improve dice loss doc (#115)
* improve dice loss doc
Showing
docs/imgs/dice.png
0 → 100644
{kind=link}
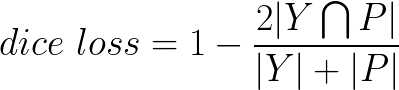
2.6 KB
docs/imgs/dice1.png
已删除
100644 → 0
{kind=link}

7.9 KB
docs/imgs/dice2.png
0 → 100644
{kind=link}
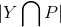
464 字节
docs/imgs/dice3.png
0 → 100644
{kind=link}
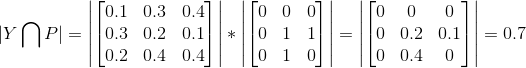
3.8 KB