Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleRec
提交
c685a493
P
PaddleRec
项目概览
PaddlePaddle
/
PaddleRec
通知
68
Star
12
Fork
5
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
27
列表
看板
标记
里程碑
合并请求
10
Wiki
1
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleRec
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
27
Issue
27
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
1
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
c685a493
编写于
5月 18, 2020
作者:
C
chengmo
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'doc_v1' into 'develop'
Doc v1 See merge request
!54
上级
e57ed516
f2ed7fd3
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
78 addition
and
361 deletion
+78
-361
README.md
README.md
+56
-32
core/trainers/tdm_cluster_trainer.py
core/trainers/tdm_cluster_trainer.py
+8
-8
core/trainers/tdm_single_trainer.py
core/trainers/tdm_single_trainer.py
+10
-10
doc/distributed_train.md
doc/distributed_train.md
+1
-4
doc/imgs/overview.png
doc/imgs/overview.png
+0
-0
doc/ps_background.md
doc/ps_background.md
+3
-136
readme.md
readme.md
+0
-171
未找到文件。
README.md
浏览文件 @
c685a493
...
@@ -78,57 +78,82 @@
...
@@ -78,57 +78,82 @@
```
bash
```
bash
# 使用CPU进行单机训练
# 使用CPU进行单机训练
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-d
cpu
-e
single
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
# 使用GPU进行单机训练
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-d
gpu
-e
single
```
```
###
# 本地模拟分布式训练
###
启动内置模型的自定配置
若您复用内置模型,对
**yaml**
配置文件进行了修改,如更改超参,重新配置数据后,可以直接使用paddlerec运行该yaml文件。
我们以dnn模型为例,在paddlerec代码目录下
```
bash
```
bash
# 使用CPU资源进行本地模拟分布式训练
cd
paddlerec
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-e
local_cluster
```
```
#### 集群分布式训练
修改了dnn模型
`models/rank/dnn/config.yaml`
的配置后,运行
`dnn`
模型:
```
bash
# 使用自定配置进行训练
python
-m
paddlerec.run
-m
./models/rank/dnn/config.yaml
```
### 分布式训练
分布式训练需要配置
`config.yaml`
,加入或修改
`engine`
选项为
`cluster`
或
`local_cluster`
,以进行分布式训练,或本地模拟分布式训练。
#### 本地模拟分布式训练
我们以dnn模型为例,在paddlerec代码目录下,修改dnn模型的
`config.yaml`
文件:
```
yaml
train
:
#engine: single
engine
:
local_cluster
```
然后启动paddlerec训练:
```
bash
```
bash
#
配置好 mpi/k8s/paddlecloud集群环境后
#
进行本地模拟分布式训练
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-e
cluster
python
-m
paddlerec.run
-m
./models/rank/dnn/config.yaml
```
```
###
启动内置模型的自定配置
###
# 集群分布式训练
若您复用内置模型,对
**yaml**
配置文件进行了修改,如更改超参,重新配置数据后,可以直接使用paddlerec运行该yaml文件。
我们以dnn模型为例,在paddlerec代码目录下,首先修改dnn模型
`config.yaml`
文件:
```
yaml
train
:
#engine: single
engine
:
cluster
```
再添加分布式启动配置文件
`backend.yaml`
,具体配置规则在
[
分布式训练
](
doc/distributed_train.md
)
教程中介绍。最后启动paddlerec训练:
我们以dnn模型为例,在paddlerec代码目录下,修改了dnn模型
`config.yaml`
的配置后,运行
`dnn`
模型:
```
bash
```
bash
python
-m
paddlerec.run
-m
./models/rank/dnn/config.yaml
-e
single
# 配置好 mpi/k8s/paddlecloud集群环境后
python
-m
paddlerec.run
-m
./models/rank/dnn/config.yaml
-b
backend.yaml
```
```
<h2
align=
"center"
>
支持模型列表
</h2>
<h2
align=
"center"
>
支持模型列表
</h2>
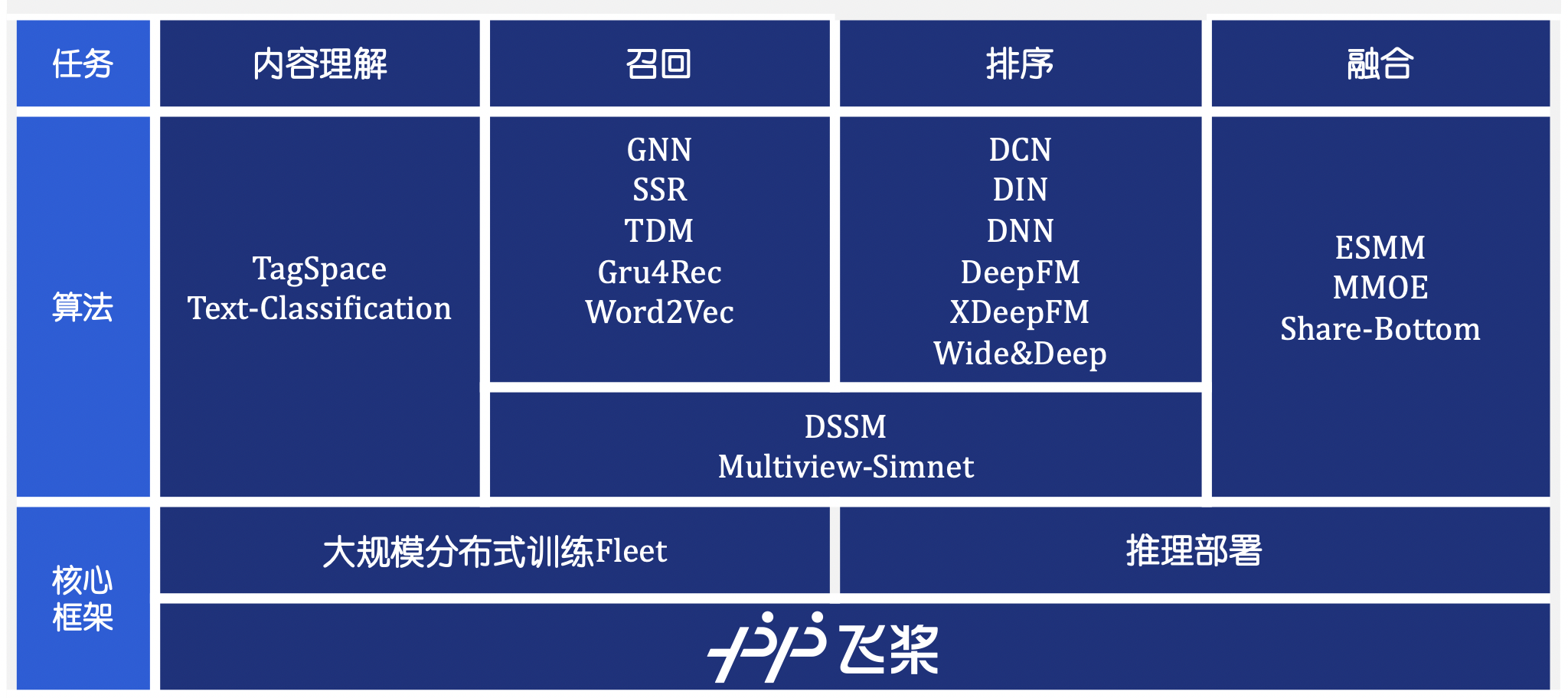
