Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSlim
提交
24ff7907
P
PaddleSlim
项目概览
PaddlePaddle
/
PaddleSlim
大约 2 年 前同步成功
通知
51
Star
1434
Fork
344
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
16
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSlim
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
16
合并请求
16
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
24ff7907
编写于
5月 20, 2022
作者:
G
Guanghua Yu
提交者:
GitHub
5月 20, 2022
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add post_training_quantization tutorial (#1121)
上级
44e69a8d
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
96 addition
and
4 deletion
+96
-4
README.md
README.md
+2
-2
demo/quant/quant_post/README.md
demo/quant/quant_post/README.md
+1
-1
docs/images/post_quant2.png
docs/images/post_quant2.png
+0
-0
docs/zh_cn/api_cn/static/quant/quantization_api.rst
docs/zh_cn/api_cn/static/quant/quantization_api.rst
+2
-1
docs/zh_cn/tutorials/quant/post_training_quantization.md
docs/zh_cn/tutorials/quant/post_training_quantization.md
+91
-0
未找到文件。
README.md
浏览文件 @
24ff7907
...
@@ -25,7 +25,7 @@ PaddleSlim是一个专注于深度学习模型压缩的工具库,提供**低
...
@@ -25,7 +25,7 @@ PaddleSlim是一个专注于深度学习模型压缩的工具库,提供**低
- 统一量化模型格式
- 统一量化模型格式
- 离线量化支持while op
- 离线量化支持while op
- 新增7种
离线量化方法
, 包括HIST, AVG, EMD, Bias Correction, AdaRound等
- 新增7种
[离线量化方法](docs/zh_cn/tutorials/quant/post_training_quantization.md)
, 包括HIST, AVG, EMD, Bias Correction, AdaRound等
- 修复BERT大模型量化训练过慢的问题
- 修复BERT大模型量化训练过慢的问题
-
支持半结构化稀疏训练
-
支持半结构化稀疏训练
...
@@ -190,7 +190,7 @@ pip install paddleslim==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
...
@@ -190,7 +190,7 @@ pip install paddleslim==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
-
低比特量化
-
低比特量化
-
[
三种量化方法介绍与应用
](
docs/zh_cn/tutorials/quant/overview.md
)
-
[
三种量化方法介绍与应用
](
docs/zh_cn/tutorials/quant/overview.md
)
-
[
量化训练
](
docs/zh_cn/quick_start/static/quant_aware_tutorial.md
)
-
[
量化训练
](
docs/zh_cn/quick_start/static/quant_aware_tutorial.md
)
-
[
离线量化
](
docs/zh_cn/tutorials/quant/static/quant_post_tutorial.md
)
-
[
离线量化
](
docs/zh_cn/tutorials/quant/static/quant_post_tutorial.md
)
|
[
离线量化方法解析
](
docs/zh_cn/tutorials/quant/post_training_quantization.md
)
-
[
embedding量化
](
docs/zh_cn/tutorials/quant/static/embedding_quant_tutorial.md
)
-
[
embedding量化
](
docs/zh_cn/tutorials/quant/static/embedding_quant_tutorial.md
)
-
NAS
-
NAS
...
...
demo/quant/quant_post/README.md
浏览文件 @
24ff7907
...
@@ -4,7 +4,7 @@
...
@@ -4,7 +4,7 @@
## 接口介绍
## 接口介绍
请参考
<a
href=
'https://
paddlepaddle.github.io/PaddleSlim/api_cn/quantization_api.html#quant-post-
static'
>
量化API文档
</a>
。
请参考
<a
href=
'https://
github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_
static'
>
量化API文档
</a>
。
## 分类模型的离线量化流程
## 分类模型的离线量化流程
...
...
docs/images/post_quant2.png
0 → 100644
浏览文件 @
24ff7907
37.5 KB
docs/zh_cn/api_cn/static/quant/quantization_api.rst
浏览文件 @
24ff7907
...
@@ -118,7 +118,7 @@ quant_post_dynamic
...
@@ -118,7 +118,7 @@ quant_post_dynamic
quant_post_static
quant_post_static
---------------
---------------
..
py
:
function
::
paddleslim
.
quant
.
quant_post_static
(
executor
,
model_dir
,
quantize_model_path
,
batch_generator
=
None
,
sample_generator
=
None
,
model_filename
=
None
,
params_filename
=
None
,
save_model_filename
=
'__model__'
,
save_params_filename
=
'__params__'
,
batch_size
=
16
,
batch_nums
=
None
,
scope
=
None
,
algo
=
'KL'
,
quantizable_op_type
=[
"conv2d"
,
"depthwise_conv2d"
,
"mul"
],
is_full_quantize
=
False
,
weight_bits
=
8
,
activation_bits
=
8
,
activation_quantize_type
=
'range_abs_max'
,
weight_quantize_type
=
'channel_wise_abs_max'
,
optimize_model
=
False
)
..
py
:
function
::
paddleslim
.
quant
.
quant_post_static
(
executor
,
model_dir
,
quantize_model_path
,
batch_generator
=
None
,
sample_generator
=
None
,
model_filename
=
None
,
params_filename
=
None
,
save_model_filename
=
'__model__'
,
save_params_filename
=
'__params__'
,
batch_size
=
16
,
batch_nums
=
None
,
scope
=
None
,
algo
=
'KL'
,
round_type
=
'round'
,
quantizable_op_type
=[
"conv2d"
,
"depthwise_conv2d"
,
"mul"
],
is_full_quantize
=
False
,
weight_bits
=
8
,
activation_bits
=
8
,
activation_quantize_type
=
'range_abs_max'
,
weight_quantize_type
=
'channel_wise_abs_max'
,
optimize_model
=
False
)
`
源代码
<
https
://
github
.
com
/
PaddlePaddle
/
PaddleSlim
/
blob
/
develop
/
paddleslim
/
quant
/
quanter
.
py
>`
_
`
源代码
<
https
://
github
.
com
/
PaddlePaddle
/
PaddleSlim
/
blob
/
develop
/
paddleslim
/
quant
/
quanter
.
py
>`
_
...
@@ -162,6 +162,7 @@ quant_post_static
...
@@ -162,6 +162,7 @@ quant_post_static
-
**
scope
(
fluid
.
Scope
,
optional
)**
-
用来获取和写入
``
Variable
``
,
如果设置为
``
None
``
,
则使用
`
fluid
.
global_scope
()
<
https
://
www
.
paddlepaddle
.
org
.
cn
/
documentation
/
docs
/
zh
/
develop
/
api_cn
/
executor_cn
/
global_scope_cn
.
html
>`
_
.
默认值是
``
None
``
.
-
**
scope
(
fluid
.
Scope
,
optional
)**
-
用来获取和写入
``
Variable
``
,
如果设置为
``
None
``
,
则使用
`
fluid
.
global_scope
()
<
https
://
www
.
paddlepaddle
.
org
.
cn
/
documentation
/
docs
/
zh
/
develop
/
api_cn
/
executor_cn
/
global_scope_cn
.
html
>`
_
.
默认值是
``
None
``
.
-
**
algo
(
str
)**
-
量化时使用的算法名称,可为
``
'KL'
``
,
``
'mse'
``,
``
'hist'
``
,
``
'avg'
``
,或者
``
'abs_max'
``
。该参数仅针对激活值的量化,因为参数值的量化使用的方式为
``
'channel_wise_abs_max'
``
.
当
``
algo
``
设置为
``
'abs_max'
``
时,使用校正数据的激活值的绝对值的最大值当作
``
Scale
``
值,当设置为
``
'KL'
``
时,则使用
KL
散度的方法来计算
``
Scale
``
值,当设置为
``
'avg'
``
时,使用校正数据激活值的最大绝对值平均数作为
``
Scale
``
值,当设置为
``
'hist'
``
时,则使用基于百分比的直方图的方法来计算
``
Scale
``
值,当设置为
``
'mse'
``
时,则使用搜索最小
mse
损失的方法来计算
``
Scale
``
值。默认值为
``
'hist'
``
。
-
**
algo
(
str
)**
-
量化时使用的算法名称,可为
``
'KL'
``
,
``
'mse'
``,
``
'hist'
``
,
``
'avg'
``
,或者
``
'abs_max'
``
。该参数仅针对激活值的量化,因为参数值的量化使用的方式为
``
'channel_wise_abs_max'
``
.
