Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSeg
提交
44f2e0d8
P
PaddleSeg
项目概览
PaddlePaddle
/
PaddleSeg
通知
289
Star
8
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
3
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSeg
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
3
合并请求
3
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
44f2e0d8
编写于
11月 26, 2019
作者:
W
wuzewu
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Fix lr warmup bug
上级
c637e35f
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
65 addition
and
20 deletion
+65
-20
docs/configs/solver_group.md
docs/configs/solver_group.md
+33
-5
docs/imgs/warmup_with_poly_decay_example.png
docs/imgs/warmup_with_poly_decay_example.png
+0
-0
pdseg/solver.py
pdseg/solver.py
+32
-15
未找到文件。
docs/configs/solver_group.md
浏览文件 @
44f2e0d8
...
...
@@ -13,6 +13,28 @@ SOLVER Group定义所有和训练优化相关的配置
<br/>
<br/>
## `LR_WARMUP`
学习率是否经过warmup过程,如果设置为True,则学习率会从0开始,经过
`LR_WARMUP_STEPS`
步后线性增长到指定的初始学习率
### 默认值
False
<br/>
<br/>
## `LR_WARMUP_STEPS`
学习率warmup步数
### 默认值
2000
<br/>
<br/>
## `LR_POLICY`
学习率的衰减策略,支持
`poly`
`piecewise`
`cosine`
三种策略
...
...
@@ -22,7 +44,7 @@ SOLVER Group定义所有和训练优化相关的配置
`poly`
### 示例
*
当使用
`poly`
衰减时,假设初始学习率为0.1,训练总步数为10000,则在power分别为
`0.4`
`0.8``1``1.2`
`1.6`
时,衰减曲线如下图:
*
当使用
`poly`
衰减时,假设初始学习率为0.1,训练总步数为10000,则在power分别为
`0.4`
`0.8`
`1`
`1.2`
`1.6`
时,衰减曲线如下图:
*
power = 1 衰减曲线为直线
*
power > 1 衰减曲线内凹
*
power < 1 衰减曲线外凸
...
...
@@ -30,15 +52,21 @@ SOLVER Group定义所有和训练优化相关的配置
<p
align=
"center"
>
<img
src=
"../imgs/poly_decay_example.png"
hspace=
'10'
height=
"400"
width=
"800"
/>
<br
/>
</p>
*
当使用
`poly`
衰减时,假设初始学习率为0.1,训练总步数为10000,power为
`1`
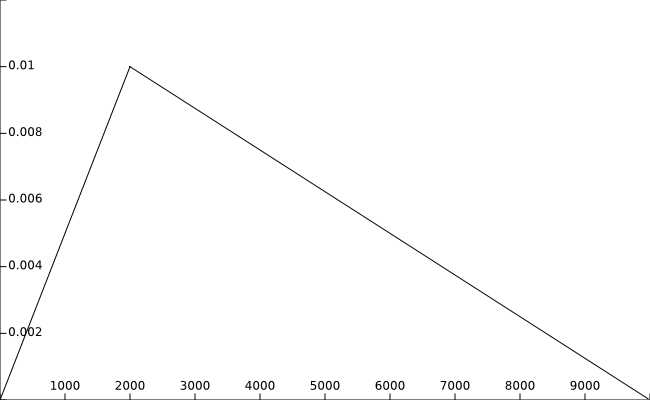
,开启了LR_WARMUP,且LR_WARMUP_STEP为2000时,衰减曲线如下图:
<p
align=
"center"
>
<img
src=
"../imgs/warmup_with_poly_decay_example.png"
hspace=
'10'
height=
"400"
width=
"800"
/>
<br
/>
</p>
*
当使用
`piecewise`
衰减时,假设初始学习率为0.1,GAMMA为0.9,总EPOCH数量为100,DECAY_EPOCH为[10, 20],衰减曲线如下图:
<p
align=
"center"
>
<img
src=
"../imgs/piecewise_decay_example.png"
hspace=
'10'
height=
"400"
width=
"800"
/>
<br
/>
</p>
*
当使用
`cosine`
衰减时,假设初始学习率为0.1,总EPOCH数量为100,衰减曲线如下图:
<p
align=
"center"
>
<img
src=
"../imgs/cosine_decay_example.png"
hspace=
'10'
height=
"400"
width=
"800"
/>
<br
/>
</p>
...
...
@@ -125,7 +153,7 @@ L2正则化系数
## `loss`
训练时选择的损失函数, 支持
`softmax_loss(sotfmax with cross entroy loss)`
,
训练时选择的损失函数, 支持
`softmax_loss(sotfmax with cross entroy loss)`
,
`dice_loss(dice coefficient loss)`
,
`bce_loss(binary cross entroy loss)`
三种损失函数。
其中
`dice_loss`
和
`bce_loss`
仅在两类分割问题中适用,
`softmax_loss`
不能与
`dice_loss`
或
`bce_loss`
组合,
`dice_loss`
可以和
`bce_loss`
组合使用。使用示例如下:
...
...
docs/imgs/warmup_with_poly_decay_example.png
0 → 100644
浏览文件 @
44f2e0d8
18.1 KB
pdseg/solver.py
浏览文件 @
44f2e0d8
...
...
@@ -33,8 +33,11 @@ class Solver(object):
self
.
total_step
=
cfg
.
SOLVER
.
NUM_EPOCHS
*
self
.
step_per_epoch
self
.
main_prog
=
main_prog
self
.
start_prog
=
start_prog
self
.
warmup_step
=
cfg
.
SOLVER
.
LR_WARMUP_STEPS
if
cfg
.
SOLVER
.
LR_WARMUP
else
-
1
self
.
decay_step
=
self
.
total_step
-
self
.
warmup_step
self
.
decay_epochs
=
cfg
.
