览文件 @
71e0acb1
144.6 KB
example/post_training_quantization/pytorch_yolo_series/README.md
浏览文件 @
71e0acb1
...
...
@@ -38,8 +38,10 @@
#### 3.1 准备环境
-
PaddlePaddle >= 2.3 (可从
[
Paddle官网
](
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/linux-pip.html
)
下载安装)
-
PaddleSlim > 2.3版本
-
X2Paddle >= 1.3.9
-
opencv-python
(1)安装paddlepaddle:
```
shell
# CPU
...
...
@@ -139,10 +141,21 @@ python analysis.py --config_path=./configs/yolov6s_analysis.yaml
经此分析,在进行离线量化时,可以跳过这些导致精度下降较多的层,可使用
[
yolov6s_analyzed_ptq.yaml
](
./configs/yolov6s_analyzed_ptq.yaml
)
,然后再次进行离线量化。跳过这些层后,离线量化精度上升9.4个点。
```
shell
python post_quant.py
--config_path
=
./configs/yolov6s_analyzed_ptq.yaml
--save_dir
=
./yolov6s_analyzed_ptq_out
```
如想分析之后直接产出符合目标精度的量化模型,可在
`yolov6s_analysis.yaml`
中将
`get_target_quant_model`
设置为True,并填写
`target_metric`
,注意
`target_metric`
不能比原模型精度高。
**加速分析过程**
使用量化分析工具时,因需要逐层量化模型并进行验证,因此过程可能较慢,若想加速分析过程,可以在配置文件中设置
`fast_val_anno_path`
,输入一个图片数量较少的annotation文件路径。注意,用少量数据验证的模型精度不一定等于全量数据验证的模型精度,若只需分析时获得不同层量化效果的相对排序,可以使用少量数据集;若要求准确精度,请使用全量验证数据集。如需要全量验证数据,将
`fast_val_anno_path`
设置为None即可。
注:分析之后若需要直接产出符合目标精度的量化模型,demo代码不会使用少量数据集验证,会自动使用全量验证数据。
量化分析工具详细介绍见
[
量化分析工具介绍
](
../analysis.md
)
## 4.预测部署
预测部署可参考
[
YOLO系列模型自动压缩示例
](
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolo_series
)
...
...
example/post_training_quantization/pytorch_yolo_series/analysis.py
浏览文件 @
71e0acb1
...
...
@@ -18,7 +18,7 @@ import numpy as np
import
argparse
import
paddle
from
tqdm
import
tqdm
from
post_process
import
YOLO
v6
PostProcess
,
coco_metric
from
post_process
import
YOLOPostProcess
,
coco_metric
from
dataset
import
COCOValDataset
,
COCOTrainDataset
from
paddleslim.common
import
load_config
,
load_onnx_model
from
paddleslim.quant.analysis
import
AnalysisQuant
...
...
@@ -53,7 +53,7 @@ def eval_function(exe, compiled_test_program, test_feed_names, test_fetch_list):
fetch_list
=
test_fetch_list
,
return_numpy
=
False
)
res
=
{}
postprocess
=
YOLO
v6
PostProcess
(
postprocess
=
YOLOPostProcess
(
score_threshold
=
0.001
,
nms_threshold
=
0.65
,
multi_label
=
True
)
res
=
postprocess
(
np
.
array
(
outs
[
0
]),
data_all
[
'scale_factor'
])
bboxes_list
.
append
(
res
[
'bbox'
])
...
...
@@ -72,6 +72,8 @@ def main():
input_name
=
'x2paddle_image_arrays'
if
config
[
'arch'
]
==
'YOLOv6'
else
'x2paddle_images'
# val dataset is sufficient for PTQ
dataset
=
COCOTrainDataset
(
dataset_dir
=
config
[
'dataset_dir'
],
image_dir
=
config
[
'val_image_dir'
],
...
...
@@ -81,10 +83,12 @@ def main():
dataset
,
batch_size
=
1
,
shuffle
=
True
,
drop_last
=
True
,
num_workers
=
0
)
global
val_loader
# fast_val_anno_path, such as annotation path of several pictures can accelerate analysis
dataset
=
COCOValDataset
(
dataset_dir
=
config
[
'dataset_dir'
],
image_dir
=
config
[
'val_image_dir'
],
anno_path
=
config
[
'val_anno_path'
])
anno_path
=
config
[
'fast_val_anno_path'
]
if
config
[
'fast_val_anno_path'
]
is
not
None
else
config
[
'val_anno_path'
])
global
anno_file
anno_file
=
dataset
.
ann_file
val_loader
=
paddle
.
io
.
