Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleOCR
提交
cc6cd2ae
P
PaddleOCR
项目概览
PaddlePaddle
/
PaddleOCR
大约 2 年 前同步成功
通知
1557
Star
32965
Fork
6643
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
108
列表
看板
标记
里程碑
合并请求
7
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
108
Issue
108
列表
看板
标记
里程碑
合并请求
7
合并请求
7
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
cc6cd2ae
编写于
5月 10, 2022
作者:
M
MissPenguin
提交者:
GitHub
5月 10, 2022
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #6243 from xiaolao/dygraph
[CherryPick] Add documents for PaddleCloud
上级
33162f53
a54fef9f
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
341 addition
and
0 deletion
+341
-0
README.md
README.md
+1
-0
README_ch.md
README_ch.md
+1
-0
deploy/paddlecloud/README.md
deploy/paddlecloud/README.md
+339
-0
deploy/paddlecloud/images/architecture.jpeg
deploy/paddlecloud/images/architecture.jpeg
+0
-0
deploy/paddlecloud/images/paddlecloud.png
deploy/paddlecloud/images/paddlecloud.png
+0
-0
未找到文件。
README.md
浏览文件 @
cc6cd2ae
...
...
@@ -106,6 +106,7 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
-
[
Serving
](
./deploy/pdserving/README.md
)
-
[
Mobile
](
./deploy/lite/readme.md
)
-
[
Paddle2ONNX
](
./deploy/paddle2onnx/readme.md
)
-
[
PaddleCloud
](
./deploy/paddlecloud/README.md
)
-
[
Benchmark
](
./doc/doc_en/benchmark_en.md
)
-
[
PP-Structure 🔥
](
./ppstructure/README.md
)
-
[
Quick Start
](
./ppstructure/docs/quickstart_en.md
)
...
...
README_ch.md
浏览文件 @
cc6cd2ae
...
...
@@ -108,6 +108,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
[
服务化部署
](
./deploy/pdserving/README_CN.md
)
-
[
端侧部署
](
./deploy/lite/readme.md
)
-
[
Paddle2ONNX模型转化与预测
](
./deploy/paddle2onnx/readme.md
)
-
[
云上飞桨部署工具
](
./deploy/paddlecloud/README.md
)
-
[
Benchmark
](
./doc/doc_ch/benchmark.md
)
-
[
PP-Structure文档分析🔥
](
./ppstructure/README_ch.md
)
-
[
快速开始
](
./ppstructure/docs/quickstart.md
)
...