| 方向 |
模型
| 单机CPU训练 | 单机GPU训练 | 分布式CPU训练 |
| 方向 |
模型
| 单机CPU训练 | 单机GPU训练 | 分布式CPU训练 |
| :------: | :-----------------------------------------------------------------------
-----
: | :---------: | :---------: | :-----------: |
| :------: | :-----------------------------------------------------------------------: | :---------: | :---------: | :-----------: |
| 内容理解 |
[
Text-Classifcation
](
models/contentunderstanding/classification/model.py
)
| ✓ | x | ✓ |
| 内容理解 |
[
Text-Classifcation
](
models/contentunderstanding/classification/model.py
)
| ✓ | x | ✓ |
| 内容理解 |
[
TagSpace
](
models/contentunderstanding/tagspace/model.py
)
| ✓ | x | ✓ |
| 内容理解 |
[
TagSpace
](
models/contentunderstanding/tagspace/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
TDM
](
models/treebased/tdm/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
TDM
](
models/treebased/tdm/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
Word2Vec
](
models/recall/word2vec/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
Word2Vec
](
models/recall/word2vec/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
SSR
](
models/recall/ssr/model.py
)
| ✓ | ✓ | ✓ |
| 召回 |
[
SSR
](
models/recall/ssr/model.py
)
| ✓ | ✓ | ✓ |
| 召回 |
[
Gru4Rec
](
models/recall/gru4rec/model.py
)
| ✓ | ✓ | ✓ |
| 召回 |
[
Gru4Rec
](
models/recall/gru4rec/model.py
)
| ✓ | ✓ | ✓ |
| 排序 |
[
Dnn
](
models/rank/dnn/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
Dnn
](
models/rank/dnn/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
DeepFM
](
models/rank/deepfm/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
DeepFM
](
models/rank/deepfm/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
xDeepFM
](
models/rank/xdeepfm/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
xDeepFM
](
models/rank/xdeepfm/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
DIN
](
models/rank/din/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
DIN
](
models/rank/din/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
Wide&Deep
](
models/rank/wide_deep/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
Wide&Deep
](
models/rank/wide_deep/model.py
)
| ✓ | x | ✓ |
| 多任务 |
[
ESMM
](
models/multitask/esmm/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
ESMM
](
models/multitask/esmm/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
MMOE
](
models/multitask/mmoe/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
MMOE
](
models/multitask/mmoe/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
ShareBottom
](
models/multitask/share-bottom/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
ShareBottom
](
models/multitask/share-bottom/model.py
)
| ✓ | ✓ | ✓ |
| 匹配 |
[
DSSM
](
models/match/dssm/model.py
)
| ✓ | x | ✓ |
| 匹配 |
[
DSSM
](
models/match/dssm/model.py
)
| ✓ | x | ✓ |
| 匹配 |
[
MultiView-Simnet
](
models/match/multiview-simnet/model.py
)
| ✓ | x | ✓ |
| 匹配 |
[
MultiView-Simnet
](
models/match/multiview-simnet/model.py
)
| ✓ | x | ✓ |
...
