Merge pull request #290 from LutaoChu/rs-doc
Update the whole process documentation for remote sensing
Showing
{kind=link}

885 字节
{kind=link}
1.3 KB
{kind=link}
1.6 KB
{kind=link}

1.4 KB
{kind=link}

106 字节
{kind=link}

106 字节
{kind=link}

416 字节
{kind=link}

186 字节
{kind=link}

372 字节
{kind=link}

611 字节
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
文件已删除
{kind=link}
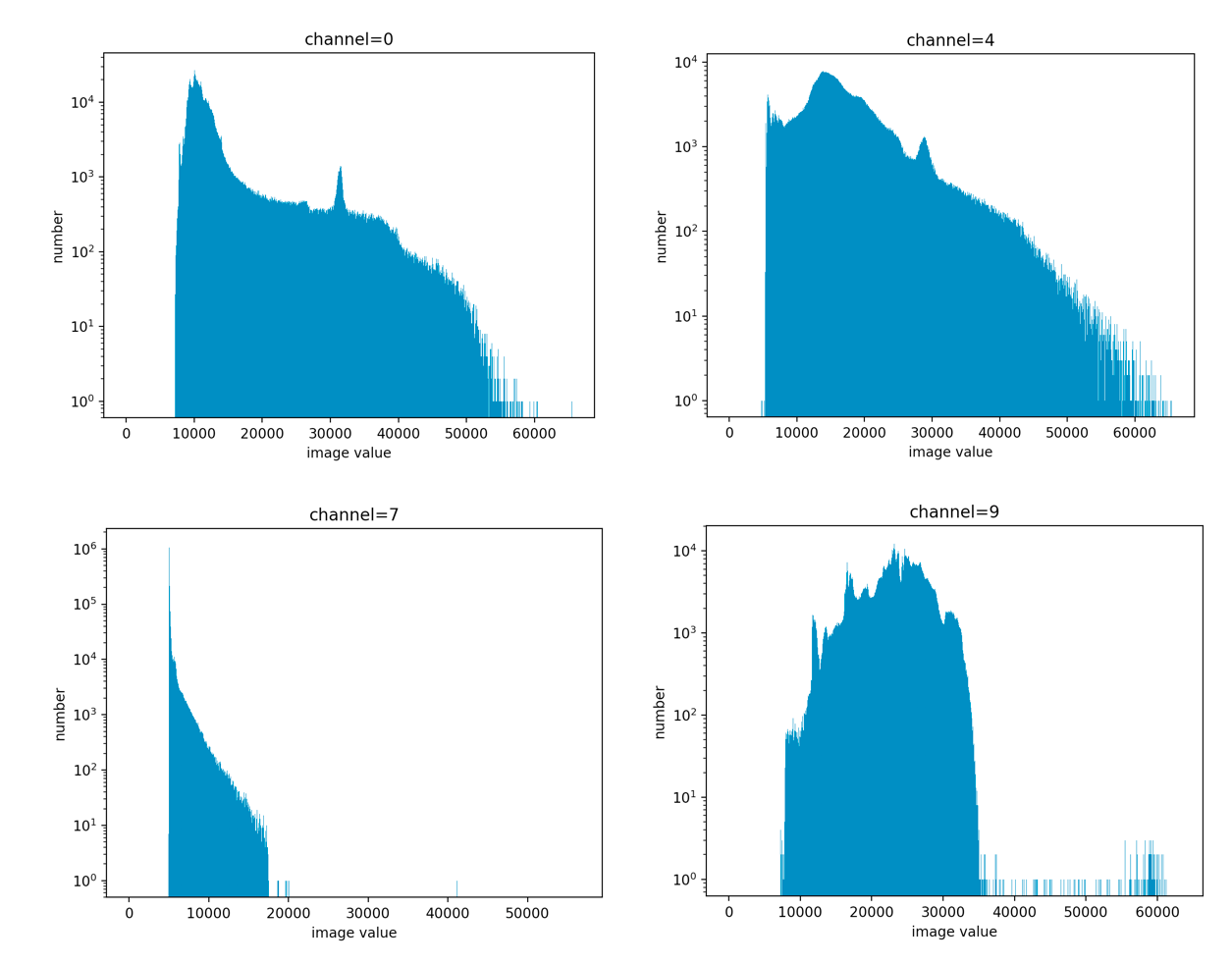
135.4 KB
{kind=link}
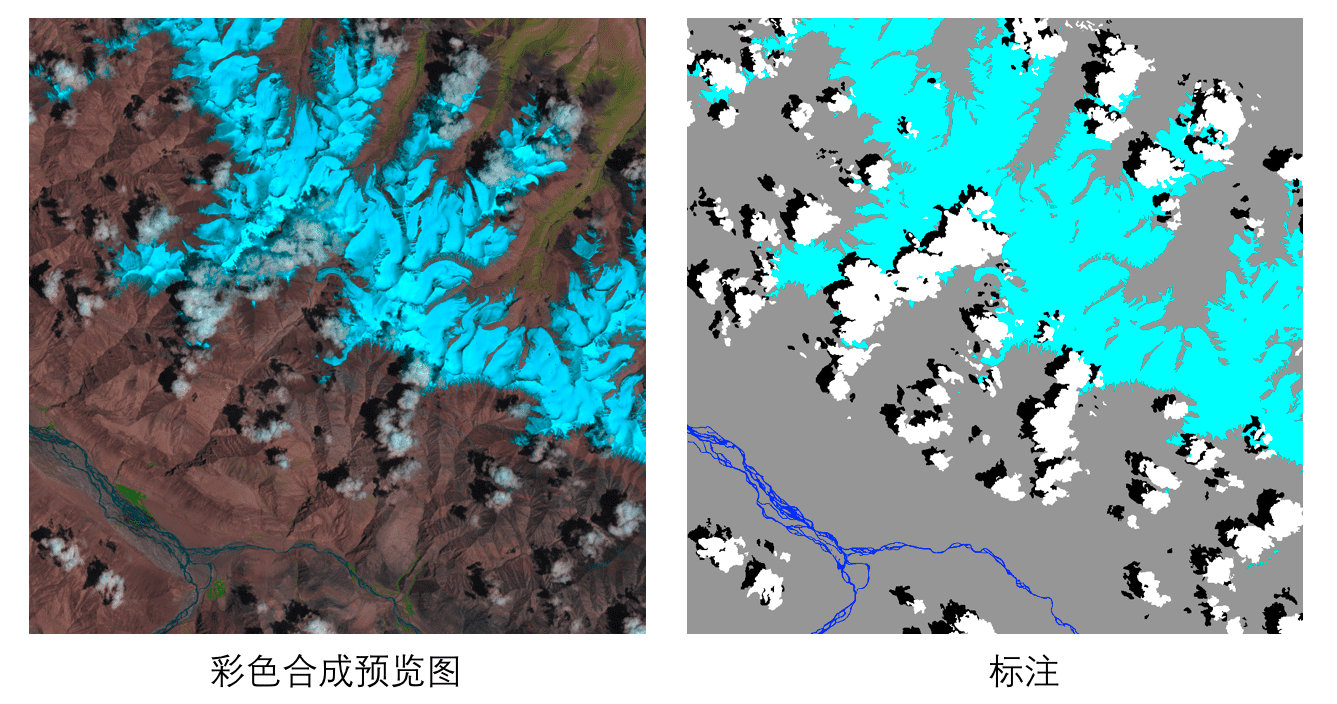
290.8 KB
{kind=link}

90.0 KB
{kind=link}
303.8 KB
{kind=link}
123.5 KB