...
deploy/paddlecloud/README.md
0 → 100644
浏览文件 @
cc6cd2ae
# 云上飞桨部署工具
[
云上飞桨(PaddleCloud)
](
https://github.com/PaddlePaddle/PaddleCloud
)
是面向飞桨框架及其模型套件的部署工具,
为用户提供了模型套件Docker化部署和Kubernetes集群部署两种方式,可以满足不同场景与环境的部署需求。
本章节我们将使用PaddleCloud提供的OCR标准镜像以及云原生组件来训练和部署PP-OCRv3识别模型。
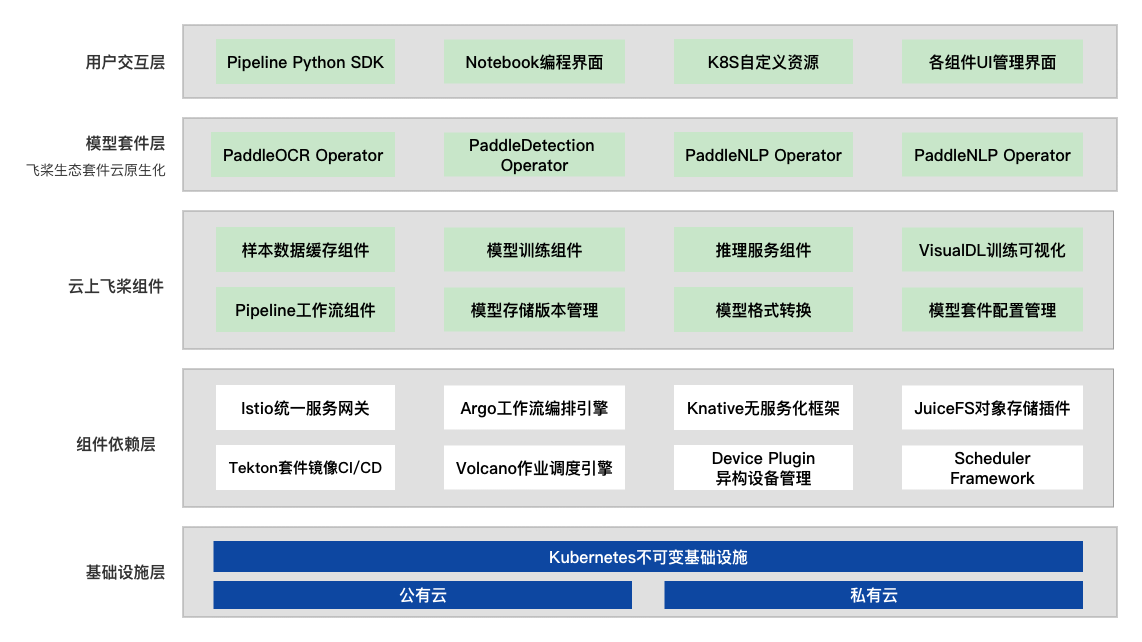
## 云上飞桨部署工具的优势
<div
align=
"center"
>
<img
src=
"./images/paddlecloud.png"
title=
"architecture"
width=
"80%"
height=
"80%"
alt=
""
>
</div>
-
**模型套件Docker镜像大礼包。**
PaddleCloud为用户提供了飞桨模型套件Docker镜像大礼包,这些镜像中包含运行模型套件案例的所有依赖并能持续更新,支持异构硬件环境和常见CUDA版本、开箱即用。
-
**具有丰富的云上飞桨组件。**
云上飞桨具有丰富的云原生功能组件,包括样本数据缓存组件、分布式训练组件、推理服务组件等,使用这些组件用户可以快速地在Kubernetes集群上进行训练和部署工作。
-
**功能强大的自运维能力。**
云上飞桨组件基于Kubernetes的Operator机制提供了功能强大的自运维能力,如训练组件支持多种架构模式并具有分布式容错与弹性训练的能力,推理服务组件支持自动扩缩容与蓝绿发版等。
-
**针对飞桨框架的定制优化。**
除了部署便捷与自运维的优势,PaddleCloud还针对飞桨框架进行了正对性优化,如通过缓存样本数据来加速云上飞桨分布式训练作业、基于飞桨框架和调度器的协同设计来优化集群GPU利用率等。
## 1. PP-OCRv3 Docker化部署
PaddleCloud基于
[
Tekton
](
https://github.com/tektoncd/pipeline
)
为OCR模型套件提供了镜像持续构建的能力,并支持CPU、GPU以及常见CUDA版本的镜像。
您可以查看
[
PaddleOCR 镜像仓库
](
https://hub.docker.com/repository/docker/paddlecloud/paddleocr
)
来获取所有的镜像列表。
同时我们也将PP-OCRv3识别模型的训练与推理实战案例放置到了AI Studio平台上,您可以点击
[
PP-OCRv3识别训推一体项目实战
](
https://aistudio.baidu.com/aistudio/projectdetail/3916206?channelType=0&channel=0
)
在平台上快速体验。
> **适用场景**:本地测试开发环境、单机部署环境。
### 1.1 安装Docker
如果您所使用的机器上还没有安装 Docker,您可以参考
[
Docker 官方文档
](
https://docs.docker.com/get-docker/
)
来进行安装。
如果您需要使用支持 GPU 版本的镜像,则还需安装好NVIDIA相关驱动和
[
nvidia-docker
](
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
)
。
**注意**
:如果您使用的是Windows系统,需要开启
[
WSL2(Linux子系统功能)功能
](
https://docs.microsoft.com/en-us/windows/wsl/install
)
。
### 1.2 启动容器
**使用CPU版本的Docker镜像**
```
bash
# 这是加上参数 --shm-size=32g 是为了防止容器里内存不足
docker run
--name
ppocr
-v
$PWD
:/mnt
-p
8888:8888
-it
--shm-size
=
32g paddlecloud/paddleocr:2.5-cpu-efbb0a /bin/bash
```
**使用GPU版本的Docker镜像**
```
bash
docker run
