diff --git a/applications/imgs/det.png b/applications/imgs/det.png
deleted file mode 100644
index 6f21ee170ed272e6ae9c3ef475f60855a064cbbc..0000000000000000000000000000000000000000
Binary files a/applications/imgs/det.png and /dev/null differ
diff --git a/applications/imgs/rec.png b/applications/imgs/rec.png
deleted file mode 100644
index c9cd069e42198947cf65aeb14923765be296ab5e..0000000000000000000000000000000000000000
Binary files a/applications/imgs/rec.png and /dev/null differ
diff --git a/applications/imgs/sys_res.png b/applications/imgs/sys_res.png
deleted file mode 100644
index 6a9305c62d529f87a9ab063f9933b686c8c63228..0000000000000000000000000000000000000000
Binary files a/applications/imgs/sys_res.png and /dev/null differ
diff --git "a/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md" "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
index 6b1ea243067b1897ff7a7d0590ae7a5a31d50246..b85bf56daf8fb217edc6d42276d395192790c32f 100644
--- "a/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
+++ "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
@@ -23,15 +23,15 @@
- [7. PaddleServing部署](#7-PaddleServing部署)
-# 1. 项目背景及意义
+## 1. 项目背景及意义
目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高,针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。
该项目以国家质量基础(NQI)为准绳,充分利用大数据、云计算、物联网等高新技术,构建覆盖计量端、实验室端、数据端和硬件端的完整计量解决方案,解决传统计量校准中存在的难题,拓宽计量检测服务体系和服务领域;解决无数传接口或数传接口不统一、不公开的计量设备,以及计量设备所处的环境比较恶劣,不适合人工读取数据。通过OCR技术实现远程计量,引领计量行业向智慧计量转型和发展。
-# 2. 项目内容
+## 2. 项目内容
本项目基于PaddleOCR开源套件,以PP-OCRv3检测和识别模型为基础,针对液晶屏读数识别场景进行优化。
-# 3. 安装环境
+## 3. 安装环境
```python
# 首先git官方的PaddleOCR项目,安装需要的依赖
@@ -41,16 +41,16 @@ cd PaddleOCR
pip install -r requirements.txt
```
-# 4. 文字检测
+## 4. 文字检测
文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法。本项目基于PP-OCRv3算法进行优化。
-## 4.1 PP-OCRv3检测算法介绍
+### 4.1 PP-OCRv3检测算法介绍
PP-OCRv3检测模型是对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了①传统的Teacher指导Student的标准蒸馏与 ②Students网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
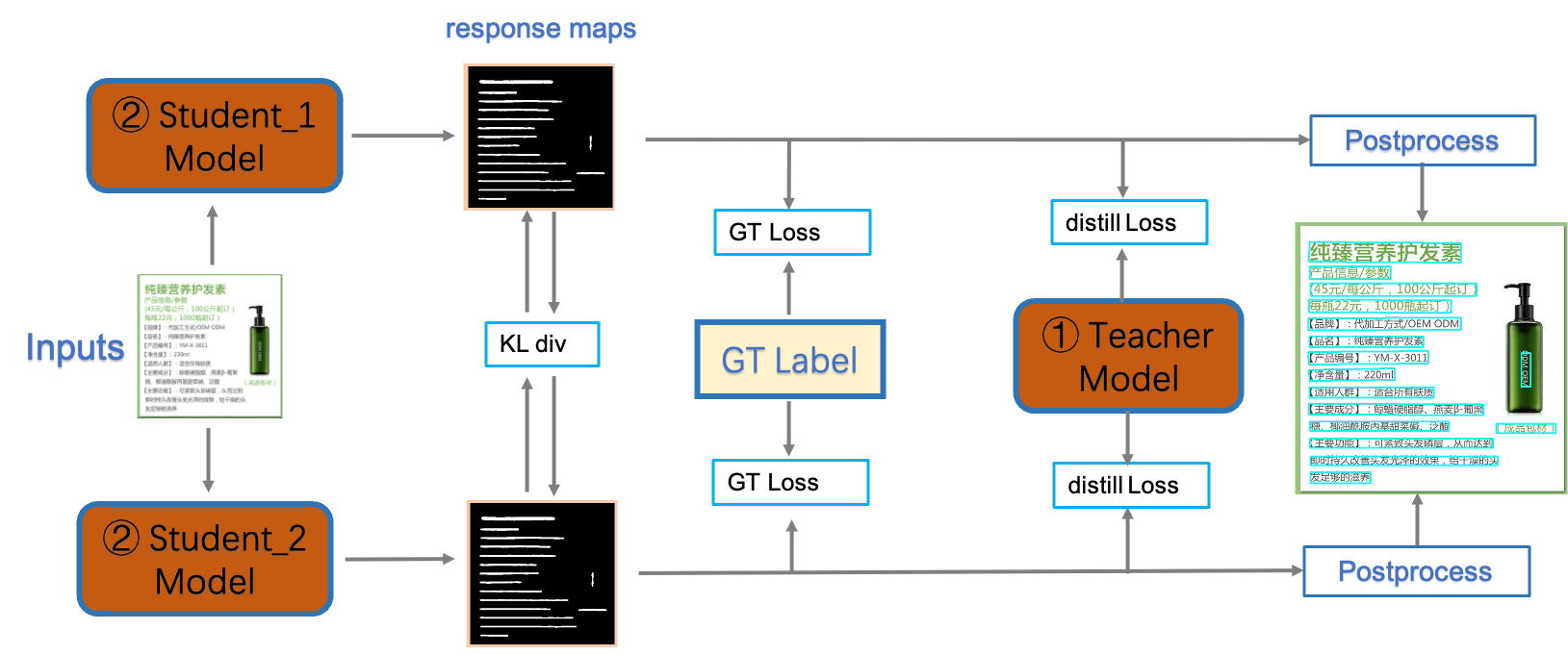
详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#2)
-## 4.2 数据准备
+### 4.2 数据准备
