Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleSeg
提交
41606c13
P
PaddleSeg
项目概览
PaddlePaddle
/
PaddleSeg
通知
289
Star
8
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
53
列表
看板
标记
里程碑
合并请求
3
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleSeg
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
53
Issue
53
列表
看板
标记
里程碑
合并请求
3
合并请求
3
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
41606c13
编写于
3月 26, 2020
作者:
S
sjtubinlong
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add RealTimeHumanSeg C++ inference
上级
b25c6b01
变更
11
隐藏空白更改
内联
并排
Showing
11 changed file
with
1064 addition
and
0 deletion
+1064
-0
contrib/RealTimeHumanSeg/CMakeLists.txt
contrib/RealTimeHumanSeg/CMakeLists.txt
+225
-0
contrib/RealTimeHumanSeg/CMakeSettings.json
contrib/RealTimeHumanSeg/CMakeSettings.json
+42
-0
contrib/RealTimeHumanSeg/README.md
contrib/RealTimeHumanSeg/README.md
+9
-0
contrib/RealTimeHumanSeg/docs/linux_build.md
contrib/RealTimeHumanSeg/docs/linux_build.md
+82
-0
contrib/RealTimeHumanSeg/docs/windows_build.md
contrib/RealTimeHumanSeg/docs/windows_build.md
+81
-0
contrib/RealTimeHumanSeg/humanseg.cc
contrib/RealTimeHumanSeg/humanseg.cc
+129
-0
contrib/RealTimeHumanSeg/humanseg.h
contrib/RealTimeHumanSeg/humanseg.h
+63
-0
contrib/RealTimeHumanSeg/humanseg_postprocess.cc
contrib/RealTimeHumanSeg/humanseg_postprocess.cc
+282
-0
contrib/RealTimeHumanSeg/humanseg_postprocess.h
contrib/RealTimeHumanSeg/humanseg_postprocess.h
+34
-0
contrib/RealTimeHumanSeg/linux_build.sh
contrib/RealTimeHumanSeg/linux_build.sh
+29
-0
contrib/RealTimeHumanSeg/main.cc
contrib/RealTimeHumanSeg/main.cc
+88
-0
未找到文件。
contrib/RealTimeHumanSeg/CMakeLists.txt
0 → 100644
浏览文件 @
41606c13
cmake_minimum_required
(
VERSION 3.0
)
project
(
PaddleMaskDetector CXX C
)
option
(
WITH_MKL
"Compile demo with MKL/OpenBlas support,defaultuseMKL."
ON
)
option
(
WITH_GPU
"Compile demo with GPU/CPU, default use CPU."
ON
)
option
(
WITH_STATIC_LIB
"Compile demo with static/shared library, default use static."
ON
)
option
(
USE_TENSORRT
"Compile demo with TensorRT."
OFF
)
SET
(
PADDLE_DIR
""
CACHE PATH
"Location of libraries"
)
SET
(
OPENCV_DIR
""
CACHE PATH
"Location of libraries"
)
SET
(
CUDA_LIB
""
CACHE PATH
"Location of libraries"
)
macro
(
safe_set_static_flag
)
foreach
(
flag_var
CMAKE_CXX_FLAGS CMAKE_CXX_FLAGS_DEBUG CMAKE_CXX_FLAGS_RELEASE
CMAKE_CXX_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_RELWITHDEBINFO
)
if
(
${
flag_var
}
MATCHES
"/MD"
)
string
(
REGEX REPLACE
"/MD"
"/MT"
${
flag_var
}
"
${${
flag_var
}}
"
)
endif
(
${
flag_var
}
MATCHES
"/MD"
)
endforeach
(
flag_var
)
endmacro
()
if
(
WITH_MKL
)
ADD_DEFINITIONS
(
-DUSE_MKL
)
endif
()
if
(
NOT DEFINED PADDLE_DIR OR
${
PADDLE_DIR
}
STREQUAL
""
)
message
(
FATAL_ERROR
"please set PADDLE_DIR with -DPADDLE_DIR=/path/paddle_influence_dir"
)
endif
()
if
(
NOT DEFINED OPENCV_DIR OR
${
OPENCV_DIR
}
STREQUAL
""
)
message
(
FATAL_ERROR
"please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv"
)
endif
()
include_directories
(
"
${
CMAKE_SOURCE_DIR
}
/"
)
include_directories
(
"
${
PADDLE_DIR
}
/"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/protobuf/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/glog/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/gflags/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/xxhash/include"
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappy/include"
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappystream/include"
)
endif
()
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/zlib/include"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/boost"
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/eigen3"
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
endif
()
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/zlib/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/protobuf/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/glog/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/gflags/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/xxhash/lib"
