Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSeg
提交
fe611760
P
PaddleSeg
项目概览
PaddlePaddle
/
PaddleSeg
通知
289
Star
8
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
3
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSeg
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
3
合并请求
3
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
You need to sign in or sign up before continuing.
提交
fe611760
编写于
12月 17, 2019
作者:
C
chenguowei01
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/PaddleSeg
into develop
上级
311f9a05
0f365acc
变更
11
隐藏空白更改
内联
并排
Showing
11 changed file
with
155 addition
and
55 deletion
+155
-55
deploy/cpp/README.md
deploy/cpp/README.md
+6
-4
deploy/cpp/demo.cpp
deploy/cpp/demo.cpp
+1
-1
deploy/cpp/docs/linux_build.md
deploy/cpp/docs/linux_build.md
+7
-7
deploy/cpp/docs/vis.md
deploy/cpp/docs/vis.md
+1
-1
deploy/cpp/docs/windows_vs2015_build.md
deploy/cpp/docs/windows_vs2015_build.md
+8
-8
deploy/cpp/docs/windows_vs2019_build.md
deploy/cpp/docs/windows_vs2019_build.md
+6
-5
deploy/cpp/predictor/seg_predictor.cpp
deploy/cpp/predictor/seg_predictor.cpp
+74
-18
deploy/cpp/preprocessor/preprocessor_seg.cpp
deploy/cpp/preprocessor/preprocessor_seg.cpp
+6
-2
deploy/cpp/utils/seg_conf_parser.h
deploy/cpp/utils/seg_conf_parser.h
+10
-0
deploy/cpp/utils/utils.h
deploy/cpp/utils/utils.h
+35
-9
pdseg/export_model.py
pdseg/export_model.py
+1
-0
未找到文件。
deploy/cpp/README.md
浏览文件 @
fe611760
...
@@ -25,7 +25,7 @@
...
@@ -25,7 +25,7 @@
## 2.主要目录和文件
## 2.主要目录和文件
```
```
inference
cpp
├── demo.cpp # 演示加载模型、读入数据、完成预测任务C++代码
├── demo.cpp # 演示加载模型、读入数据、完成预测任务C++代码
|
|
├── conf
├── conf
...
@@ -90,6 +90,8 @@ deeplabv3p_xception65_humanseg
...
@@ -90,6 +90,8 @@ deeplabv3p_xception65_humanseg
DEPLOY
:
DEPLOY
:
# 是否使用GPU预测
# 是否使用GPU预测
USE_GPU
:
1
USE_GPU
:
1
# 是否是PaddleSeg 0.3.0新版本模型
USE_PR
:
1
# 模型和参数文件所在目录路径
# 模型和参数文件所在目录路径
MODEL_PATH
:
"
/root/projects/models/deeplabv3p_xception65_humanseg"
MODEL_PATH
:
"
/root/projects/models/deeplabv3p_xception65_humanseg"
# 模型文件名
# 模型文件名
...
@@ -125,11 +127,11 @@ DEPLOY:
...
@@ -125,11 +127,11 @@ DEPLOY:
`Linux`
系统中执行以下命令:
`Linux`
系统中执行以下命令:
```
shell
```
shell
./demo
--conf
=
/root/projects/PaddleSeg/
inference/conf/humanseg.yaml
--input_dir
=
/root/projects/PaddleSeg/inference
/images/humanseg/
./demo
--conf
=
/root/projects/PaddleSeg/
deploy/cpp/conf/humanseg.yaml
--input_dir
=
/root/projects/PaddleSeg/deploy/cpp
/images/humanseg/
```
```
`Windows`
中执行以下命令:
`Windows`
中执行以下命令:
```
shell
```
shell
D:
\p
rojects
\P
addleSeg
\
i
nference
\b
uild
\R
elease>demo.exe
--conf
=
D:
\\
projects
\\
PaddleSeg
\\
inference
\\
conf
\\
humanseg.yaml
--input_dir
=
D:
\\
projects
\\
PaddleSeg
\\
inference
\\
images
\h
umanseg
\\
D:
\p
rojects
\P
addleSeg
\
d
eploy
\c
pp
\b
uild
\R
elease>demo.exe
--conf
=
D:
\\
projects
\\
PaddleSeg
\\
deploy
\\
cpp
\\
conf
\\
humanseg.yaml
--input_dir
=
D:
\\
projects
\\
PaddleSeg
\\
deploy
\\
cpp
\\
images
\h
umanseg
\\
```
```
...
@@ -141,7 +143,7 @@ D:\projects\PaddleSeg\inference\build\Release>demo.exe --conf=D:\\projects\\Padd
...
@@ -141,7 +143,7 @@ D:\projects\PaddleSeg\inference\build\Release>demo.exe --conf=D:\\projects\\Padd
| input_dir | 需要预测的图片目录 |
| input_dir | 需要预测的图片目录 |
配置文件说明请参考上一步,样例程序会扫描input_dir目录下的所有以
**jpg或jpeg**
为后缀的图片,并生成对应的预测结果(若input_dir目录下没有以
**jpg或jpeg**
为后缀的图片,程序会报错)。图像分割会对
`demo.jpg`
的每个像素进行分类,其预测的结果保存在
`demo_jpg
.png`
中。分割预测结果的图不能直接看到效果,必须经过可视化处理。对于二分类的图像分割模型,样例程序自动将预测结果转换成可视化结果,保存在
`demo_jpg_scoremap.png`
中, 原始尺寸的预测结果在
`demo_jpg_recover.png`
中,如下图。对于
**多分类**
的图像分割模型
,请参考
[
可视化脚本使用方法
](
./docs/vis.md
)
。
配置文件说明请参考上一步,样例程序会扫描input_dir目录下的所有以
**jpg或jpeg**
为后缀的图片,并生成对应的预测结果(若input_dir目录下没有以
**jpg或jpeg**
为后缀的图片,程序会报错)。图像分割会对
`demo.jpg`
的每个像素进行分类,其预测的结果保存在
`demo_jpg
_mask.png`
中。分割预测结果的图不能直接看到效果,必须经过可视化处理。对于二分类的图像分割模型。如果需要对预测结果进行
**可视化**
,请参考
[
可视化脚本使用方法
](
./docs/vis.md
)
。
输入原图
输入原图


...
