Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleRec
提交
1b2a89f6
P
PaddleRec
项目概览
PaddlePaddle
/
PaddleRec
通知
68
Star
12
Fork
5
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
27
列表
看板
标记
里程碑
合并请求
10
Wiki
1
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleRec
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
27
Issue
27
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
1
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
1b2a89f6
编写于
5月 15, 2020
作者:
C
chengmo
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'ai_studio_beta' into 'develop'
Readme update See merge request
!43
上级
7aef156b
531bf6f7
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
456 addition
and
54 deletion
+456
-54
core/model.py
core/model.py
+0
-6
doc/custom_dataset_reader.md
doc/custom_dataset_reader.md
+172
-45
doc/design.md
doc/design.md
+281
-1
doc/imgs/design.png
doc/imgs/design.png
+0
-0
doc/ps_background.md
doc/ps_background.md
+2
-1
readme.md
readme.md
+1
-1
未找到文件。
core/model.py
浏览文件 @
1b2a89f6
...
@@ -43,12 +43,6 @@ class Model(object):
...
@@ -43,12 +43,6 @@ class Model(object):
"""
"""
return
self
.
_metrics
return
self
.
_metrics
def
custom_preprocess
(
self
):
"""
do something after exe.run(stratup_program) and before run()
"""
pass
def
get_fetch_period
(
self
):
def
get_fetch_period
(
self
):
return
self
.
_fetch_interval
return
self
.
_fetch_interval
...
...
doc/custom_dataset_reader.md
浏览文件 @
1b2a89f6
# PaddleRec 自定义数据集及Reader
# PaddleRec 自定义数据集及Reader
## 数据集及reader配置简介
用户自定义数据集及配置异步Reader,需要关注以下几个步骤:
以
`ctr-dnn`
模型举例:
*
[
数据集整理
](
#数据集整理
)
*
[
在模型组网中加入输入占位符
](
#在模型组网中加入输入占位符
)
*
[
Reader实现
](
#Reader的实现
)
*
[
在yaml文件中配置Reader
](
#在yaml文件中配置reader
)
```
yaml
我们以CTR-DNN模型为例,给出了从数据整理,变量定义,Reader写法,调试的完整历程。
reader
:
batch_size
:
2
*
[
数据及Reader示例-DNN
](
#数据及Reader示例-DNN
)
class
:
"
{workspace}/../criteo_reader.py"
train_data_path
:
"
{workspace}/data/train"
reader_debug_mode
:
False
## 数据集整理
PaddleRec支持模型自定义数据集。
关于数据的tips:
1.
数据量:
PaddleRec面向大规模数据设计,可以轻松支持亿级的数据读取,工业级的数据读写api:`dataset`在搜索、推荐、信息流等业务得到了充分打磨。
2.
文件类型:
支持任意直接可读的文本数据,`dataset`同时支持`.gz`格式的文本压缩数据,无需额外代码,可直接读取。数据样本应以`\n`为标志,按行组织。
3.
文件存放位置:
文件通常存放在训练节点本地,但同时,`dataset`支持使用`hadoop`远程读取数据,数据无需下载到本地,为dataset配置hadoop相关账户及地址即可。
4.
数据类型
Reader处理的是以行为单位的`string`数据,喂入网络的数据需要转为`int`,`float`的数值数据,不支持`string`喂入网络,不建议明文保存及处理训练数据。
5.