DataLoader
(
...
...
@@ -101,7 +105,30 @@ def main():
data_loader
=
data_loader
,
save_dir
=
config
[
'save_dir'
],
ptq_config
=
ptq_config
)
analyzer
.
analysis
()
# plot the boxplot of activations of quantizable weights
analyzer
.
plot_activation_distribution
()
# get the rank of sensitivity of each quantized layer
# plot the histogram plot of best and worst activations and weights if plot_hist is True
analyzer
.
compute_quant_sensitivity
(
plot_hist
=
config
[
'plot_hist'
])
if
config
[
'get_target_quant_model'
]:
if
config
[
'fast_val_anno_path'
]
is
not
None
:
# change fast_val_loader to full val_loader
dataset
=
COCOValDataset
(
dataset_dir
=
config
[
'dataset_dir'
],
image_dir
=
config
[
'val_image_dir'
],
anno_path
=
config
[
'val_anno_path'
])
anno_file
=
dataset
.
ann_file
val_loader
=
paddle
.
io
.
DataLoader
(
dataset
,
batch_size
=
1
,
shuffle
=
False
,
drop_last
=
False
,
num_workers
=
0
)
# get the quantized model that satisfies target metric you set
analyzer
.
get_target_quant_model
(
config
[
'target_metric'
])
if
__name__
==
'__main__'
:
...
...
example/post_training_quantization/pytorch_yolo_series/configs/yolov6s_analysis.yaml
浏览文件 @
71e0acb1
...
...
@@ -4,6 +4,11 @@ save_dir: ./analysis_results
dataset_dir
:
/dataset/coco/
val_image_dir
:
val2017
val_anno_path
:
annotations/instances_val2017.json
# Small Dataset to accelerate analysis
fast_val_anno_path
:
annotations/small_instances_val2017.json
# if not exist, please set None
get_target_quant_model
:
False
target_metric
:
None
plot_hist
:
True
PTQ
:
quantizable_op_type
:
[
"
conv2d"
,
"
depthwise_conv2d"
]
...
...
example/post_training_quantization/pytorch_yolo_series/configs/yolov7_analysis.yaml
0 → 100644
浏览文件 @
71e0acb1
arch
:
YOLOv7
model_dir
:
./yolov7.onnx
save_dir
:
./analysis_results
dataset_dir
:
/dataset/coco/
val_image_dir
:
val2017
val_anno_path
:
annotations/instances_val2017.json
# Small Dataset to accelerate analysis
fast_val_anno_path
:
annotations/small_instances_val2017.json
# if not exist, please set None
get_target_quant_model
:
False
target_metric
:
None
plot_hist
:
True
PTQ
:
quantizable_op_type
:
[
"
conv2d"
,
"
depthwise_conv2d"
]
weight_quantize_type
:
'
abs_max'
activation_quantize_type
:
'
moving_average_abs_max'
is_full_quantize
:
False
batch_size
:
10
batch_nums
:
10
\ No newline at end of file
example/post_training_quantization/pytorch_yolo_series/configs/yolov7
s
_ptq.yaml
→
example/post_training_quantization/pytorch_yolo_series/configs/yolov7_ptq.yaml
浏览文件 @
71e0acb1
arch
:
YOLOv7
model_dir
:
./yolov7
s
.onnx
model_dir
:
./yolov7.onnx
dataset_dir
:
/dataset/coco/
train_image_dir
:
train2017
val_image_dir
:
val2017
...
...
paddleslim/quant/analysis.py
浏览文件 @
71e0acb1
...
...
@@ -20,7 +20,7 @@ import logging
import
matplotlib.pyplot
as
plt
from
matplotlib.backends.backend_pdf
import
PdfPages
import
numpy
as
np
import
random
import
paddle
from
paddle.fluid
import
core
from
paddle.fluid
import
framework
...
...
@@ -105,7 +105,7 @@ class AnalysisQuant(object):
if
self
.
eval_function
is
not
None
:
self
.
base_metric
=
self
.
eval_function
(
executor
,
program
,
self
.
feed_list
,
self
.
fetch_list
)
_logger
.
info
(
'
b
efore quantized, the accuracy of the model is: {}'
.
_logger
.
info
(
'
B
efore quantized, the accuracy of the model is: {}'
.
format
(
self
.
base_metric
))
# quant and evaluate after quant (skip_list = None)
...
