Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
test_tipc/docs/install.md
0 → 100644
test_tipc/docs/lite_auto_log.png
0 → 100644
{kind=link}
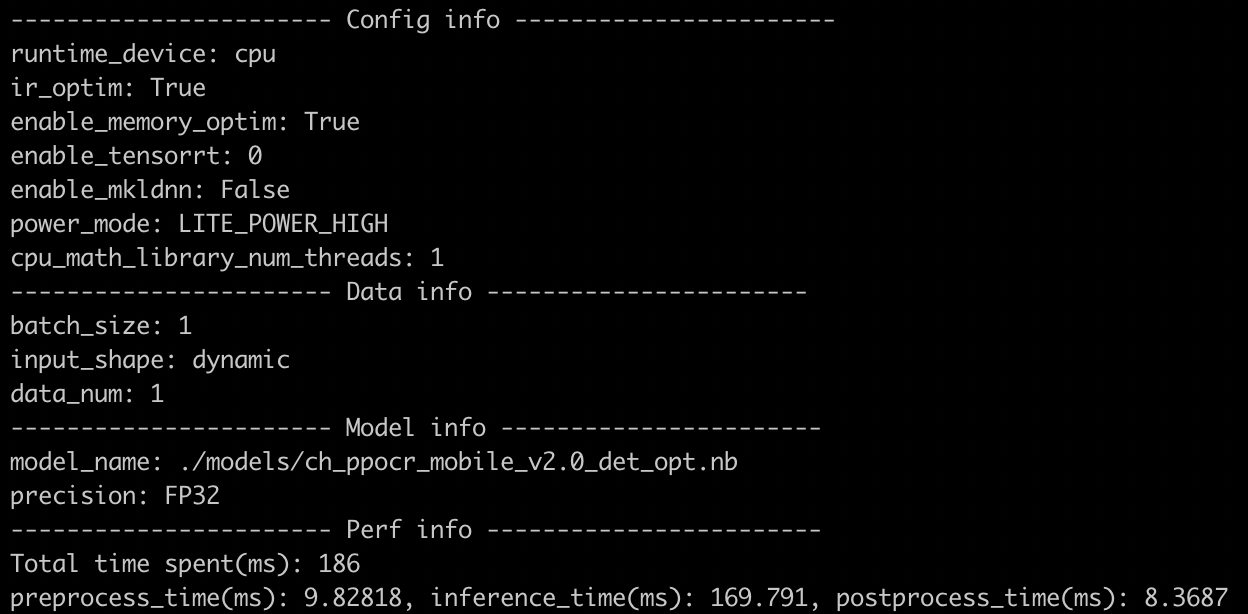
289.9 KB
test_tipc/docs/lite_log.png
0 → 100644
{kind=link}
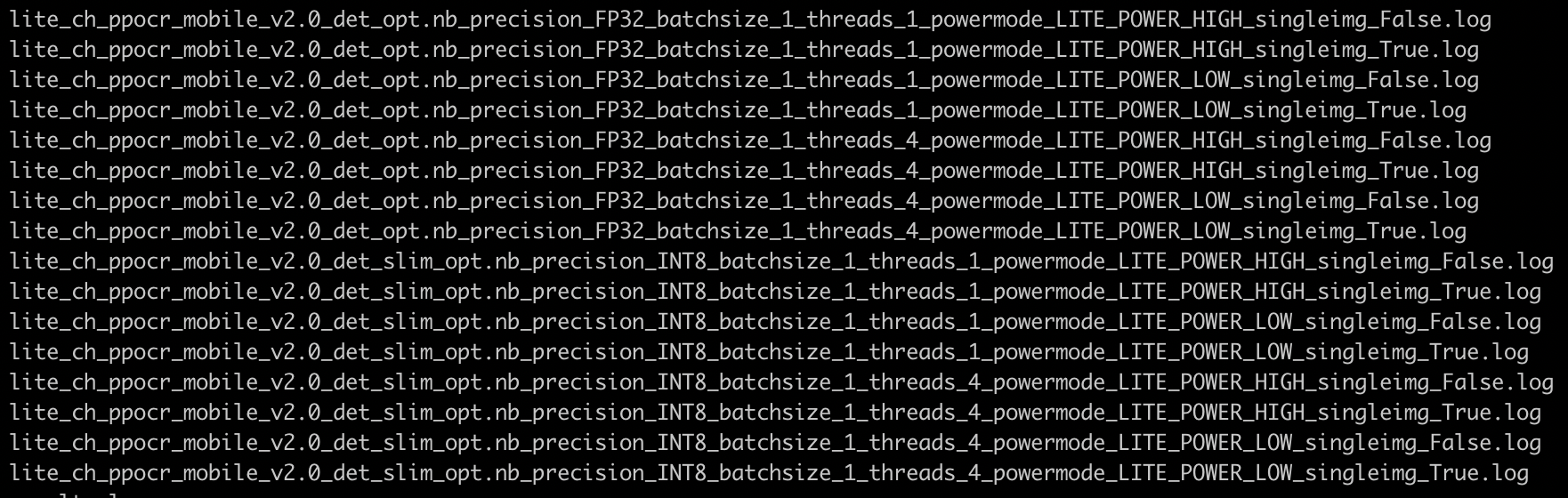
775.5 KB
test_tipc/docs/ssh_termux_ls.png
0 → 100644
{kind=link}

31.6 KB
test_tipc/docs/termux.jpg
0 → 100644
{kind=link}
74.1 KB
{kind=link}
test_tipc/docs/test_lite.md
0 → 100644
test_tipc/docs/test_serving.md
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
test_tipc/test_lite.sh
0 → 100644