Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSeg
提交
c2f9874e
P
PaddleSeg
项目概览
PaddlePaddle
/
PaddleSeg
通知
289
Star
8
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
3
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSeg
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
3
合并请求
3
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
c2f9874e
编写于
12月 09, 2019
作者:
S
sjtubinlong
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add Inference Benchmark
上级
8750b689
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
521 addition
and
0 deletion
+521
-0
deploy/python/docs/PaddleSeg_Infer_Benchmark.md
deploy/python/docs/PaddleSeg_Infer_Benchmark.md
+521
-0
未找到文件。
deploy/python/docs/PaddleSeg_Infer_Benchmark.md
0 → 100644
浏览文件 @
c2f9874e
# PaddleSeg 分割模型预测性能测试
## 测试软件环境
-
CUDA 9.0
-
CUDNN 7.6
-
TensorRT-5.1.5
-
PaddlePaddle v1.6.1
-
Ubuntu 16.04
-
GPU: Tesla V100
-
CPU:Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
## 测试方法
-
输入采用 1000张RGB图片,batch_size 统一为 1。
-
重复跑多轮,去掉第一轮预热时间,计后续几轮的平均时间:包括数据拷贝到GPU,预测引擎计算时间,预测结果拷贝回CPU 时间。
-
采用Fluid C++预测引擎
-
测试时开启了 FLAGS_cudnn_exhaustive_search=True,使用exhaustive方式搜索卷积计算算法。
-
对于每个模型,同事测试了
`OP`
优化模型和原生模型的推理速度, 并分别就是否开启
`FP16`
和
`FP32`
的进行了测试
## 推理速度测试数据
**说明**
:
`OP优化模型`
指的是
`PaddleSeg 0.3.0`
版以后导出的新版模型,把图像的预处理和后处理部分放入 GPU 中进行加速,提高性能。每个模型包含了三种
`eval_crop_size`