Tips
Dataset模式下,训练线程与数据读取线程的关系强相关,为了多线程充分利用,`强烈建议将文件合理的拆为多个小文件`,尤其是在分布式训练场景下,可以均衡各个节点的数据量,同时加快数据的下载速度。
## 在模型组网中加入输入占位符
Reader读取文件后,产出的数据喂入网络,需要有占位符进行接收。占位符在Paddle中使用
`fluid.data`
或
`fluid.layers.data`
进行定义。
`data`
的定义可以参考
[
fluid.data
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/fluid_cn/data_cn.html#data
)
以及
[
fluid.layers.data
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/layers_cn/data_cn.html#data
)
。
加入您希望输入三个数据,分别是维度32的数据A,维度变长的稀疏数据B,以及一个一维的标签数据C,并希望梯度可以经过该变量向前传递,则示例如下:
数据A的定义:
```
python
var_a
=
fluid
.
data
(
name
=
'A'
,
shape
=
[
-
1
,
32
],
dtype
=
'float32'
)
```
数据B的定义,变长数据的使用可以参考
[
LoDTensor
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/basic_concept/lod_tensor.html#cn-user-guide-lod-tensor
)
:
```
python
var_b
=
fluid
.
data
(
name
=
'B'
,
shape
=
[
-
1
,
1
],
lod_level
=
1
,
dtype
=
'int64'
)
```
数据C的定义:
```
python
var_c
=
fluid
.
data
(
name
=
'C'
,
shape
=
[
-
1
,
1
],
dtype
=
'int32'
)
var_c
.
stop_gradient
=
False
```
当我们完成以上三个数据的定义后,在PaddleRec的模型定义中,还需将其加入model基类成员变量
`self._data_var`
```
python
self
.
_data_var
.
append
(
var_a
)
self
.
_data_var
.
append
(
var_b
)
self
.
_data_var
.
append
(
var_c
)
```
```
有以上4个需要重点关注的配置选项:
至此,我们完成了在组网中定义输入数据的工作。
## Reader的实现
### Reader的实现范式
Reader的逻辑需要一个单独的python文件进行描述。我们试写一个
`test_reader.py`
,实现的具体流程如下:
1.
首先我们需要引入Reader基类
-
batch_size: 网络进行小批量训练的一组数据的大小
```python
-
class: 指定数据处理及读取的
`reader`
python文件
from paddlerec.core.reader import Reader
-
train_data_path: 训练数据所在地址
```
-
reader_debug_mode: 测试reader语法,及输出是否符合预期的debug模式的开关
2.
创建一个子类,继承Reader的基类,训练所需Reader命名为
`TrainerReader`
```
python
class
TrainerReader
(
Reader
):
def
init
(
self
):
pass
def
generator_sample
(
self
,
line
):
pass
```
3.
在
`init(self)`
函数中声明一些在数据读取中会用到的变量,必要时可以在
`config.yaml`
文件中配置变量,利用
`env.get_global_env()`
拿到。
比如,我们希望从yaml文件中读取一个数据预处理变量
`avg=10`
,目的是将数据A的数据缩小10倍,可以这样实现:
-
首先更改yaml文件,在某个space下加入该变量
```
yaml
...
train
:
reader
:
avg
:
10
...
```
-
再更改Reader的init函数
```
python
from
paddlerec.core.utils
import
envs
class
TrainerReader
(
Reader
):
def
init
(
self
):
self
.
avg
=
envs
.
get_global_env
(
"avg"
,
None
,
"train.reader"
)
def
generator_sample
(
self
,
line
):
pass
```
4.
继承并实现基类中的
`generate_sample(self, line)`
函数,逐行读取数据。
-
该函数应返回一个可以迭代的reader方法(带有yield的函数不再是一个普通的函数,而是一个生成器generator,成为了可以迭代的对象,等价于一个数组、链表、文件、字符串etc.)