@@ -168,4 +193,3 @@ python -m paddlerec.run -m ./models/rank/dnn/config.yaml -e single
...
@@ -168,4 +193,3 @@ python -m paddlerec.run -m ./models/rank/dnn/config.yaml -e single
### 许可证书
### 许可证书
本项目的发布受
[
Apache 2.0 license
](
LICENSE
)
许可认证。
本项目的发布受
[
Apache 2.0 license
](
LICENSE
)
许可认证。
>>>>>>> d7171ec5daa477584de89ea7e57a382045e12311
core/trainers/tdm_cluster_trainer.py
浏览文件 @
c685a493
...
@@ -67,7 +67,7 @@ class TDMClusterTrainer(ClusterTrainer):
...
@@ -67,7 +67,7 @@ class TDMClusterTrainer(ClusterTrainer):
# covert tree to tensor, set it into Fluid's variable.
# covert tree to tensor, set it into Fluid's variable.
for
param_name
in
special_param
:
for
param_name
in
special_param
:
param_t
=
fluid
.
global_scope
().
find_var
(
param_name
).
get_tensor
()
param_t
=
fluid
.
global_scope
().
find_var
(
param_name
).
get_tensor
()
param_array
=
self
.
tdm_prepare
(
param_name
)
param_array
=
self
.
_
tdm_prepare
(
param_name
)
param_t
.
set
(
param_array
.
astype
(
'int32'
),
self
.
_place
)
param_t
.
set
(
param_array
.
astype
(
'int32'
),
self
.
_place
)
if
save_init_model
:
if
save_init_model
:
...
@@ -78,27 +78,27 @@ class TDMClusterTrainer(ClusterTrainer):
...
@@ -78,27 +78,27 @@ class TDMClusterTrainer(ClusterTrainer):
context
[
'status'
]
=
'train_pass'
context
[
'status'
]
=
'train_pass'
def
tdm_prepare
(
self
,
param_name
):
def
_
tdm_prepare
(
self
,
param_name
):
if
param_name
==
"TDM_Tree_Travel"
:
if
param_name
==
"TDM_Tree_Travel"
:
travel_array
=
self
.
tdm_travel_prepare
()
travel_array
=
self
.
_
tdm_travel_prepare
()
return
travel_array
return
travel_array
elif
param_name
==
"TDM_Tree_Layer"
:
elif
param_name
==
"TDM_Tree_Layer"
:
layer_array
,
_
=
self
.
tdm_layer_prepare
()
layer_array
,
_
=
self
.
_
tdm_layer_prepare
()
return
layer_array
return
layer_array
elif
param_name
==
"TDM_Tree_Info"
:
elif
param_name
==
"TDM_Tree_Info"
:
info_array
=
self
.
tdm_info_prepare
()
info_array
=
self
.
_
tdm_info_prepare
()
return
info_array
return
info_array
else
:
else
:
raise
" {} is not a special tdm param name"
.
format
(
param_name
)
raise
" {} is not a special tdm param name"
.
format
(
param_name
)
def
tdm_travel_prepare
(
self
):
def
_
tdm_travel_prepare
(
self
):
"""load tdm tree param from npy/list file"""
"""load tdm tree param from npy/list file"""
travel_array
=
np
.
load
(
self
.
tree_travel_path
)
travel_array
=
np
.
load
(
self
.
tree_travel_path
)
logger
.
info
(
"TDM Tree leaf node nums: {}"
.
format
(
logger
.
info
(
"TDM Tree leaf node nums: {}"
.
format
(
travel_array
.
shape
[
0
]))
travel_array
.
shape
[
0
]))
return
travel_array
return
travel_array
def
tdm_layer_prepare
(
self
):
def
_
tdm_layer_prepare
(
self
):
"""load tdm tree param from npy/list file"""
"""load tdm tree param from npy/list file"""
layer_list
=
[]
layer_list
=
[]
layer_list_flat
=
[]
layer_list_flat
=
[]
...
@@ -118,7 +118,7 @@ class TDMClusterTrainer(ClusterTrainer):
...
@@ -118,7 +118,7 @@ class TDMClusterTrainer(ClusterTrainer):
[
len
(
i
)
for
i
in
layer_list
]))
[
len
(
i
)
for
i
in
layer_list
]))
return
layer_array
,
layer_list
return
layer_array
,
layer_list
def
tdm_info_prepare
(
self
):
def
_
tdm_info_prepare
(
self
):
"""load tdm tree param from list file"""
"""load tdm tree param from list file"""
info_array
=
np
.
load
(
self
.
tree_info_path
)
info_array
=
np
.
load
(
self
.
tree_info_path
)
return
info_array
return
info_array
core/trainers/tdm_single_trainer.py
浏览文件 @
c685a493
...
@@ -70,7 +70,7 @@ class TDMSingleTrainer(SingleTrainer):
...
