Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into update_readme_1215
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/imgs_results/1.jpg
已删除
100644 → 0
{kind=link}

129.4 KB
doc/imgs_results/10.jpg
已删除
100644 → 0
{kind=link}

94.0 KB
doc/imgs_results/11.jpg
已删除
100644 → 0
{kind=link}

236.4 KB
doc/imgs_results/1101.jpg
已删除
100644 → 0
{kind=link}

81.7 KB
doc/imgs_results/1102.jpg
已删除
100644 → 0
{kind=link}

147.1 KB
doc/imgs_results/1103.jpg
已删除
100644 → 0
{kind=link}
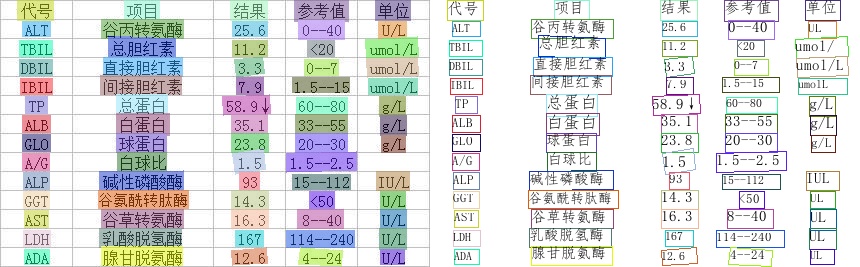
124.2 KB
doc/imgs_results/1104.jpg
已删除
100644 → 0
{kind=link}
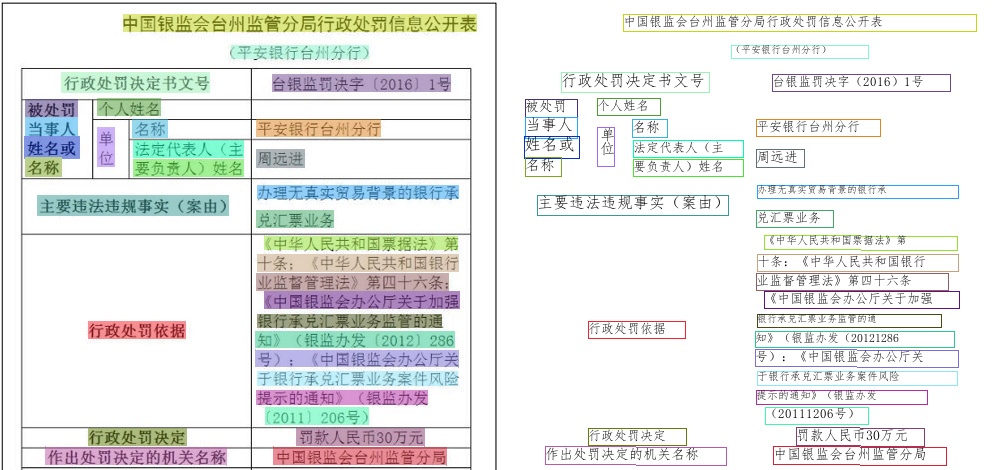
163.6 KB
doc/imgs_results/1105.jpg
已删除
100644 → 0
{kind=link}