-
在这个可以迭代的函数中,如示例代码中的
`def reader()`
,我们定义数据读取的逻辑。以行为单位的数据进行截取,转换及预处理。
-
最后,我们需要将数据整理为特定的格式,才能够被PaddleRec的Reader正确读取,并灌入的训练的网络中。简单来说,数据的输出顺序与我们在网络中创建的
`inputs`
必须是严格一一对应的,并转换为类似字典的形式。
示例: 假设数据ABC在文本数据中,每行以这样的形式存储:
```
shell
0.1,0.2,0.3...3.0,3.1,3.2
\t
99999,99998,99997
\t
1
\n
```
则示例代码如下:
```python
from paddlerec.core.utils import envs
class TrainerReader(Reader):
def init(self):
self.avg = envs.get_global_env("avg", None, "train.reader")
def generator_sample(self, line):
def reader(self, line):
# 先分割 '\n', 再以 '\t'为标志分割为list
variables = (line.strip('\n')).split('\t')
# A是第一个元素,并且每个数据之间使用','分割
var_a = variables[0].split(',') # list
var_a = [float(i) / self.avg for i in var_a] # 将str数据转换为float
# B是第二个元素,同样以 ',' 分割
var_b = variables[1].split(',') # list
var_b = [int(i) for i in var_b] # 将str数据转换为int
# C是第三个元素, 只有一个元素,没有分割符
var_c = variables[2]
var_c = int(var_c) # 将str数据转换为int
var_c = [var_c] # 将单独的数据元素置入list中
# 将数据与数据名结合,组织为dict的形式
# 如下,output形式为{ A: var_a, B: var_b, C: var_c}
variable_name = ['A', 'B', 'C']
output = zip(variable_name, [var_a] + [var_b] + [var_c])
# 将数据输出,使用yield方法,将该函数变为了一个可迭代的对象
yield output
## 自定义数据集
```
至此,我们完成了Reader的实现。
PaddleRec支持模型自定义数据集,在model.config.yaml文件中的reader部分,通过
`train_data_path`
指定数据读取路径。
关于数据的tips
### 在yaml文件中配置Reader
-
PaddleRec 面向的是推荐与搜索领域,数据以文本格式为主
在模型的yaml配置文件中,主要的修改是三个,如下
-
Dataset模式支持读取文本数据压缩后的
`.gz`
格式
-
Dataset模式下,训练线程与数据读取线程的关系强相关,为了多线程充分利用,
`强烈建议将文件拆成多个小文件`
,尤其是在分布式训练场景下,可以均衡各个节点的数据量。
## 自定义Reader
```
yaml
reader
:
batch_size
:
2
class
:
"
{workspace}/reader.py"
train_data_path
:
"
{workspace}/data/train_data"
reader_debug_mode
:
False
```
batch_size: 顾名思义,是小批量训练时的样本大小
class: 运行改模型所需reader的路径
train_data_path: 训练数据所在文件夹
reader_debug_mode: 测试reader语法,及输出是否符合预期的debug模式的开关
数据集准备就绪后,需要适当修改或重写一个新的reader以适配数据集或新组网。
我们以
`ctr-dnn`
网络举例
`reader`
的正确打开方式,网络文件位于
`models/rank/dnn`
。
## 数据及Reader示例-DNN
Reader代码来源于
[
criteo_reader.py
](
../models/rank/criteo_reader.py
)
, 组网代码来源于
[
model.py
](
../models/rank/dnn/model.py
)
### Criteo数据集格式
### Criteo数据集格式
...
@@ -100,13 +250,8 @@ for input in self.sparse_inputs:
...
@@ -100,13 +250,8 @@ for input in self.sparse_inputs:
self
.
_data_var
.
append
(
self
.
label_input
)
self
.
_data_var
.
append
(
self
.
label_input
)
if
self
.
_platform
!=
"LINUX"
:
self
.
_data_loader
=
fluid
.
io
.
DataLoader
.
from_generator
(
feed_list
=
self
.
_data_var
,
capacity
=
64
,
use_double_buffer
=
False
,
iterable
=
False
)
```
```
若运行于
**Linux**
环境下,默认使用
**dataset**
模式读取数据集;若运行于
**windows**
或
**mac**
下,默认使用
**dataloader**
模式读取数据集。以上两种方法是paddle.io中提供的不同模式,
`dataset`
运行速度更快,但依赖于linux的环境,因此会有该逻辑判断。
> Paddle的组网中不支持数据输入为`str`类型,`强烈不建议使用明文保存和读取数据`
### Criteo Reader写法
### Criteo Reader写法
...