:
`192x192`
/
`512x512`
/
`768x768`
。
<table
width=
"1440"
>
<tbody>
<tr>
<td
rowspan=
"2"
width=
"432"
>
<p>
模型
</p>
</td>
<td
colspan=
"3"
width=
"535"
>
<p>
原始模型
(单位 ms/image)
</p>
</td>
<td
colspan=
"3"
width=
"588"
>
<p>
OP 优化模型
(单位 ms/image)
</p>
</td>
</tr>
<tr>
<td>
<p>
Fluid
</p>
</td>
<td>
<p>
Fluid-TRT FP32
</p>
</td>
<td>
<p>
Fluid-TRT FP16
</p>
</td>
<td>
<p>
Fluid
</p>
</td>
<td>
<p>
Fluid-TRT FP32
</p>
</td>
<td>
<p>
Fluid-TRT FP16
</p>
</td>
</tr>
<tr>
<td>
<p>
deeplabv3p_mobilenetv2-1-0_bn_192x192
</p>
</td>
<td>
<p>
4.717
</p>
</td>
<td>
<p>
3.085
</p>
</td>
<td>
<p>
2.607
</p>
</td>
<td>
<p>
3.705
</p>
</td>
<td>
<p>
2.09
</p>
</td>
<td>
<p>
1.775
</p>
</td>
</tr>
<tr>
<td>
<p>
deeplabv3p_mobilenetv2-1-0_bn_512x512
</p>
</td>
<td>
<p>
15.848
</p>
</td>
<td>
<p>
14.243
</p>
</td>
<td>
<p>
13.699
</p>
</td>
<td>
<p>
8.284
</p>
</td>
<td>
<p>
6.972
</p>
</td>
<td>
<p>
6.013
</p>
</td>
</tr>
<tr>
<td>
<p>
deeplabv3p_mobilenetv2-1-0_bn_768x768
</p>
</td>
<td>
<p>
63.148
</p>
</td>
<td>
<p>
61.133
</p>
</td>
<td>
<p>
59.262
</p>
</td>
<td>
<p>
16.242
</p>
</td>
<td>
<p>
13.624
</p>
</td>
<td>
<p>
12.018
</p>
</td>
</tr>
<tr>
<td>
<p>
deeplabv3p_xception65_bn_192x192
</p>
</td>
<td>
<p>
9.703
</p>
</td>
<td>
<p>
9.393
</p>
</td>
<td>
<p>
6.46
</p>
</td>
<td>
<p>
8.555
</p>
</td>
<td>