...
deploy/cpp/demo.cpp
浏览文件 @
fe611760
...
@@ -24,7 +24,7 @@ int main(int argc, char** argv) {
...
@@ -24,7 +24,7 @@ int main(int argc, char** argv) {
google
::
ParseCommandLineFlags
(
&
argc
,
&
argv
,
true
);
google
::
ParseCommandLineFlags
(
&
argc
,
&
argv
,
true
);
if
(
FLAGS_conf
.
empty
()
||
FLAGS_input_dir
.
empty
())
{
if
(
FLAGS_conf
.
empty
()
||
FLAGS_input_dir
.
empty
())
{
std
::
cout
<<
"Usage: ./predictor --conf=/config/path/to/your/model "
std
::
cout
<<
"Usage: ./predictor --conf=/config/path/to/your/model "
<<
"--input_dir=/directory/of/your/input/images"
;
<<
"--input_dir=/directory/of/your/input/images"
<<
std
::
endl
;
return
-
1
;
return
-
1
;
}
}
// 1. create a predictor and init it with conf
// 1. create a predictor and init it with conf
...
...
deploy/cpp/docs/linux_build.md
浏览文件 @
fe611760
...
@@ -16,7 +16,7 @@
...
@@ -16,7 +16,7 @@
1.
`mkdir -p /root/projects/ && cd /root/projects`
1.
`mkdir -p /root/projects/ && cd /root/projects`
2.
`git clone https://github.com/PaddlePaddle/PaddleSeg.git`
2.
`git clone https://github.com/PaddlePaddle/PaddleSeg.git`
`C++`
预测代码在
`/root/projects/PaddleSeg/
inference
`
目录,该目录不依赖任何
`PaddleSeg`
下其他目录。
`C++`
预测代码在
`/root/projects/PaddleSeg/
deploy/cpp
`
目录,该目录不依赖任何
`PaddleSeg`
下其他目录。
### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
...
@@ -25,9 +25,9 @@ PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。其中,针对不
...
@@ -25,9 +25,9 @@ PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。其中,针对不
| 版本 | 链接 |
| 版本 | 链接 |
| ---- | ---- |
| ---- | ---- |
| CPU版本 |
[
fluid_inference.tgz
](
https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_linux_cpu_1.6.1
.tgz
)
|
| CPU版本 |
[
fluid_inference.tgz
](
https://
paddle-inference-lib.bj.bcebos.com/1.6.1-cpu-avx-mkl/fluid_inference
.tgz
)
|
| CUDA 9.0版本 |
[
fluid_inference.tgz
](
https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_linux_cuda97_1.6.1
.tgz
)
|
| CUDA 9.0版本 |
[
fluid_inference.tgz
](
https://
paddle-inference-lib.bj.bcebos.com/1.6.1-gpu-cuda9-cudnn7-avx-mkl/fluid_inference
.tgz
)
|
| CUDA 10.0版本 |
[
fluid_inference.tgz
](
https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_linux_cuda10_1.6.1
.tgz
)
|
| CUDA 10.0版本 |
[
fluid_inference.tgz
](
https://
paddle-inference-lib.bj.bcebos.com/1.6.1-gpu-cuda10-cudnn7-avx-mkl/fluid_inference
.tgz
)
|
针对不同的CPU类型、不同的指令集,官方提供更多可用的预测库版本,目前已经推出1.6版本的预测库。其余版本具体请参考以下链接:
[
C++预测库下载列表
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_usage/deploy/inference/build_and_install_lib_cn.html
)
针对不同的CPU类型、不同的指令集,官方提供更多可用的预测库版本,目前已经推出1.6版本的预测库。其余版本具体请参考以下链接:
[
C++预测库下载列表
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_usage/deploy/inference/build_and_install_lib_cn.html
)
...
@@ -75,7 +75,7 @@ make install
...
@@ -75,7 +75,7 @@ make install
在使用
**GPU版本**
预测库进行编译时,可执行下列操作。
**注意**
把对应的参数改为你的上述依赖库实际路径:
在使用
**GPU版本**
预测库进行编译时,可执行下列操作。
**注意**
把对应的参数改为你的上述依赖库实际路径:
```
shell
```
shell
cd
/root/projects/PaddleSeg/
inference
cd
/root/projects/PaddleSeg/
deploy/cpp
mkdir
build
&&
cd
build
mkdir
build
&&
cd
build
cmake ..
-DWITH_GPU
=
ON
-DPADDLE_DIR
=
/root/projects/fluid_inference
-DCUDA_LIB
=
/usr/local/cuda/lib64/
-DOPENCV_DIR
=
/root/projects/opencv3/
-DCUDNN_LIB
=
/usr/local/cuda/lib64/
-DWITH_STATIC_LIB
=
OFF
cmake ..
-DWITH_GPU
=
ON
-DPADDLE_DIR
=
/root/projects/fluid_inference
-DCUDA_LIB
=
/usr/local/cuda/lib64/
-DOPENCV_DIR
=
/root/projects/opencv3/
-DCUDNN_LIB
=
/usr/local/cuda/lib64/
-DWITH_STATIC_LIB
=
OFF
make
make
...