@@ -165,24 +310,6 @@ class TrainReader(Reader):
...
@@ -165,24 +310,6 @@ class TrainReader(Reader):
return
reader
return
reader
```
```
### 如何自定义数据读取规则
在上文我们看到了由
`criteo_reader.py`
实现具体的数据读取规则,那么,怎样为自己的数据集写规则呢?
具体流程如下:
1.
首先我们需要引入Reader基类
```python
from paddlerec.core.reader import Reader
```
2.
创建一个子类,继承Reader的基类,训练所需Reader命名为
`TrainerReader`
3.
在
`init(self)`
函数中声明一些在数据读取中会用到的变量,如示例代码中的
`cont_min_`
、
`categorical_range_`
等,必要时可以在
`config.yaml`
文件中配置变量,通过
`env.get_global_env()`
拿到。
4.
继承并实现基类中的
`generate_sample(self, line)`
函数,逐行读取数据。该函数应返回一个可以迭代的reader方法(带有yield的函数不再是一个普通的函数,而是一个生成器generator,成为了可以迭代的对象,等价于一个数组、链表、文件、字符串etc.)
5.
在这个可以迭代的函数中,如示例代码中的
`def reader()`
,我们定义数据读取的逻辑。以行为单位的数据进行截取,转换及预处理。
6.
最后,我们需要将数据整理为特定的格式,才能够被dataset正确读取,并灌入的训练的网络中。简单来说,数据的输出顺序与我们在网络中创建的
`inputs`
必须是严格一一对应的,并转换为类似字典的形式。在示例代码中,我们使用
`zip`
的方法将参数名与数值构成的元组组成了一个list,并将其yield输出。如果展开来看,我们输出的数据形如
`[('dense_feature',[value]),('C1',[value]),('C2',[value]),...,('C26',[value]),('label',[value])]`
### 调试Reader
### 调试Reader
...
...
doc/design.md
浏览文件 @
1b2a89f6