@@ -70,7 +70,7 @@ class TDMSingleTrainer(SingleTrainer):
# covert tree to tensor, set it into Fluid's variable.
# covert tree to tensor, set it into Fluid's variable.
for
param_name
in
special_param
:
for
param_name
in
special_param
:
param_t
=
fluid
.
global_scope
().
find_var
(
param_name
).
get_tensor
()
param_t
=
fluid
.
global_scope
().
find_var
(
param_name
).
get_tensor
()
param_array
=
self
.
tdm_prepare
(
param_name
)
param_array
=
self
.
_
tdm_prepare
(
param_name
)
if
param_name
==
'TDM_Tree_Emb'
:
if
param_name
==
'TDM_Tree_Emb'
:
param_t
.
set
(
param_array
.
astype
(
'float32'
),
self
.
_place
)
param_t
.
set
(
param_array
.
astype
(
'float32'
),
self
.
_place
)
else
:
else
:
...
@@ -84,37 +84,37 @@ class TDMSingleTrainer(SingleTrainer):
...
@@ -84,37 +84,37 @@ class TDMSingleTrainer(SingleTrainer):
context
[
'status'
]
=
'train_pass'
context
[
'status'
]
=
'train_pass'
def
tdm_prepare
(
self
,
param_name
):
def
_
tdm_prepare
(
self
,
param_name
):
if
param_name
==
"TDM_Tree_Travel"
:
if
param_name
==
"TDM_Tree_Travel"
:
travel_array
=
self
.
tdm_travel_prepare
()
travel_array
=
self
.
_
tdm_travel_prepare
()
return
travel_array
return
travel_array
elif
param_name
==
"TDM_Tree_Layer"
:
elif
param_name
==
"TDM_Tree_Layer"
:
layer_array
,
_
=
self
.
tdm_layer_prepare
()
layer_array
,
_
=
self
.
_
tdm_layer_prepare
()
return
layer_array
return
layer_array
elif
param_name
==
"TDM_Tree_Info"
:
elif
param_name
==
"TDM_Tree_Info"
:
info_array
=
self
.
tdm_info_prepare
()
info_array
=
self
.
_
tdm_info_prepare
()
return
info_array
return
info_array
elif
param_name
==
"TDM_Tree_Emb"
:
elif
param_name
==
"TDM_Tree_Emb"
:
emb_array
=
self
.
tdm_emb_prepare
()
emb_array
=
self
.
_
tdm_emb_prepare
()
return
emb_array
return
emb_array
else
:
else
:
raise
" {} is not a special tdm param name"
.
format
(
param_name
)
raise
" {} is not a special tdm param name"
.
format
(
param_name
)
def
tdm_travel_prepare
(
self
):
def
_
tdm_travel_prepare
(
self
):
"""load tdm tree param from npy/list file"""
"""load tdm tree param from npy/list file"""
travel_array
=
np
.
load
(
self
.
tree_travel_path
)
travel_array
=
np
.
load
(
self
.
tree_travel_path
)
logger
.
info
(
"TDM Tree leaf node nums: {}"
.
format
(
logger
.
info
(
"TDM Tree leaf node nums: {}"
.
format
(
travel_array
.
shape
[
0
]))
travel_array
.
shape
[
0
]))
return
travel_array
return
travel_array
def
tdm_emb_prepare
(
self
):
def
_
tdm_emb_prepare
(
self
):
"""load tdm tree param from npy/list file"""
"""load tdm tree param from npy/list file"""
emb_array
=
np
.
load
(
self
.
tree_emb_path
)
emb_array
=
np
.
load
(
self
.
tree_emb_path
)
logger
.
info
(
"TDM Tree node nums from emb: {}"
.
format
(
logger
.
info
(
"TDM Tree node nums from emb: {}"
.
format
(
emb_array
.
shape
[
0
]))
emb_array
.
shape
[
0
]))
return
emb_array
return
emb_array
def
tdm_layer_prepare
(
self
):
def
_
tdm_layer_prepare
(
self
):
"""load tdm tree param from npy/list file"""
"""load tdm tree param from npy/list file"""
layer_list
=
[]
layer_list
=
[]
layer_list_flat
=
[]
layer_list_flat
=
[]
...
@@ -134,7 +134,7 @@ class TDMSingleTrainer(SingleTrainer):
...
@@ -134,7 +134,7 @@ class TDMSingleTrainer(SingleTrainer):
[
len
(
i
)
for
i
in
layer_list
]))
[
len
(
i
)
for
i
in
layer_list
]))
return
layer_array
,
layer_list
return
layer_array
,
layer_list
def
tdm_info_prepare
(
self
):
def
_
tdm_info_prepare
(
self
):
"""load tdm tree param from list file"""
"""load tdm tree param from list file"""
info_array
=
np
.
load
(
self
.
tree_info_path
)
info_array
=
np
.
load
(
self
.
tree_info_path
)
return
info_array
return
info_array
doc/distributed_train.md
浏览文件 @
c685a493
...
@@ -4,10 +4,7 @@
...
@@ -4,10 +4,7 @@
> 占位
> 占位
### 本地模拟分布式
### 本地模拟分布式
> 占位
> 占位
### MPI集群运行分布式
> 占位
### PaddleCloud集群运行分布式
> 占位
### K8S集群运行分布式
### K8S集群运行分布式
> 占位
> 占位
...
