Add mobile device deploy document (#624)
* add dygraph prune quick_start
* add mobile deploy doc
* complete deploy doc
* add images
* fix a error;
* fix some error
Co-authored-by: Ngmm <38800877+mmglove@users.noreply.github.com>
Showing
docs/images/deploy/baseline.png
0 → 100644
{kind=link}
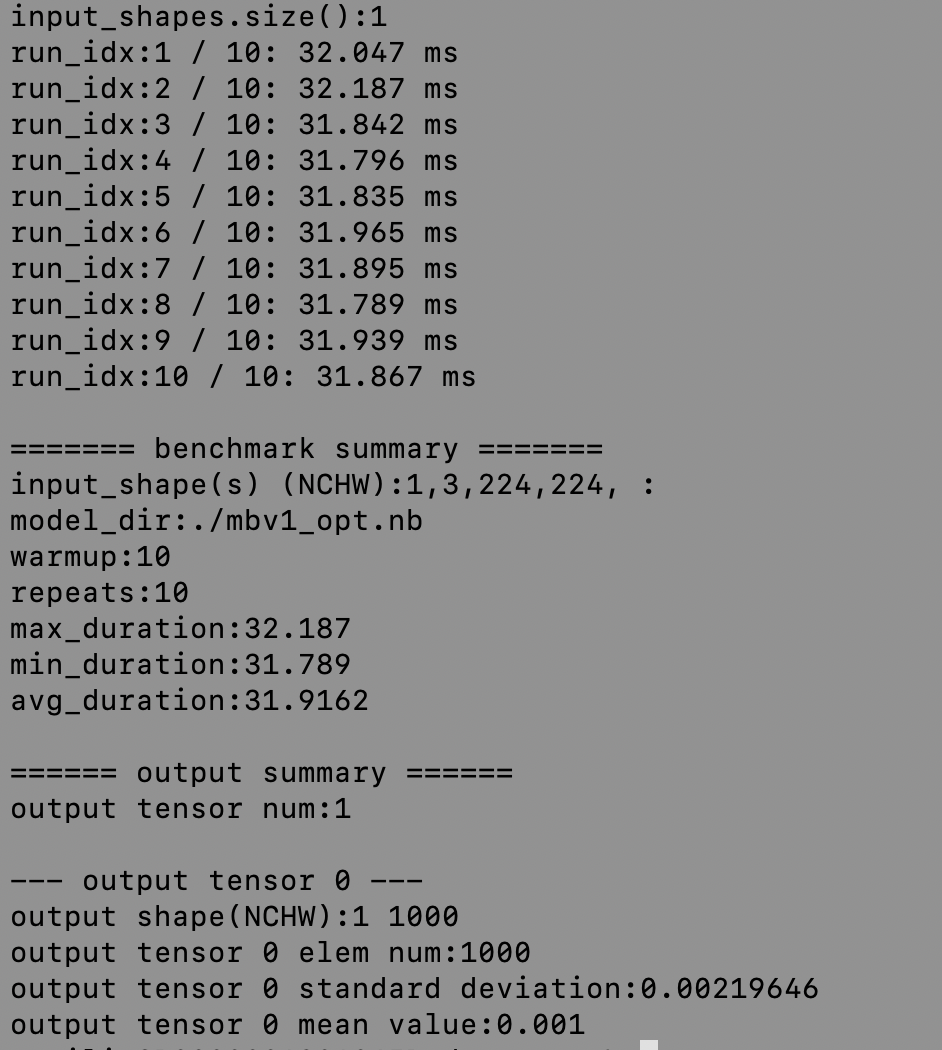
408.0 KB
docs/images/deploy/quanted.png
0 → 100644
{kind=link}
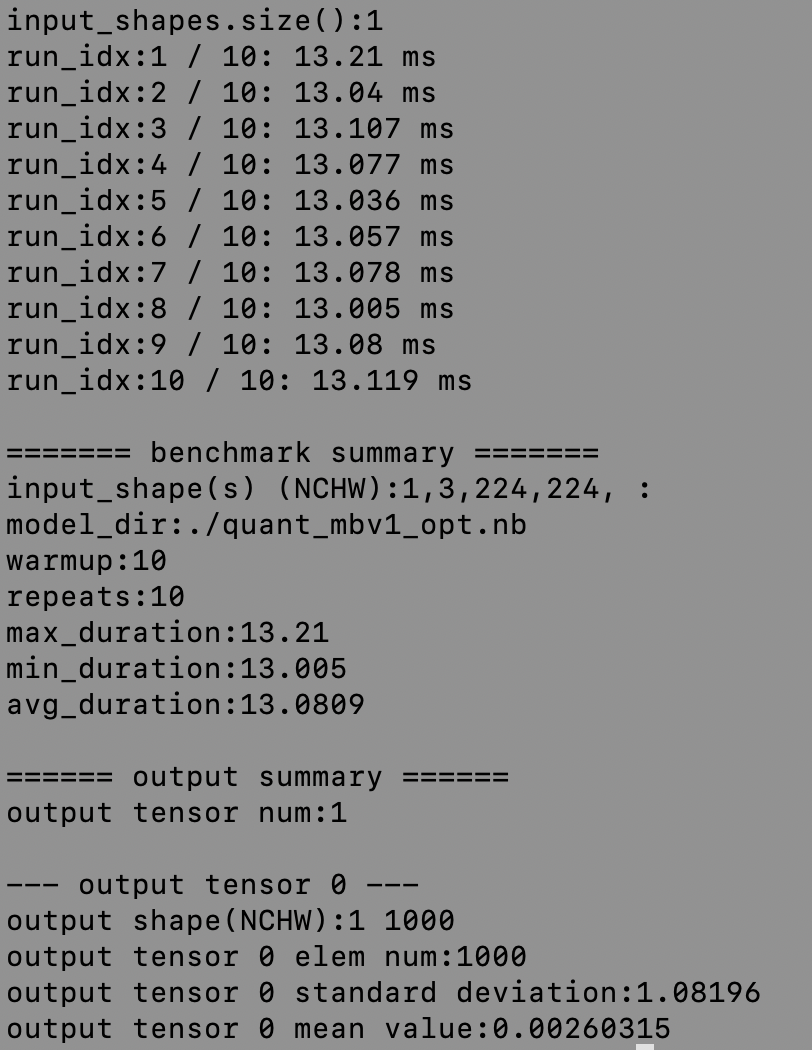
396.0 KB