# PaddleRec 设计
# PaddleRec 设计
> 占位
\ No newline at end of file
## PaddleRec 整体设计概览
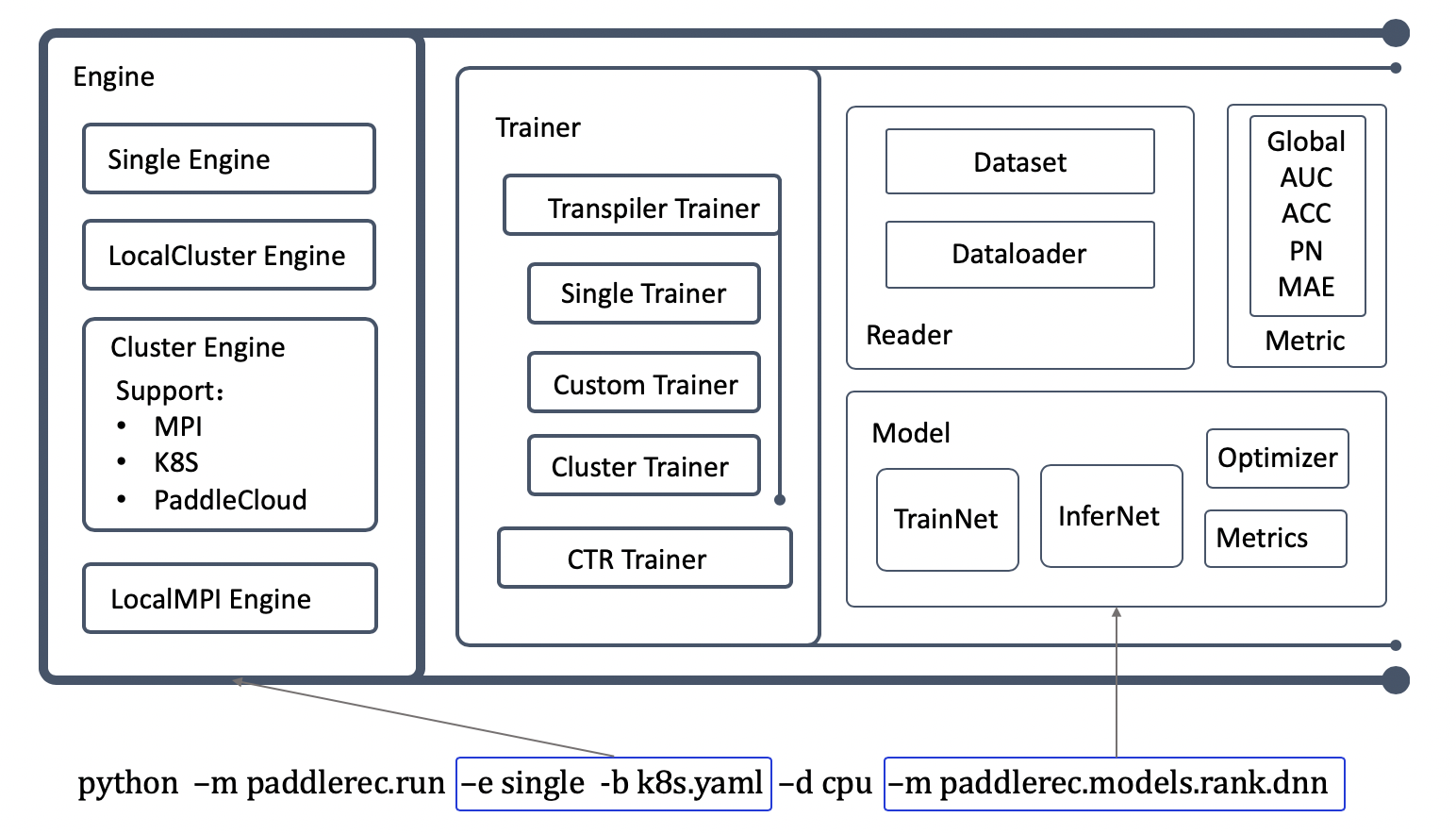
PaddleRec将推荐模型的训练与预测流程,整体抽象为了五个大模块:
*
[
Engine 流程执行引擎
](
#engine
)
*
[
Trainer 流程具体定义
](
#trainer
)
*
[
Model 模型组网定义
](
#model
)
*
[
Reader 数据读取定义
](
#reader
)
*
[
Metric 精度指标打印
](
#metric
)
层级结构,以及一键启动训练时的调用关系如下图所示:
<p
align=
"center"
>
<img
align=
"center"
src=
"imgs/design.png"
>
<p>
core的文件结构如下,后续分别对各个模块进行介绍。
```
.core
├── engine/ 运行引擎实现
├── metrics/ 全局指标实现
├── modules/ 自定义op实现
├── trainers/ 运行流程实现
├── utils/ 辅助工具
├── factory.py 运行流程的注册
├── layer.py 自定义op基类定义
├── metric.py Metric基类定义
├── model.py Model基类定义
├── reader.py Reader基类定义
└── trainer.py Trainer基类定义
```
## Engine
Engine是整体训练的执行引擎,与组网逻辑及数据无关,只与当前运行模式、运行环境及运行设备有关。
运行模式具体是指:
-
单机运行
-
分布式运行
-
本地模拟分布式
运行环境是指:
-
Linux
-
Windows
-
Mac
运行设备是指:
-
CPU
-
GPU
-
AI芯片
在用户调用
`python -m paddlerec.run`
时,首先会根据
`yaml`
文件中的配置信息选择合适的执行引擎, 以下代码位于
[
run.py
](
../run.py
)
:
```
python
engine_registry
()
which_engine
=
get_engine
(
args
)
engine
=
which_engine
(
args
)
engine
.