--name
ppocr
--runtime
=
nvidia
-v
$PWD
:/mnt
-p
8888:8888
-it
--shm-size
=
32g paddlecloud/paddleocr:2.5-gpu-cuda10.2-cudnn7-efbb0a /bin/bash
```
进入容器内,则可进行 PP-OCRv3 模型的训练和部署工作。
### 1.3 准备训练数据
本教程以HierText数据集为例,HierText是第一个具有自然场景和文档中文本分层注释的数据集。
该数据集包含从 Open Images 数据集中选择的 11639 张图像,提供高质量的单词 (~1.2M)、行和段落级别的注释。
我们已经将数据集上传到百度云对象存储(BOS),您可以通过运行如下指令,完成数据集的下载和解压操作:
```
bash
# 下载数据集
$
wget
-P
/mnt https://paddleflow-public.hkg.bcebos.com/ppocr/hiertext1.tar
# 解压数据集
$
tar
xf /mnt/hiertext1.tar
-C
/mnt
&&
mv
/mnt/hiertext1 /mnt/hiertext
```
运行上述命令后,在
`/mnt`
目录下包含以下文件:
```
/mnt/hiertext
└─ train/ HierText训练集数据
└─ validation/ HierText验证集数据
└─ label_hiertext_train.txt HierText训练集的行标注
└─ label_hiertext_val.txt HierText验证集的行标注
```
### 1.4 修改配置文件
PP-OCRv3模型配置文件位于
`/home/PaddleOCR/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`
,需要修改的配置如下:
-
修改训练数据配置:
```
yaml
Train
:
dataset
:
name
:
SimpleDataSet
data_dir
:
./train_data/icdar2015/text_localization/
label_file_list
:
-
./train_data/icdar2015/text_localization/train_icdar2015_label.txt
```
修改为:
```
yaml
Train
:
dataset
:
name
:
SimpleDataSet
data_dir
:
/mnt/
label_file_list
:
-
/mnt/hiertext/label_hiertext_train.txt
```
-
修改验证数据配置:
```
yaml
Eval
:
dataset
:
name
:
SimpleDataSet
data_dir
:
./train_data/icdar2015/text_localization/
label_file_list
:
-
./train_data/icdar2015/text_localization/test_icdar2015_label.txt
```
修改为:
```
yaml
Eval
:
dataset
:
name
:
SimpleDataSet
data_dir
:
/mnt/
label_file_list
:
-
/mnt/hiertext/label_hiertext_val.txt
```
### 1.5 启动训练
下载PP-OCRv3的蒸馏预训练模型并进行训练的方式如下
```
bash
# 下载预训练模型到/home/PaddleOCR/pre_train文件夹下
$
mkdir
/home/PaddleOCR/pre_train
$
wget
-P
/home/PaddleOCR/pre_train https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
$
tar
xf /home/PaddleOCR/pre_train/ch_PP-OCRv3_det_distill_train.tar
-C
/home/PaddleOCR/pre_train/
```
启动训练,训练模型默认保存在
`output`
目录下,加载PP-OCRv3检测预训练模型。
```
bash