)
link_directories
(
"
${
PADDLE_DIR
}
/paddle/lib/"
)
link_directories
(
"
${
CMAKE_CURRENT_BINARY_DIR
}
"
)
if
(
WIN32
)
include_directories
(
"
${
PADDLE_DIR
}
/paddle/fluid/inference"
)
include_directories
(
"
${
PADDLE_DIR
}
/paddle/include"
)
link_directories
(
"
${
PADDLE_DIR
}
/paddle/fluid/inference"
)
include_directories
(
"
${
OPENCV_DIR
}
/build/include"
)
include_directories
(
"
${
OPENCV_DIR
}
/opencv/build/include"
)
link_directories
(
"
${
OPENCV_DIR
}
/build/x64/vc14/lib"
)
else
()
include_directories
(
"
${
PADDLE_DIR
}
/paddle/include"
)
link_directories
(
"
${
PADDLE_DIR
}
/paddle/lib"
)
include_directories
(
"
${
OPENCV_DIR
}
/include"
)
link_directories
(
"
${
OPENCV_DIR
}
/lib"
)
endif
()
if
(
WIN32
)
add_definitions
(
"/DGOOGLE_GLOG_DLL_DECL="
)
set
(
CMAKE_C_FLAGS_DEBUG
"
${
CMAKE_C_FLAGS_DEBUG
}
/bigobj /MTd"
)
set
(
CMAKE_C_FLAGS_RELEASE
"
${
CMAKE_C_FLAGS_RELEASE
}
/bigobj /MT"
)
set
(
CMAKE_CXX_FLAGS_DEBUG
"
${
CMAKE_CXX_FLAGS_DEBUG
}
/bigobj /MTd"
)
set
(
CMAKE_CXX_FLAGS_RELEASE
"
${
CMAKE_CXX_FLAGS_RELEASE
}
/bigobj /MT"
)
if
(
WITH_STATIC_LIB
)
safe_set_static_flag
()
add_definitions
(
-DSTATIC_LIB
)
endif
()
else
()
set
(
CMAKE_CXX_FLAGS
"
${
CMAKE_CXX_FLAGS
}
-g -o2 -fopenmp -std=c++11"
)
set
(
CMAKE_STATIC_LIBRARY_PREFIX
""
)
endif
()
# TODO let users define cuda lib path
if
(
WITH_GPU
)
if
(
NOT DEFINED CUDA_LIB OR
${
CUDA_LIB
}
STREQUAL
""
)
message
(
FATAL_ERROR
"please set CUDA_LIB with -DCUDA_LIB=/path/cuda-8.0/lib64"
)
endif
()
if
(
NOT WIN32
)
if
(
NOT DEFINED CUDNN_LIB
)
message
(
FATAL_ERROR
"please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn_v7.4/cuda/lib64"
)
endif
()
endif
(
NOT WIN32
)
endif
()
if
(
NOT WIN32
)
if
(
USE_TENSORRT AND WITH_GPU
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/tensorrt/include"
)
link_directories
(
"
${
PADDLE_DIR
}
/third_party/install/tensorrt/lib"
)
endif
()
endif
(
NOT WIN32
)
if
(
NOT WIN32
)
set
(
NGRAPH_PATH
"
${
PADDLE_DIR
}
/third_party/install/ngraph"
)
if
(
EXISTS
${
NGRAPH_PATH
}
)
include
(
GNUInstallDirs
)
include_directories
(
"
${
NGRAPH_PATH
}
/include"
)
link_directories
(
"
${
NGRAPH_PATH
}
/
${
CMAKE_INSTALL_LIBDIR
}
"
)
set
(
NGRAPH_LIB
${
NGRAPH_PATH
}
/
${
CMAKE_INSTALL_LIBDIR
}
/libngraph
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
WITH_MKL
)
include_directories
(
"
${
PADDLE_DIR
}
/third_party/install/mklml/include"
)
if
(
WIN32
)
set
(
MATH_LIB
${
PADDLE_DIR
}
/third_party/install/mklml/lib/mklml.lib
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5md.lib
)
else
()
set
(
MATH_LIB
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libmklml_intel
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
execute_process
(
COMMAND cp -r
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libmklml_intel
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
/usr/lib
)
endif
()
set
(
MKLDNN_PATH
"
${
PADDLE_DIR
}
/third_party/install/mkldnn"
)
if
(
EXISTS
${
MKLDNN_PATH
}
)
include_directories
(
"
${
MKLDNN_PATH
}
/include"
)
if
(
WIN32
)
set
(
MKLDNN_LIB
${
MKLDNN_PATH
}
/lib/mkldnn.lib
)
else
()
set
(
MKLDNN_LIB
${
MKLDNN_PATH
}
/lib/libmkldnn.so.0
)
endif
()
endif
()
else
()
set
(
MATH_LIB
${
PADDLE_DIR
}
/third_party/install/openblas/lib/libopenblas
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
if
(
WIN32
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/paddle/fluid/inference/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
"
)
set
(
DEPS
${
PADDLE_DIR
}
/paddle/fluid/inference/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
else
()
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
WITH_STATIC_LIB
)
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/libpaddle_fluid
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
else
()
set
(
DEPS
${
PADDLE_DIR
}
/paddle/lib/libpaddle_fluid
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
endif
()
if
(
NOT WIN32
)
set
(
DEPS
${
DEPS
}
${
MATH_LIB
}
${
MKLDNN_LIB
}