run
()
```
我们以
`single engine`
为例,概览engine的行为:
```
python
def
single_engine
(
args
):
trainer
=
get_trainer_prefix
(
args
)
+
"SingleTrainer"
single_envs
=
{}
single_envs
[
"train.trainer.trainer"
]
=
trainer
single_envs
[
"train.trainer.threads"
]
=
"2"
single_envs
[
"train.trainer.engine"
]
=
"single"
single_envs
[
"train.trainer.device"
]
=
args
.
device
single_envs
[
"train.trainer.platform"
]
=
envs
.
get_platform
()
print
(
"use {} engine to run model: {}"
.
format
(
trainer
,
args
.
model
))
set_runtime_envs
(
single_envs
,
args
.
model
)
trainer
=
TrainerFactory
.
create
(
args
.
model
)
return
trainer
```
single_engine被调用后,主要进行了以下两个工作:
1.
根据
`yaml`
配置文件,设置了
**当前进程的环境变量**
,后续的所有流程都依赖于环境变量。
2.
根据模型及环境,指定并初始化了运行流程所用的
`Trainer`
进一步细化第一步工作
-
本地模拟分布式引擎会在单机环境变量的基础上,额外设置本地模拟分布式的环境变量,比如:为各个进程设置不同通信端口,分配ID。最后会启动多个
`Trainer`
完成本地模拟分布式的工作。
-
分布式引擎会在单机环境变量的基础上,基于运行参数
`-b --backend`
所指定的脚本或配置文件,完成分布式任务的文件打包,上传,提交等操作。该脚本格式与分布式任务运行的集群有关,如MPI/K8S/PaddleCloud等,用户可以自定义分布式运行逻辑。
Engine的自定义实现,可以参考
[
local_cluster.py
](
../core/engine/local_cluster.py
)
## Trainer
`Trainer`
是训练与预测流程的具体实现,会run模型中定义的各个流程,与model、reader、metric紧密相关。PaddleRec以有限状态机的逻辑定义了训练中的各个阶段,不同的Trainer子类会分别实现阶段中的特殊需求。有限状态机的流程在
`def processor_register()`
中注册。
我们以SingleTrainer为例,概览Trainer行为:
```
python
class
SingleTrainer
(
TranspileTrainer
):
def
processor_register
(
self
):
self
.
regist_context_processor
(
'uninit'
,
self
.
instance
)
self
.
regist_context_processor
(
'init_pass'
,
self
.
init
)
self
.
regist_context_processor
(
'startup_pass'
,
self
.
startup
)
if
envs
.
get_platform
()
==
"LINUX"
and
envs
.
get_global_env
(
"dataset_class"
,
None
,
"train.reader"
)
!=
"DataLoader"
:
self
.
regist_context_processor
(
'train_pass'
,
self
.
dataset_train
)
else
:
self
.
regist_context_processor
(
'train_pass'
,
self
.
dataloader_train
)
self
.
regist_context_processor
(
'infer_pass'
,
self
.
infer
)
self
.
regist_context_processor
(
'terminal_pass'
,
self
.
terminal
)
```
SingleTrainer首先注册了完成任务所需的步骤,各步骤首先按照注册顺序加入
`Trainer`
基类中名为
`status_processor`
的字典,运行的先后顺序,可以在每个执行步骤中改变
`context['status']`
的值,指定下一步运行哪个步骤。
SingleTrainer指定了以下6个步骤:
1.
uninit:默认排在首位,通过环境变量决定model的对象
1.
init_pass:调用model_的接口,生成模型的组网,初始化fetch及metric的变量
2.
startup_pass:初始化模型组网中的各个参数,run(fluid.default_startup_program)
3.
train_pass:会根据环境分别调用
`dataset`
与
`dataloader`
进行训练的流程。
4.
infer_pass:在训练结束后,会对训练保存的模型在测试集上验证效果
5.
terminal_pass:打印全局变量及预测结果等自定义的信息。
Trainer的自定义实现,可以参照
[
single_trainer.py
](
../core/trainers/single_trainer.py
)
## Model
Model定义了各个模型实现的范式,模型只要继承并实现基类中的函数,并给一些成员赋值,就可以保证模型被Trainer正确调用。
我们首先看一下Model基类中的部分重要定义,对模型的实现流程有初步概念。
```
python
class
Model
(
object
):
__metaclass__
=
abc
.