...
@@ -121,7 +121,7 @@ class AnalysisQuant(object):
program
=
post_training_quantization
.
quantize
()
self
.
quant_metric
=
self
.
eval_function
(
executor
,
program
,
self
.
feed_list
,
self
.
fetch_list
)
_logger
.
info
(
'
a
fter quantized, the accuracy of the model is: {}'
.
format
(
_logger
.
info
(
'
A
fter quantized, the accuracy of the model is: {}'
.
format
(
self
.
quant_metric
))
# get quantized weight and act var name
...
...
@@ -135,8 +135,13 @@ class AnalysisQuant(object):
list
(
self
.
quant_layer_metrics
.
keys
()))
self
.
tobe_analyized_layer
=
sorted
(
list
(
self
.
tobe_analyized_layer
))
def
analysis
(
self
):
self
.
compute_quant_sensitivity
()
def
compute_quant_sensitivity
(
self
,
plot_hist
=
True
):
'''
compute the sensitivity of quantized layers by eval function
'''
assert
self
.
data_loader
is
not
None
,
"When computing the sensitivity of quantized layers, the data loader is needed"
assert
self
.
eval_function
is
not
None
,
"When computing the sensitivity of quantized layers, the eval function is needed"
self
.
eval_quant_model
()
self
.
sensitivity_ranklist
=
sorted
(
self
.
quant_layer_metrics
,
key
=
self
.
quant_layer_metrics
.
get
,
...
...
@@ -154,7 +159,9 @@ class AnalysisQuant(object):
"quant layer name: {}, eval metric: {}
\n
"
.
format
(
name
,
self
.
quant_layer_metrics
[
name
]))
_logger
.
info
(
'Analysis file is saved in {}'
.
format
(
analysis_file
))
self
.
calculate_histogram
()
if
plot_hist
:
self
.
calculate_histogram
()
def
save_checkpoint
(
self
):
if
not
os
.
path
.
exists
(
self
.
save_dir
):
...
...
@@ -171,12 +178,76 @@ class AnalysisQuant(object):
_logger
.
info
(
'load checkpoint from {}'
.
format
(
self
.
checkpoint_name
))
return
True
def
compute_quant_sensitivity
(
self
):
def
plot_activation_distribution
(
self
,
axis
=
None
):
'''
Collect and plot the distribution of the activation of each weight layer.
'''
devices
=
paddle
.
device
.
get_device
().
split
(
':'
)[
0
]
places
=
paddle
.
device
.
_convert_to_place
(
devices
)
executor
=
paddle
.
static
.
Executor
(
places
)
[
program
,
feed_list
,
fetch_list
]
=
load_inference_model
(
\
self
.
model_dir
,
\
executor
=
executor
,
\
model_filename
=
self
.
model_filename
,
\
params_filename
=
self
.
params_filename
)
scope
=
global_scope
()
graph
=
IrGraph
(
core
.
Graph
(
program
.
desc
),
for_test
=
False
)
persistable_var_names
=
[]
for
var
in
program
.
list_vars
():
if
var
.
persistable
:
persistable_var_names
.
append
(
var
.
name
)
weight_names
=
sorted
(
list
(
self
.
quantized_weight_var_name
))
acts_weight_map
=
self
.
get_weight_act_map
(
program
,
weight_names
,
persistable_var_names
)
all_acts
=
list
(
acts_weight_map
.
keys
())
all_weights
=
[
acts_weight_map
[
act
]
for
act
in
all_acts
]
act_distribution
=
[]
for
var_name
in
all_acts
:
var_tensor
=
load_variable_data
(
scope
,
var_name
)
if
axis
is
None
:
var_tensor
=
var_tensor
.
flatten
()
else
:
var_tensor
=
var_tensor
.
reshape
(
[
-
1
,
var_tensor
.
shape
[
axis
]]).
abs
().
max
(
axis
=-
1
)
sample_num
=
len
(
var_tensor
)
if
len
(
var_tensor
)
<
1000
else
1000
var_tensor
=
random
.
sample
(
list
(
var_tensor
),
sample_num
)
act_distribution
.
append
(
var_tensor
)
all_values
=
sum
(
act_distribution
,
[])
max_value
=
np
.
max
(
all_values
)
min_value
=
np
.
min
(
all_values
)
pdf_path
=
os
.
path
.
join
(
self
.
