add ofa api docs (#576)
* add ofa api docs
Showing
{kind=link}
{kind=link}
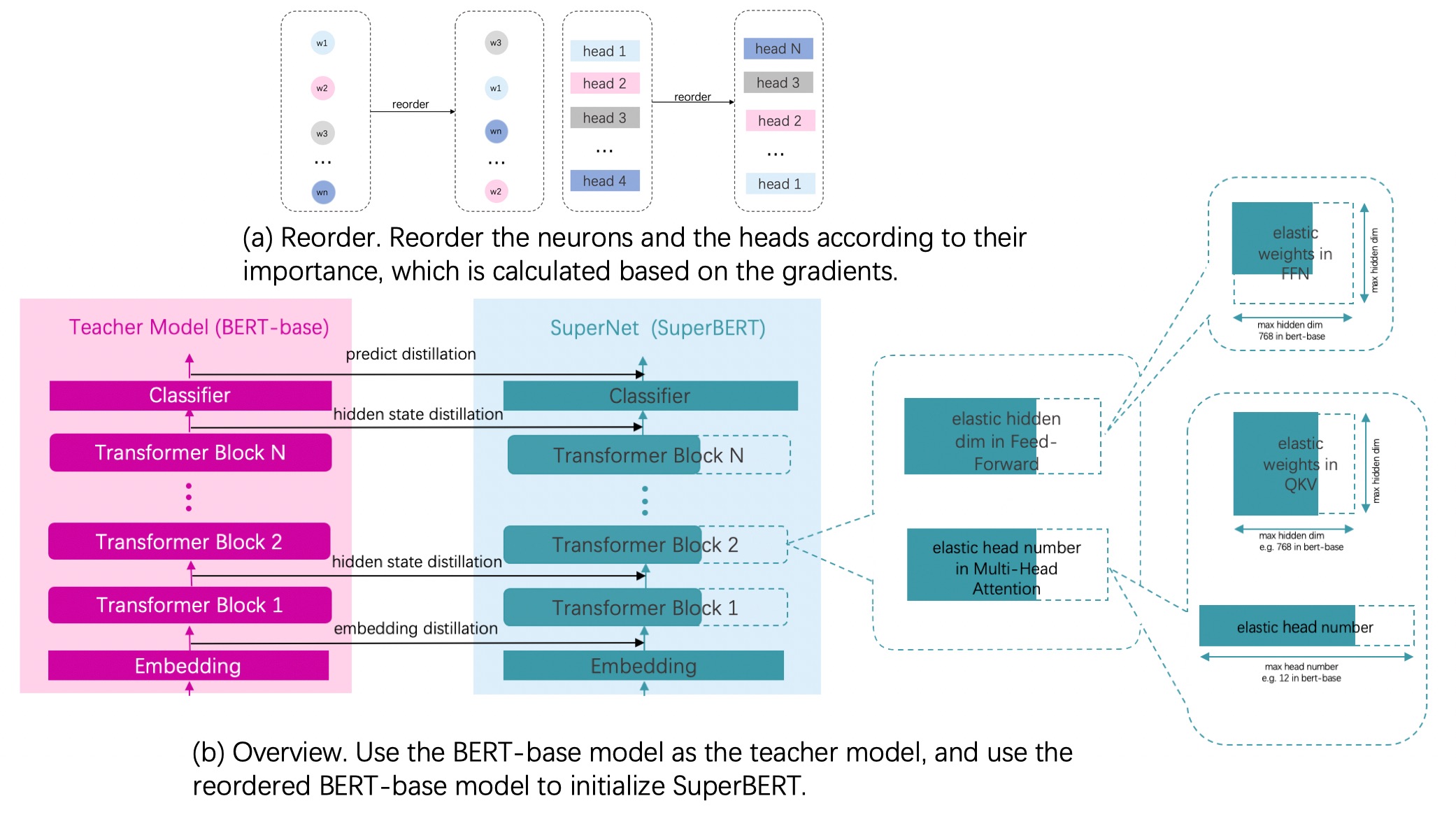
| W: | H:
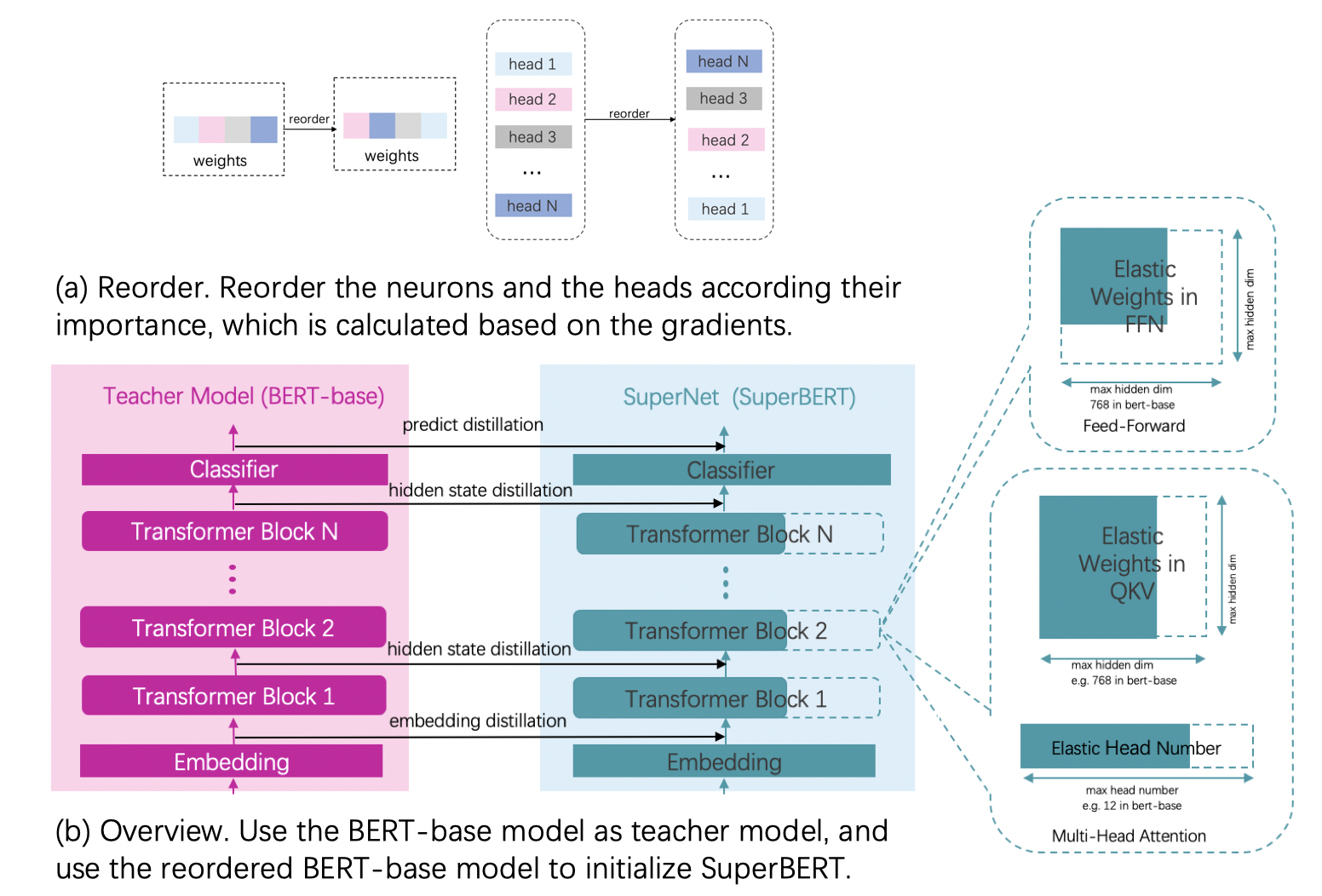
| W: | H:
docs/zh_cn/api_cn/ofa_api.rst
0 → 100644
tests/test_ofa_layers.py
0 → 100644
tests/test_ofa_layers_old.py
0 → 100644