Optimize lovasz loss implementation, support multiple loss weighted combination (#215)
* modify label tool * add lovasz loss * lovasz * model builder * test * lovasz * update lovasz * update lovasz * add sh yaml * add sh yaml * add sh yaml * no per_image and device_guard * no per_image and device_guard * Update lovasz_loss.md * Update lovasz_loss.md * Update lovasz_loss.md * Update lovasz_loss.md * Update lovasz_loss.md * elementwise_mul replace matmul
Showing
docs/imgs/lovasz-hinge.png
0 → 100644
{kind=link}
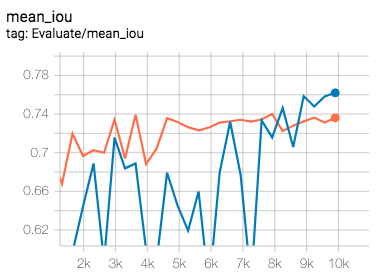
33.8 KB
docs/imgs/lovasz-softmax.png
0 → 100644
{kind=link}
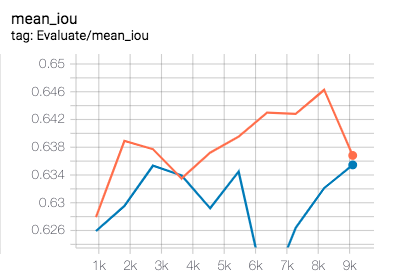
30.5 KB
docs/lovasz_loss.md
0 → 100644
pdseg/lovasz_losses.py
0 → 100755