save_dir
,
'activation_distribution.pdf'
)
with
PdfPages
(
pdf_path
)
as
pdf
:
for
i
in
range
(
0
,
len
(
act_distribution
),
20
):
r
=
i
+
20
if
i
+
20
<
len
(
act_distribution
)
else
len
(
act_distribution
)
plt
.
boxplot
(
act_distribution
[
i
:
r
],
labels
=
all_weights
[
i
:
r
],
showbox
=
True
,
patch_artist
=
True
)
plt
.
xticks
(
rotation
=
90
)
plt
.
tick_params
(
axis
=
'x'
)
plt
.
ylim
([
min_value
,
max_value
])
plt
.
xlabel
(
'Weight Name'
)
plt
.
ylabel
(
"Activation Distribution"
)
plt
.
tight_layout
()
plt
.
show
()
pdf
.
savefig
()
plt
.
close
()
_logger
.
info
(
'Distribution plots is saved in {}'
.
format
(
pdf_path
))
def
eval_quant_model
(
self
):
'''
For each layer, quantize the weight op and evaluate the quantized model.
'''
for
i
,
layer_name
in
enumerate
(
self
.
tobe_analyized_layer
):
_logger
.
info
(
'
c
hecking {}/{} quant model: quant layer {}'
.
format
(
_logger
.
info
(
'
C
hecking {}/{} quant model: quant layer {}'
.
format
(
i
+
1
,
len
(
self
.
tobe_analyized_layer
),
layer_name
))
skip_list
=
copy
.
copy
(
list
(
self
.
quantized_weight_var_name
))
skip_list
.
remove
(
layer_name
)
...
...
@@ -198,15 +269,14 @@ class AnalysisQuant(object):
self
.
fetch_list
)
executor
.
close
()
_logger
.
info
(
"
quant
layer name: {}, eval metric: {}, the loss caused by this layer: {}"
.
"
Quantized
layer name: {}, eval metric: {}, the loss caused by this layer: {}"
.
format
(
layer_name
,
quant_metric
,
self
.
base_metric
-
quant_metric
))
self
.
quant_layer_metrics
[
layer_name
]
=
quant_metric
self
.
save_checkpoint
()
def
get_act_name_by_weight
(
self
,
program
,
weight_names
,
persistable_var_names
):
act_ops_names
=
[]
def
get_weight_act_map
(
self
,
program
,
weight_names
,
persistable_var_names
):
act_names
=
{}
for
op_name
in
weight_names
:
for
block_id
in
range
(
len
(
program
.
blocks
)):
for
op
in
program
.
blocks
[
block_id
].
ops
:
...
...
@@ -214,8 +284,8 @@ class AnalysisQuant(object):
if
op_name
in
var_name_list
:
for
var_name
in
var_name_list
:
if
var_name
not
in
persistable_var_names
:
act_
ops_names
.
append
(
var_name
)
return
act_
ops_
names
act_
names
[
var_name
]
=
op_name
return
act_names
def
get_hist_ops_name
(
self
,
graph
,
program
):
if
self
.
num_histogram_plots
<=
0
:
...
...
@@ -230,13 +300,13 @@ class AnalysisQuant(object):
if
var
.
persistable
:
persistable_var_names
.
append
(
var
.
name
)
best_act
_ops
=
self
.
get_act_name_by_weight
(
program
,
best_weight_ops
,
persistable_var_names
)
worst_act
_ops
=
self
.
get_act_name_by_weight
(
program
,
worst_weight_ops
,
persistable_var_names
)
return
[
best_weight_ops
,
best_act
_ops
,
worst_weight_ops
,
worst_act_op
s
]
best_act
s
=
self
.
get_weight_act_map
(
program
,
best_weight_ops
,
persistable_var_names
)
worst_act
s
=
self
.
get_weight_act_map
(
program
,
worst_weight_ops
,
persistable_var_names
)
return
[
best_weight_ops
,
best_act
s
,
worst_weight_ops
,
worst_act
s
]
def
collect_
op
s_histogram
(
self
,
scope
,
ops
):
def
collect_
tensor
s_histogram
(
self
,
scope
,
ops
):
hist
=
{}
for
var_name
in
ops
:
var_tensor
=
load_variable_data
(
scope
,
var_name
)
...
...
@@ -268,8 +338,8 @@ class AnalysisQuant(object):
scope
=
global_scope
()
graph
=
IrGraph
(
core
.
