Merge branch 'master' into add_lr
Showing
doc/development.md
0 → 100644
{kind=link}
{kind=link}
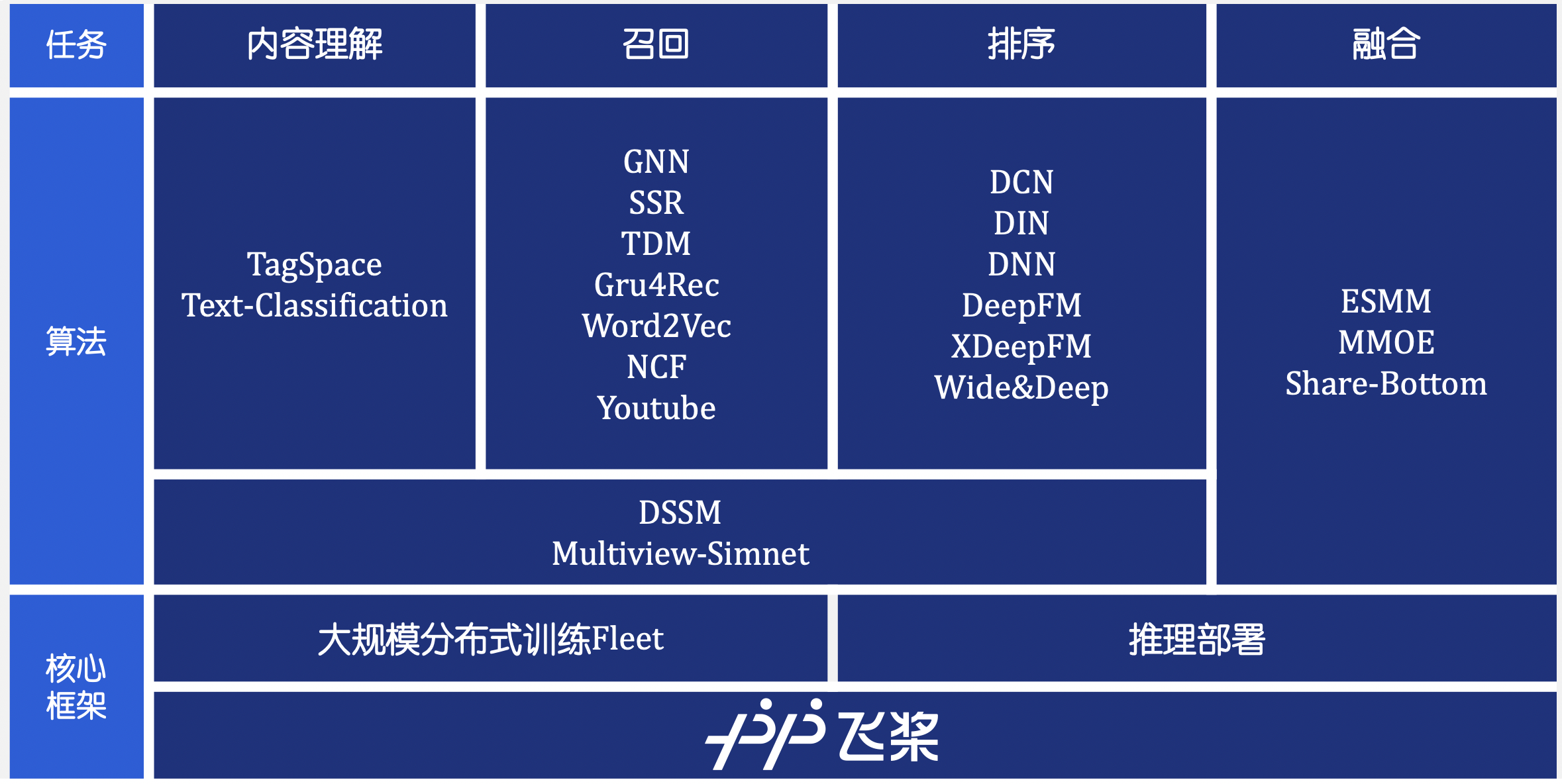
| W: | H:
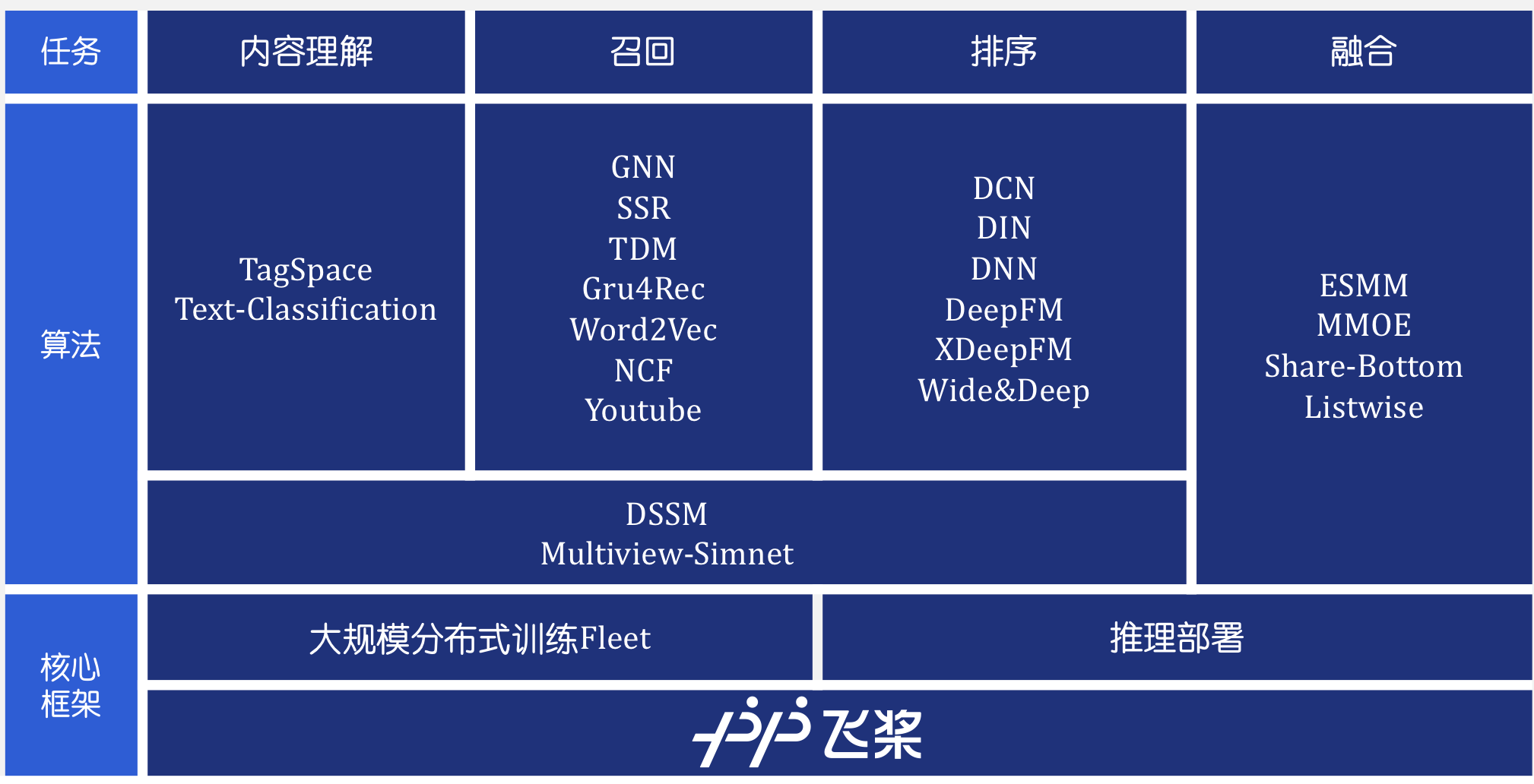
| W: | H:
文件已移动
文件已移动
文件已移动
文件已移动
models/multitask/mmoe/data/run.sh
0 → 100644
| W: | H:
| W: | H: