Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSlim
提交
245d5fc2
P
PaddleSlim
项目概览
PaddlePaddle
/
PaddleSlim
大约 2 年 前同步成功
通知
51
Star
1434
Fork
344
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
16
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSlim
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
16
合并请求
16
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
245d5fc2
编写于
1月 29, 2021
作者:
Y
yukavio
提交者:
GitHub
1月 29, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add mobile device deploy document (#624) (#635)
上级
0eaa11e4
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
300 addition
and
0 deletion
+300
-0
docs/deploy/deploy_cls_model_on_mobile_device.md
docs/deploy/deploy_cls_model_on_mobile_device.md
+193
-0
docs/images/deploy/baseline.png
docs/images/deploy/baseline.png
+0
-0
docs/images/deploy/quanted.png
docs/images/deploy/quanted.png
+0
-0
dygraph_docs/quick_start/pruning_tutorial.md
dygraph_docs/quick_start/pruning_tutorial.md
+107
-0
未找到文件。
docs/deploy/deploy_cls_model_on_mobile_device.md
0 → 100644
浏览文件 @
245d5fc2
# 端侧部署
本教程以图像分类模型为例,介绍基于
[
Paddle Lite
](
https://github.com/PaddlePaddle/Paddle-Lite
)
在移动端部署经过PaddleSlim压缩后的分类模型的详细步骤。
Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。
## 1. 准备环境
该节主要介绍如何准备部署环境。
### 1.1 运行准备
-
电脑(编译Paddle Lite)
-
安卓手机(armv7或armv8)
### 1.2 准备交叉编译环境
交叉编译环境用于编译 Paddle Lite的C++ demo。
支持多种开发环境,不同开发环境的编译流程请参考对应文档。
1.
[
Docker
](
https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#docker
)
2.
[
Linux
](
https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#linux
)
3.
[
MAC OS
](
https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#mac-os
)
### 1.3 准备预测库
编译Paddle-Lite得到预测库,Paddle-Lite的编译方式如下:
```
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
# 切换到Paddle-Lite 稳定分支,这里以release/v2.8为例
git checkout release/v2.8
./lite/tools/build_android.sh --arch=armv8 --with_cv=ON
```
注意:编译Paddle-Lite获得预测库时,需要打开
`--with_cv=ON --with_extra=ON`
两个选项,
`--arch`
表示
`arm`
版本,这里指定为armv8,
更多编译命令介绍请参考
[
链接
](
https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_andriod.html
)
。
预测库的文件目录如下:
```
inference_lite_lib.android.armv8/
|-- cxx C++ 预测库和头文件
| |-- include C++ 头文件
| | |-- paddle_api.h
| | |-- paddle_image_preprocess.h
| | |-- paddle_lite_factory_helper.h
| | |-- paddle_place.h
| | |-- paddle_use_kernels.h
| | |-- paddle_use_ops.h
| | `-- paddle_use_passes.h
| `-- lib C++预测库
| |-- libpaddle_api_light_bundled.a C++静态库
| `-- libpaddle_light_api_shared.so C++动态库
|-- java Java预测库
| |-- jar
| | `-- PaddlePredictor.jar
| |-- so
| | `-- libpaddle_lite_jni.so
| `-- src
|-- demo C++和Java示例代码
| |-- cxx C++ 预测库demo
| `-- java Java 预测库demo
```
## 2. 模型准备
该节主要介绍如何准备Paddle-Lite的模型转换工具以及如何利用模型转换工具将模型转化为部署所需要的.nb文件。
### 2.1 准备模型转换工具
Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括量化、子图融合、混合调度、Kernel优选等方法,使用Paddle-lite的opt工具可以自动
对inference模型进行优化,优化后的模型更轻量,模型运行速度更快。
如果已经准备好了
`.nb`
结尾的模型文件,可以跳过此步骤。
模型优化需要Paddle-Lite的opt可执行文件,可以通过编译Paddle-Lite源码获得,编译步骤如下:
```
# 如果准备环境时已经clone了Paddle-Lite,则不用重新clone Paddle-Lite
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
git checkout release/v2.8
# 启动编译
./lite/tools/build.sh build_optimize_tool
```
编译完成后,opt文件位于
`build.opt/lite/api/`
下,可通过如下方式查看opt的运行选项和使用方式;
```
cd build.opt/lite/api/
./opt
```
|选项|说明|
|-|-|
|--model_dir |待优化的PaddlePaddle模型(非combined形式)的路径|
|--model_file |待优化的PaddlePaddle模型(combined形式)的网络结构文件路径|
|--param_file |待优化的PaddlePaddle模型(combined形式)的权重文件路径|
|--optimize_out_type |输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现。若您需要在mobile端执行模型预测,请将此选项设置为naive_buffer。默认为protobuf|
|--optimize_out |优化模型的输出路径|
|--valid_targets |指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm|
|--record_tailoring_info|当使用 根据模型裁剪库文件 功能时,则设置该选项为true,以记录优化后模型含有的kernel和OP信息,默认为false|
`--model_dir`
适用于待优化的模型是非combined方式,
`--model_file`
与
`--param_file`
用于待优化的combined模型,即模型结构和模型参数使用单独一个文件存储。通过
[
paddle.jit.save
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc1/api/paddle/fluid/dygraph/jit/save_cn.html
)
保存的模型均为combined模型。
一般来讲,通过剪枝、蒸馏、NAS方法压缩得到的模型,和通用模型PaddleLite部署、模型转换步骤相同,下面以MobileNetv1的原始模型和经过PaddleSlim量化后的模型为例。
### 2.2 转换模型
#### 转换原始模型
```
wget https://paddle-inference-dist.bj.bcebos.com/PaddleLite/benchmark_0/benchmark_models.tgz && tar xf benchmark_models.tgz
./opt --model_dir=./benchmark_models/mobilenetv1 --optimize_out_type=naive_buffer --optimize_out=./mbv1_opt --valid_targets=arm
```
#### 转换量化模型
```
wget https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_quant_aware.tar && tar xf MobileNetV1_quant_aware.tar
./opt --model_file=./MobileNetV1_quant_aware/model --param_file=./MobileNetV1_quant_aware/params --optimize_out_type=naive_buffer --optimize_out=./quant_mbv1_opt --valid_targets=arm
```
转换成功后,当前目录下会多出
`.nb`
结尾的文件,即是转换成功的模型文件。
注意:使用paddle-lite部署时,需要使用opt工具优化后的模型。 opt 工具的输入模型是paddle保存的inference模型
## 3. 运行模型
首先需要进行一些准备工作。
1.
准备一台arm8的安卓手机,如果编译的预测库和opt文件是armv7,则需要arm7的手机,并修改Makefile中
`ARM_ABI = arm7`
。
2.
打开手机的USB调试选项,选择文件传输模式,连接电脑。
3.
电脑上安装adb工具,用于调试。 adb安装方式如下:
3.1. MAC电脑安装ADB:
```
brew cask install android-platform-tools
```
3.2. Linux安装ADB
```
sudo apt update
sudo apt install -y wget adb
```
3.3. Window安装ADB
win上安装需要去谷歌的安卓平台下载adb软件包进行安装:[链接](https://developer.android.com/studio)
打开终端,手机连接电脑,在终端中输入
```
adb devices
```
如果有device输出,则表示安装成功。
```
List of devices attached
744be294 device
```
4.
准备优化后的模型、预测库文件
```
# 创建临时目录
mkdir /{user path}/temp
cd /{lite repo path}/build.lite.android.armv8.gcc/inference_lite_lib.android.armv8/demo/cxx/mobile_light/
# 编译部署程序
make
# 将部署程序拷贝到之前创建的临时目录
cp mobilenetv1_light_api /{user path}/temp
# 将链接文件拷贝到临时目录
cp ../../../cxx/lib/libpaddle_light_api_shared.so /{user path}/temp
```
将之前生成的模型文件:`mbv1_opt.nb`, `quant_mbv1_opt.nb` 同样拷贝到/{user path}/temp目录下。
5.
启动调试
上述步骤完成后就可以使用adb将文件push到手机上运行,步骤如下:
```
# 进入/{user path}/temp
cd /{user path}/temp
# 将模型文件push到手机上
adb push mbv1_opt.nb /data/local/tmp
adb push quant_mbv1_opt.nb /data/local/tmp
# 将部署文件和链接文件push到手机上
adb push libpaddle_light_api_shared.so /data/local/tmp
adb push mobilenetv1_light_api /data/local/tmp
# 执行原始MobileNetV1模型
adb shell 'cd /data/local/tmp && export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data/local/tmp && ./mobilenetv1_light_api ./mbv1_opt.nb'
# 执行原始MobileNetV1模型
adb shell 'cd /data/local/tmp && export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data/local/tmp && ./mobilenetv1_light_api ./quant_mbv1_opt.nb'
```
如果对代码做了修改,则需要重新编译并push到手机上。
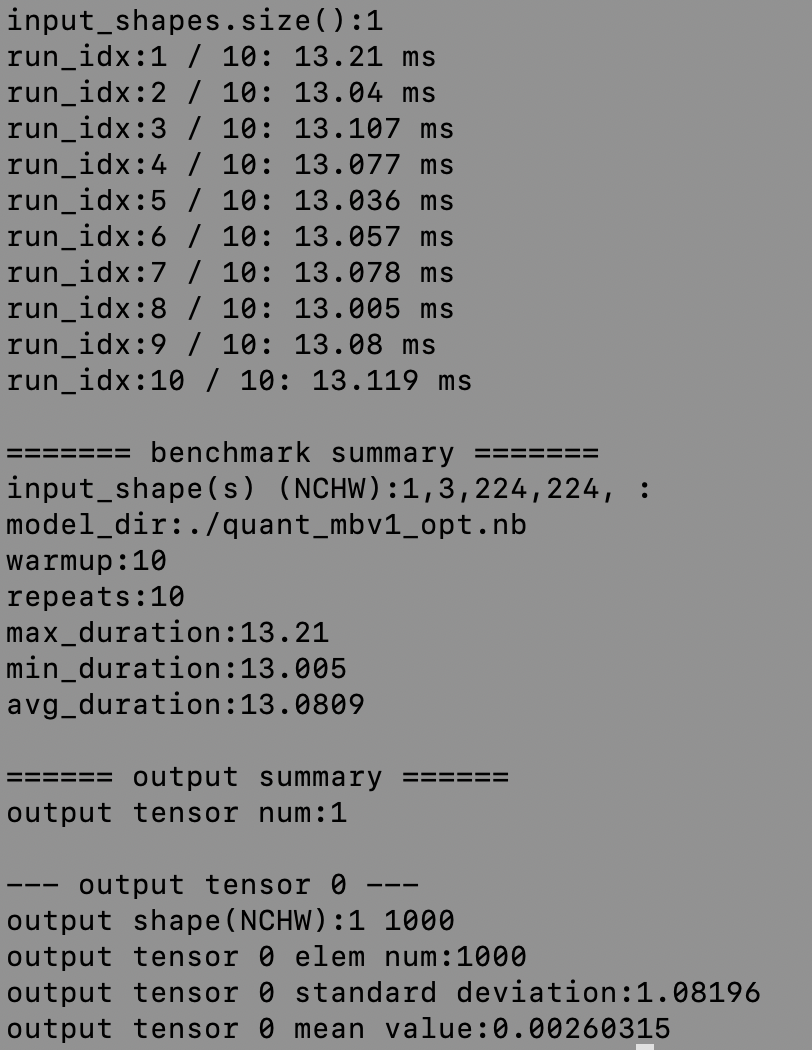
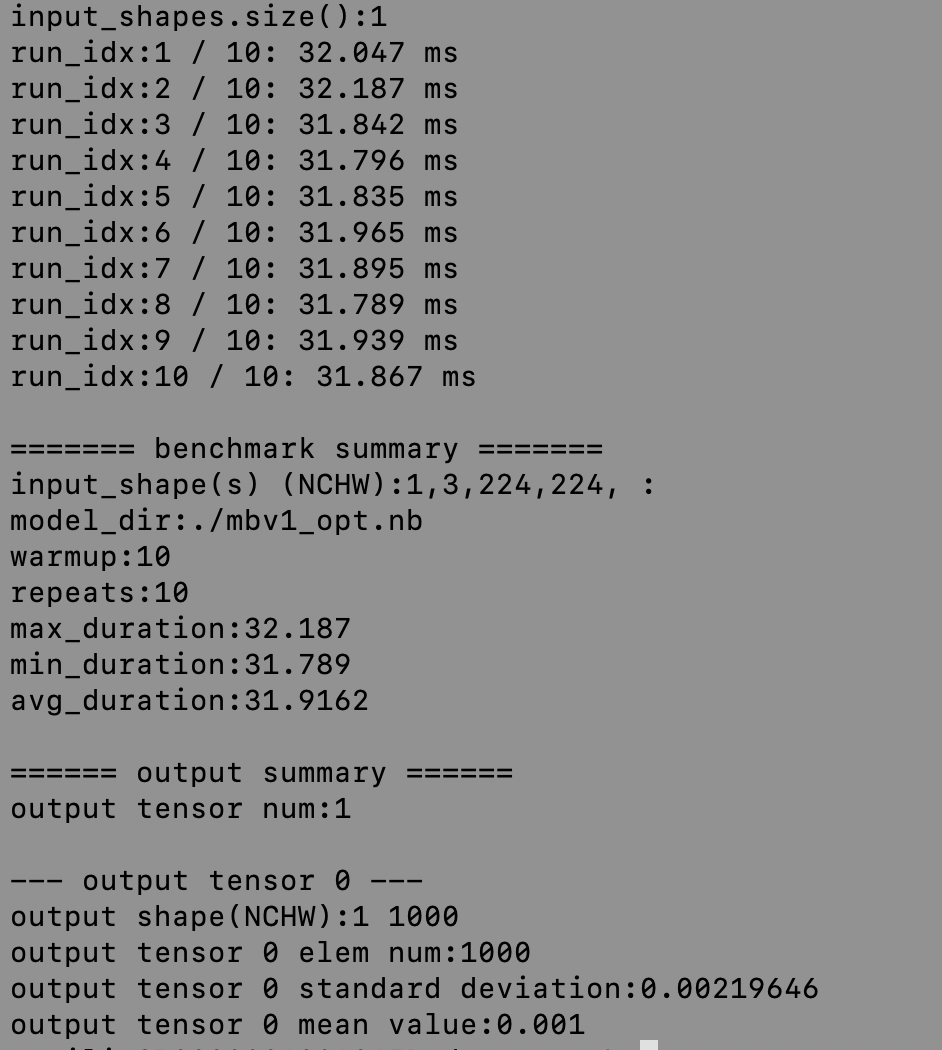
运行效果如下:
原始模型/量化模型:
<div align="center">
<img src="../images/deploy/baseline.png" width="600">
<img src="../images/deploy/quanted.png" width="518">
</div>
docs/images/deploy/baseline.png
0 → 100644
浏览文件 @
245d5fc2
408.0 KB
docs/images/deploy/quanted.png
0 → 100644
浏览文件 @
245d5fc2
396.0 KB
dygraph_docs/quick_start/pruning_tutorial.md
0 → 100644
浏览文件 @
245d5fc2
# 图像分类模型通道剪裁-快速开始
该教程以图像分类模型MobileNetV1为例,说明如何快速使用
[
PaddleSlim的卷积通道剪裁接口
](
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/dygraph_docs
)
。
该示例包含以下步骤:
1.
导入依赖
2.