[计量设备屏幕字符检测数据集](https://aistudio.baidu.com/aistudio/datasetdetail/127845)数据来源于实际项目中各种计量设备的数显屏,以及在网上搜集的一些其他数显屏,包含训练集755张,测试集355张。
```python
@@ -83,11 +83,11 @@ def get_one_image(train):
get_one_image(train)
```
-
+
-## 4.3 模型训练
+### 4.3 模型训练
-### 4.3.1 预训练模型直接评估
+#### 4.3.1 预训练模型直接评估
下载我们需要的PP-OCRv3检测预训练模型,更多选择请自行选择其他的[文字检测模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#1-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E6%A8%A1%E5%9E%8B)
```python
@@ -110,8 +110,8 @@ python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Globa
|---|---------------------------|---|
| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
-### 4.3.2 预训练模型直接finetune
-#### 修改配置文件
+#### 4.3.2 预训练模型直接finetune
+##### 修改配置文件
我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
```
epoch:100
@@ -123,7 +123,7 @@ learning_rate: 0.00025
num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
```
-#### 开始训练
+##### 开始训练
使用我们上面修改的配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,训练命令如下:
```python
@@ -144,7 +144,7 @@ python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Globa
| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
-### 4.3.3 基于预训练模型Finetune_student模型
+#### 4.3.3 基于预训练模型Finetune_student模型
我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
```
@@ -177,7 +177,7 @@ python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o G
| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
-### 4.3.4 基于预训练模型Finetune_teacher模型
+#### 4.3.4 基于预训练模型Finetune_teacher模型
首先需要从提供的预训练模型best_accuracy.pdparams中提取teacher参数,组合成适合dml训练的初始化模型,提取代码如下:
@@ -236,7 +236,7 @@ python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Globa
| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.8%|
-### 4.3.5 采用CML蒸馏进一步提升student模型精度
+#### 4.3.5 采用CML蒸馏进一步提升student模型精度
需要从4.3.3和4.3.4训练得到的best_accuracy.pdparams中提取各自代表student和teacher的参数,组合成适合cml训练的初始化模型,提取代码如下:
@@ -298,9 +298,15 @@ python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Globa
| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.8%|
| 4 | 基于2和3训练好的模型fintune |82.7%|
-### 4.3.6 模型导出推理
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+

+
+
+