<p>
8.202
</p>
</td>
<td>
<p>
5.15
</p>
</td>
</tr>
<tr>
<td>
<p>
deeplabv3p_xception65_bn_512x512
</p>
</td>
<td>
<p>
30.944
</p>
</td>
<td>
<p>
30.031
</p>
</td>
<td>
<p>
20.716
</p>
</td>
<td>
<p>
23.571
</p>
</td>
<td>
<p>
22.601
</p>
</td>
<td>
<p>
13.327
</p>
</td>
</tr>
<tr>
<td>
<p>
deeplabv3p_xception65_bn_768x768
</p>
</td>
<td>
<p>
92.109
</p>
</td>
<td>
<p>
89.338
</p>
</td>
<td>
<p>
43.342
</p>
</td>
<td>
<p>
44.341
</p>
</td>
<td>
<p>
41.945
</p>
</td>
<td>
<p>
25.486
</p>
</td>
</tr>
<tr>
<td>
<p>
icnet_bn_192x192
</p>
</td>
<td>
<p>
5.706
</p>
</td>
<td>
<p>
5.057
</p>
</td>
<td>
<p>
4.515
</p>
</td>
<td>
<p>
4.694
</p>
</td>
<td>
<p>
4.066
</p>
</td>
<td>
<p>
3.369
</p>
</td>
</tr>
<tr>
<td>
<p>
icnet_bn_512x512
</p>
</td>
<td>
<p>
18.326
</p>
</td>
<td>
<p>
16.971
</p>
</td>
<td>
<p>
16.663
</p>
</td>
<td>
<p>
10.576
</p>
</td>
<td>
<p>
9.779
</p>
</td>
<td>
<p>
9.389
</p>
</td>
</tr>
<tr>
<td>
<p>
icnet_bn_768x768
</p>
</td>
<td>
<p>
67.542
</p>
</td>
<td>
<p>
65.436
</p>
</td>
<td>
<p>
64.197
</p>
</td>
<td>
<p>
18.464
</p>
</td>
<td>
<p>
17.881
</p>
</td>
<td>
<p>
16.958
</p>
</td>
</tr>
<tr>
<td>
<p>
pspnet101_bn_192x192
</p>
</td>
<td>
<p>
20.978
</p>
</td>
<td>
<p>
18.089
</p>
</td>
<td>
<p>
11.946
</p>
</td>
<td>
<p>
20.102
</p>
</td>
<td>
<p>
17.128
</p>
</td>
<td>
<p>
11.011
</p>