Graph
(
program
.
desc
),
for_test
=
False
)
op
s_tobe_draw_hist
=
self
.
get_hist_ops_name
(
graph
,
program
)
if
not
op
s_tobe_draw_hist
:
tensor
s_tobe_draw_hist
=
self
.
get_hist_ops_name
(
graph
,
program
)
if
not
tensor
s_tobe_draw_hist
:
return
for
var
in
program
.
list_vars
():
...
...
@@ -294,19 +364,72 @@ class AnalysisQuant(object):
'worst_weight_hist_result.pdf'
,
'worst_act_hist_result.pdf'
,
]
for
ops
,
save_pdf_name
in
zip
(
ops_tobe_draw_hist
,
pdf_names
):
hist_data
=
self
.
collect_ops_histogram
(
scope
,
ops
)
self
.
draw_pdf
(
hist_data
,
save_pdf_name
)
def
draw_pdf
(
self
,
hist_data
,
save_pdf_name
):
for
tensors
,
save_pdf_name
in
zip
(
tensors_tobe_draw_hist
,
pdf_names
):
if
isinstance
(
tensors
,
list
):
hist_data
=
self
.
collect_tensors_histogram
(
scope
,
tensors
)
self
.
draw_hist_pdf
(
hist_data
,
save_pdf_name
,
None
)
else
:
hist_data
=
self
.
collect_tensors_histogram
(
scope
,
list
(
tensors
.
keys
()))
self
.
draw_hist_pdf
(
hist_data
,
save_pdf_name
,
tensors
)
def
draw_hist_pdf
(
self
,
hist_data
,
save_pdf_name
,
weight_act_map
):
pdf_path
=
os
.
path
.
join
(
self
.
save_dir
,
save_pdf_name
)
with
PdfPages
(
pdf_path
)
as
pdf
:
for
name
in
hist_data
:
plt
.
hist
(
hist_data
[
name
][
0
],
bins
=
hist_data
[
name
][
1
])
plt
.
xlabel
(
name
)
plt
.
ylabel
(
"frequency"
)
plt
.
title
(
"Hist of variable {}"
.
format
(
name
))
plt
.
ylabel
(
"Frequency"
)
if
'act'
in
save_pdf_name
:
plt
.
title
(
"Hist of Activation {}/Input of Weight {}"
.
format
(
name
,
weight_act_map
[
name
]))
else
:
plt
.
title
(
"Hist of Weight {}"
.
format
(
name
))
plt
.
show
()
pdf
.
savefig
()
plt
.
close
()
_logger
.
info
(
'Histogram plot is saved in {}'
.
format
(
pdf_path
))
def
get_target_quant_model
(
self
,
target_metric
):
_logger
.
info
(
'Start to Find quant model that satisfies the target metric.'
)
_logger
.
info
(
'Make sure that you are using full eval dataset to get target quantized model.'
)
skip_list
=
[]
rank_list
=
copy
.
copy
(
self
.
sensitivity_ranklist
)
while
True
:
skip_list
.
append
(
rank_list
.
pop
(
0
))
_logger
.
info
(
'Skip Ops: {}'
.
format
(
skip_list
))
executor
=
paddle
.
static
.
Executor
(
self
.
places
)
post_training_quantization
=
PostTrainingQuantization
(
executor
=
executor
,
data_loader
=
self
.
data_loader
,
model_dir
=
self
.
model_dir
,
model_filename
=
self
.
model_filename
,
params_filename
=
self
.
params_filename
,
skip_tensor_list
=
skip_list
,
**
self
.
ptq_config
)
program
=
post_training_quantization
.
quantize
()
_logger
.
info
(
'Evaluating...'
)
quant_metric
=
self
.
eval_function
(
executor
,
program
,
self
.
feed_list
,
self
.
fetch_list
)
_logger
.
info
(
"Current eval metric: {}, the target metric: {}"
.
format
(
quant_metric
,
target_metric
))
if
quant_metric
>=
target_metric
:
quantize_model_path
=
os
.
path
.
join
(
self
.
save_dir
,
'target_quant_model'
)
_logger
.
info
(
'The quantized model satisfies the target metric and is saved to {}'
.
format
(
quantize_model_path
))
post_training_quantization
.
save_quantized_model
(
quantize_model_path
,
model_filename
=
'model.pdmodel'
,
params_filename
=
'model.pdiparams'
)
break
else
:
_logger
.
info
(
'The quantized model does not satisfy the target metric. Skip next Op...'
)
executor
.
close
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}