Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleRec
提交
daf4f3c0
P
PaddleRec
项目概览
PaddlePaddle
/
PaddleRec
通知
68
Star
12
Fork
5
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
27
列表
看板
标记
里程碑
合并请求
10
Wiki
1
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleRec
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
27
Issue
27
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
1
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
“2d45b245384f0f6e71695329c384c33ae37fb44a”上不存在“develop/doc/dev/new_layer_en.html”
提交
daf4f3c0
编写于
8月 13, 2020
作者:
M
malin10
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add w2v readme
上级
1a2cafdc
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
220 addition
and
0 deletion
+220
-0
models/recall/word2vec/README.md
models/recall/word2vec/README.md
+220
-0
未找到文件。
models/recall/word2vec/README.md
0 → 100644
浏览文件 @
daf4f3c0
# GNN
以下是本例的简要目录结构及说明:
```
├── data #样例数据
├── train
├── convert_sample.txt
├── test
├── sample.txt
├── dict
├── word_count_dict.txt
├── word_id_dict.txt
├── preprocess.py # 数据预处理文件
├── __init__.py
├── README.md # 文档
├── model.py #模型文件
├── config.yaml #配置文件
├── data_prepare.sh #一键数据处理脚本
├── w2v_reader.py #训练数据reader
├── w2v_evaluate_reader.py # 预测数据reader
```
注:在阅读该示例前,建议您先了解以下内容:
[
paddlerec入门教程
](
https://github.com/PaddlePaddle/PaddleRec/blob/master/README.md
)
---
## 内容
-
[
模型简介
](
#模型简介
)
-
[
数据准备
](
#数据准备
)
-
[
运行环境
](
#运行环境
)
-
[
快速开始
](
#快速开始
)
-
[
论文复现
](
#论文复现
)
-
[
进阶使用
](
#进阶使用
)
-
[
FAQ
](
#FAQ
)
## 模型简介
本例实现了skip-gram模式的word2vector模型,如下图中的skip-gram部分:
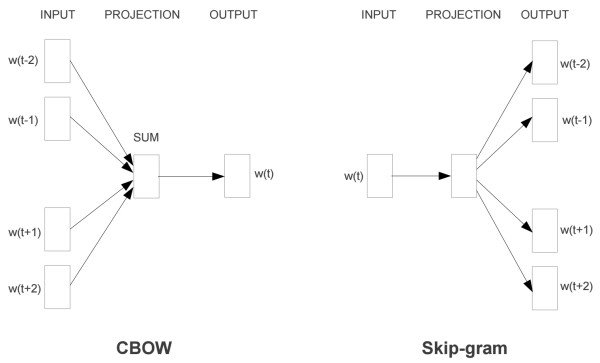
以每一个词为中心词X,然后在窗口内和临近的词Y组成样本对(X,Y)用于网络训练。在实际训练过程中还会根据自定义的负采样率生成负样本来加强训练的效果
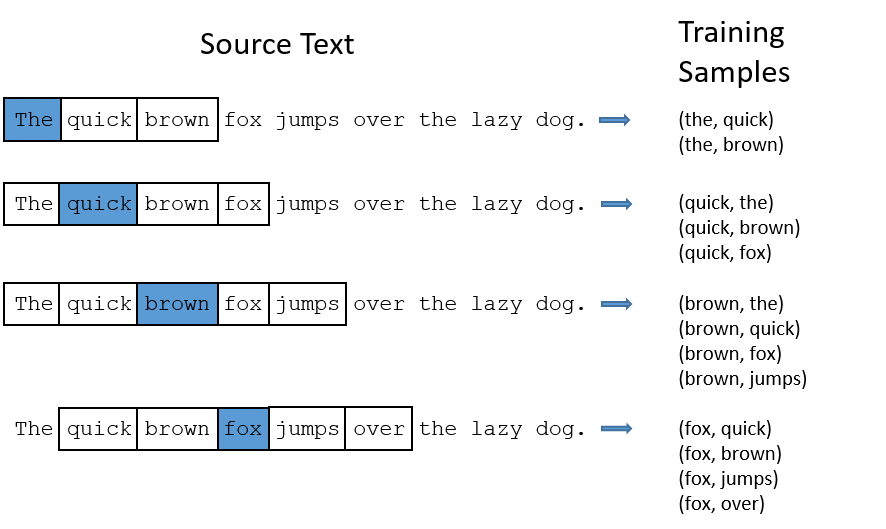
具体的训练思路如下:
推荐用户参考
[
IPython Notebook demo
](
https://aistudio.baidu.com/aistudio/projectDetail/124377
)
教程获取更详细的信息。
本模型配置默认使用demo数据集,若进行精度验证,请参考
[
论文复现
](
#论文复现
)
部分。
本项目支持功能
训练:单机CPU、本地模拟参数服务器训练、增量训练,配置请参考
[
启动训练
](
https://github.com/PaddlePaddle/PaddleRec/blob/master/doc/train.md
)
预测:单机CPU;配置请参考
[
PaddleRec 离线预测
](
https://github.com/PaddlePaddle/PaddleRec/blob/master/doc/predict.md
)
## 数据处理
本示例中数据处理共包含三步:
-
Step1: 数据下载。
```
# 全量训练集
mkdir raw_data
wget --no-check-certificate https://paddlerec.bj.bcebos.com/word2vec/1-billion-word-language-modeling-benchmark-r13output.tar
tar xvf 1-billion-word-language-modeling-benchmark-r13output.tar
mv 1-billion-word-language-modeling-benchmark-r13output/training-monolingual.tokenized.shuffled/ raw_data/
# 测试集
wget --no-check-certificate https://paddlerec.bj.bcebos.com/word2vec/test_dir.tar
tar xzvf test_dir.tar -C raw_data
```
-
Step2: 训练据预处理。包含三步,第一步,根据英文语料生成词典,中文语料可以通过修改text_strip方法自定义处理方法。
```
python preprocess.py --build_dict --build_dict_corpus_dir raw_data/training-monolingual.tokenized.shuffled --dict_path raw_data/word_count_dict.txt
```
得到的词典格式为词
<空格>
词频,低频词用'UNK'表示,如下所示:
```
the 1061396
of 593677
and 416629
one 411764
in 372201
a 325873
<UNK> 324608
to 316376
zero 264975
nine 250430
```
第二步,根据词典将文本转成id, 同时进行downsample,按照概率过滤常见词, 同时生成word和id映射的文件,文件名为词典+"word_to_id"。
```
python preprocess.py --filter_corpus --dict_path raw_data/word_count_dict.txt --input_corpus_dir raw_data/training-monolingual.tokenized.shuffled --output_corpus_dir raw_data/convert_text8 --min_count 5 --downsample 0.001
```
第三步,为更好地利用多线程进行训练加速,我们需要将训练文件分成多个子文件,默认拆分成1024个文件,文件保存在data/train目录下。
```
rm -rf data/train/*
python preprocess.py --data_resplit --input_corpus_dir=raw_data/convert_text8 --output_corpus_dir=data/train
```
-
Step3: 数据整理。 将训练文件统一放在data/train目录下,测试文件统一放在data/test目录下,词典相关文件放在data/dict目录下。
```
rm -rf data/test/*
mv raw_data/data/test_dir/* data/test/
mv raw_data/word_count_dict.txt data/dict/
mv raw_data/word_id_dict.txt data/dict/
rm -rf raw_data
```
方便起见, 我们提供了一键式数据处理脚本:
```
sh data_prepare.sh
```
## 运行环境
PaddlePaddle>=1.7.2
python 2.7/3.5/3.6/3.7
PaddleRec >=0.1
os : windows/linux/macos
## 快速开始
### 单机训练
CPU环境
在config.yaml文件中设置好设备,epochs等。
```
# select runner by name
mode: [single_cpu_train, single_cpu_infer]
# config of each runner.
# runner is a kind of paddle training class, which wraps the train/infer process.
runner:
- name: single_cpu_train
class: train
# num of epochs
epochs: 5
# device to run training or infer
device: cpu
save_checkpoint_interval: 1 # save model interval of epochs
save_inference_interval: 1 # save inference
save_checkpoint_path: "increment_w2v" # save checkpoint path
save_inference_path: "inference_w2v" # save inference path
save_inference_feed_varnames: [] # feed vars of save inference
save_inference_fetch_varnames: [] # fetch vars of save inference
init_model_path: "" # load model path
print_interval: 1
phases: [phase1]
```
### 单机预测
CPU环境
在config.yaml文件中设置好epochs、device等参数。
```
- name: single_cpu_infer
class: infer
# device to run training or infer
device: cpu
init_model_path: "increment_w2v" # load model path
print_interval: 1
phases: [phase2]
```
### 运行
```
python -m paddlerec.run -m paddlerec.models.recall.w2v
```
### 结果展示
样例数据训练结果展示:
```
Running SingleStartup.
Running SingleRunner.
W0813 11:36:16.129736 43843 build_strategy.cc:170] fusion_group is not enabled for Windows/MacOS now, and only effective when running with CUDA GPU.
batch: 1, LOSS: [3.618 3.684 3.698 3.653 3.736]
batch: 2, LOSS: [3.394 3.453 3.605 3.487 3.553]
batch: 3, LOSS: [3.411 3.402 3.444 3.387 3.357]
batch: 4, LOSS: [3.557 3.196 3.304 3.209 3.299]
batch: 5, LOSS: [3.217 3.141 3.168 3.114 3.315]
batch: 6, LOSS: [3.342 3.219 3.124 3.207 3.282]
batch: 7, LOSS: [3.19 3.207 3.136 3.322 3.164]
epoch 0 done, use time: 0.119026899338, global metrics: LOSS=[3.19 3.207 3.136 3.322 3.164]
...
epoch 4 done, use time: 0.097608089447, global metrics: LOSS=[2.734 2.66 2.763 2.804 2.809]
```
样例数据预测结果展示:
```
Running SingleInferStartup.
Running SingleInferRunner.
load persistables from increment_w2v/4
batch: 1, acc: [1.]
batch: 2, acc: [1.]
batch: 3, acc: [1.]
Infer phase2 of epoch 4 done, use time: 4.89376211166, global metrics: acc=[1.]
...
Infer phase2 of epoch 3 done, use time: 4.43099021912, global metrics: acc=[1.]
```
## 论文复现
用原论文的完整数据复现论文效果需要在config.yaml修改超参:
-
batch_size: 修改config.yaml中dataset_train数据集的batch_size为100。
-
epochs: 修改config.yaml中runner的epochs为5。
使用cpu训练 5轮 测试Recall@20:0.540
修改后运行方案:修改config.yaml中的'workspace'为config.yaml的目录位置,执行
```
python -m paddlerec.run -m /home/your/dir/config.yaml #调试模式 直接指定本地config的绝对路径
```
## 进阶使用
## FAQ
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录