“c167df2f60d08085167cdc9431101f4b45a8a019”上不存在“ppocr/git@gitcode.net:s920243400/PaddleOCR.git”
add ppocr_v3_introduction
Showing
doc/ppocr_v3/LKPAN.png
0 → 100644
{kind=link}
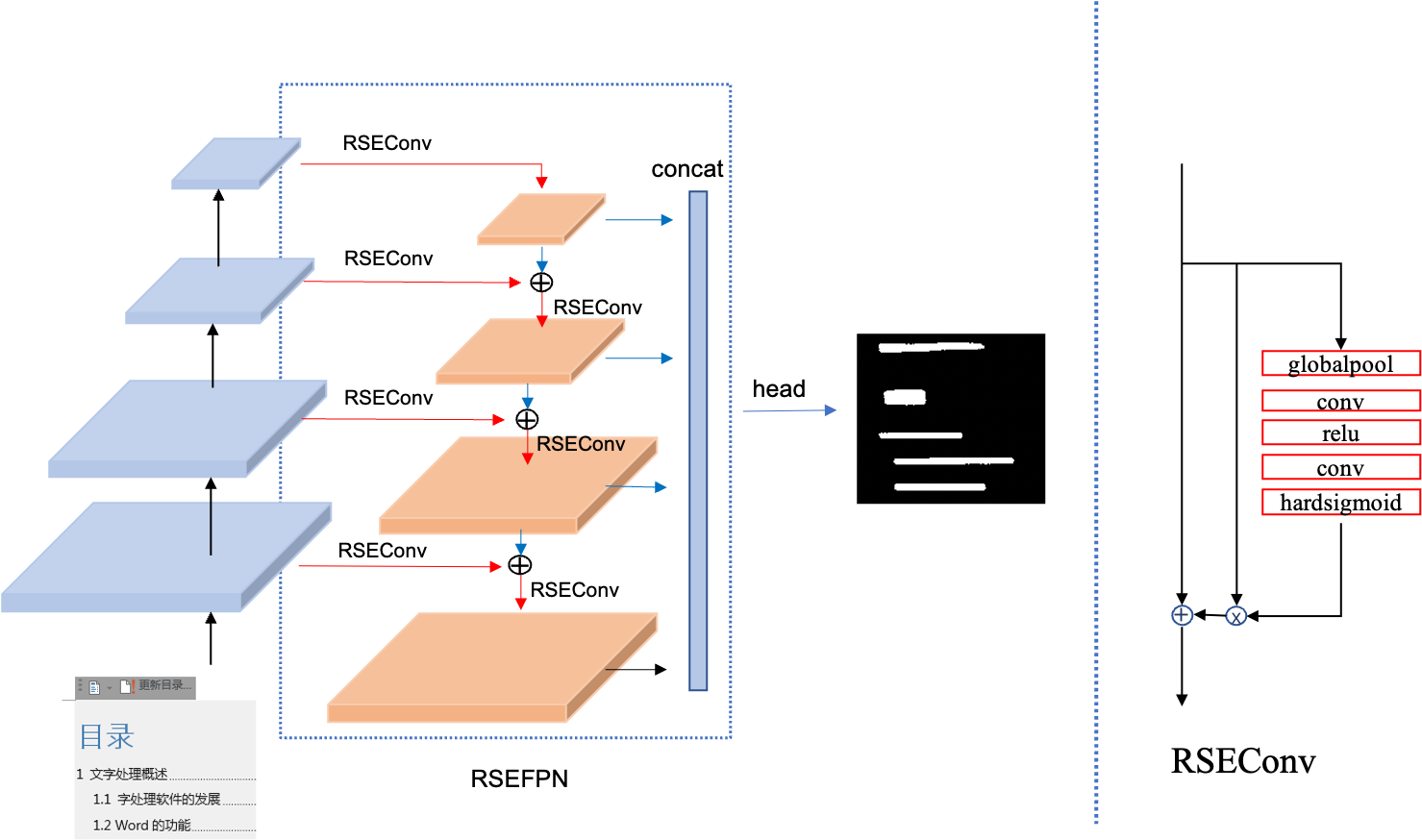
125.7 KB
doc/ppocr_v3/RSEFPN.png
0 → 100644
{kind=link}
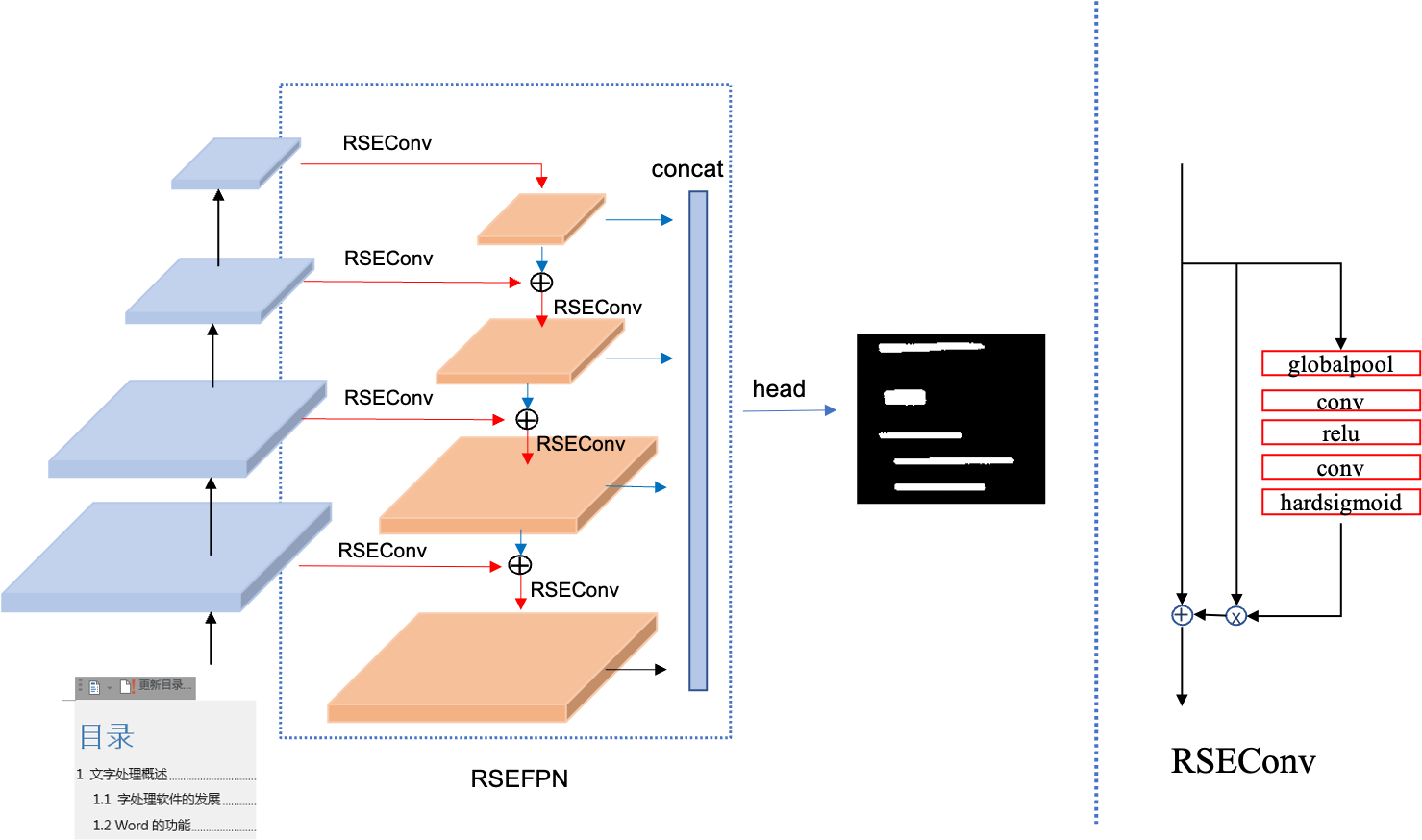
125.7 KB