当
``
algo
``
设置为
``
'abs_max'
``
时,使用校正数据的激活值的绝对值的最大值当作
``
Scale
``
值,当设置为
``
'KL'
``
时,则使用
KL
散度的方法来计算
``
Scale
``
值,当设置为
``
'avg'
``
时,使用校正数据激活值的最大绝对值平均数作为
``
Scale
``
值,当设置为
``
'hist'
``
时,则使用基于百分比的直方图的方法来计算
``
Scale
``
值,当设置为
``
'mse'
``
时,则使用搜索最小
mse
损失的方法来计算
``
Scale
``
值。默认值为
``
'hist'
``
。
-
**
hist_percent
(
float
)**
-
``
'hist'
``
方法的百分位数。默认值为
0.9999
。
-
**
hist_percent
(
float
)**
-
``
'hist'
``
方法的百分位数。默认值为
0.9999
。
-
**
round_type
(
str
)**
-
权重量化时采用的四舍五入方法,默认为
`
round
`
。另外支持
`
adaround
`
,对每层
weight
值进行量化时,自适应的决定
weight
量化时将浮点值近似到最近右定点值还是左定点值,具体的算法原理参考自
[
论文
](
https
://
arxiv
.
org
/
abs
/
2004.10568
)
。
-
**
bias_correction
(
bool
)**
-
是否使用
bias
correction
算法。默认值为
False
。
-
**
bias_correction
(
bool
)**
-
是否使用
bias
correction
算法。默认值为
False
。
-
**
quantizable_op_type
(
list
[
str
])**
-
需要量化的
op
类型列表。默认值为
``[
"conv2d"
,
"depthwise_conv2d"
,
"mul"
]``
。
-
**
quantizable_op_type
(
list
[
str
])**
-
需要量化的
op
类型列表。默认值为
``[
"conv2d"
,
"depthwise_conv2d"
,
"mul"
]``
。
-
**
is_full_quantize
(
bool
)**
-
是否量化所有可支持的
op
类型。如果设置为
False
,
则按照
``
'quantizable_op_type'
``
的设置进行量化。如果设置为
True
,
则按照
`
量化配置
<#
id2
>`
_
中
``
QUANT_DEQUANT_PASS_OP_TYPES
+
QUANT_DEQUANT_PASS_OP_TYPES
``
定义的
op
进行量化。
-
**
is_full_quantize
(
bool
)**
-
是否量化所有可支持的
op
类型。如果设置为
False
,
则按照
``
'quantizable_op_type'
``
的设置进行量化。如果设置为
True
,
则按照
`
量化配置
<#
id2
>`
_
中
``
QUANT_DEQUANT_PASS_OP_TYPES
+
QUANT_DEQUANT_PASS_OP_TYPES
``
定义的
op
进行量化。
...
...