构建模型和数据集
3.
进行预训练
4.
剪裁
5.
训练剪裁后的模型
以下章节依次次介绍每个步骤的内容。
## 1. 导入依赖
请确认已正确安装Paddle,版本依赖关系可见
[
PaddleSlim Rep主页
](
https://github.com/PaddlePaddle/PaddleSlim
)
。然后按以下方式导入Paddle和PaddleSlim:
```
import paddle
import paddle.vision.models as models
from paddle.static import InputSpec as Input
from paddle.vision.datasets import Cifar10
import paddle.vision.transforms as T
from paddleslim.dygraph import L1NormFilterPruner
```
## 2. 构建网络和数据集
该章节构造一个用于对CIFAR10数据进行分类的分类模型,选用
`MobileNetV1`
,并将输入大小设置为
`[3, 32, 32]`
,输出类别数为10。
为了方便展示示例,我们使用Paddle提供的
[
预定义分类模型
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api/paddle/vision/models/mobilenetv1/MobileNetV1_cn.html#mobilenetv1
)
和
[
高层API
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc1/tutorial/quick_start/high_level_api/high_level_api.html
)
,执行以下代码构建分类模型:
```
net
=
models
.
mobilenet_v1
(
pretrained
=
False
,
scale
=
1.0
,
num_classes
=
10
)
inputs
=
[
Input
([
None
,
3
,
32
,
32
],
'float32'
,
name
=
'image'
)]
labels
=
[
Input
([
None
,
1
],
'int64'
,
name
=
'label'
)]
optimizer
=
paddle
.
optimizer
.
Momentum
(
learning_rate
=
0.1
,
parameters
=
net
.
parameters
())
model
=
paddle
.
Model
(
net
,
inputs
,
labels
)
model
.
prepare
(
optimizer
,
paddle
.
nn
.
CrossEntropyLoss
(),
paddle
.
metric
.
Accuracy
(
topk
=(
1
,
5
)))
transform
=
T
.
Compose
([
T
.
Transpose
(),
T
.
Normalize
([
127.5
],
[
127.5
])
])
val_dataset
=
Cifar10
(
mode
=
'test'
,
transform
=
transform
)
train_dataset
=
Cifar10
(
mode
=
'train'
,
transform
=
transform
)
```
## 3. 进行预训练
对模型进行预训练,为之后的裁剪做准备。
执行以下代码对模型进行预训练
```
model.fit(train_dataset, epochs=2, batch_size=128, verbose=1)
```
## 4. 剪裁卷积层通道
### 4.1 计算剪裁之前的FLOPs
```
FLOPs = paddle.flops(net, input_size=[1, 3, 32, 32], print_detail=True)
```
### 4.2 剪裁
对网络模型两个不同的网络层按照参数名分别进行比例为50%,60%的裁剪。
代码如下所示:
```
pruner = L1NormFilterPruner(net, [1, 3, 32, 32])
pruner.prune_vars({'conv2d_22.w_0':0.5, 'conv2d_20.w_0':0.6}, axis=0)
```
以上操作会按照网络结构中不同网路层的冗余程度对网络层进行不同程度的裁剪并修改网络模型结构。
### 4.3 计算剪裁之后的FLOPs
```
FLOPs = paddle.flops(net, input_size=[1, 3, 32, 32], print_detail=True)
```
## 5. 训练剪裁后的模型
### 5.1 评估裁剪后的模型
对模型进行裁剪会导致模型精度有一定程度下降。
以下代码评估裁剪后模型的精度:
```
model.evaluate(val_dataset, batch_size=128, verbose=1)
```
### 5.2 对模型进行微调
对模型进行finetune会有助于模型恢复原有精度。
以下代码对裁剪过后的模型进行评估后执行了一个
`epoch`
的微调,再对微调过后的模型重新进行评估:
```
model.fit(train_dataset, epochs=1, batch_size=128, verbose=1)
model.evaluate(val_dataset, batch_size=128, verbose=1)
```
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}