glog gflags protobuf z xxhash
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
set
(
DEPS
${
DEPS
}
snappystream
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
set
(
DEPS
${
DEPS
}
snappy
)
endif
()
else
()
set
(
DEPS
${
DEPS
}
${
MATH_LIB
}
${
MKLDNN_LIB
}
opencv_world346 glog gflags_static libprotobuf zlibstatic xxhash
)
set
(
DEPS
${
DEPS
}
libcmt shlwapi
)
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappy/lib"
)
set
(
DEPS
${
DEPS
}
snappy
)
endif
()
if
(
EXISTS
"
${
PADDLE_DIR
}
/third_party/install/snappystream/lib"
)
set
(
DEPS
${
DEPS
}
snappystream
)
endif
()
endif
(
NOT WIN32
)
if
(
WITH_GPU
)
if
(
NOT WIN32
)
if
(
USE_TENSORRT
)
set
(
DEPS
${
DEPS
}
${
PADDLE_DIR
}
/third_party/install/tensorrt/lib/libnvinfer
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
PADDLE_DIR
}
/third_party/install/tensorrt/lib/libnvinfer_plugin
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/libcudart
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
CUDNN_LIB
}
/libcudnn
${
CMAKE_SHARED_LIBRARY_SUFFIX
}
)
else
()
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/cudart
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/cublas
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
set
(
DEPS
${
DEPS
}
${
CUDA_LIB
}
/cudnn
${
CMAKE_STATIC_LIBRARY_SUFFIX
}
)
endif
()
endif
()
if
(
NOT WIN32
)
set
(
EXTERNAL_LIB
"-ldl -lrt -lgomp -lz -lm -lpthread"
"-lopencv_world -lopencv_img_hash"
"-lIlmImf -llibpng -lippiw -lippicv"
"-llibtiff -llibwebp -littnotify -llibjasper"
"-llibjpeg -lzlib"
)
set
(
DEPS
${
DEPS
}
${
EXTERNAL_LIB
}
)
endif
()
add_executable
(
main main.cc humanseg.cc humanseg_postprocess.cc
)
target_link_libraries
(
main
${
DEPS
}
)
if
(
WIN32
)
add_custom_command
(
TARGET main POST_BUILD
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/mklml.dll ./mklml.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
COMMAND
${
CMAKE_COMMAND
}
-E copy_if_different
${
PADDLE_DIR
}
/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
)
endif
()
contrib/RealTimeHumanSeg/CMakeSettings.json
0 → 100644
浏览文件 @
41606c13
{
"configurations"
:
[
{
"name"
:
"x64-Release"
,
"generator"
:
"Ninja"
,
"configurationType"
:
"RelWithDebInfo"
,
"inheritEnvironments"
:
[
"msvc_x64_x64"
],
"buildRoot"
:
"${projectDir}
\\
out
\\
build
\\
${name}"
,
"installRoot"
:
"${projectDir}
\\
out
\\
install
\\
${name}"
,
"cmakeCommandArgs"
:
""
,
"buildCommandArgs"
:
"-v"
,
"ctestCommandArgs"
:
""
,
"variables"
:
[
{
"name"
:
"CUDA_LIB"
,
"value"
:
"D:/projects/packages/cuda10_0/lib64"
,
"type"
:
"PATH"
},
{
"name"
:
"CUDNN_LIB"
,
"value"
:
"D:/projects/packages/cuda10_0/lib64"
,
"type"
:
"PATH"
},
{
"name"
:
"OPENCV_DIR"
,
"value"
:
"D:/projects/packages/opencv3_4_6"
,
"type"
:
"PATH"
},
{
"name"
:
"PADDLE_DIR"
,
"value"
:
"D:/projects/packages/fluid_inference1_6_1"
,
"type"
:
"PATH"
},
{
"name"
:
"CMAKE_BUILD_TYPE"
,
"value"
:
"Release"
,
"type"
:
"STRING"
}
]
}
]
}
\ No newline at end of file
contrib/RealTimeHumanSeg/README.md
0 → 100644
浏览文件 @
41606c13
# 视频实时图像分割模型C++预测部署
本文档主要介绍实时图像分割模型如何在
`Windows`
和
`Linux`
上完成基于
`C++`
的预测部署。
## C++预测部署编译
本项目支持在Windows和Linux上编译并部署C++项目,不同平台的编译请参考:
-
[
Linux 编译
](
./docs/linux_build.md
)
-
[
Windows 使用 Visual Studio 2019编译
](
./docs/windows_build.md
)
contrib/RealTimeHumanSeg/docs/linux_build.md
0 → 100644
浏览文件 @
41606c13
# 视频实时人像分割模型Linux平台C++预测部署
## 1. 系统和软件依赖
### 1.1 操作系统及硬件要求
-
Ubuntu 14.04 或者 16.04 (其它平台未测试)
-
GCC版本4.8.5 ~ 4.9.2
-
支持Intel MKL-DNN的CPU
-
NOTE: 如需在Nvidia GPU运行,请自行安装CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
### 1.2 下载PaddlePaddle C++预测库
PaddlePaddle C++ 预测库主要分为CPU版本和GPU版本。
其中,GPU 版本支持
`CUDA 10.0`
和
`CUDA 9.0`
:
以下为各版本C++预测库的下载链接:
| 版本 | 链接 |
| ---- | ---- |
| CPU+MKL版 |
[
fluid_inference.tgz
](
https://paddle-inference-lib.bj.bcebos.com/1.6.3-cpu-avx-mkl/fluid_inference.tgz
)
|
| CUDA9.0+MKL 版 |
[
fluid_inference.tgz
](
https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda9-cudnn7-avx-mkl/fluid_inference.tgz
)
|
| CUDA10.0+MKL 版 |
[
fluid_inference.tgz
](