...
doc/imgs/overview.png
查看替换文件 @
e57ed516
浏览文件 @
c685a493
536.6 KB
|
W:
|
H:
732.1 KB
|
W:
|
H:
2-up
Swipe
Onion skin
doc/ps_background.md
浏览文件 @
c685a493
#
分布式-参数服务器训练简介
#
# [分布式训练概述](https://www.paddlepaddle.org.cn/tutorials/projectdetail/459124)
以下文档来源于
[
参数服务器训练简介
](
https://www.paddlepaddle.org.cn/tutorials/projectdetail/454253
)
如图1所示,参数服务器是分布式训练领域普遍采用的编程架构,主要包含Server和Worker两个部分,其中Server负责参数的存储和更新,而Worker负责训练。飞桨的参数服务器功能也是基于这种经典的架构进行设计和开发的,同时在这基础上进行了SGD(Stochastic Gradient Descent)算法的创新(Geometric Stochastic Gradient Descent)。当前经过大量的实验验证,最佳的方案是每台机器上启动Server和Worker两个进程,而一个Worker进程中可以包含多个用于训练的线程。
## [多机多卡训练](https://www.paddlepaddle.org.cn/tutorials/projectdetail/459127)
<p
align=
"center"
>
<img
align=
"center"
src=
"imgs/ps-overview.png"
>
<p>
参数服务器是主要解决两类问题:
-
模型参数过大:单机内存空间不足,需要采用分布式存储。
## [参数服务器训练](https://www.paddlepaddle.org.cn/tutorials/projectdetail/464839)
-
训练数据过多:单机训练太慢,需要加大训练节点,来提高并发训练速度。 设想,当训练数据过多,一个Worker训练太慢时,可以引入多个Worker同时训练,这时Worker之间需要同步模型参数。直观想法是,引入一个Server,Server充当Worker间参数交换的媒介。但当模型参数过大以至于单机存储空间不足时或Worker过多导致一个Server是瓶颈时,就需要引入多个Server。
具体训练流程:
-
将训练数据均匀的分配给不同的Worker。
-
将模型参数分片,存储在不同的Server上。
-
Worker端:读取一个minibatch训练数据,从Server端拉取最新的参数,计算梯度,并根据分片上传给不同的Server。
-
Server端:接收Worker端上传的梯度,根据优化算法更新参数。根据Server端每次参数更新是否需要等待所有Worker端的梯度,分为同步训练和异步训练两种机制。
飞桨的参数服务器框架也是基于这种经典的参数服务器模式进行设计和开发的,同时在这基础上进行了SGD(Stochastic Gradient Descent)算法的创新(GEO-SGD)。目前飞桨支持3种模式,分别是同步训练模式、异步训练模式、GEO异步训练模式,如图2所示。
<p
align=
"center"
>
<img
align=
"center"
src=
"imgs/fleet-ps.png"
>
<p>
## 同步训练
Worker在训练一个batch的数据后,会合并所有线程的梯度发给Server, Server在收到所有节点的梯度后,会统一进行梯度合并及参数更新。同步训练的优势在于Loss可以比较稳定的下降,缺点是整个训练速度较慢,这是典型的木桶原理,速度的快慢取决于最慢的那个线程的训练计算时间,因此在训练较为复杂的模型时,即模型训练过程中神经网络训练耗时远大于节点间通信耗时的场景下,推荐使用同步训练模式。
## 异步训练
在训练一个batch的数据后,Worker的每个线程会发送梯度给Server。而Server不会等待接收所有节点的梯度,而是直接基于已收到的梯度进行参数更新。异步训练去除了训练过程中的等待机制,训练速度得到了极大的提升,但是缺点也很明显,那就是Loss下降不稳定,容易发生抖动。建议在个性化推荐(召回、排序)、语义匹配等数据量大的场景使用。 尤其是推荐领域的点击率预估场景,该场景可能会出现千亿甚至万亿规模的稀疏特征,而稀疏参数也可以达到万亿数量级,且需要小时级或分钟级流式增量训练。如果使用异步训练模式,可以很好的满足该场景的online-learning需求。
## GEO异步训练
GEO(Geometric Stochastic Gradient Descent)异步训练是飞桨自研的异步训练模式,其最大的特点是将参数的更新从Server转移到Worker上。每个Worker在本地训练过程中会使用SGD优化算法更新本地模型参数,在训练若干个batch的数据后,Worker将发送参数更新信息给Server。Server在接收后会通过加和方式更新保存的参数信息。所以显而易见,在GEO异步训练模式下,Worker不用再等待Server发来新的参数即可执行训练,在训练效果和训练速度上有了极大的提升。但是此模式比较适合可以在单机内能完整保存的模型,在搜索、NLP等类型的业务上应用广泛,推荐在词向量、语义匹配等场景中使用。
> 运行策略的详细描述可以参考文档:[PaddlePaddle Fluid CPU分布式训练(Trainspiler)使用指南](https://www.paddlepaddle.org.cn/tutorials/projectdetail/454253)
## 单机代码转分布式
### 训练代码准备
参数服务器架构,有两个重要的组成部分:Server与Worker。为了启动训练,我们是否要准备两套代码分别运行呢?答案是不需要的。Paddle Fleet API将两者运行的逻辑进行了很好的统一,用户只需使用
`fleet.init(role)`
就可以判断当前启动的程序扮演server还是worker。使用如下的编程范式,只需10行,便可将单机代码转变为分布式代码:
```
python
role
=
role_maker
.