@@ -83,7 +83,7 @@ make
...
@@ -83,7 +83,7 @@ make
在使用
**CPU版本**
预测库进行编译时,可执行下列操作。
在使用
**CPU版本**
预测库进行编译时,可执行下列操作。
```
shell
```
shell
cd
/root/projects/PaddleSeg/
inference
cd
/root/projects/PaddleSeg/
cpp
mkdir
build
&&
cd
build
mkdir
build
&&
cd
build
cmake ..
-DWITH_GPU
=
OFF
-DPADDLE_DIR
=
/root/projects/fluid_inference
-DOPENCV_DIR
=
/root/projects/opencv3/
-DWITH_STATIC_LIB
=
OFF
cmake ..
-DWITH_GPU
=
OFF
-DPADDLE_DIR
=
/root/projects/fluid_inference
-DOPENCV_DIR
=
/root/projects/opencv3/
-DWITH_STATIC_LIB
=
OFF
...
@@ -98,4 +98,4 @@ make
...
@@ -98,4 +98,4 @@ make
./demo --conf=/path/to/your/conf --input_dir=/path/to/your/input/data/directory
./demo --conf=/path/to/your/conf --input_dir=/path/to/your/input/data/directory
```
```
更详细说明请参考README文档:
[
预测和可视化部分
](
../README.md
)
更详细说明请参考README文档:
[
预测和可视化部分
](
../README.md
)
\ No newline at end of file
deploy/cpp/docs/vis.md
浏览文件 @
fe611760
...
@@ -12,7 +12,7 @@ cd inference/tools/
...
@@ -12,7 +12,7 @@ cd inference/tools/
# 拷贝保存分割预测结果的图片到本目录
# 拷贝保存分割预测结果的图片到本目录
cp
XXX/demo_jpg.png
.
cp
XXX/demo_jpg.png
.
# 运行可视化脚本
# 运行可视化脚本
python visualize.py demo.jpg demo_jpg.png vis_result.png
python visualize.py demo.jpg demo_jpg
_mask
.png vis_result.png
```
```
以下为上述运行可视化脚本例子中每个参数的含义,请根据测试机器中图片的
**实际路径**
修改对应参数。
以下为上述运行可视化脚本例子中每个参数的含义,请根据测试机器中图片的
**实际路径**
修改对应参数。
...
...
deploy/cpp/docs/windows_vs2015_build.md
浏览文件 @
fe611760
...
@@ -15,7 +15,7 @@
...
@@ -15,7 +15,7 @@
1.
打开
`cmd`
, 执行
`cd /d D:\projects`
1.
打开
`cmd`
, 执行
`cd /d D:\projects`
2.
`git clone http://gitlab.baidu.com/Paddle/PaddleSeg.git`
2.
`git clone http://gitlab.baidu.com/Paddle/PaddleSeg.git`
`C++`
预测库代码在
`D:\projects\PaddleSeg\
inference
`
目录,该目录不依赖任何
`PaddleSeg`
下其他目录。
`C++`
预测库代码在
`D:\projects\PaddleSeg\
deploy\cpp
`
目录,该目录不依赖任何
`PaddleSeg`
下其他目录。
### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
...
@@ -24,9 +24,9 @@ PaddlePaddle C++ 预测库主要分为两大版本:CPU版本和GPU版本。其
...
@@ -24,9 +24,9 @@ PaddlePaddle C++ 预测库主要分为两大版本:CPU版本和GPU版本。其
| 版本 | 链接 |
| 版本 | 链接 |
| ---- | ---- |
| ---- | ---- |
| CPU版本 | [fluid_inference_install_dir.zip](https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_install_dir_win_cpu_1.6
.zip) |
| CPU版本 | [fluid_inference_install_dir.zip](https://
paddle-wheel.bj.bcebos.com/1.6.2/win-infer/mkl/cpu/fluid_inference_install_dir
.zip) |
| CUDA 9.0版本 | [fluid_inference_install_dir.zip](https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_install_dir_win_cuda9_1.6.1
.zip) |
| CUDA 9.0版本 | [fluid_inference_install_dir.zip](https://
paddle-wheel.bj.bcebos.com/1.6.2/win-infer/mkl/post97/fluid_inference_install_dir
.zip) |
| CUDA 10.0版本 | [fluid_inference_install_dir.zip](https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_install_dir_win_cuda10_1.6.1
.zip) |
| CUDA 10.0版本 | [fluid_inference_install_dir.zip](https://
paddle-wheel.bj.bcebos.com/1.6.2/win-infer/mkl/post107/fluid_inference_install_dir
.zip) |
解压后`
D:
\p
rojects
\f
luid_inference
`目录包含内容为:
解压后`
D:
\p
rojects
\f
luid_inference
`目录包含内容为:
```
```
...
@@ -70,19 +70,19 @@ call "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\vcvarsall.bat" amd6
...