https://paddle-inference-lib.bj.bcebos.com/1.6.3-gpu-cuda10-cudnn7-avx-mkl/fluid_inference.tgz
)
|
更多可用预测库版本,请点击以下链接下载:
[
C++预测库下载列表
](
https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/build_and_install_lib_cn.html
)
下载并解压, 解压后的
`fluid_inference`
目录包含的内容:
```
fluid_inference
├── paddle # paddle核心库和头文件
|
├── third_party # 第三方依赖库和头文件
|
└── version.txt # 版本和编译信息
```
**注意:**
请把解压后的目录放到合适的路径,
**该目录路径后续会作为编译依赖**
使用。
## 2. 编译与运行
### 2.1 配置编译脚本
打开文件
`linux_build.sh`
, 看到以下内容:
```
shell
# 是否使用GPU
WITH_GPU
=
OFF
# Paddle 预测库路径
PADDLE_DIR
=
/PATH/TO/fluid_inference/
# CUDA库路径, 仅 WITH_GPU=ON 时设置
CUDA_LIB
=
/PATH/TO/CUDA_LIB64/
# CUDNN库路径,仅 WITH_GPU=ON 且 CUDA_LIB有效时设置
CUDNN_LIB
=
/PATH/TO/CUDNN_LIB64/
# OpenCV 库路径, 无须设置
OPENCV_DIR
=
/PATH/TO/opencv3gcc4.8/
cd
build
cmake ..
\
-DWITH_GPU
=
${
WITH_GPU
}
\
-DPADDLE_DIR
=
${
PADDLE_DIR
}
\
-DCUDA_LIB
=
${
CUDA_LIB
}
\
-DCUDNN_LIB
=
${
CUDNN_LIB
}
\
-DOPENCV_DIR
=
${
OPENCV_DIR
}
\
-DWITH_STATIC_LIB
=
OFF
make
-j4
```
把上述参数根据实际情况做修改后,运行脚本编译程序:
```
shell
sh linux_build.sh
```
### 2.2. 运行和可视化
可执行文件有
**2**
个参数,第一个是前面导出的
`inference_model`
路径,第二个是需要预测的视频路径。
示例:
```
shell
./build/main ./models /PATH/TO/TEST_VIDEO
```
contrib/RealTimeHumanSeg/docs/windows_build.md
0 → 100644
浏览文件 @
41606c13
# 视频实时人像分割模型Windows平台C++预测部署
## 1. 系统和软件依赖
### 1.1 基础依赖
-
Windows 10 / Windows Server 2016+ (其它平台未测试)
-
Visual Studio 2019 (社区版或专业版均可)
-
CUDA 9.0 / 10.0 + CUDNN 7.3+ (不支持9.1/10.1版本的CUDA)
### 1.2 下载OpenCV并设置环境变量
-
在OpenCV官网下载适用于Windows平台的3.4.6版本:
[
点击下载
](
https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download
)
-
运行下载的可执行文件,将OpenCV解压至合适目录,这里以解压到
`D:\projects\opencv`
为例
-
把OpenCV动态库加入到系统环境变量
-
此电脑(我的电脑)->属性->高级系统设置->环境变量
-
在系统变量中找到Path(如没有,自行创建),并双击编辑
-
新建,将opencv路径填入并保存,如D:
\p
rojects
\o
pencv
\b
uild
\x
64
\v
c14
\b
in
**注意:**
`OpenCV`
的解压目录后续将做为编译配置项使用,所以请放置合适的目录中。
### 1.3 下载PaddlePaddle C++ 预测库
`PaddlePaddle`
**C++ 预测库**
主要分为
`CPU`
和
`GPU`
版本, 其中
`GPU版本`
提供
`CUDA 9.0`
和
`CUDA 10.0`
支持。
常用的版本如下:
| 版本 | 链接 |
| ---- | ---- |
| CPU+MKL版 |
[
fluid_inference_install_dir.zip
](
https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/cpu/fluid_inference_install_dir.zip
)
|
| CUDA9.0+MKL 版 |
[
fluid_inference_install_dir.zip
](
https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post97/fluid_inference_install_dir.zip
)
|
| CUDA10.0+MKL 版 |
[
fluid_inference_install_dir.zip
](
https://paddle-wheel.bj.bcebos.com/1.6.3/win-infer/mkl/post107/fluid_inference_install_dir.zip
)
|
更多不同平台的可用预测库版本,请
[
点击查看
](
https://paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/windows_cpp_inference.html
)
选择适合你的版本。
下载并解压, 解压后的
`fluid_inference`
目录包含的内容:
```
fluid_inference_install_dir
├── paddle # paddle核心库和头文件
|
├── third_party # 第三方依赖库和头文件
|
└── version.txt # 版本和编译信息
```
**注意:**
这里的
`fluid_inference_install_dir`
目录所在路径,将用于后面的编译参数设置,请放置在合适的位置。
## 2. Visual Studio 2019 编译
-
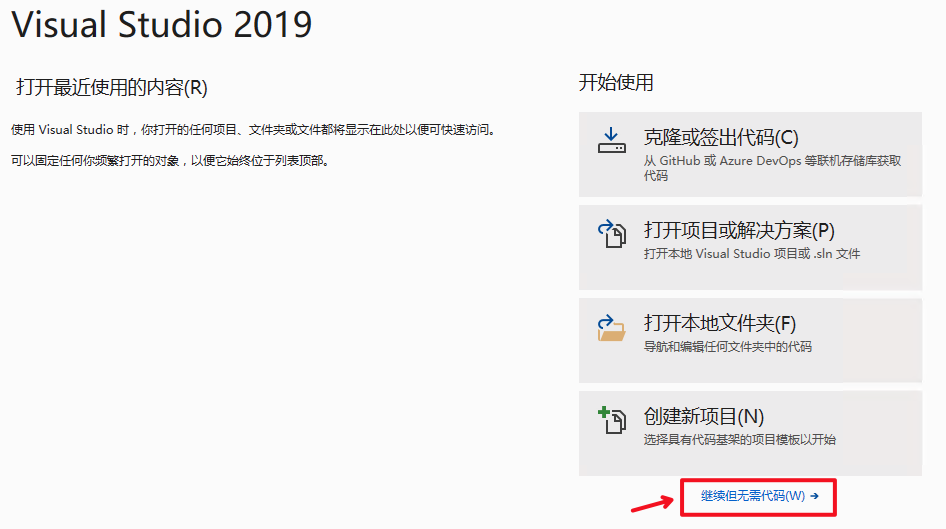
2.1 打开Visual Studio 2019 Community,点击
`继续但无需代码`
, 如下图:
-
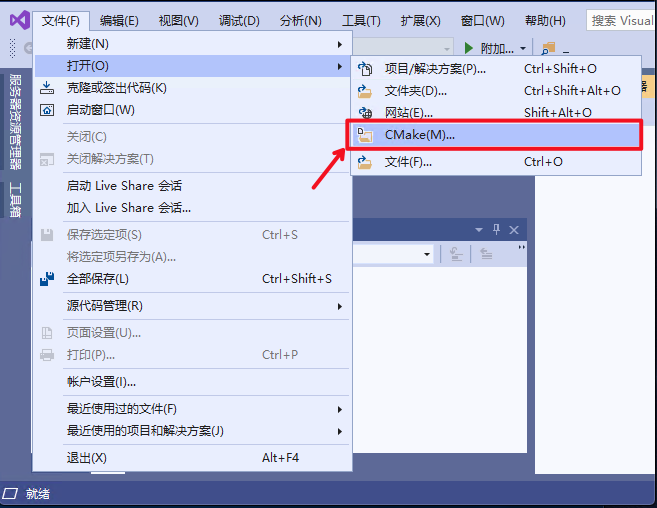
2.2 点击
`文件`
->
`打开`
->
`CMake`
, 如下图:
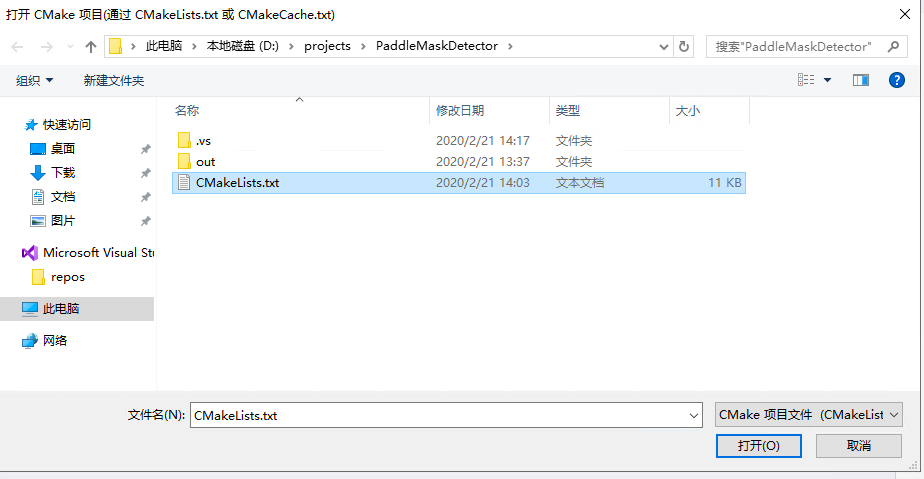
-
2.3 选择本项目根目录
`CMakeList.txt`
文件打开, 如下图:
-
2.4 点击:
`项目`
->
`PaddleMaskDetector的CMake设置`
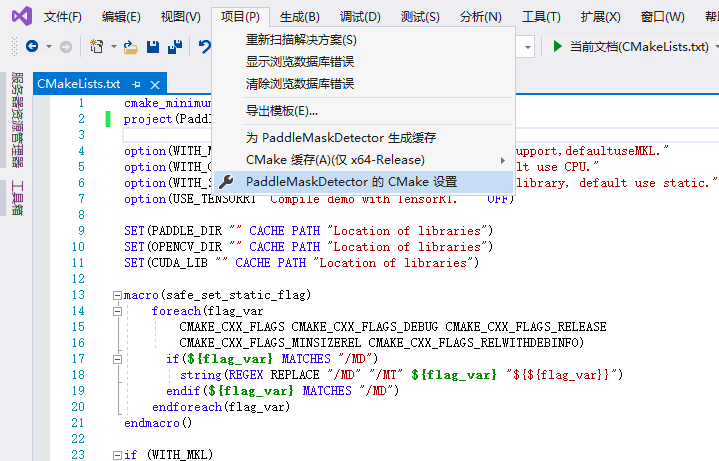
-
2.5 点击浏览设置
`OPENCV_DIR`
,
`CUDA_LIB`
和
`PADDLE_DIR`
3个编译依赖库的位置, 设置完成后点击
`保存并生成CMake缓存并加载变量`
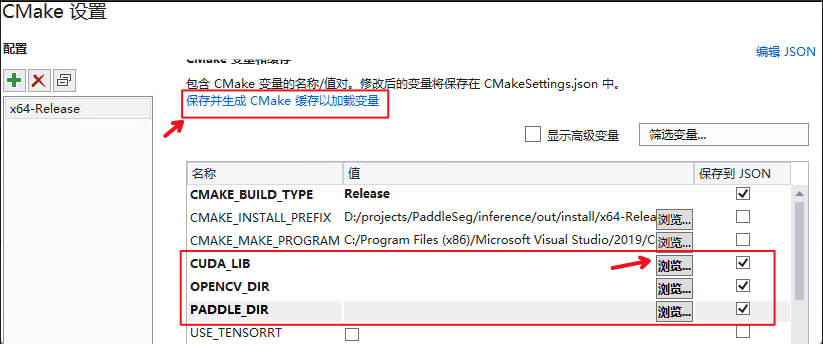
-
2.6 点击
`生成`
->
`全部生成`
编译项目
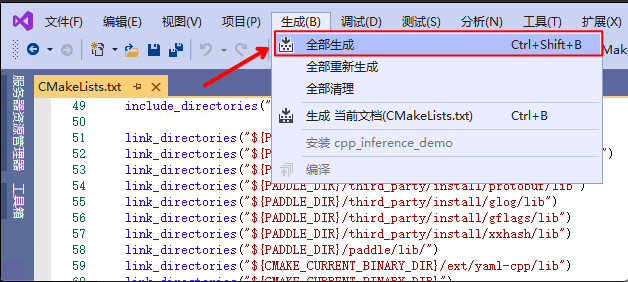
## 3. 运行程序
成功编译后, 产出的可执行文件在项目子目录
`out\build\x64-Release`
目录, 按以下步骤运行代码:
-
打开
`cmd`
切换至该目录
-
运行以下命令传入模型路径与测试视频
```
shell
main.exe ./models/ ./data/test.avi
```
第一个参数即人像分割预测模型的路径,第二个参数即要预测的视频。
运行后,预测结果保存在文件
`result.avi`
中。
contrib/RealTimeHumanSeg/humanseg.cc
0 → 100644
浏览文件 @
41606c13
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
# include "humanseg.h"
# include "humanseg_postprocess.h"
// Normalize the image by (pix - mean) * scale
void
NormalizeImage
(
const
std
::
vector
<
float
>
&
mean
,
const
std
::
vector
<
float
>
&
scale
,
cv
::
Mat
&
im
,
// NOLINT
float
*
input_buffer
)
{
int
height
=
im
.