PaddleCloudRoleMaker
()
fleet
.
init
(
role
)
# Define your network, choose your optimizer(SGD/Adam/Adagrad etc.)
strategy
=
StrategyFactory
.
create_sync_strategy
()
optimizer
=
fleet
.
distributed_optimizer
(
optimizer
,
strategy
)
if
fleet
.
is_server
():
fleet
.
init_server
()
fleet
.
run_server
()
if
fleet
.
is_worker
():
fleet
.
init_worker
()
# run training
fleet
.
stop_worker
()
```
### 运行环境准备
-
Paddle参数服务器模式的训练,目前只支持在
`Liunx`
环境下运行,推荐使用
`ubuntu`
或
`CentOS`
-
Paddle参数服务器模式的前端代码支持
`python 2.7`
及
`python 3.5+`
,若使用
`Dataset`
模式的高性能IO,需使用
`python 2.7`
-
使用多台机器进行分布式训练,请确保各自之间可以通过
`ip:port`
的方式访问
`rpc`
服务,使用
`http/https`
代理会导致通信失败
-
各个机器之间的通信耗费应尽量少
假设我们有两台机器,想要在每台机器上分别启动一个
`server`
进程以及一个
`worker`
进程,完成2x2(2个参数服务器,2个训练节点)的参数服务器模式分布式训练,按照如下步骤操作。
### 启动server
机器A,IP地址是
`10.89.176.11`
,通信端口是
`36000`
,配置如下环境变量后,运行训练的入口程序:
```
bash
export
PADDLE_PSERVERS_IP_PORT_LIST
=
"10.89.176.11:36000,10.89.176.12:36000"
export
TRAINING_ROLE
=
PSERVER
export
POD_IP
=
10.89.176.11
# node A:10.89.176.11
export
PADDLE_PORT
=
36000
export
PADDLE_TRAINERS_NUM
=
2
python
-u
train.py
--is_cloud
=
1
```
应能在日志中看到如下输出:
> I0318 21:47:01.298220 188592128 grpc_server.cc:470] Server listening on 127.0.0.1:36000 selected port: 36000
查看系统进程
> 8624 | ttys000 | 0:02.31 | python -u train.py --is_cloud=1
查看系统进程及端口占用:
> python3.7 | 8624 | paddle | 8u | IPv6 | 0xe149b87d093872e5 | 0t0 | TCP | localhost:36000 (LISTEN)
也可以看到我们的
`server`
进程8624的确在
`36000`
端口开始了监听,等待
`worker`
的通信。
机器B,IP地址是
`10.89.176.12`
,通信端口是
`36000`
,配置如下环境变量后,运行训练的入口程序:
```
bash
export
PADDLE_PSERVERS_IP_PORT_LIST
=
"10.89.176.11:36000,10.89.176.12:36000"
export
TRAINING_ROLE
=
PSERVER
export
POD_IP
=
10.89.176.12
# node B: 10.89.176.12
export
PADDLE_PORT
=
36000
export
PADDLE_TRAINERS_NUM
=
2
python
-u
train.py
--is_cloud
=
1
```
也可以看到相似的日志输出与进程状况。(进行验证时,请务必确保IP与端口的正确性)
### 启动worker
接下来我们分别在机器A与B上开启训练进程。配置如下环境变量并开启训练进程:
机器A:
```
bash
export
PADDLE_PSERVERS_IP_PORT_LIST
=
"10.89.176.11:36000,10.89.176.12:36000"
export
TRAINING_ROLE
=
TRAINER
export
PADDLE_TRAINERS_NUM
=
2
export
PADDLE_TRAINER_ID
=
0
# node A:trainer_id = 0
python
-u
train.py
--is_cloud
=
1
```
机器B:
```
bash
export
PADDLE_PSERVERS_IP_PORT_LIST
=
"10.89.176.11:36000,10.89.176.12:36000"
export
TRAINING_ROLE
=
TRAINER
export
PADDLE_TRAINERS_NUM
=
2
export
PADDLE_TRAINER_ID
=
1
# node B: trainer_id = 1
python
-u
train.py
--is_cloud
=
1
```
运行该命令时,若pserver还未就绪,可在日志输出中看到如下信息:
> server not ready, wait 3 sec to retry...
