Merge remote-tracking branch 'upstream/develop' into develop
Showing
README_ch.md
100644 → 100755
doc/doc_ch/FAQ.md
100644 → 100755
{kind=link}
{kind=link}

| W: | H:

| W: | H:
thirdparty/paddleocr-go/README.md
0 → 100644
thirdparty/paddleocr-go/go.mod
0 → 100644
thirdparty/paddleocr-go/go.sum
0 → 100644
{kind=link}
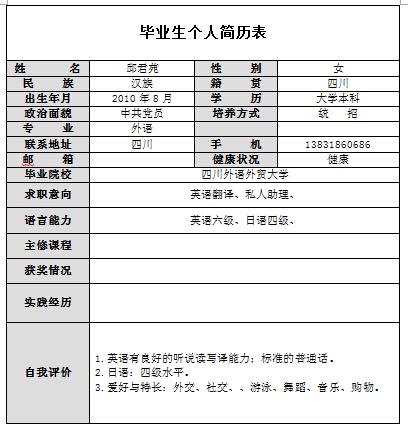
35.9 KB
{kind=link}
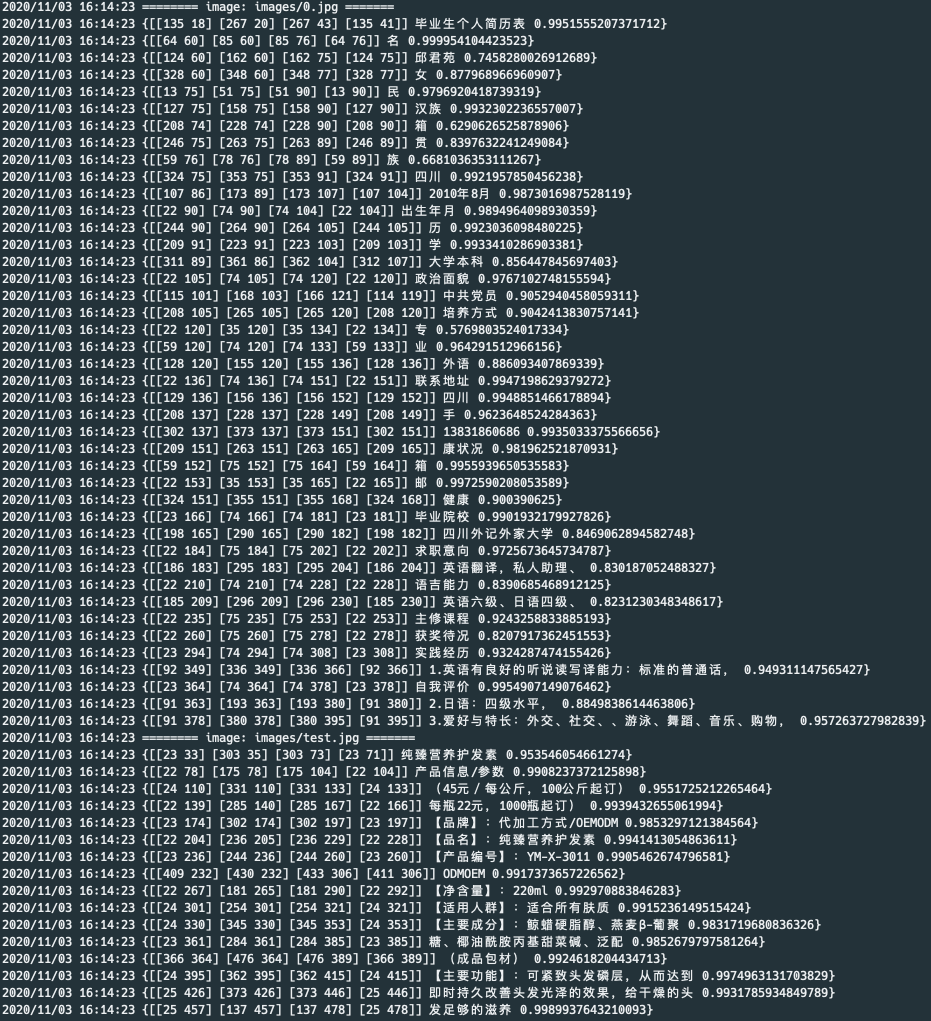
278.8 KB
{kind=link}

97.7 KB
{kind=link}

162.2 KB
{kind=link}
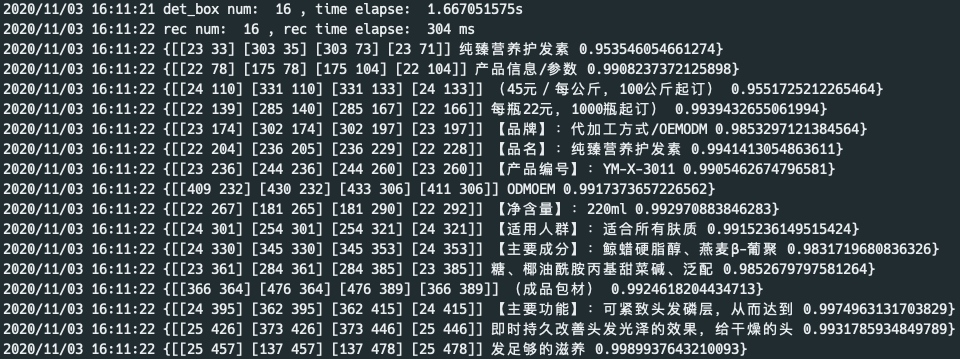
141.3 KB
{kind=link}

47.5 KB