rows
;
int
width
=
im
.
cols
;
int
stride
=
width
*
height
;
for
(
int
h
=
0
;
h
<
height
;
h
++
)
{
for
(
int
w
=
0
;
w
<
width
;
w
++
)
{
int
base
=
h
*
width
+
w
;
input_buffer
[
base
+
0
*
stride
]
=
(
im
.
at
<
cv
::
Vec3f
>
(
h
,
w
)[
0
]
-
mean
[
0
])
*
scale
[
0
];
input_buffer
[
base
+
1
*
stride
]
=
(
im
.
at
<
cv
::
Vec3f
>
(
h
,
w
)[
1
]
-
mean
[
1
])
*
scale
[
1
];
input_buffer
[
base
+
2
*
stride
]
=
(
im
.
at
<
cv
::
Vec3f
>
(
h
,
w
)[
2
]
-
mean
[
2
])
*
scale
[
2
];
}
}
}
// Load Model and return model predictor
void
LoadModel
(
const
std
::
string
&
model_dir
,
bool
use_gpu
,
std
::
unique_ptr
<
paddle
::
PaddlePredictor
>*
predictor
)
{
// Config the model info
paddle
::
AnalysisConfig
config
;
config
.
SetModel
(
model_dir
);
if
(
use_gpu
)
{
config
.
EnableUseGpu
(
100
,
0
);
}
else
{
config
.
DisableGpu
();
}
config
.
SwitchUseFeedFetchOps
(
false
);
config
.
SwitchSpecifyInputNames
(
true
);
// Memory optimization
config
.
EnableMemoryOptim
();
*
predictor
=
std
::
move
(
CreatePaddlePredictor
(
config
));
}
void
HumanSeg
::
Preprocess
(
const
cv
::
Mat
&
image_mat
)
{
// Clone the image : keep the original mat for postprocess
cv
::
Mat
im
=
image_mat
.
clone
();
cv
::
resize
(
im
,
im
,
cv
::
Size
(
192
,
192
),
0.
f
,
0.
f
,
cv
::
INTER_LINEAR
);
im
.
convertTo
(
im
,
CV_32FC3
,
1.0
);
int
rc
=
im
.
channels
();
int
rh
=
im
.
rows
;
int
rw
=
im
.
cols
;
input_shape_
=
{
1
,
rc
,
rh
,
rw
};
input_data_
.
resize
(
1
*
rc
*
rh
*
rw
);
float
*
buffer
=
input_data_
.
data
();
NormalizeImage
(
mean_
,
scale_
,
im
,
input_data_
.
data
());
}
cv
::
Mat
HumanSeg
::
Postprocess
(
const
cv
::
Mat
&
im
)
{
int
h
=
input_shape_
[
2
];
int
w
=
input_shape_
[
3
];
scoremap_data_
.
resize
(
3
*
h
*
w
*
sizeof
(
float
));
float
*
base
=
output_data_
.
data
()
+
h
*
w
;
for
(
int
i
=
0
;
i
<
h
*
w
;
++
i
)
{
scoremap_data_
[
i
]
=
uchar
(
base
[
i
]
*
255
);
}
cv
::
Mat
im_scoremap
=
cv
::
Mat
(
h
,
w
,
CV_8UC1
);
im_scoremap
.
data
=
scoremap_data_
.
data
();
cv
::
resize
(
im_scoremap
,
im_scoremap
,
cv
::
Size
(
im
.
cols
,
im
.
rows
));
im_scoremap
.
convertTo
(
im_scoremap
,
CV_32FC1
,
1
/
255.0
);
float
*
pblob
=
reinterpret_cast
<
float
*>
(
im_scoremap
.
data
);
int
out_buff_len
=
im
.
cols
*
im
.
rows
*
sizeof
(
uchar
);
segout_data_
.
resize
(
out_buff_len
);
unsigned
char
*
seg_result
=
segout_data_
.
data
();
MergeProcess
(
im
.
data
,
pblob
,
im
.
rows
,
im
.
cols
,
seg_result
);
cv
::
Mat
seg_mat
(
im
.
rows
,
im
.
cols
,
CV_8UC1
,
seg_result
);
cv
::
resize
(
seg_mat
,
seg_mat
,
cv
::
Size
(
im
.
cols
,
im
.
rows
));
cv
::
GaussianBlur
(
seg_mat
,
seg_mat
,
cv
::
Size
(
5
,
5
),
0
,
0
);
float
fg_threshold
=
0.8
;
float
bg_threshold
=
0.4
;
cv
::
Mat
show_seg_mat
;
seg_mat
.
convertTo
(
seg_mat
,
CV_32FC1
,
1
/
255.0
);
ThresholdMask
(
seg_mat
,
fg_threshold
,
bg_threshold
,
show_seg_mat
);
auto
out_im
=
MergeSegMat
(
show_seg_mat
,
im
);
return
out_im
;
}
cv
::
Mat
HumanSeg
::
Predict
(
const
cv
::
Mat
&
im
)
{
// Preprocess image
Preprocess
(
im
);
// Prepare input tensor
auto
input_names
=
predictor_
->
GetInputNames
();
auto
in_tensor
=
predictor_
->
GetInputTensor
(
input_names
[
0
]);
in_tensor
->
Reshape
(
input_shape_
);
in_tensor
->
copy_from_cpu
(
input_data_
.
data
());
// Run predictor
predictor_
->
ZeroCopyRun
();
// Get output tensor
auto
output_names
=
predictor_
->
GetOutputNames
();
auto
out_tensor
=
predictor_
->
GetOutputTensor
(
output_names
[
0
]);
auto
output_shape
=
out_tensor
->
shape
();
// Calculate output length
int
output_size
=
1
;
for
(
int
j
=
0
;
j
<
output_shape
.
size
();
++
j
)
{
output_size
*=
output_shape
[
j
];
}
output_data_
.
resize
(
output_size
);
out_tensor
->
copy_to_cpu
(
output_data_
.