ABCMeta
def
__init__
(
self
,
config
):
self
.
_cost
=
None
self
.
_metrics
=
{}
self
.
_data_var
=
[]
self
.
_infer_data_var
=
[]
self
.
_infer_results
=
{}
self
.
_data_loader
=
None
self
.
_infer_data_loader
=
None
self
.
_fetch_interval
=
20
self
.
_namespace
=
"train.model"
self
.
_platform
=
envs
.
get_platform
()
def
get_inputs
(
self
):
return
self
.
_data_var
@
abc
.
abstractmethod
def
train_net
(
self
):
pass
@
abc
.
abstractmethod
def
infer_net
(
self
):
pass
def
get_cost_op
(
self
):
return
self
.
_cost
```
每个模型都一定需要继承
`def train_net`
与
`def infer_net`
,并且给
`self._data_var`
与
`self._cost`
成员赋值,指定模型入口,实现组网的整体逻辑。若有更多或更复杂的需求,可以参照下面的接口,分别继承各个函数,并实现需要的功能:
```
python
def
get_infer_inputs
(
self
):
return
self
.
_infer_data_var
def
get_infer_results
(
self
):
return
self
.
_infer_results
def
get_metrics
(
self
):
return
self
.
_metrics
def
get_fetch_period
(
self
):
return
self
.
_fetch_interval
```
model的具体实现,可以参考dnn的示例
[
model.py
](
../../models/rank/dnn/../../../paddlerec/core/model.py
)
## Reader
PaddleRec会根据运行环境,分别指定不同的数据IO方式。在Linux下,优先使用
`Dataset`
,Win及Mac优先使用
`Dataloader`
。
Dataset的使用介绍可以参考
[
DatasetFactory
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dataset_cn/DatasetFactory_cn.html
)
Dataloader的使用介绍可以参考
[
异步数据读取
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/data_preparing/use_py_reader.html
)
考虑到以上两种高效的数据IO方式仍然有很高的学习门槛,PaddleRec将两种数据读取方式进行了更高层次的封装,用户需要实现的仅是每行数据的处理逻辑,剩下的工作交给PaddleRec的Reader基类完成。
首先浏览以下Reader基类的定义,有一个初步的印象:
```
python
class
Reader
(
dg
.
MultiSlotDataGenerator
):
__metaclass__
=
abc
.
ABCMeta
def
__init__
(
self
,
config
):
dg
.
MultiSlotDataGenerator
.
__init__
(
self
)
if
os
.
path
.
isfile
(
config
):
with
open
(
config
,
'r'
)
as
rb
:
_config
=
yaml
.
load
(
rb
.
read
(),
Loader
=
yaml
.
FullLoader
)
else
:
raise
ValueError
(
"reader config only support yaml"
)
envs
.
set_global_envs
(
_config
)
envs
.
update_workspace
()
@
abc
.
abstractmethod
def
init
(
self
):
pass
@
abc
.