>
> not ready endpoints:['10.89.176.11:36000', '10.89.176.12:36000']
worker进程将持续等待,直到server开始监听,或等待超时。
当pserver都准备就绪后,可以在日志输出看到如下信息:
> I0317 11:38:48.099179 16719 communicator.cc:271] Communicator start
>
> I0317 11:38:49.838711 16719 rpc_client.h:107] init rpc client with trainer_id 0
至此,分布式训练启动完毕,将开始训练。
readme.md
已删除
100644 → 0
浏览文件 @
e57ed516
<p
align=
"center"
>
<img
align=
"center"
src=
"doc/imgs/logo.png"
>
<p>
<p
align=
"center"
>
<br>
<img
alt=
"Release"
src=
"https://img.shields.io/badge/Release-0.1.0-yellowgreen"
>
<img
alt=
"License"
src=
"https://img.shields.io/github/license/PaddlePaddle/Serving"
>
<img
alt=
"Slack"
src=
"https://img.shields.io/badge/Join-Slack-green"
>
<br>
<p>
<h2
align=
"center"
>
什么是PaddleRec
</h2>
<p
align=
"center"
>
<img
align=
"center"
src=
"doc/imgs/structure.png"
>
<p>
-
源于飞桨生态的搜索推荐模型
**一站式开箱即用工具**
-
适合初学者,开发者,研究者从调研,训练到预测部署的全流程解决方案
-
包含语义理解、召回、粗排、精排、多任务学习、融合等多个任务的推荐搜索算法库
-
配置
**yaml**
自定义选项,即可快速上手使用单机训练、大规模分布式训练、离线预测、在线部署
<h2
align=
"center"
>
PadlleRec概览
</h2>
<p
align=
"center"
>
<img
align=
"center"
src=
"doc/imgs/overview.png"
>
<p>
<h2
align=
"center"
>
推荐系统-流程概览
</h2>
<p
align=
"center"
>
<img
align=
"center"
src=
"doc/imgs/rec-overview.png"
>
<p>
<h2
align=
"center"
>
便捷安装
</h2>
### 环境要求
*
Python 2.7/ 3.5 / 3.6 / 3.7
*
PaddlePaddle >= 1.7.2
*
操作系统: Windows/Mac/Linux
### 安装命令
-
安装方法一
<PIP源直接安装>
:
```
bash
python
-m
pip
install
paddle-rec
```
-
安装方法二
源码编译安装
1.
安装飞桨
**注:需要用户安装版本 >1.7.2 的飞桨**
```shell
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
2.
源码安装PaddleRec
```
git clone https://github.com/PaddlePaddle/PaddleRec/
cd PaddleRec
python setup.py install
```
<h2
align=
"center"
>
快速启动
</h2>
### 启动内置模型的默认配置
目前框架内置了多个模型,简单的命令即可使用内置模型开始单机训练和本地1
*
1模拟训练,我们以
`dnn`
为例介绍PaddleRec的简单使用。
#### 单机训练
```
bash
# 使用CPU进行单机训练
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-d
cpu
-e
single
# 使用GPU进行单机训练
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-d
gpu
-e
single
```
#### 本地模拟分布式训练
```
bash
# 使用CPU资源进行本地模拟分布式训练
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-e
local_cluster
```
#### 集群分布式训练
```
bash
# 配置好 mpi/k8s/paddlecloud集群环境后
python
-m
paddlerec.run
-m
paddlerec.models.rank.dnn
-e
cluster
```
### 启动内置模型的自定配置
若您复用内置模型,对
**yaml**
配置文件进行了修改,如更改超参,重新配置数据后,可以直接使用paddlerec运行该yaml文件。
我们以dnn模型为例,在paddlerec代码目录下,修改了dnn模型