</td>
</tr>
<tr>
<td>
<p>
pspnet101_bn_512x512
</p>
</td>
<td>
<p>
72.085
</p>
</td>
<td>
<p>
71.114
</p>
</td>
<td>
<p>
43.009
</p>
</td>
<td>
<p>
64.584
</p>
</td>
<td>
<p>
63.715
</p>
</td>
<td>
<p>
35.806
</p>
</td>
</tr>
<tr>
<td>
<p>
pspnet101_bn_768x768
</p>
</td>
<td>
<p>
160.552
</p>
</td>
<td>
<p>
157.791
</p>
</td>
<td>
<p>
110.544
</p>
</td>
<td>
<p>
111.996
</p>
</td>
<td>
<p>
111.22
</p>
</td>
<td>
<p>
69.646
</p>
</td>
</tr>
<tr>
<td>
<p>
pspnet50_bn_192x192
</p>
</td>
<td>
<p>
13.854
</p>
</td>
<td>
<p>
12.491
</p>
</td>
<td>
<p>
9.357
</p>
</td>
<td>
<p>
12.889
</p>
</td>
<td>
<p>
11.479
</p>
</td>
<td>
<p>
8.516
</p>
</td>
</tr>
<tr>
<td>
<p>
pspnet50_bn_512x512
</p>
</td>
<td>
<p>
55.868
</p>
</td>
<td>
<p>
55.205
</p>
</td>
<td>
<p>
39.659
</p>
</td>
<td>
<p>
48.647
</p>
</td>
<td>
<p>
48.076
</p>
</td>
<td>
<p>
32.403
</p>
</td>
</tr>
<tr>
<td>
<p>
pspnet50_bn_768x768
</p>
</td>
<td>
<p>
135.268
</p>
</td>
<td>
<p>
131.268
</p>
</td>
<td>
<p>
109.732
</p>
</td>
<td>
<p>
85.167
</p>
</td>
<td>
<p>
84.615
</p>
</td>
<td>
<p>
65.483
</p>
</td>
</tr>
<tr>
<td>
<p>
unet_bn_coco_192x192
</p>
</td>
<td>
<p>
7.557
</p>
</td>
<td>
<p>
7.979
</p>
</td>
<td>
<p>
8.049
</p>
</td>
<td>
<p>
4.933
</p>
</td>
<td>
<p>
4.952
</p>
</td>
<td>
<p>
4.959
</p>
</td>
</tr>
<tr>
<td>
<p>
unet_bn_coco_512x512