docs/zh_cn/tutorials/quant/post_training_quantization.md
0 → 100644
浏览文件 @
24ff7907
# PaddleSlim离线量化
## 简介
神经网络模型具有大规模的参数量,对存储和计算量往往需求较大,使得模型难以计算在低存储和低算力设备上运行。这给神经网络的部署和应用带来了巨大挑战。随着越来越多的硬件设备支持低精度的计算,量化已经成为给模型带来预测加速的通用方法。模型量化方法可以分为量化训练(quantization aware training)和离线量化(post training quantization)方法。其中,量化训练方法需要对全精度模型进行微调,而离线量化方法只需要少量数据对模型进行校准,快速且实用,因而得到广泛应用。PaddleSlim基于PaddlePaddle深度学习框架,实现了一系列离线量化方法,并配合Paddle Inference和Paddle Lite的推理引擎,实现了量化模型在端上的推理加速。本文将立足于此,对离线量化进行方法上和实践上的系统介绍。
## 量化方法
从量化计算方式的角度,量化主要可以分为线性量化和非线性量化。线性量化方法由于计算方式简单以及较多硬件支持,应用最为广泛。线性量化又可以细分为对称量化,非对称量化和ristretto等。目前PaddleSlim中已经支持的是对称量化。
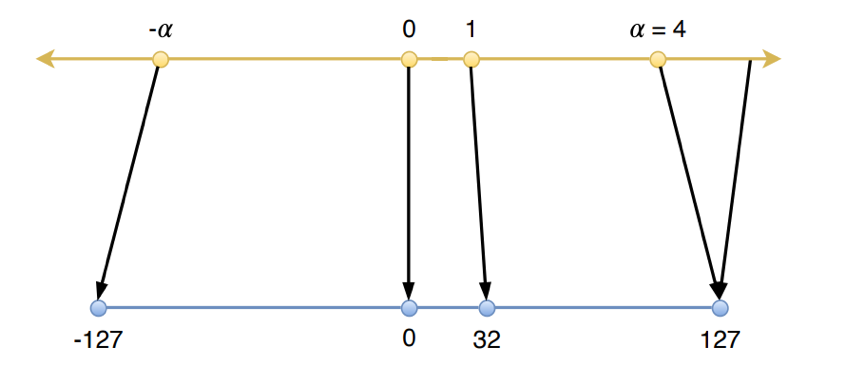
### 对称量化
对称量化将参数限制在正负对称的范围内,如下图所示:(图片出自
[
论文
](
https://arxiv.org/abs/2004.09602
)
)
<div
align=
"center"
>
<img
src=
"../../../images/post_quant2.png"
width=
'600'
/>
</div>
上图所示的对称量化过程可以用如下公式表述:
$$
s=
\f
rac{2^{b-1}-1}{
\a
lpha}
$$
$$
x_{q}=
\o
peratorname{quantize}(x, b, s)=
\o
peratorname{clip}
\l
eft(
\o
peratorname{round}(s
\c
dot x),-2^{b-1}+1,2^{b-1}-1
\r
ight)
$$
反量化过程可以用以下公式表述:
$$
x_{q}=
\o
peratorname{quantize}(x, b, s)=
\o
peratorname{clip}
\l
eft(
\o
peratorname{round}(s
\c
dot x),-2^{b-1}+1,2^{b-1}-1
\r
ight)
$$
其中,s为所选取的scale值,即将s作为尺度因子,将全精度参数映射到低比特取值范围;α为选定的全精度参数的表示范围,即全精度参数将被限制在[-α,α]内;b为量化的比特数,x为待量化的全精度参数。因此,如果给定量化的比特数b,我们只需要选定合适的α值,就可以确定量化所需的参数s。
### 权重量化和激活量化
-
权重量化:即仅需要对网络中的权重执行量化操作。因为模型的权重在推理时数值无变化,所以我们可以提前根据权重获得相应的量化参数scale。由于仅对权重执行了量化,这种量化方法不会加速推理流程。
-
激活量化:即不仅对网络中的权重进行量化,还对激活值进行量化。因为激活层的范围通常不容易提前获得,所以需要在网络实际推理的过程中进行计算scale值,此过程需要部分无标签数据。
几点说明:
1.
对于权重,可以选择逐层(layer-wise)或者逐通道(channel-wise)的量化粒度,也就是说每层或者每个通道选取一个量化scale。在PaddleSlim的
[
离线量化接口
](
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_static
)
中,通过
`weight_quantize_type`
的参数来配置权重量化,可选择
`abs_max`
或者
`channel_wise_abs_max`
,前者是layer-wise,后者是channel-wise,按照经验,
`channel_wise_abs_max`
的量化方式更精确,但部分部署硬件有可能不支持channel-wise量化推理。
2.