abstractmethod
def
generate_sample
(
self
,
line
):
pass
```
用户需要关注并实现的是
`def init(self)`
与
`def generate_sample(self,line)`
函数,分别执行数据读取中预处理所需变量的初始化,以及每一行string的切分及处理逻辑。
当用户定义好以上两个函数,完成自己的Reader后,PaddleRec分别使用
-
[
dataset_instance.py
](
../core/utils/dataset_instance.py
)
-
[
dataloader_instance.py
](
../core/utils/dataloader_instance.py
)
完成reader的构建工作。
Reader数据处理的逻辑,可以参考
[
criteo_reader.py
](
../../models/rank/../../paddlerec/models/rank/criteo_reader.py
)
## Metric
训练必然伴随着训练指标的打印,当单机运行时,打印相关信息比较简单。但分布式训练时,单机指标与全局指标往往有很大diff,比如
`auc`
以及正逆序
`pn`
。PaddleRec面向大规模分布式训练,将指标打印的逻辑抽象出来单独实现,以解决分布式训练时全局指标打印的问题。
Metric基类定义了基本的接口,如下:
```
python
class
Metric
(
object
):
__metaclass__
=
abc
.
ABCMeta
def
__init__
(
self
,
config
):
""" init """
pass
@
abc
.
abstractmethod
def
clear
(
self
,
scope
,
params
):
"""
clear current value
Args:
scope: value container
params: extend varilable for clear
"""
pass
@
abc
.
abstractmethod
def
calculate
(
self
,
scope
,
params
):
"""
calculate result
Args:
scope: value container
params: extend varilable for clear
"""
pass
@
abc
.
abstractmethod
def
get_result
(
self
):
"""
Return:
result(dict) : calculate result
"""
pass
@
abc
.
abstractmethod
def
get_result_to_string
(
self
):
"""
Return:
result(string) : calculate result with string format, for output
"""
pass
```
全局指标的计算及输出,需要分别继承并实现以上四个成员函数。具体实现的例子,可以参考
[
auc_metric.py
](
../core/metrics/auc_metrics.py
)
\ No newline at end of file
doc/imgs/design.png
0 → 100644
浏览文件 @
1b2a89f6
456.1 KB
doc/ps_background.md
浏览文件 @
1b2a89f6
# 参数服务器训练简介
#
分布式-
参数服务器训练简介
以下文档来源于
[
参数服务器训练简介
](
https://www.paddlepaddle.org.cn/tutorials/projectdetail/454253
)
如图1所示,参数服务器是分布式训练领域普遍采用的编程架构,主要包含Server和Worker两个部分,其中Server负责参数的存储和更新,而Worker负责训练。飞桨的参数服务器功能也是基于这种经典的架构进行设计和开发的,同时在这基础上进行了SGD(Stochastic Gradient Descent)算法的创新(Geometric Stochastic Gradient Descent)。当前经过大量的实验验证,最佳的方案是每台机器上启动Server和Worker两个进程,而一个Worker进程中可以包含多个用于训练的线程。
如图1所示,参数服务器是分布式训练领域普遍采用的编程架构,主要包含Server和Worker两个部分,其中Server负责参数的存储和更新,而Worker负责训练。飞桨的参数服务器功能也是基于这种经典的架构进行设计和开发的,同时在这基础上进行了SGD(Stochastic Gradient Descent)算法的创新(Geometric Stochastic Gradient Descent)。当前经过大量的实验验证,最佳的方案是每台机器上启动Server和Worker两个进程,而一个Worker进程中可以包含多个用于训练的线程。
<p
align=
"center"
>
<p
align=
"center"
>
...
...
readme.md
浏览文件 @
1b2a89f6
...
@@ -131,7 +131,7 @@ python -m paddlerec.run -m ./models/rank/dnn/config.yaml -e single
...
@@ -131,7 +131,7 @@ python -m paddlerec.run -m ./models/rank/dnn/config.yaml -e single
### 背景介绍
### 背景介绍
*
[
推荐系统
](
doc/rec_background.md
)
*
[
推荐系统
](
doc/rec_background.md
)
*
[
分布式
-参数服务器
](
doc/ps_background.md
)
*
[
分布式
训练
](
doc/ps_background.md
)
### 新手教程
### 新手教程
*
[
环境要求
](
#环境要求
)
*
[
环境要求
](
#环境要求
)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}