</p>
</td>
<td>
<p>
37.131
</p>
</td>
<td>
<p>
36.668
</p>
</td>
<td>
<p>
36.706
</p>
</td>
<td>
<p>
26.857
</p>
</td>
<td>
<p>
26.917
</p>
</td>
<td>
<p>
26.928
</p>
</td>
</tr>
<tr>
<td>
<p>
unet_bn_coco_768x768
</p>
</td>
<td>
<p>
110.578
</p>
</td>
<td>
<p>
110.031
</p>
</td>
<td>
<p>
109.979
</p>
</td>
<td>
<p>
59.118
</p>
</td>
<td>
<p>
59.173
</p>
</td>
<td>
<p>
59.124
</p>
</td>
</tr>
</tbody>
</table>
<p>
</p>
## 数据分析
### 1. 新版OP优化模型的加速效果
下图是
`PaddleSeg 0.3.0`
进行OP优化的模型和原模型的性能数据对比(以512x512 为例):

`分析`
:
-
优化模型的加速效果在各模型上都很明显,最高优化效果可达100%
-
模型的
`eval_crop_size`
越大,加速效果越明显
### 2. 使用 TensorRT 开启 FP16 和 FP32 优化效果分析
在原始模型上的加速效果:
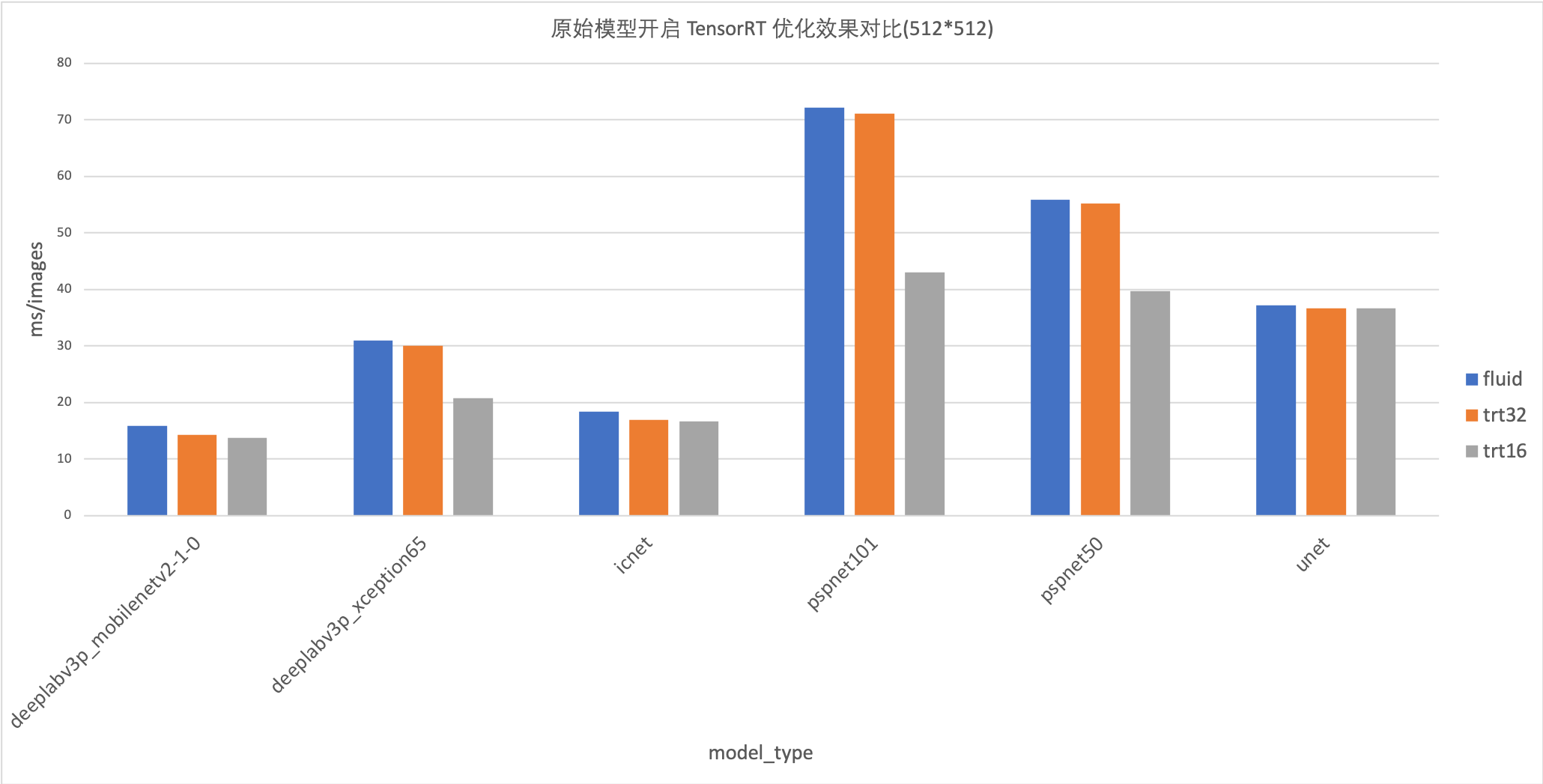
在优化模型上的加速效果:
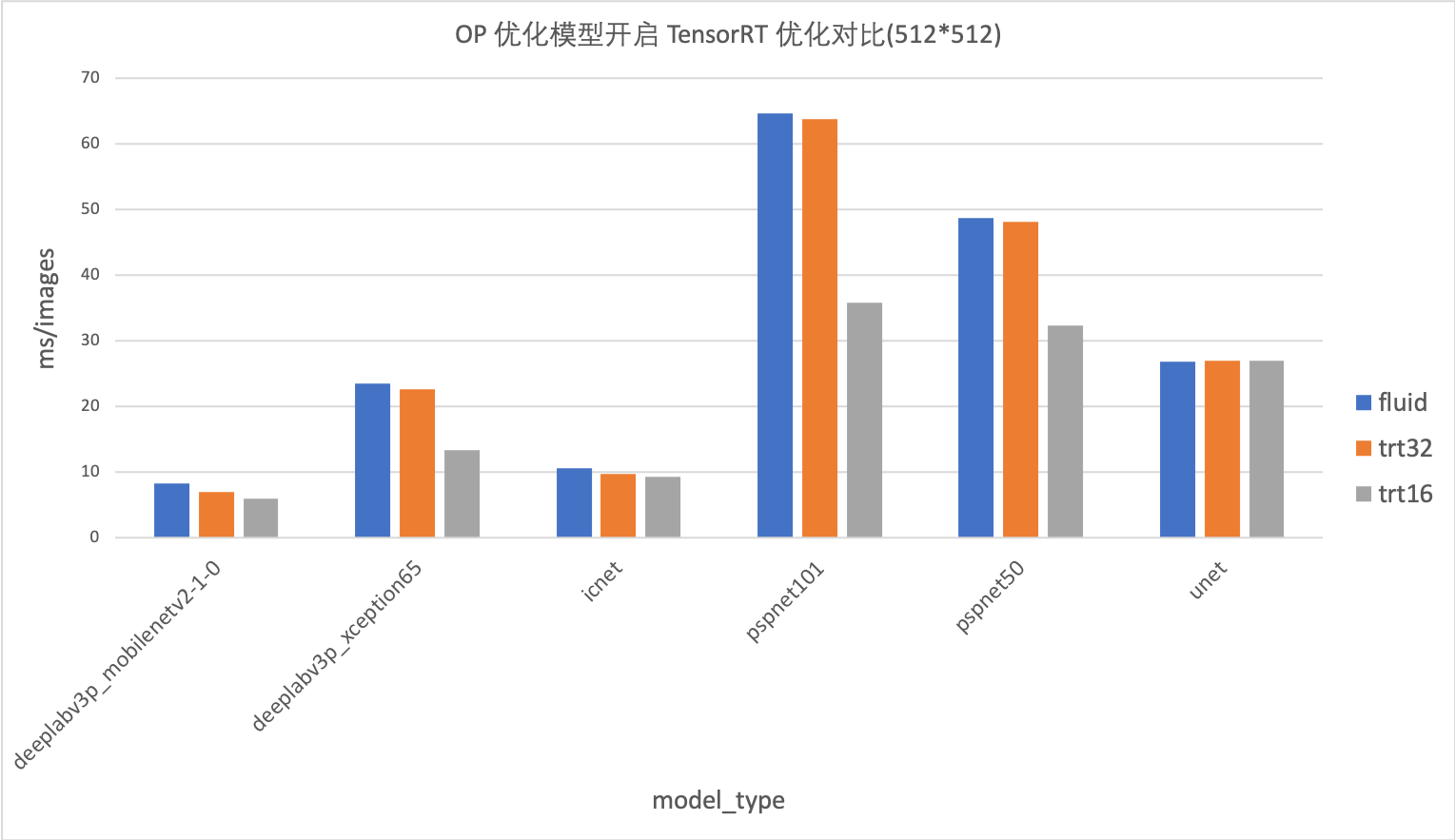
`分析`
:
-
unet和icnet模型,使用Fluid-TensorRT的加速效果不明显,甚至没有加速。
-
deeplabv3p_mobilenetv2模型,Fluid-TensorRT在原生模型的加速效果不明显,仅3%-5%的加速效果。在优化模型的加速效果可以达到20%。
-
`deeplabv3_xception`
、
`pspnet50`
和
`pspnet101`
模型,
`fp16`
加速效果很明显,在
`768x768`
的size下加速效果最高可达110%。
### 3. 不同的EVAL_CROP_SIZE对图片想能的影响
在
`deeplabv3p_xception`
上的数据对比图:

在
`deeplabv3p_mobilenet`
上的数据对比图:

在
`unet`
上的测试数据对比图:

在
`icnet`
上的测试数据对比图:

在
`pspnet101`
上的测试数据对比图:

在
`pspnet50`
上的测试数据对比图:

`分析`
:
-
对于同一模型,
`eval_crop_size`
越大,推理速度越慢
-
同一模型,不管是 TensorRT 优化还是 OP 优化,
`eval_crop_size`
越大效果越明显
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录