data
());
// Postprocessing result
return
Postprocess
(
im
);
}
contrib/RealTimeHumanSeg/humanseg.h
0 → 100644
浏览文件 @
41606c13
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <string>
#include <vector>
#include <memory>
#include <utility>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/optflow.hpp>
#include "paddle_inference_api.h" // NOLINT
// Load Paddle Inference Model
void
LoadModel
(
const
std
::
string
&
model_dir
,
bool
use_gpu
,
std
::
unique_ptr
<
paddle
::
PaddlePredictor
>*
predictor
);
class
HumanSeg
{
public:
explicit
HumanSeg
(
const
std
::
string
&
model_dir
,
const
std
::
vector
<
float
>&
mean
,
const
std
::
vector
<
float
>&
scale
,
bool
use_gpu
=
false
)
:
mean_
(
mean
),
scale_
(
scale
)
{
LoadModel
(
model_dir
,
use_gpu
,
&
predictor_
);
}
// Run predictor
cv
::
Mat
Predict
(
const
cv
::
Mat
&
im
);
private:
// Preprocess image and copy data to input buffer
void
Preprocess
(
const
cv
::
Mat
&
im
);
// Postprocess result
cv
::
Mat
Postprocess
(
const
cv
::
Mat
&
im
);
std
::
unique_ptr
<
paddle
::
PaddlePredictor
>
predictor_
;
std
::
vector
<
float
>
input_data_
;
std
::
vector
<
int
>
input_shape_
;
std
::
vector
<
float
>
output_data_
;
std
::
vector
<
uchar
>
scoremap_data_
;
std
::
vector
<
uchar
>
segout_data_
;
std
::
vector
<
float
>
mean_
;
std
::
vector
<
float
>
scale_
;
};
contrib/RealTimeHumanSeg/humanseg_postprocess.cc
0 → 100644
浏览文件 @
41606c13
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <iostream>
#include <string>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/optflow.hpp>
#include "humanseg_postprocess.h" // NOLINT
int
HumanSegTrackFuse
(
const
cv
::
Mat
&
track_fg_cfd
,
const
cv
::
Mat
&
dl_fg_cfd
,
const
cv
::
Mat
&
dl_weights
,
const
cv
::
Mat
&
is_track
,
const
float
cfd_diff_thres
,
const
int
patch_size
,
cv
::
Mat
cur_fg_cfd
)
{
float
*
cur_fg_cfd_ptr
=
reinterpret_cast
<
float
*>
(
cur_fg_cfd
.
data
);
float
*
dl_fg_cfd_ptr
=
reinterpret_cast
<
float
*>
(
dl_fg_cfd
.
data
);
float
*
track_fg_cfd_ptr
=
reinterpret_cast
<
float
*>
(
track_fg_cfd
.
data
);
float
*
dl_weights_ptr
=
reinterpret_cast
<
float
*>
(
dl_weights
.
data
);
uchar
*
is_track_ptr
=
reinterpret_cast
<
uchar
*>
(
is_track
.
data
);
int
y_offset
=
0
;
int
ptr_offset
=
0
;
int
h
=
track_fg_cfd
.
rows
;
int
w
=
track_fg_cfd
.
cols
;
float
dl_fg_score
=
0.0
;
float
track_fg_score
=
0.0
;
for
(
int
y
=
0
;
y
<
h
;
++
y
)
{
for
(
int
x
=
0
;
x
<
w
;
++
x
)
{
dl_fg_score
=
dl_fg_cfd_ptr
[
ptr_offset
];
if
(
is_track_ptr
[
ptr_offset
]
>
0
)
{
track_fg_score
=
track_fg_cfd_ptr
[
ptr_offset
];
if
(
dl_fg_score
>
0.9
||
dl_fg_score
<
0.1
)
{
if
(
dl_weights_ptr
[
ptr_offset
]
<=
0.10
)
{
cur_fg_cfd_ptr
[
ptr_offset
]
=
dl_fg_score
*
0.3
+
track_fg_score
*
0.7
;
}
else
{
cur_fg_cfd_ptr
[
ptr_offset
]
=
dl_fg_score
*
0.4
+
track_fg_score
*
0.6
;
}
}
else
{
cur_fg_cfd_ptr
[
ptr_offset
]
=
dl_fg_score
*
dl_weights_ptr
[
ptr_offset
]
+
track_fg_score
*
(
1
-
dl_weights_ptr
[
ptr_offset
]);
}
}
else
{
cur_fg_cfd_ptr
[
ptr_offset
]
=
dl_fg_score
;
}
++
ptr_offset
;
}
y_offset
+=
w
;
ptr_offset
=
y_offset
;
}
return
0
;
}
int
HumanSegTracking
(
const
cv
::
Mat
&
prev_gray
,
const
cv
::
Mat
&
cur_gray
,
const
cv
::
Mat
&
prev_fg_cfd
,
int
patch_size
,
cv
::
Mat
track_fg_cfd
,
cv
::
Mat
is_track
,
cv
::
Mat
dl_weights
,
cv
::
Ptr
<
cv
::
optflow
::
DISOpticalFlow
>
disflow
)
{
cv
::
Mat
flow_fw
;
disflow
->
calc
(
prev_gray
,
cur_gray
,
flow_fw
);
cv
::
Mat
flow_bw
;
disflow
->
calc
(
cur_gray
,
prev_gray
,
flow_bw
);
float
double_check_thres
=
8
;
cv
::
Point2f
fxy_fw
;
int
dy_fw
=
0
;
int
dx_fw
=
0
;
cv
::
Point2f
fxy_bw
;
int
dy_bw
=
0
;
int
dx_bw
=
0
;
float
*
prev_fg_cfd_ptr
=
reinterpret_cast
<
float
*>
(
prev_fg_cfd
.
data
);
float
*
track_fg_cfd_ptr
=
reinterpret_cast
<
float
*>
(
track_fg_cfd
.
data
);
float
*
dl_weights_ptr
=
reinterpret_cast
<
float
*>
(
dl_weights
.
data
);
uchar
*
is_track_ptr
=
reinterpret_cast
<
uchar
*>
(
is_track
.
data
);
int
prev_y_offset
=
0
;
int
prev_ptr_offset
=
0
;
int
cur_ptr_offset
=
0
;
float
*
flow_fw_ptr
=
reinterpret_cast
<
float
*>
(
flow_fw
.
data
);
float
roundy_fw
=
0.0
;
float
roundx_fw
=
0.0
;
float
roundy_bw
=
0.0
;
float
roundx_bw
=
0.0
;
int
h
=
prev_fg_cfd
.
rows
;
int
w
=
prev_fg_cfd
.
cols
;
for
(
int
r
=
0
;
r
<
h
;
++
r
)
{
for
(
int
c
=
0
;
c
<
w
;
++
c
)
{
++
prev_ptr_offset
;
fxy_fw
=
flow_fw
.
ptr
<
cv
::
Point2f
>
(
r
)[
c
];
roundy_fw
=
fxy_fw
.
y
>=
0
?
0.5
:
-
0.5
;
roundx_fw
=
fxy_fw
.
x
>=
0
?