# 这里以 GPU 训练为例,使用 CPU 进行训练的话,需要指定参数 Global.use_gpu=false
python3 tools/train.py
-c
configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
-o
Global.save_model_dir
=
./output/ Global.pretrained_model
=
./pre_train/ch_PP-OCRv3_det_distill_train/best_accuracy
```
如果要使用多GPU分布式训练,请使用如下命令:
```
bash
# 启动训练,训练模型默认保存在output目录下,--gpus '0,1,2,3'表示使用0,1,2,3号GPU训练
python3
-m
paddle.distributed.launch
--log_dir
=
./debug/
--gpus
'0,1,2,3'
tools/train.py
-c
configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
-o
Global.save_model_dir
=
./output/ Global.pretrained_model
=
./pre_train/ch_PP-OCRv3_det_distill_train/best_accuracy
```
### 1.6 模型评估
训练过程中保存的模型在output目录下,包含以下文件:
```
best_accuracy.states
best_accuracy.pdparams # 默认保存最优精度的模型参数
best_accuracy.pdopt # 默认保存最优精度的优化器相关参数
latest.states
latest.pdparams # 默认保存的最新模型参数
latest.pdopt # 默认保存的最新模型的优化器相关参数
```
其中,best_accuracy是保存的最优模型,可以直接使用该模型评估
```
bash
# 进行模型评估
cd
/home/PaddleOCR/
python3 tools/eval.py
-c
configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
-o
Global.checkpoints
=
./output/best_accuracy
```
## 2. PP-OCRv3云端部署
PaddleCloud基于Kubernetes的Operator机制为您提供了多个功能强大的云原生组件,如样本数据缓存组件、分布式训练组件、 以及模型推理服务组件,
使用这些组件您可以快速地在云上进行分布式训练和模型服务化部署。更多关于PaddleCloud云原生组件的内容,请参考文档
[
PaddleCloud架构概览
](
https://github.com/PaddlePaddle/PaddleCloud/blob/main/docs/zh_CN/paddlecloud-overview.md
)
。
> **适用场景**:基于Kubernetes的多机部署环境。
### 2.1 安装云上飞桨组件
**环境要求**
-
[
Kubernetes v1.16+
](
https://kubernetes.io/zh/
)
-
[
kubectl
](
https://kubernetes.io/docs/tasks/tools/
)
-
[
Helm
](
https://helm.sh/zh/docs/intro/install/
)
如果您没有Kubernetes环境,可以使用MicroK8S在本地搭建环境,更多详情请参考
[
MicroK8S官方文档
](
https://microk8s.io/docs/getting-started
)
。
使用Helm一键安装所有组件和所有依赖
```
bash
# 添加PaddleCloud Chart仓库
$
helm repo add paddlecloud https://paddleflow-public.hkg.bcebos.com/charts
$
helm repo update
# 安装云上飞桨组件
$
helm
install
pdc paddlecloud/paddlecloud
--set
tags.all-dep
=
true
--namespace