@@ -70,19 +70,19 @@ call "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\vcvarsall.bat" amd6
```bash
```bash
# 切换到预测库所在目录
# 切换到预测库所在目录
cd /d D:\projects\PaddleSeg\
inference
\
cd /d D:\projects\PaddleSeg\
deply\cpp
\
# 创建构建目录, 重新构建只需要删除该目录即可
# 创建构建目录, 重新构建只需要删除该目录即可
mkdir build
mkdir build
cd build
cd build
# cmake构建VS项目
# cmake构建VS项目
D:\projects\PaddleSeg\
inference
\build> cmake .. -G "Visual Studio 14 2015 Win64" -DWITH_GPU=ON -DPADDLE_DIR=D:\projects\fluid_inference -DCUDA_LIB=D:\projects\cudalib\v9.0\lib\x64 -DOPENCV_DIR=D:\projects\opencv -T host=x64
D:\projects\PaddleSeg\
deploy\cpp
\build> cmake .. -G "Visual Studio 14 2015 Win64" -DWITH_GPU=ON -DPADDLE_DIR=D:\projects\fluid_inference -DCUDA_LIB=D:\projects\cudalib\v9.0\lib\x64 -DOPENCV_DIR=D:\projects\opencv -T host=x64
```
```
在使用**CPU版本**预测库进行编译时,可执行下列操作。
在使用**CPU版本**预测库进行编译时,可执行下列操作。
```bash
```bash
# 切换到预测库所在目录
# 切换到预测库所在目录
cd /d D:\projects\PaddleSeg\
inference
\
cd /d D:\projects\PaddleSeg\
deploy\cpp
\
# 创建构建目录, 重新构建只需要删除该目录即可
# 创建构建目录, 重新构建只需要删除该目录即可
mkdir build
mkdir build
cd build
cd build
...
@@ -102,7 +102,7 @@ D:\projects\PaddleSeg\inference\build> msbuild /m /p:Configuration=Release cpp_i
...
@@ -102,7 +102,7 @@ D:\projects\PaddleSeg\inference\build> msbuild /m /p:Configuration=Release cpp_i
上述`
Visual Studio 2015
`编译产出的可执行文件在`
build
\r
elease
`目录下,切换到该目录:
上述`
Visual Studio 2015
`编译产出的可执行文件在`
build
\r
elease
`目录下,切换到该目录:
```
```
cd /d D:\projects\PaddleSeg\
inference
\build\release
cd /d D:\projects\PaddleSeg\
deploy\cpp
\build\release
```
```
之后执行命令:
之后执行命令:
...
...
deploy/cpp/docs/windows_vs2019_build.md
浏览文件 @
fe611760
...
@@ -15,7 +15,7 @@ Windows 平台下,我们使用`Visual Studio 2015` 和 `Visual Studio 2019 Com
...
@@ -15,7 +15,7 @@ Windows 平台下,我们使用`Visual Studio 2015` 和 `Visual Studio 2019 Com
### Step1: 下载代码
### Step1: 下载代码
1.
点击下载源代码:
[
下载地址
](
https://github.com/PaddlePaddle/PaddleSeg/archive/release/v0.
2
.0.zip
)
1.
点击下载源代码:
[
下载地址
](
https://github.com/PaddlePaddle/PaddleSeg/archive/release/v0.
3
.0.zip
)
2.
解压,解压后目录重命名为
`PaddleSeg`
2.
解压,解压后目录重命名为
`PaddleSeg`
以下代码目录路径为
`D:\projects\PaddleSeg`
为例。
以下代码目录路径为
`D:\projects\PaddleSeg`
为例。
...
@@ -27,9 +27,9 @@ PaddlePaddle C++ 预测库主要分为两大版本:CPU版本和GPU版本。其
...
@@ -27,9 +27,9 @@ PaddlePaddle C++ 预测库主要分为两大版本:CPU版本和GPU版本。其
| 版本 | 链接 |
| 版本 | 链接 |
| ---- | ---- |
| ---- | ---- |
| CPU版本 | [fluid_inference_install_dir.zip](https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_install_dir_win_cpu_1.6
.zip) |
| CPU版本 | [fluid_inference_install_dir.zip](https://
paddle-wheel.bj.bcebos.com/1.6.1/win-infer/mkl/cpu/fluid_inference_install_dir
.zip) |
| CUDA 9.0版本 | [fluid_inference_install_dir.zip](https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_install_dir_win_cuda9_1.6.1
.zip) |
| CUDA 9.0版本 | [fluid_inference_install_dir.zip](https://
paddle-wheel.bj.bcebos.com/1.6.1/win-infer/mkl/post97/fluid_inference_install_dir
.zip) |
| CUDA 10.0版本 | [fluid_inference_install_dir.zip](https://
bj.bcebos.com/paddlehub/paddle_inference_lib/fluid_inference_install_dir_win_cuda10_1.6.1
.zip) |
| CUDA 10.0版本 | [fluid_inference_install_dir.zip](https://
paddle-wheel.bj.bcebos.com/1.6.1/win-infer/mkl/post107/fluid_inference_install_dir
.zip) |
解压后`
D:
\p
rojects
\f
luid_inference
`目录包含内容为:
解压后`
D:
\p
rojects
\f
luid_inference
`目录包含内容为:
```
```
...
@@ -74,6 +74,7 @@ fluid_inference
...
@@ -74,6 +74,7 @@ fluid_inference
| *CUDA_LIB | CUDA的库路径 |
| *CUDA_LIB | CUDA的库路径 |
| OPENCV_DIR | OpenCV的安装路径 |
| OPENCV_DIR | OpenCV的安装路径 |
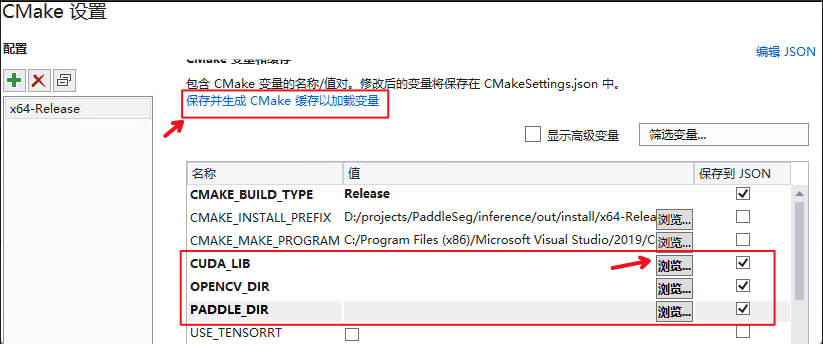
| PADDLE_DIR | Paddle预测库的路径 |
| PADDLE_DIR | Paddle预测库的路径 |
**注意**在使用CPU版本预测库时,需要把CUDA_LIB的勾去掉。
**注意**在使用CPU版本预测库时,需要把CUDA_LIB的勾去掉。

...