0.5
:
-
0.5
;
dy_fw
=
static_cast
<
int
>
(
fxy_fw
.
y
+
roundy_fw
);
dx_fw
=
static_cast
<
int
>
(
fxy_fw
.
x
+
roundx_fw
);
int
cur_x
=
c
+
dx_fw
;
int
cur_y
=
r
+
dy_fw
;
if
(
cur_x
<
0
||
cur_x
>=
h
||
cur_y
<
0
||
cur_y
>=
w
)
{
continue
;
}
fxy_bw
=
flow_bw
.
ptr
<
cv
::
Point2f
>
(
cur_y
)[
cur_x
];
roundy_bw
=
fxy_bw
.
y
>=
0
?
0.5
:
-
0.5
;
roundx_bw
=
fxy_bw
.
x
>=
0
?
0.5
:
-
0.5
;
dy_bw
=
static_cast
<
int
>
(
fxy_bw
.
y
+
roundy_bw
);
dx_bw
=
static_cast
<
int
>
(
fxy_bw
.
x
+
roundx_bw
);
auto
total
=
(
dy_fw
+
dy_bw
)
*
(
dy_fw
+
dy_bw
)
+
(
dx_fw
+
dx_bw
)
*
(
dx_fw
+
dx_bw
);
if
(
total
>=
double_check_thres
)
{
continue
;
}
cur_ptr_offset
=
cur_y
*
w
+
cur_x
;
if
(
abs
(
dy_fw
)
<=
0
&&
abs
(
dx_fw
)
<=
0
&&
abs
(
dy_bw
)
<=
0
&&
abs
(
dx_bw
)
<=
0
)
{
dl_weights_ptr
[
cur_ptr_offset
]
=
0.05
;
}
is_track_ptr
[
cur_ptr_offset
]
=
1
;
track_fg_cfd_ptr
[
cur_ptr_offset
]
=
prev_fg_cfd_ptr
[
prev_ptr_offset
];
}
prev_y_offset
+=
w
;
prev_ptr_offset
=
prev_y_offset
-
1
;
}
return
0
;
}
int
MergeProcess
(
const
uchar
*
im_buff
,
const
float
*
scoremap_buff
,
const
int
height
,
const
int
width
,
uchar
*
result_buff
)
{
cv
::
Mat
prev_fg_cfd
;
cv
::
Mat
cur_fg_cfd
;
cv
::
Mat
cur_fg_mask
;
cv
::
Mat
track_fg_cfd
;
cv
::
Mat
prev_gray
;
cv
::
Mat
cur_gray
;
cv
::
Mat
bgr_temp
;
cv
::
Mat
is_track
;
cv
::
Mat
static_roi
;
cv
::
Mat
weights
;
cv
::
Ptr
<
cv
::
optflow
::
DISOpticalFlow
>
disflow
=
cv
::
optflow
::
createOptFlow_DIS
(
cv
::
optflow
::
DISOpticalFlow
::
PRESET_ULTRAFAST
);
bool
is_init
=
false
;
const
float
*
cfd_ptr
=
scoremap_buff
;
if
(
!
is_init
)
{
is_init
=
true
;
cur_fg_cfd
=
cv
::
Mat
(
height
,
width
,
CV_32FC1
,
cv
::
Scalar
::
all
(
0
));
memcpy
(
cur_fg_cfd
.
data
,
cfd_ptr
,
height
*
width
*
sizeof
(
float
));
cur_fg_mask
=
cv
::
Mat
(
height
,
width
,
CV_8UC1
,
cv
::
Scalar
::
all
(
0
));
if
(
height
<=
64
||
width
<=
64
)
{
disflow
->
setFinestScale
(
1
);
}
else
if
(
height
<=
160
||
width
<=
160
)
{
disflow
->
setFinestScale
(
2
);
}
else
{
disflow
->
setFinestScale
(
3
);
}
is_track
=
cv
::
Mat
(
height
,
width
,
CV_8UC1
,
cv
::
Scalar
::
all
(
0
));
static_roi
=
cv
::
Mat
(
height
,
width
,
CV_8UC1
,
cv
::
Scalar
::
all
(
0
));
track_fg_cfd
=
cv
::
Mat
(
height
,
width
,
CV_32FC1
,
cv
::
Scalar
::
all
(
0
));
bgr_temp
=
cv
::
Mat
(
height
,
width
,
CV_8UC3
);
memcpy
(
bgr_temp
.
data
,
im_buff
,
height
*
width
*
3
*
sizeof
(
uchar
));
cv
::
cvtColor
(
bgr_temp
,
cur_gray
,
cv
::
COLOR_BGR2GRAY
);
weights
=
cv
::
Mat
(
height
,
width
,
CV_32FC1
,
cv
::
Scalar
::
all
(
0.30
));
}
else
{
memcpy
(
cur_fg_cfd
.
data
,
cfd_ptr
,
height
*
width
*
sizeof
(
float
));
memcpy
(
bgr_temp
.
data
,
im_buff
,
height
*
width
*
3
*
sizeof
(
uchar
));
cv
::
cvtColor
(
bgr_temp
,
cur_gray
,
cv
::
COLOR_BGR2GRAY
);
memset
(
is_track
.
data
,
0
,
height
*
width
*
sizeof
(
uchar
));
memset
(
static_roi
.
data
,
0
,
height
*
width
*
sizeof
(
uchar
));
weights
=
cv
::
Mat
(
height
,
width
,
CV_32FC1
,
cv
::
Scalar
::
all
(
0.30
));
HumanSegTracking
(
prev_gray
,
cur_gray
,
prev_fg_cfd
,
0
,
track_fg_cfd
,
is_track
,
weights
,
disflow
);
HumanSegTrackFuse
(
track_fg_cfd
,
cur_fg_cfd
,
weights
,
is_track
,
1.1
,
0
,
cur_fg_cfd
);
}
int
ksize
=
3
;
cv
::
GaussianBlur
(
cur_fg_cfd
,
cur_fg_cfd
,
cv
::
Size
(
ksize
,
ksize
),
0
,
0
);
prev_fg_cfd
=
cur_fg_cfd
.
clone
();
prev_gray
=
cur_gray
.
clone
();
cur_fg_cfd
.
convertTo
(
cur_fg_mask
,
CV_8UC1
,
255
);
memcpy
(
result_buff
,
cur_fg_mask
.
data
,
height
*
width
);
return
0
;
}
cv
::
Mat
MergeSegMat
(
const
cv
::
Mat
&
seg_mat
,
const
cv
::
Mat
&
ori_frame
)
{
cv
::
Mat
return_frame
;
cv
::
resize
(
ori_frame
,
return_frame
,
cv
::
Size
(
ori_frame
.
cols
,
ori_frame
.
rows
));
for
(
int
i
=
0
;
i
<
ori_frame
.
rows
;
i
++
)
{
for
(
int
j
=
0
;
j
<
ori_frame
.
cols
;
j
++
)
{
float
score
=
seg_mat
.
at
<
uchar
>
(
i
,
j
)
/
255.0
;
if
(
score
>
0.1
)
{
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)[
2
]
=
static_cast
<
int
>
((
1
-
score
)
*
255
+
score
*
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)[
2
]);
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)[
1
]
=
static_cast
<
int
>
((
1
-
score
)
*
255
+
score
*
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)[
1
]);
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)[
0
]
=
static_cast
<
int
>
((
1
-
score
)
*
255
+
score
*
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)[
0
]);
}
else
{
return_frame
.
at
<
cv
::
Vec3b
>
(
i
,
j
)
=
{
255
,
255
,
255
};
}
}
}
return
return_frame
;
}
int
ThresholdMask
(
const
cv
::
Mat
&
fg_cfd
,
const
float
fg_thres
,
const
float
bg_thres
,
cv
::
Mat
fg_mask
)
{
if
(
fg_cfd
.
type
()
!=
CV_32FC1
)
{
printf
(
"ThresholdMask: type is not CV_32FC1.