对于激活,一般只能采用逐层(layer-wise)的量化粒度,每层选取一个量化参数,从而在部署时实现计算的加速。在PaddleSlim的
[
离线量化接口
](
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_static
)
中,通过
`activation_quantize_type`
参数来配置激活量化,可选择
`range_abs_max`
或者
`moving_average_abs_max`
,一般保持默认
`range_abs_max`
即可。
## 方法介绍
### 对于激活量化
对于激活的离线量化,需要用少量数据进行校准,经过模型的前向过程,统计得到激活的量化scale参数。具体来说,我们支持了如下几种确定激活的量化截断值α的方法:
| 激活量化方法 | 详解 |
| :-------- | :--------: |
| abs_max | 选取所有激活值的绝对值的最大值作为截断值α。此方法的计算最为简单,但是容易受到某些绝对值较大的极端值的影响,适用于几乎不存在极端值的情况。 |
| KL |使用参数在量化前后的KL散度作为量化损失的衡量指标。此方法是TensorRT所使用的方法,我们根据
[
8-bit Inference with TensorRT
](
https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
)
进行了实现。在大多数情况下,使用KL方法校准的表现要优于abs_max方法。 |
| avg | 选取所有样本的激活值的绝对值最大值的平均数作为截断值α。此方法计算较为简单,可以在一定程度上消除不同数据样本的激活值的差异,抵消一些极端值影响,总体上优于abs_max方法。 |
| hist| 首先采用与KL散度类似的方式将所有参数映射为直方图,然后根据给定的百分比,选取直方图的百分位点作为截断值α。此方法可以去除掉一些极端值,并且可以灵活调节直方图百分比(hist_percent)来调整截断值大小,以适应不同模型。 |
| mse | 使用均方误差作为模型量化前后输出的损失的衡量指标。选取使得激活值在量化前后的均方误差最小的量化参数。此方法较为耗时,但是效果常常优于其他方法。 |
| emd | 使用推土距离(EMD)作为模型量化前后输出的损失的衡量指标。使用EMD距离做度量,量化前后EMD距离越小,量化精度越高。选取使得激活值在量化前后的均方误差最小的量化参数。 |
说明:
-
当模型量化效果不好时,可多尝试几种激活方法,具体的,可以在PaddleSlim的
[
离线量化接口
](
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_static
)
修改
`algo`
参数,目前支持:
`abs_max`
、
`KL`
、
`avg`
、
`hist`
、
`mse`
、
`emd`
。
### 对于权重量化
在对权重scale参数进行量化时,一般直接采用选取绝对值最大值的方式。对于权重量化,还可通过其他方法提升量化的精度,比如矫正weight偏差,round方法等,比如PaddleSlim中目前支持以下几种方法:
| 权重量化方法 | 详解 |
| :-------- | :--------: |
| bias_correction | 通过简单的校正常数来补偿权重weight量化前后的均值和方差的固有偏差,参考自
[
论文
](
https://arxiv.org/abs/1810.05723
)
。 |
| Adaround | 对每层weight值进行量化时,不再采样固定四舍五入方法,而是自适应的决定weight量化时将浮点值近似到最近右定点值还是左定点值。具体的算法原理参考自
[
论文
](
https://arxiv.org/abs/2004.10568
)
。 |
说明:
-
如果想使用bias_correction,可以在PaddleSlim的
[
离线量化接口
](
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_static
)
修改
`bias_correction`
参数为True即可,默认为False。
-
如果想使用Adaround方法,可以在PaddleSlim的
[
离线量化接口
](
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_static
)
修改
`round_type`
参数为
`adaround`
即可,默认为
`round`
。
### 效果对比
以上离线量化方法在MobileNet模型上的效果对比如下:
<p
align=
"center"
>
<img
width=
"750"
alt=
"image"
src=
"https://user-images.githubusercontent.com/7534971/169042883-9ca281ce-19be-4525-a3d2-c54cea4a2cbd.png"
/>
<br
/>
<strong>
表1:多种离线量化方法效果对比
</strong>
</p>
更详细的使用可查看
[
PaddleSlim离线量化API文档
](
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/api_cn/static/quant/quantization_api.rst#quant_post_static
)
## 快速体验
-
离线量化:参考PaddleSlim的
[
离线量化Demo
](
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/demo/quant/quant_post
)
。
-
自动化压缩ACT:可试用PaddleSlim新功能
[
自动化压缩Demo
](
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/demo/auto_compression
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}