Merge branch 'master' of https://github.com/PaddlePaddle/PaddleSeg
pull before pr
Showing
configs/icnet_pet.yaml
0 → 100644
{kind=link}

172.9 KB
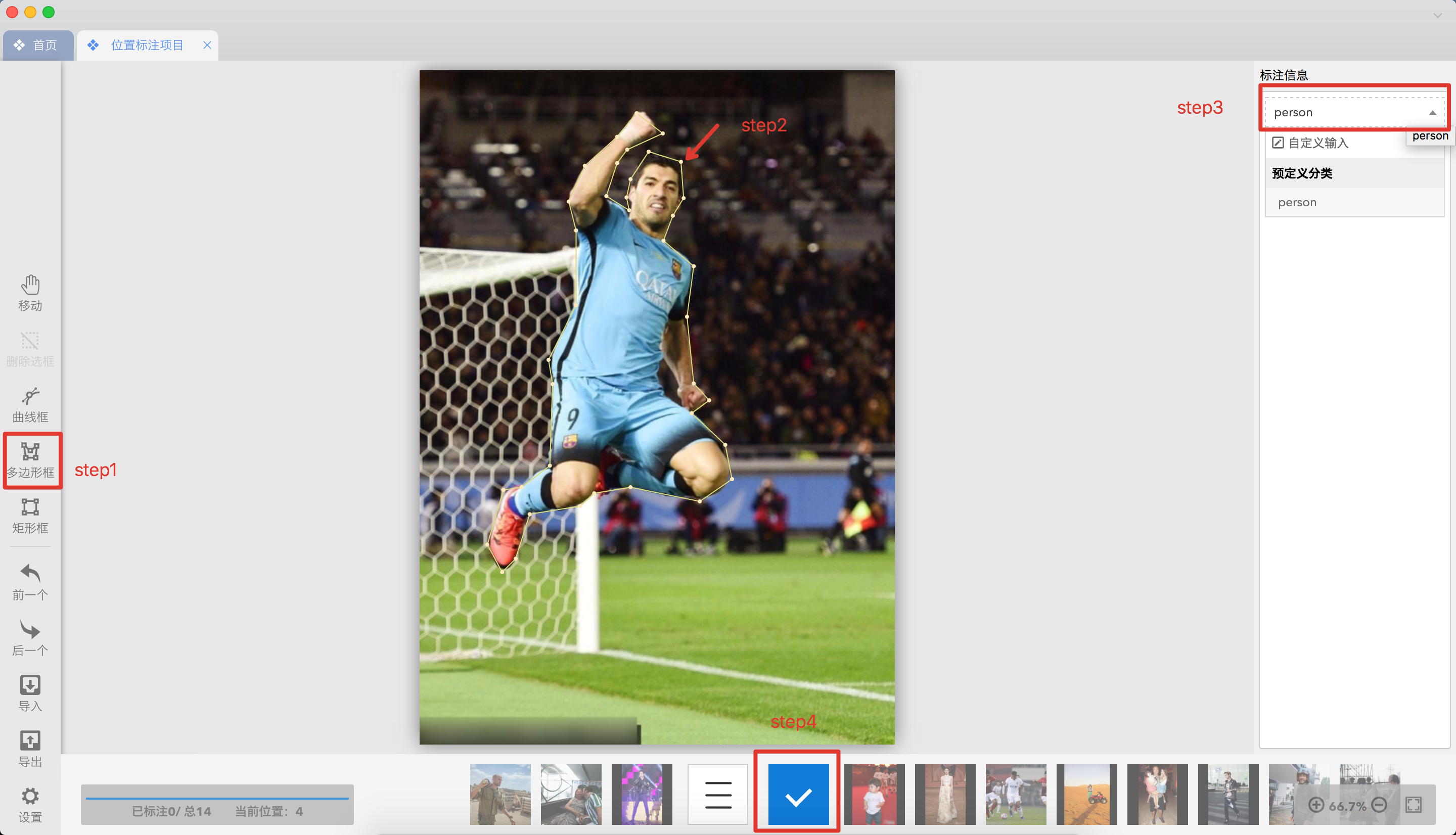
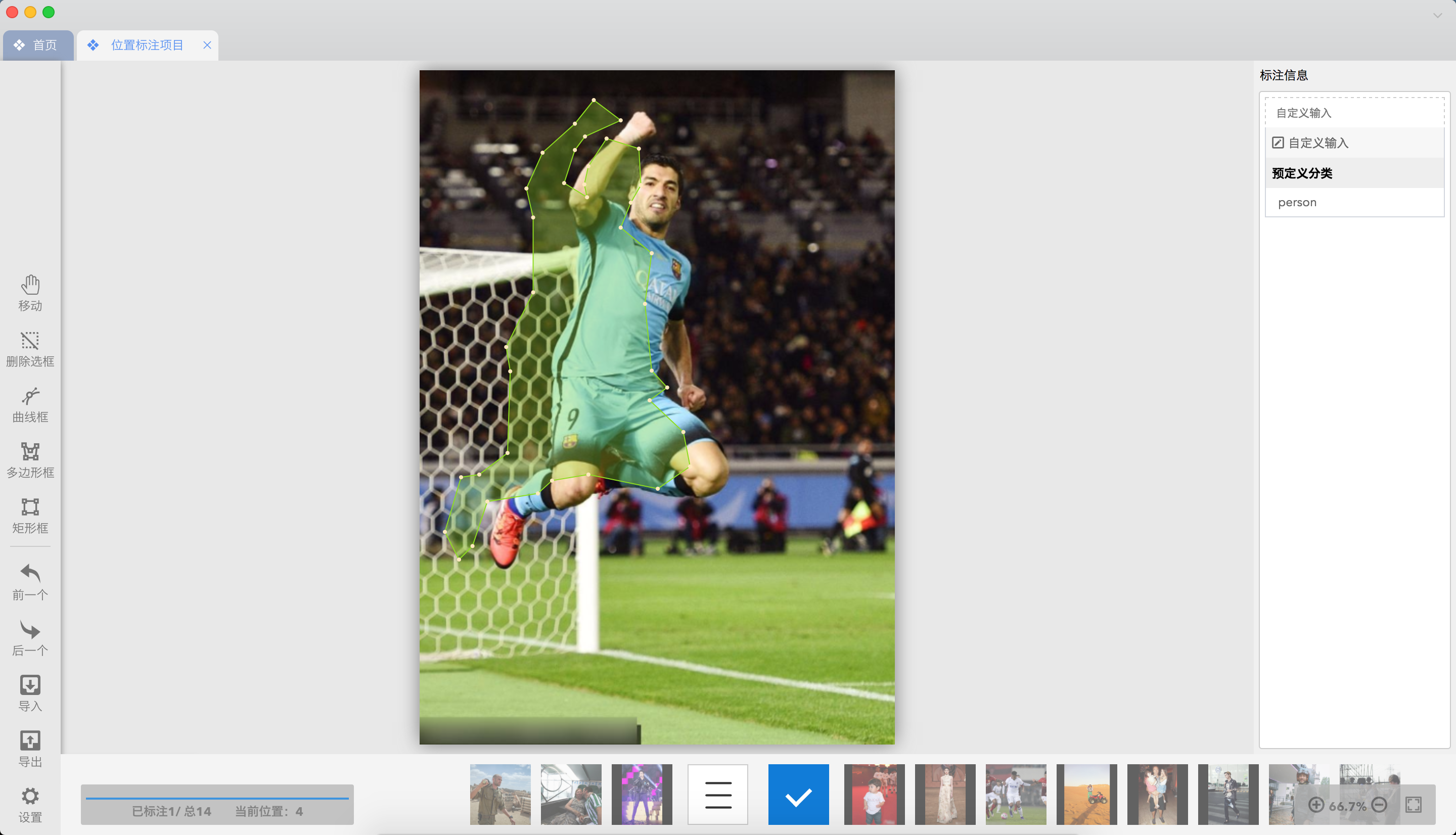
docs/annotation/jingling2seg.md
0 → 100644
docs/annotation/jingling2seg.py
0 → 100644
docs/annotation/labelme2seg.md
0 → 100644
docs/check.md
0 → 100644
{kind=link}
260.6 KB
{kind=link}
2.1 MB
{kind=link}
2.1 MB
{kind=link}
15.8 KB
{kind=link}
153.7 KB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
629.1 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
docs/imgs/qq_group2.png
0 → 100644
{kind=link}

4.6 KB
docs/model_export.md
0 → 100644
pdseg/models/modeling/pspnet.py
0 → 100644
turtorial/finetune_icnet.md
0 → 100644
turtorial/finetune_pspnet.md
0 → 100644
turtorial/finetune_unet.md
0 → 100644