`config.yaml`
的配置后,运行
`dnn`
模型:
```
bash
python
-m
paddlerec.run
-m
./models/rank/dnn/config.yaml
-e
single
```
<h2
align=
"center"
>
支持模型列表
</h2>
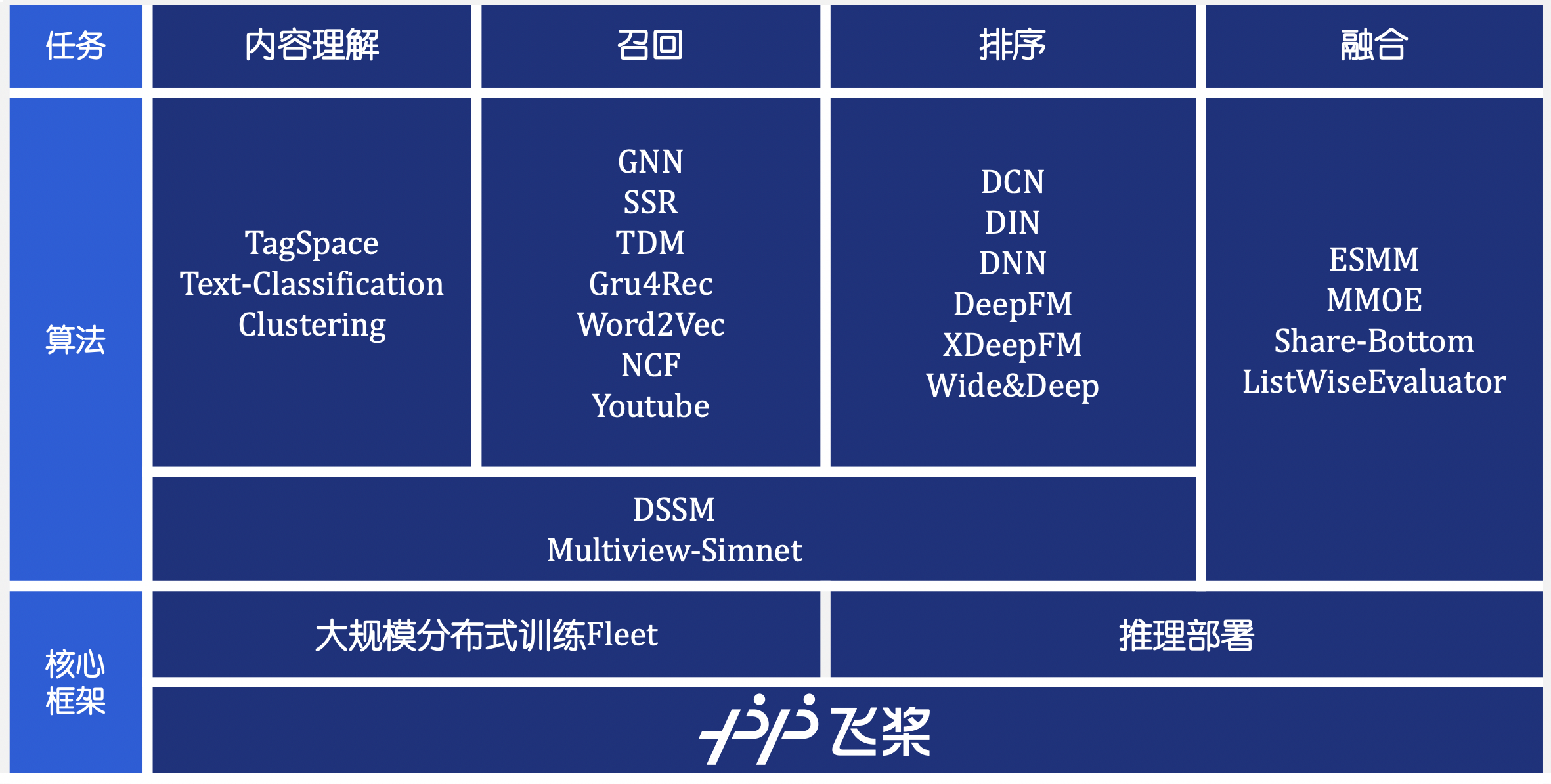
| 方向 | 模型 | 单机CPU训练 | 单机GPU训练 | 分布式CPU训练 |
| :------: | :----------------------------------------------------------------------------: | :---------: | :---------: | :-----------: |
| 内容理解 |
[
Text-Classifcation
](
models/contentunderstanding/classification/model.py
)
| ✓ | x | ✓ |
| 内容理解 |
[
TagSpace
](
models/contentunderstanding/tagspace/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
TDM
](
models/treebased/tdm/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
Word2Vec
](
models/recall/word2vec/model.py
)
| ✓ | x | ✓ |
| 召回 |
[
SSR
](
models/recall/ssr/model.py
)
| ✓ | ✓ | ✓ |
| 召回 |
[
Gru4Rec
](
models/recall/gru4rec/model.py
)
| ✓ | ✓ | ✓ |
| 排序 |
[
Dnn
](
models/rank/dnn/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
DeepFM
](
models/rank/deepfm/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
xDeepFM
](
models/rank/xdeepfm/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
DIN
](
models/rank/din/model.py
)
| ✓ | x | ✓ |
| 排序 |
[
Wide&Deep
](
models/rank/wide_deep/model.py
)
| ✓ | x | ✓ |
| 多任务 |
[
ESMM
](
models/multitask/esmm/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
MMOE
](
models/multitask/mmoe/model.py
)
| ✓ | ✓ | ✓ |
| 多任务 |
[
ShareBottom
](
models/multitask/share-bottom/model.py
)
| ✓ | ✓ | ✓ |
| 匹配 |
[
DSSM
](
models/match/dssm/model.py
)
| ✓ | x | ✓ |
| 匹配 |
[
MultiView-Simnet
](
models/match/multiview-simnet/model.py
)
| ✓ | x | ✓ |
<h2
align=
"center"
>
文档
</h2>
### 背景介绍
*
[
推荐系统介绍
](
doc/rec_background.md
)
*
[
分布式深度学习介绍
](
doc/ps_background.md
)
### 新手教程
*
[
环境要求
](
#环境要求
)
*
[
安装命令
](
#安装命令
)
*
[
快速开始
](
#启动内置模型的默认配置
)
### 进阶教程
*
[
自定义数据集及Reader
](
doc/custom_dataset_reader.md
)
*
[
分布式训练
](
doc/distributed_train.md
)
### 开发者教程
*
[
PaddleRec设计文档
](
doc/design.md
)
### 关于PaddleRec性能
*
[
Benchmark
](
doc/benchmark.md
)
### FAQ
*
[
常见问题FAQ
](
doc/faq.md
)
<h2
align=
"center"
>
社区
</h2>
### 反馈
如有意见、建议及使用中的BUG,欢迎在
`GitHub Issue`
提交
### 版本历史
-
2020.5.14 - PaddleRec v0.1
### 许可证书
本项目的发布受
[
Apache 2.0 license
](
LICENSE
)
许可认证。
>>>>>>> d7171ec5daa477584de89ea7e57a382045e12311
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}