paddlecloud
--create-namespace
# 检查所有云上飞桨组件是否成功启动,命名空间下的所有Pod都为Runing状态则安装成功。
$
kubectl get pods
-n
paddlecloud
NAME READY STATUS RESTARTS AGE
pdc-hostpath-5b6bd6787d-bxvxg 1/1 Running 0 10h
juicefs-csi-node-pkldt 3/3 Running 0 10h
juicefs-csi-controller-0 3/3 Running 0 10h
pdc-paddlecloud-sampleset-767bdf6947-pb6zm 1/1 Running 0 10h
pdc-paddlecloud-paddlejob-7cc8b7bfc6-7gqnh 1/1 Running 0 10h
pdc-minio-7cc967669d-824q5 1/1 Running 0 10h
pdc-redis-master-0 1/1 Running 0 10h
```
更多安装参数请参考
[
PaddleCloud安装指南
](
https://github.com/PaddlePaddle/PaddleCloud/blob/main/docs/zh_CN/installation.md
)
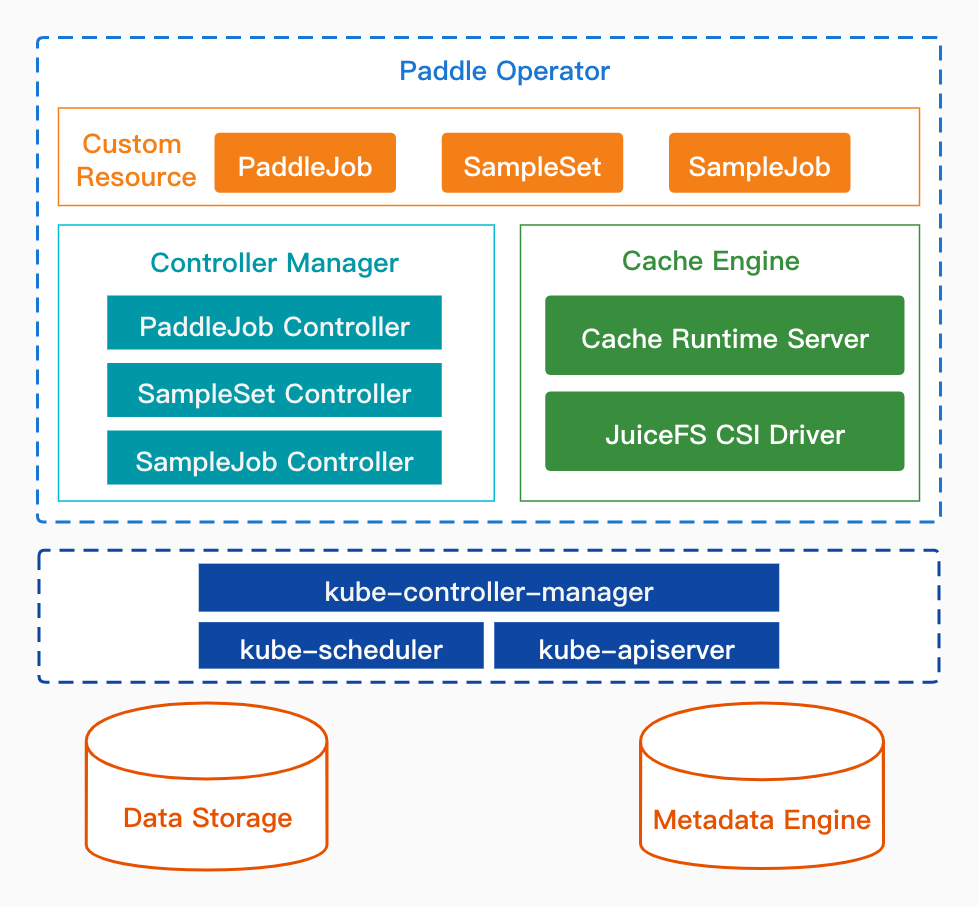
### 2.2 云原生组件介绍
<div
align=
"center"
>
<img
src=
"./images/architecture.jpeg"
title=
"architecture"
width=
"60%"
height=
"60%"
alt=
""
>
</div>
-
**数据缓存组件。**
数据缓存组件使用JuiceFS作为缓存引擎,能够将远程样本数据缓存到训练集群本地,大幅加速云上飞桨分布式训练作业。
-
**分布式训练组件。**
分布式训练组件支持参数服务器(PS)与集合通信(Collective)两种架构模式,方便用户在云上快速运行飞桨分布式训练作业。
以下内容我们将使用这两个云原生组件来在Kubernetes集群中部署PP-OCRv3识别模型的训练作业。
### 2.3 准备hiertext数据集
使用数据缓存组件来准备数据集,编写SampleSet Yaml文件如下:
```
yaml
# hiertext.yaml
apiVersion
:
batch.paddlepaddle.org/v1alpha1
kind
:
SampleSet
metadata
:
name
:
hiertext
namespace
:
paddlecloud
spec
:
partitions
:
1
source
:
uri
:
bos://paddleflow-public.hkg.bcebos.com/ppocr/hiertext
secretRef
:
name
:
none
secretRef
:
name
:
data-center
```
然后在命令行中,使用kubectl执行如下命令。
```
bash
# 创建hiertext数据集
$
kubectl apply
-f
hiertext.yaml
sampleset.batch.paddlepaddle.org/hiertext created
# 查看数据集的状态
$
kubectl get sampleset hiertext
-n
paddlecloud
NAME TOTAL SIZE CACHED SIZE AVAIL SPACE RUNTIME PHASE AGE
hiertext 3.3 GiB 3.2 GiB 12 GiB 1/1 Ready 11m
```
### 2.4 训练PP-OCRv3模型
使用训练组件在Kubernetes集群上训练PP-OCRv3模型,编写PaddleJob Yaml文件如下:
```
yaml
# ppocrv3.yaml
apiVersion
:
batch.paddlepaddle.org/v1
kind
:
PaddleJob
metadata
:
name
:
ppocrv3
namespace
:
paddlecloud
spec
:
cleanPodPolicy
:
OnCompletion
sampleSetRef
:
name
:
hiertext
namespace
:
paddlecloud
mountPath
:
/mnt/hiertext
worker
:
replicas
:
1
template
:
spec
:
containers
:
-
name
:
ppocrv3
image
:
paddlecloud/paddleocr:2.5-gpu-cuda10.2-cudnn7-efbb0a
command
:
-
/bin/bash
args
:
-
"
-c"
-
>
mkdir /home/PaddleOCR/pre_train &&
wget -P ./pre_train https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar &&
tar xf ./pre_train/ch_PP-OCRv3_det_distill_train.tar -C ./pre_train/ &&
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o
Train.dataset.data_dir=/mnt/
Train.dataset.label_file_list=[\"/mnt/hiertext/label_hiertext_train.txt\"]
Eval.dataset.data_dir=/mnt/
Eval.dataset.label_file_list=[\"/mnt/hiertext/label_hiertext_val.txt\"]
Global.save_model_dir=./output/
Global.pretrained_model=./pre_train/ch_PP-OCRv3_det_distill_train/best_accuracy
resources
:
limits
:
nvidia.com/gpu
:
1
volumeMounts
:
# 添加 shared memory 挂载以防止缓存出错
-
mountPath
:
/dev/shm
name
:
dshm
volumes
:
-
name
:
dshm
emptyDir
:
medium
:
Memory
```
本案例采用GPU进行训练,如果您只有CPU机器,则可以将镜像替换成CPU版本
`paddlecloud/paddleocr:2.5-cpu-efbb0a`
,并在args中加上参数
`Global.use_gpu=false`
。
```
bash
# 创建PaddleJob训练模型
$
kubectl apply
-f
ppocrv3.yaml
paddlejob.batch.paddlepaddle.org/ppocrv3 created
# 查看PaddleJob状态
$
kubectl get pods
-n
paddlecloud
-l
paddle-res-name
=
ppocrv3-worker-0
NAME READY STATUS RESTARTS AGE
ppocrv3-worker-0 1/1 Running 0 4s
# 查看训练日志
$
kubectl logs
-f
ppocrv3-worker-0
-n
paddlecloud
```
## 更多资源
欢迎关注
[
云上飞桨项目PaddleCloud
](
https://github.com/PaddlePaddle/PaddleCloud
)
,我们为您提供了飞桨模型套件标准镜像以及全栈的云原生模型套件部署组件,如您有任何关于飞桨模型套件的部署问题,请联系我们。
如果你发现任何PaddleCloud存在的问题或者是建议, 欢迎通过
[
GitHub Issues
](
https://github.com/PaddlePaddle/PaddleCloud/issues
)
给我们提issues。
\ No newline at end of file
deploy/paddlecloud/images/architecture.jpeg
0 → 100644
浏览文件 @
cc6cd2ae
121.8 KB
deploy/paddlecloud/images/paddlecloud.png
0 → 100644
浏览文件 @
cc6cd2ae
113.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}