@@ -89,7 +90,7 @@ fluid_inference
...
@@ -89,7 +90,7 @@ fluid_inference
上述`
Visual Studio 2019
`编译产出的可执行文件在`
out
\b
uild
\x
64-Release
`目录下,打开`
cmd
`,并切换到该目录:
上述`
Visual Studio 2019
`编译产出的可执行文件在`
out
\b
uild
\x
64-Release
`目录下,打开`
cmd
`,并切换到该目录:
```
```
cd /d D:\projects\PaddleSeg\
inference
\out\build\x64-Release
cd /d D:\projects\PaddleSeg\
deploy\cpp
\out\build\x64-Release
```
```
之后执行命令:
之后执行命令:
...
...
deploy/cpp/predictor/seg_predictor.cpp
浏览文件 @
fe611760
...
@@ -83,7 +83,6 @@ namespace PaddleSolution {
...
@@ -83,7 +83,6 @@ namespace PaddleSolution {
int
blob_out_len
=
length
;
int
blob_out_len
=
length
;
int
seg_out_len
=
eval_height
*
eval_width
*
eval_num_class
;
int
seg_out_len
=
eval_height
*
eval_width
*
eval_num_class
;
if
(
blob_out_len
!=
seg_out_len
)
{
if
(
blob_out_len
!=
seg_out_len
)
{
LOG
(
ERROR
)
<<
" [FATAL] unequal: input vs output ["
<<
LOG
(
ERROR
)
<<
" [FATAL] unequal: input vs output ["
<<
seg_out_len
<<
"|"
<<
blob_out_len
<<
"]"
<<
std
::
endl
;
seg_out_len
<<
"|"
<<
blob_out_len
<<
"]"
<<
std
::
endl
;
...
@@ -99,23 +98,20 @@ namespace PaddleSolution {
...
@@ -99,23 +98,20 @@ namespace PaddleSolution {
std
::
string
nname
(
fname
);
std
::
string
nname
(
fname
);
auto
pos
=
fname
.
rfind
(
"."
);
auto
pos
=
fname
.
rfind
(
"."
);
nname
[
pos
]
=
'_'
;
nname
[
pos
]
=
'_'
;
std
::
string
mask_save_name
=
nname
+
".png"
;
std
::
string
mask_save_name
=
nname
+
"
_mask
.png"
;
cv
::
imwrite
(
mask_save_name
,
mask_png
);
cv
::
imwrite
(
mask_save_name
,
mask_png
);
cv
::
Mat
scoremap_png
=
cv
::
Mat
(
eval_height
,
eval_width
,
CV_8UC1
);
cv
::
Mat
scoremap_png
=
cv
::
Mat
(
eval_height
,
eval_width
,
CV_8UC1
);
scoremap_png
.
data
=
_scoremap
.
data
();
scoremap_png
.
data
=
_scoremap
.
data
();
std
::
string
scoremap_save_name
=
nname
std
::
string
scoremap_save_name
=
nname
+
std
::
string
(
"_scoremap.png"
);
+
std
::
string
(
"_scoremap.png"
);
cv
::
imwrite
(
scoremap_save_name
,
scoremap_png
);
cv
::
imwrite
(
scoremap_save_name
,
scoremap_png
);
std
::
cout
<<
"save mask of ["
<<
fname
<<
"] done"
<<
std
::
endl
;
std
::
cout
<<
"save mask of ["
<<
fname
<<
"] done"
<<
std
::
endl
;
if
(
height
&&
width
)
{
if
(
height
&&
width
)
{
int
recover_height
=
*
height
;
int
recover_height
=
*
height
;
int
recover_width
=
*
width
;
int
recover_width
=
*
width
;
cv
::
Mat
recover_png
=
cv
::
Mat
(
recover_height
,
cv
::
Mat
recover_png
=
cv
::
Mat
(
recover_height
,
recover_width
,
CV_8UC1
);
recover_width
,
CV_8UC1
);
cv
::
resize
(
scoremap_png
,
recover_png
,
cv
::
resize
(
scoremap_png
,
recover_png
,
cv
::
Size
(
recover_width
,
recover_height
),
cv
::
Size
(
recover_width
,
recover_height
),
0
,
0
,
cv
::
INTER_CUBIC
);
0
,
0
,
cv
::
INTER_CUBIC
);
std
::
string
recover_name
=
nname
+
std
::
string
(
"_recover.png"
);
std
::
string
recover_name
=
nname
+
std
::
string
(
"_recover.png"
);
cv
::
imwrite
(
recover_name
,
recover_png
);
cv
::
imwrite
(
recover_name
,
recover_png
);
}
}
...
@@ -176,8 +172,13 @@ namespace PaddleSolution {
...
@@ -176,8 +172,13 @@ namespace PaddleSolution {
}
}
paddle
::
PaddleTensor
im_tensor
;
paddle
::
PaddleTensor
im_tensor
;
im_tensor
.
name
=
"image"
;
im_tensor
.
name
=
"image"
;
im_tensor
.
shape
=
std
::
vector
<
int
>
{
batch_size
,
channels
,
if
(
!
