update doc for case
Showing
applications/imgs/det.png
已删除
100644 → 0
{kind=link}
65.1 KB
applications/imgs/rec.png
已删除
100644 → 0
{kind=link}

13.4 KB
applications/imgs/sys_res.png
已删除
100644 → 0
{kind=link}
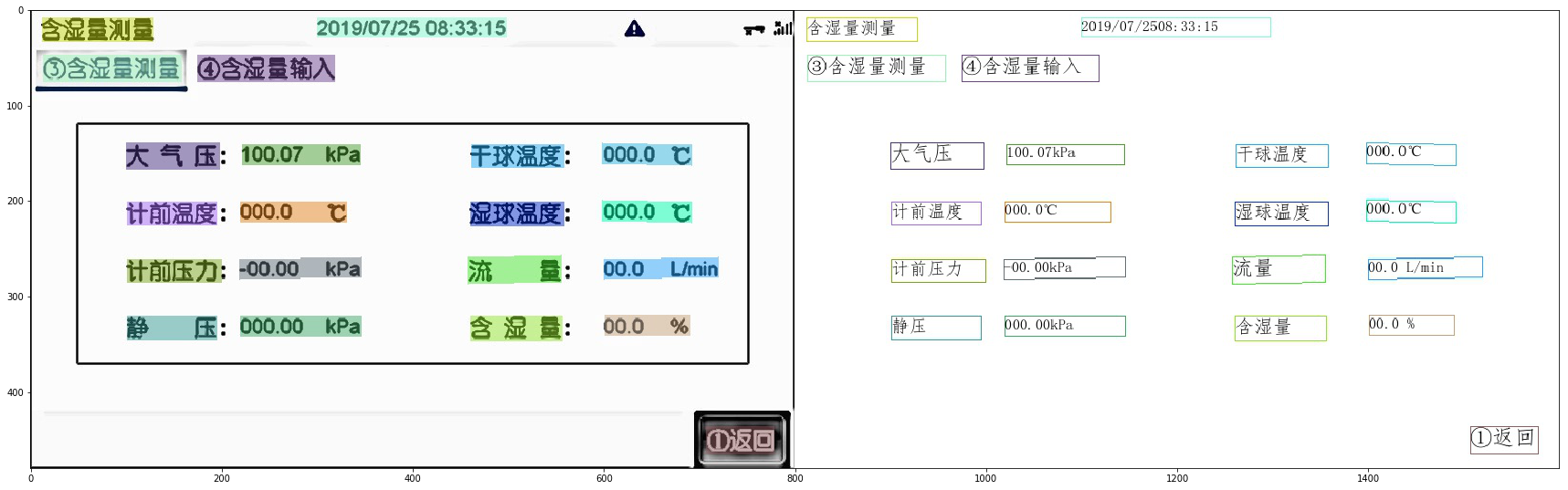
284.6 KB
65.1 KB
13.4 KB
284.6 KB