SOLVER
.
NUM_EPOCHS
-
self
.
warmup_step
/
self
.
step_per_epoch
def
lr_warmup
(
self
,
learning_rate
,
warmup_steps
,
start_lr
,
end_lr
):
def
lr_warmup
(
self
,
learning_rate
,
start_lr
,
end_lr
):
linear_step
=
end_lr
-
start_lr
lr
=
fluid
.
layers
.
tensor
.
create_global_var
(
shape
=
[
1
],
...
...
@@ -44,11 +47,19 @@ class Solver(object):
name
=
"learning_rate_warmup"
)
global_step
=
fluid
.
layers
.
learning_rate_scheduler
.
_decay_step_counter
()
warmup_counter
=
fluid
.
layers
.
autoincreased_step_counter
(
counter_name
=
'@LR_DECAY_COUNTER_WARMUP_IN_SEG@'
,
begin
=
1
,
step
=
1
)
global_counter
=
fluid
.
default_main_program
().
global_block
(
).
vars
[
'@LR_DECAY_COUNTER@'
]
warmup_counter
=
fluid
.
layers
.
cast
(
warmup_counter
,
'float32'
)
with
fluid
.
layers
.
control_flow
.
Switch
()
as
switch
:
with
switch
.
case
(
global_step
<
warmup_steps
):
decayed_lr
=
start_lr
+
linear_step
*
(
global_step
/
warmup_steps
)
with
switch
.
case
(
warmup_counter
<=
self
.
warmup_step
):
decayed_lr
=
start_lr
+
linear_step
*
(
warmup_counter
/
self
.
warmup_step
)
fluid
.
layers
.
tensor
.
assign
(
decayed_lr
,
lr
)
# hold the global_step to 0 during the warm-up phase
fluid
.
layers
.
increment
(
global_counter
,
value
=-
1
)
with
switch
.
default
():
fluid
.
layers
.
tensor
.
assign
(
learning_rate
,
lr
)
return
lr
...
...
@@ -63,12 +74,12 @@ class Solver(object):
def
poly_decay
(
self
):
power
=
cfg
.
SOLVER
.
POWER
decayed_lr
=
fluid
.
layers
.
polynomial_decay
(
cfg
.
SOLVER
.
LR
,
self
.
total
_step
,
end_learning_rate
=
0
,
power
=
power
)
cfg
.
SOLVER
.
LR
,
self
.
decay
_step
,
end_learning_rate
=
0
,
power
=
power
)
return
decayed_lr
def
cosine_decay
(
self
):
decayed_lr
=
fluid
.
layers
.
cosine_decay
(
cfg
.
SOLVER
.
LR
,
self
.
step_per_epoch
,
cfg
.
SOLVER
.
NUM_EPOCHS
)
cfg
.
SOLVER
.
LR
,
self
.
step_per_epoch
,
self
.
decay_epochs
)
return
decayed_lr
def
get_lr
(
self
,
lr_policy
):
...
...
@@ -83,11 +94,7 @@ class Solver(object):
"unsupport learning decay policy! only support poly,piecewise,cosine"
)
if
cfg
.
SOLVER
.
LR_WARMUP
:
start_lr
=
0
end_lr
=
cfg
.
SOLVER
.
LR
warmup_steps
=
cfg
.
SOLVER
.
LR_WARMUP_STEPS
decayed_lr
=
self
.
lr_warmup
(
decayed_lr
,
warmup_steps
,
start_lr
,
end_lr
)
decayed_lr
=
self
.
lr_warmup
(
decayed_lr
,
0
,
cfg
.
SOLVER
.
LR
)
return
decayed_lr
def
sgd_optimizer
(
self
,
lr_policy
,
loss
):
...
...
@@ -103,16 +110,26 @@ class Solver(object):
custom_black_list
=
{
"pool2d"
}
else
:
custom_black_list
=
{}
amp_lists
=
AutoMixedPrecisionLists
(
custom_black_list
=
custom_black_list
)
amp_lists
=
AutoMixedPrecisionLists
(
custom_black_list
=
custom_black_list
)
assert
isinstance
(
cfg
.
MODEL
.
SCALE_LOSS
,
float
)
or
isinstance
(
cfg
.
MODEL
.
SCALE_LOSS
,
str
),
\
"data type of MODEL.SCALE_LOSS must be float or str"
if
isinstance
(
cfg
.
MODEL
.
SCALE_LOSS
,
float
):
optimizer
=
decorate
(
optimizer
,
amp_lists
=
amp_lists
,
init_loss_scaling
=
cfg
.
MODEL
.
SCALE_LOSS
,
use_dynamic_loss_scaling
=
False
)
optimizer
=
decorate
(
optimizer
,
amp_lists
=
amp_lists
,
init_loss_scaling
=
cfg
.
MODEL
.
SCALE_LOSS
,
use_dynamic_loss_scaling
=
False
)
else
:
assert
cfg
.
MODEL
.
SCALE_LOSS
.
lower
()
in
[
'dynamic'
],
"if MODEL.SCALE_LOSS is a string,
\
assert
cfg
.
MODEL
.
SCALE_LOSS
.
lower
()
in
[
'dynamic'
],
"if MODEL.SCALE_LOSS is a string,
\
must be set as 'DYNAMIC'!"
optimizer
=
decorate
(
optimizer
,
amp_lists
=
amp_lists
,
use_dynamic_loss_scaling
=
True
)
optimizer
=
decorate
(
optimizer
,
amp_lists
=
amp_lists
,
use_dynamic_loss_scaling
=
True
)
optimizer
.
minimize
(
loss
)
return
decayed_lr
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}