_model_config
.
_use_pr
)
{
eval_height
,
eval_width
};
im_tensor
.
shape
=
std
::
vector
<
int
>
{
batch_size
,
channels
,
eval_height
,
eval_width
};
}
else
{
im_tensor
.
shape
=
std
::
vector
<
int
>
{
batch_size
,
eval_height
,
eval_width
,
channels
};
}
im_tensor
.
data
.
Reset
(
input_buffer
.
data
(),
im_tensor
.
data
.
Reset
(
input_buffer
.
data
(),
real_buffer_size
*
sizeof
(
float
));
real_buffer_size
*
sizeof
(
float
));
im_tensor
.
dtype
=
paddle
::
PaddleDType
::
FLOAT32
;
im_tensor
.
dtype
=
paddle
::
PaddleDType
::
FLOAT32
;
...
@@ -202,19 +203,45 @@ namespace PaddleSolution {
...
@@ -202,19 +203,45 @@ namespace PaddleSolution {
std
::
cout
<<
_outputs
[
0
].
shape
[
j
]
<<
","
;
std
::
cout
<<
_outputs
[
0
].
shape
[
j
]
<<
","
;
}
}
std
::
cout
<<
")"
<<
std
::
endl
;
std
::
cout
<<
")"
<<
std
::
endl
;
const
size_t
nums
=
_outputs
.
front
().
data
.
length
()
/
sizeof
(
float
);
size_t
nums
=
_outputs
.
front
().
data
.
length
()
/
sizeof
(
float
);
if
(
out_num
%
batch_size
!=
0
||
out_num
!=
nums
)
{
if
(
_model_config
.
_use_pr
)
{
LOG
(
ERROR
)
<<
"outputs data size mismatch with shape size."
;
nums
=
_outputs
.
front
().
data
.
length
()
/
sizeof
(
int64_t
);
}
// size mismatch checking
bool
size_mismatch
=
out_num
%
batch_size
;
size_mismatch
|=
(
!
_model_config
.
_use_pr
)
&&
(
nums
!=
out_num
);
size_mismatch
|=
_model_config
.
_use_pr
&&
(
nums
!=
eval_height
*
eval_width
);
if
(
size_mismatch
)
{
LOG
(
ERROR
)
<<
"output with a unexpected size"
;
return
-
1
;
return
-
1
;
}
}
if
(
_model_config
.
_use_pr
)
{
std
::
vector
<
uchar
>
out_data
;
out_data
.
resize
(
out_num
);
auto
addr
=
reinterpret_cast
<
int64_t
*>
(
_outputs
[
0
].
data
.
data
());
for
(
int
r
=
0
;
r
<
out_num
;
++
r
)
{
out_data
[
r
]
=
(
int
)(
addr
[
r
]);
}
for
(
int
r
=
0
;
r
<
batch_size
;
++
r
)
{
cv
::
Mat
mask_png
=
cv
::
Mat
(
eval_height
,
eval_width
,
CV_8UC1
);
mask_png
.
data
=
out_data
.
data
()
+
eval_height
*
eval_width
*
r
;
auto
name
=
imgs_batch
[
r
];
auto
pos
=
name
.
rfind
(
"."
);
name
[
pos
]
=
'_'
;
std
::
string
mask_save_name
=
name
+
"_mask.png"
;
cv
::
imwrite
(
mask_save_name
,
mask_png
);
}
continue
;
}
for
(
int
i
=
0
;
i
<
batch_size
;
++
i
)
{
for
(
int
i
=
0
;
i
<
batch_size
;
++
i
)
{
float
*
output_addr
=
reinterpret_cast
<
float
*>
(
float
*
output_addr
=
reinterpret_cast
<
float
*>
(
_outputs
[
0
].
data
.
data
())
_outputs
[
0
].
data
.
data
())
+
i
*
(
out_num
/
batch_size
);
+
i
*
(
nums
/
batch_size
);
output_mask
(
imgs_batch
[
i
],
output_addr
,
output_mask
(
imgs_batch
[
i
],
output_addr
,
out_num
/
batch_size
,
nums
/
batch_size
,
&
org_height
[
i
],
&
org_height
[
i
],
&
org_width
[
i
]);
&
org_width
[
i
]);
}
}
...
@@ -278,8 +305,14 @@ namespace PaddleSolution {
...
@@ -278,8 +305,14 @@ namespace PaddleSolution {
return
-
1
;
return
-
1
;
}
}
auto
im_tensor
=
_main_predictor
->
GetInputTensor
(
"image"
);
auto
im_tensor
=
_main_predictor
->
GetInputTensor
(
"image"
);
im_tensor
->
Reshape
({
batch_size
,
channels
,
if
(
!
_model_config
.
_use_pr
)
{
im_tensor
->
Reshape
({
batch_size
,
channels
,
eval_height
,
eval_width
});
eval_height
,
eval_width
});
}
else
{
im_tensor
->
Reshape
({
batch_size
,
eval_height
,
eval_width
,
channels
});
}
im_tensor
->
copy_from_cpu
(
input_buffer
.
data
());
im_tensor
->
copy_from_cpu
(
input_buffer
.
data
());
auto
t1
=
std
::
chrono
::
high_resolution_clock
::
now
();
auto
t1
=
std
::
chrono
::
high_resolution_clock
::
now
();
...
@@ -292,7 +325,6 @@ namespace PaddleSolution {
...
