Merge branch 'PaddlePaddle:dygraph' into dygraph
Showing
文件已移动
文件已移动
文件已移动
PTDN/docs/compare_cpp_right.png
0 → 100644
{kind=link}

49.4 KB
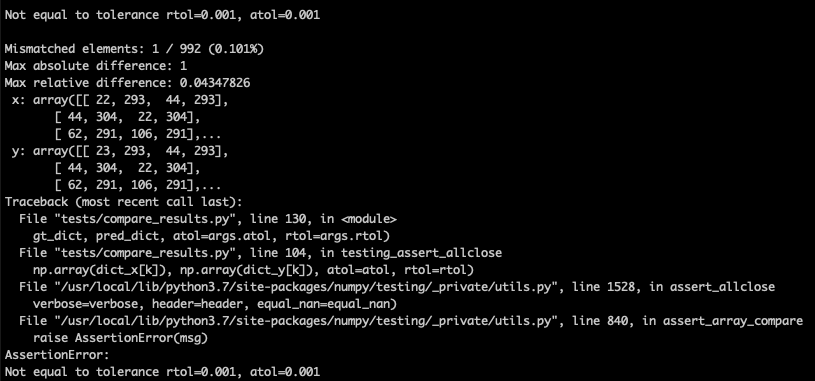
PTDN/docs/compare_cpp_wrong.png
0 → 100644
{kind=link}
63.3 KB
{kind=link}
{kind=link}
{kind=link}
PTDN/docs/install.md
0 → 100644
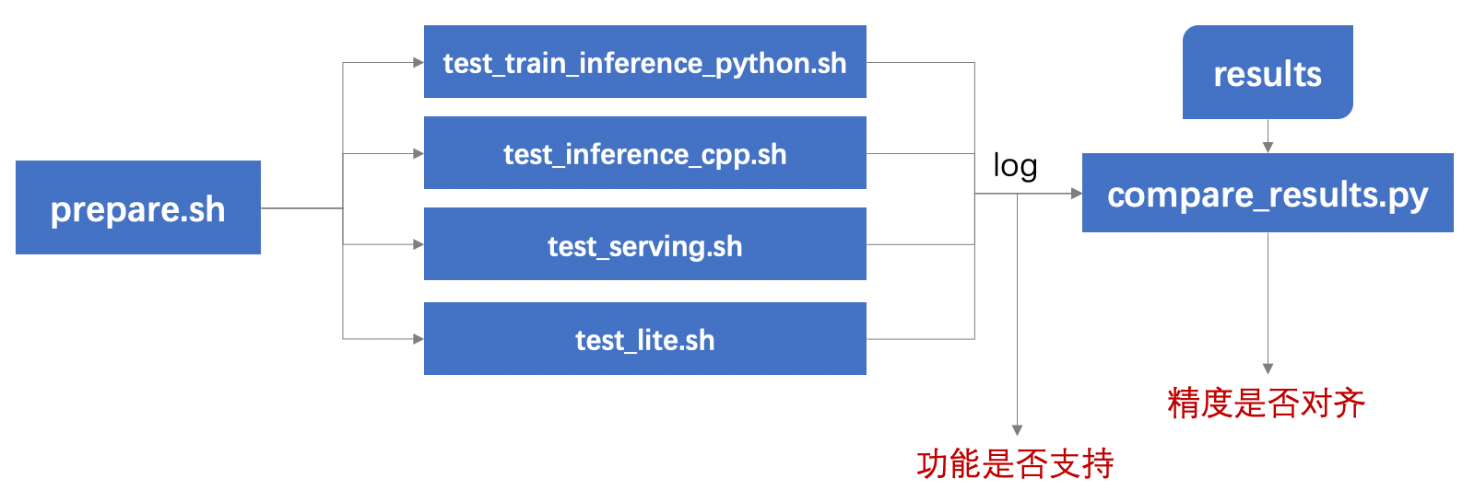
PTDN/docs/test.png
0 → 100644
{kind=link}
223.8 KB
PTDN/docs/test_inference_cpp.md
0 → 100644
PTDN/docs/test_serving.md
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
{kind=link}

| W: | H:

| W: | H:
ppocr/utils/EN_symbol_dict.txt
0 → 100644
| shapely | shapely | ||
| scikit-image==0.17.2 | scikit-image==0.18.3 | ||
| imgaug==0.4.0 | imgaug==0.4.0 | ||
| pyclipper | pyclipper | ||
| lmdb | lmdb | ||
| ... | ... |
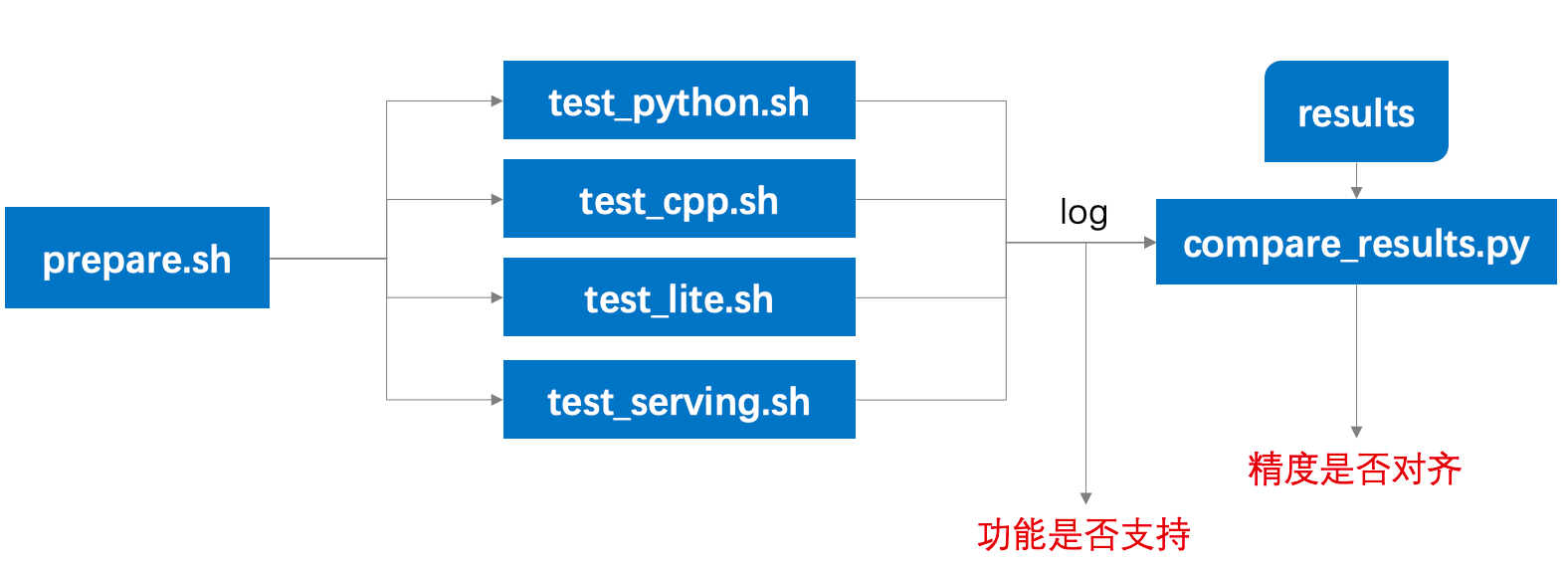
tests/docs/test.png
已删除
100644 → 0
{kind=link}
71.8 KB
tests/docs/test_cpp.md
已删除
100644 → 0