\n
"
);
return
-
1
;
}
if
(
!
(
fg_mask
.
type
()
==
CV_8UC1
&&
fg_mask
.
rows
==
fg_cfd
.
rows
&&
fg_mask
.
cols
==
fg_cfd
.
cols
))
{
fg_mask
=
cv
::
Mat
(
fg_cfd
.
rows
,
fg_cfd
.
cols
,
CV_8UC1
,
cv
::
Scalar
::
all
(
0
));
}
for
(
int
r
=
0
;
r
<
fg_cfd
.
rows
;
++
r
)
{
for
(
int
c
=
0
;
c
<
fg_cfd
.
cols
;
++
c
)
{
float
score
=
fg_cfd
.
at
<
float
>
(
r
,
c
);
if
(
score
<
bg_thres
)
{
fg_mask
.
at
<
uchar
>
(
r
,
c
)
=
0
;
}
else
if
(
score
>
fg_thres
)
{
fg_mask
.
at
<
uchar
>
(
r
,
c
)
=
255
;
}
else
{
fg_mask
.
at
<
uchar
>
(
r
,
c
)
=
static_cast
<
int
>
(
(
score
-
bg_thres
)
/
(
fg_thres
-
bg_thres
)
*
255
);
}
}
}
return
0
;
}
contrib/RealTimeHumanSeg/humanseg_postprocess.h
0 → 100644
浏览文件 @
41606c13
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <opencv2/core/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/optflow.hpp>
int
ThresholdMask
(
const
cv
::
Mat
&
fg_cfd
,
const
float
fg_thres
,
const
float
bg_thres
,
cv
::
Mat
fg_mask
);
cv
::
Mat
MergeSegMat
(
const
cv
::
Mat
&
seg_mat
,
const
cv
::
Mat
&
ori_frame
);
int
MergeProcess
(
const
uchar
*
im_buff
,
const
float
*
im_scoremap_buff
,
const
int
height
,
const
int
width
,
uchar
*
result_buff
);
contrib/RealTimeHumanSeg/linux_build.sh
0 → 100644
浏览文件 @
41606c13
OPENCV_URL
=
https://paddleseg.bj.bcebos.com/deploy/deps/opencv341.tar.bz2
if
[
!
-d
"./deps/opencv341"
]
;
then
mkdir
-p
deps
cd
deps
wget
-c
${
OPENCV_URL
}
tar
xvfj opencv341.tar.bz2
rm
-rf
opencv341.tar.bz2
cd
..
fi
WITH_GPU
=
OFF
PADDLE_DIR
=
/root/projects/deps/fluid_inference/
CUDA_LIB
=
/usr/local/cuda-10.0/lib64/
CUDNN_LIB
=
/usr/local/cuda-10.0/lib64/
OPENCV_DIR
=
$(
pwd
)
/deps/opencv341/
rm
-rf
build
mkdir
-p
build
cd
build
cmake ..
\
-DWITH_GPU
=
${
WITH_GPU
}
\
-DPADDLE_DIR
=
${
PADDLE_DIR
}
\
-DCUDA_LIB
=
${
CUDA_LIB
}
\
-DCUDNN_LIB
=
${
CUDNN_LIB
}
\
-DOPENCV_DIR
=
${
OPENCV_DIR
}
\
-DWITH_STATIC_LIB
=
OFF
make clean
make
-j12
contrib/RealTimeHumanSeg/main.cc
0 → 100644
浏览文件 @
41606c13
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <iostream>
#include <string>
#include "humanseg.h" // NOLINT
#include "humanseg_postprocess.h" // NOLINT
// Do predicting on a video file
int
VideoPredict
(
const
std
::
string
&
video_path
,
HumanSeg
&
seg
)
{
cv
::
VideoCapture
capture
;
capture
.
open
(
video_path
.
c_str
());
if
(
!
capture
.
isOpened
())
{
printf
(
"can not open video : %s
\n
"
,
video_path
.
c_str
());
return
-
1
;
}
int
video_width
=
static_cast
<
int
>
(
capture
.
get
(
CV_CAP_PROP_FRAME_WIDTH
));
int
video_height
=
static_cast
<
int
>
(
capture
.
get
(
CV_CAP_PROP_FRAME_HEIGHT
));
cv
::
VideoWriter
video_out
;
std
::
string
video_out_path
=
"result.avi"
;
video_out
.
open
(
video_out_path
.
c_str
(),
CV_FOURCC
(
'M'
,
'J'
,
'P'
,
'G'
),
30.0
,
cv
::
Size
(
video_width
,
video_height
),
true
);
if
(
!
video_out
.
isOpened
())
{
printf
(
"create video writer failed!
\n
"
);
return
-
1
;
}
cv
::
Mat
frame
;
while
(
capture
.
read
(
frame
))
{
cv
::
Mat
out_im
=
seg
.
Predict
(
frame
);
video_out
.
write
(
out_im
);
}
capture
.
release
();
return
0
;
}
// Do predicting on a image file
int
ImagePredict
(
const
std
::
string
&
image_path
,
HumanSeg
&
seg
)
{
cv
::
Mat
img
=
imread
(
image_path
,
cv
::
IMREAD_COLOR
);
cv
::
Mat
out_im
=
seg
.
Predict
(
img
);
imwrite
(
"result.jpeg"
,
out_im
);
return
0
;
}
int
main
(
int
argc
,
char
*
argv
[])
{
if
(
argc
<
3
||
argc
>
4
)
{
std
::
cout
<<
"Usage:"
<<
"./humanseg ./models/ ./data/test.avi"
<<
std
::
endl
;
return
-
1
;
}
bool
use_gpu
=
(
argc
==
4
?
std
::
stoi
(
argv
[
3
])
:
false
);
auto
model_dir
=
std
::
string
(
argv
[
1
]);
auto
input_path
=
std
::
string
(
argv
[
2
]);
// Init Model
std
::
vector
<
float
>
means
=
{
104.008
,
116.669
,
122.675
};
std
::
vector
<
float
>
scale
=
{
1.000
,
1.000
,
1.000
};
HumanSeg
seg
(
model_dir
,
means
,
scale
,
use_gpu
);
// Call ImagePredict while input_path is a image file path
// The output will be saved as result.jpeg
ImagePredict
(
input_path
,
seg
);
// Call VideoPredict while input_path is a video file path
// The output will be saved as result.avi
// VideoPredict(input_path, seg);
return
0
;
}
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录