@@ -292,7 +325,6 @@ namespace PaddleSolution {
auto
output_names
=
_main_predictor
->
GetOutputNames
();
auto
output_names
=
_main_predictor
->
GetOutputNames
();
auto
output_t
=
_main_predictor
->
GetOutputTensor
(
auto
output_t
=
_main_predictor
->
GetOutputTensor
(
output_names
[
0
]);
output_names
[
0
]);
std
::
vector
<
float
>
out_data
;
std
::
vector
<
int
>
output_shape
=
output_t
->
shape
();
std
::
vector
<
int
>
output_shape
=
output_t
->
shape
();
int
out_num
=
1
;
int
out_num
=
1
;
...
@@ -303,6 +335,30 @@ namespace PaddleSolution {
...
@@ -303,6 +335,30 @@ namespace PaddleSolution {
}
}
std
::
cout
<<
")"
<<
std
::
endl
;
std
::
cout
<<
")"
<<
std
::
endl
;
if
(
_model_config
.
_use_pr
)
{
std
::
vector
<
int64_t
>
out_data
;
out_data
.
resize
(
out_num
);
output_t
->
copy_to_cpu
(
out_data
.
data
());
std
::
vector
<
uchar
>
mask_data
;
mask_data
.
resize
(
out_num
);
auto
addr
=
reinterpret_cast
<
int64_t
*>
(
out_data
.
data
());
for
(
int
r
=
0
;
r
<
out_num
;
++
r
)
{
mask_data
[
r
]
=
(
int
)(
addr
[
r
]);
}
for
(
int
r
=
0
;
r
<
batch_size
;
++
r
)
{
cv
::
Mat
mask_png
=
cv
::
Mat
(
eval_height
,
eval_width
,
CV_8UC1
);
mask_png
.
data
=
mask_data
.
data
()
+
eval_height
*
eval_width
*
r
;
auto
name
=
imgs_batch
[
r
];
auto
pos
=
name
.
rfind
(
"."
);
name
[
pos
]
=
'_'
;
std
::
string
mask_save_name
=
name
+
"_mask.png"
;
cv
::
imwrite
(
mask_save_name
,
mask_png
);
}
continue
;
}
std
::
vector
<
float
>
out_data
;
out_data
.
resize
(
out_num
);
out_data
.
resize
(
out_num
);
output_t
->
copy_to_cpu
(
out_data
.
data
());
output_t
->
copy_to_cpu
(
out_data
.
data
());
for
(
int
i
=
0
;
i
<
batch_size
;
++
i
)
{
for
(
int
i
=
0
;
i
<
batch_size
;
++
i
)
{
...
...
deploy/cpp/preprocessor/preprocessor_seg.cpp
浏览文件 @
fe611760
...
@@ -40,14 +40,18 @@ namespace PaddleSolution {
...
@@ -40,14 +40,18 @@ namespace PaddleSolution {
LOG
(
ERROR
)
<<
"Only support rgb(gray) and rgba image."
;
LOG
(
ERROR
)
<<
"Only support rgb(gray) and rgba image."
;
return
false
;
return
false
;
}
}
cv
::
Size
resize_size
(
_config
->
_resize
[
0
],
_config
->
_resize
[
1
]);
cv
::
Size
resize_size
(
_config
->
_resize
[
0
],
_config
->
_resize
[
1
]);
int
rw
=
resize_size
.
width
;
int
rw
=
resize_size
.
width
;
int
rh
=
resize_size
.
height
;
int
rh
=
resize_size
.
height
;
if
(
*
ori_h
!=
rh
||
*
ori_w
!=
rw
)
{
if
(
*
ori_h
!=
rh
||
*
ori_w
!=
rw
)
{
cv
::
resize
(
im
,
im
,
resize_size
,
0
,
0
,
cv
::
INTER_LINEAR
);
cv
::
resize
(
im
,
im
,
resize_size
,
0
,
0
,
cv
::
INTER_LINEAR
);
}
}
utils
::
normalize
(
im
,
data
,
_config
->
_mean
,
_config
->
_std
);
if
(
!
_config
->
_use_pr
)
{
utils
::
normalize
(
im
,
data
,
_config
->
_mean
,
_config
->
_std
);
}
else
{
utils
::
flatten_mat
(
im
,
data
);
}
return
true
;
return
true
;
}
}
...
...
deploy/cpp/utils/seg_conf_parser.h
浏览文件 @
fe611760
...
@@ -25,6 +25,7 @@ class PaddleSegModelConfigPaser {
...
@@ -25,6 +25,7 @@ class PaddleSegModelConfigPaser {
:
_class_num
(
0
),
:
_class_num
(
0
),
_channels
(
0
),
_channels
(
0
),
_use_gpu
(
0
),
_use_gpu
(
0
),
_use_pr
(
0
),
_batch_size
(
1
),
_batch_size
(
1
),
_model_file_name
(
"__model__"
),
_model_file_name
(
"__model__"
),
_param_file_name
(
"__params__"
)
{
_param_file_name
(
"__params__"
)
{
...
@@ -40,6 +41,7 @@ class PaddleSegModelConfigPaser {
...
@@ -40,6 +41,7 @@ class PaddleSegModelConfigPaser {
_class_num
=
0
;
_class_num
=
0
;
_channels
=
0
;
_channels
=
0
;
_use_gpu
=
0
;
_use_gpu
=
0
;
_use_pr
=
0
;
_batch_size
=
1
;
_batch_size
=
1
;
_model_file_name
.
clear
();
_model_file_name
.
clear
();
_model_path
.
clear
();
_model_path
.
clear
();
...
@@ -172,6 +174,12 @@ class PaddleSegModelConfigPaser {
...
@@ -172,6 +174,12 @@ class PaddleSegModelConfigPaser {
std
::
cerr
<<
"Please set CHANNELS: x"
<<
std
::
endl
;
std
::
cerr
<<
"Please set CHANNELS: x"
<<
std
::
endl
;
return
false
;
return
false
;
}
}
// 15. use_pr
if
(
config
[
"DEPLOY"
][
"USE_PR"
].
IsDefined
())
{
_use_pr
=
config
[
"DEPLOY"
][
"USE_PR"
].
as
<
int
>
();
}
else
{
_use_pr
=
0
;
}
return
true
;
return
true
;
}
}
...
@@ -238,6 +246,8 @@ class PaddleSegModelConfigPaser {
...
@@ -238,6 +246,8 @@ class PaddleSegModelConfigPaser {
std
::
string
_predictor_mode
;
std
::
string
_predictor_mode
;
// DEPLOY.BATCH_SIZE
// DEPLOY.BATCH_SIZE
int
_batch_size
;
int
_batch_size
;
// USE_PR: OP Optimized model
int
_use_pr
;
};
};
}
// namespace PaddleSolution
}
// namespace PaddleSolution
deploy/cpp/utils/utils.h
浏览文件 @
fe611760
...
@@ -23,7 +23,8 @@
...
@@ -23,7 +23,8 @@
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/highgui/highgui.hpp>
#ifdef _WIN32
#ifdef _WIN32
#include <filesystem>
#define GLOG_NO_ABBREVIATED_SEVERITIES
#include <windows.h>
#else
#else
#include <dirent.h>
#include <dirent.h>
#include <sys/types.h>
#include <sys/types.h>
...
@@ -67,15 +68,21 @@ namespace utils {
...
@@ -67,15 +68,21 @@ namespace utils {
// scan a directory and get all files with input extensions
// scan a directory and get all files with input extensions
inline
std
::
vector
<
std
::
string
>
get_directory_images
(
inline
std
::
vector
<
std
::
string
>
get_directory_images
(
const
std
::
string
&
path
,
const
std
::
string
&
exts
)
{
const
std
::
string
&
path
,
const
std
::
string
&
exts
)
{
std
::
string
pattern
(
path
);
pattern
.
append
(
"
\\
*"
);
std
::
vector
<
std
::
string
>
imgs
;
std
::
vector
<
std
::
string
>
imgs
;
for
(
const
auto
&
item
:
WIN32_FIND_DATA
data
;
std
::
experimental
::
filesystem
::
directory_iterator
(
path
))
{
HANDLE
hFind
;
auto
suffix
=
item
.
path
().
extension
().
string
();
if
((
hFind
=
FindFirstFile
(
pattern
.
c_str
(),
&
data
))
!=
INVALID_HANDLE_VALUE
)
{
if
(
exts
.
find
(
suffix
)
!=
std
::
string
::
npos
&&
suffix
.
size
()
>
0
)
{
do
{
auto
fullname
=
path_join
(
path
,
auto
fname
=
std
::
string
(
data
.
cFileName
);
item
.
path
().
filename
().
string
());
auto
pos
=
fname
.
rfind
(
"."
);
imgs
.
push_back
(
item
.
path
().
string
());
auto
ext
=
fname
.
substr
(
pos
+
1
);
}
if
(
ext
.
size
()
>
1
&&
exts
.
find
(
ext
)
!=
std
::
string
::
npos
)
{
imgs
.
push_back
(
path
+
"
\\
"
+
data
.
cFileName
);
}
}
while
(
FindNextFile
(
hFind
,
&
data
)
!=
0
);
FindClose
(
hFind
);
}
}
return
imgs
;
return
imgs
;
}
}
...
@@ -103,6 +110,25 @@ namespace utils {
...
@@ -103,6 +110,25 @@ namespace utils {
}
}
}
}
// flatten a cv::mat
inline
void
flatten_mat
(
cv
::
Mat
&
im
,
float
*
data
)
{
int
rh
=
im
.
rows
;
int
rw
=
im
.
cols
;
int
rc
=
im
.
channels
();
#pragma omp parallel for
for
(
int
h
=
0
;
h
<
rh
;
++
h
)
{
const
uchar
*
ptr
=
im
.
ptr
<
uchar
>
(
h
);
int
im_index
=
0
;
int
top_index
=
h
*
rw
*
rc
;
for
(
int
w
=
0
;
w
<
rw
;
++
w
)
{
for
(
int
c
=
0
;
c
<
rc
;
++
c
)
{
float
pixel
=
static_cast
<
float
>
(
ptr
[
im_index
++
]);
data
[
top_index
++
]
=
pixel
;
}
}
}
}
// argmax
// argmax
inline
void
argmax
(
float
*
out
,
std
::
vector
<
int
>&
shape
,
inline
void
argmax
(
float
*
out
,
std
::
vector
<
int
>&
shape
,
std
::
vector
<
uchar
>&
mask
,
std
::
vector
<
uchar
>&
scoremap
)
{
std
::
vector
<
uchar
>&
mask
,
std
::
vector
<
uchar
>&
scoremap
)
{
...
...
pdseg/export_model.py
浏览文件 @
fe611760
...
@@ -52,6 +52,7 @@ def parse_args():
...
@@ -52,6 +52,7 @@ def parse_args():
def
export_inference_config
():
def
export_inference_config
():
deploy_cfg
=
'''DEPLOY:
deploy_cfg
=
'''DEPLOY:
USE_GPU : 1
USE_GPU : 1
USE_PR : 1
MODEL_PATH : "%s"
MODEL_PATH : "%s"
MODEL_FILENAME : "%s"
MODEL_FILENAME : "%s"
PARAMS_FILENAME : "%s"
PARAMS_FILENAME : "%s"
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录