136.8 KB
doc/imgs_results/1106.jpg
已删除
100644 → 0
{kind=link}

284.1 KB
doc/imgs_results/1110.jpg
已删除
100644 → 0
{kind=link}

243.6 KB
doc/imgs_results/12.jpg
已删除
100644 → 0
{kind=link}

180.4 KB
doc/imgs_results/13.png
已删除
100644 → 0
{kind=link}

305.0 KB
doc/imgs_results/15.jpg
已删除
100644 → 0
{kind=link}

141.0 KB
doc/imgs_results/16.png
已删除
100644 → 0
{kind=link}

329.1 KB
doc/imgs_results/17.png
已删除
100644 → 0
{kind=link}

201.3 KB
doc/imgs_results/22.jpg
已删除
100644 → 0
{kind=link}

132.5 KB
doc/imgs_results/3.jpg
已删除
100644 → 0
{kind=link}

95.6 KB
doc/imgs_results/4.jpg
已删除
100644 → 0
{kind=link}

105.3 KB
doc/imgs_results/5.jpg
已删除
100644 → 0
{kind=link}

114.7 KB
doc/imgs_results/6.jpg
已删除
100644 → 0
{kind=link}

151.3 KB
doc/imgs_results/7.jpg
已删除
100644 → 0
{kind=link}

60.3 KB
doc/imgs_results/8.jpg
已删除
100644 → 0
{kind=link}

124.9 KB
doc/imgs_results/9.jpg
已删除
100644 → 0
{kind=link}

123.3 KB
{kind=link}

212.5 KB
{kind=link}

63.0 KB
{kind=link}

173.1 KB
{kind=link}
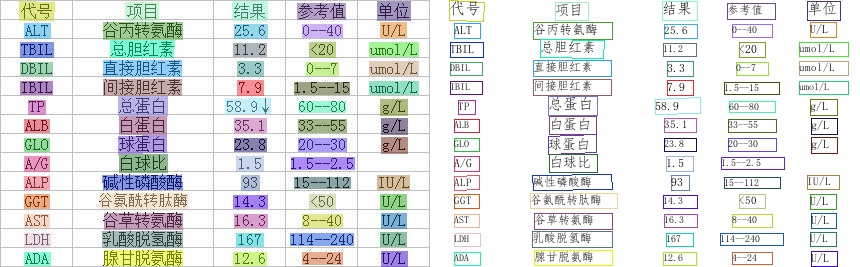
116.8 KB
{kind=link}

160.4 KB
{kind=link}

279.4 KB
{kind=link}
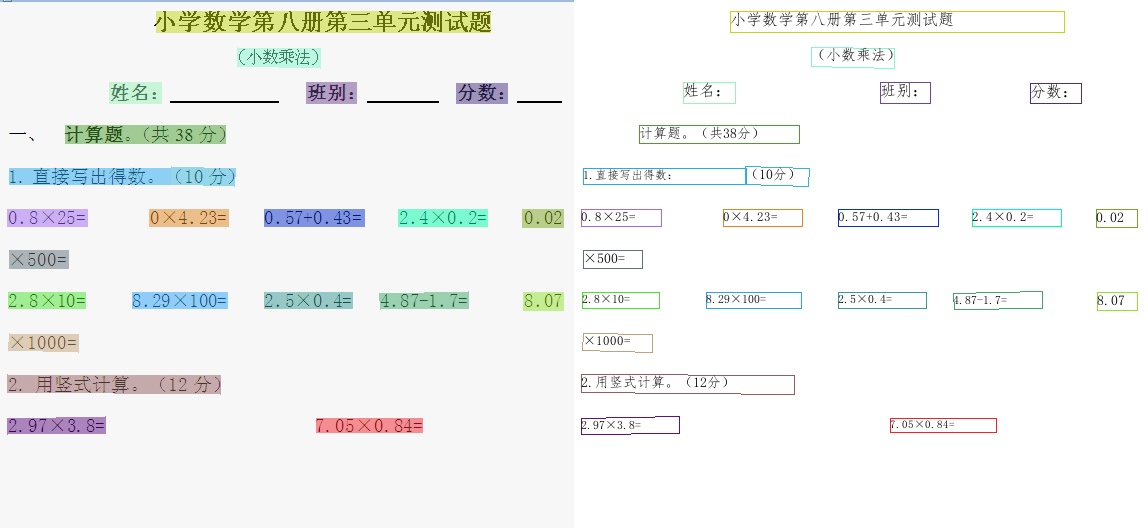
95.1 KB
{kind=link}

170.4 KB
{kind=link}
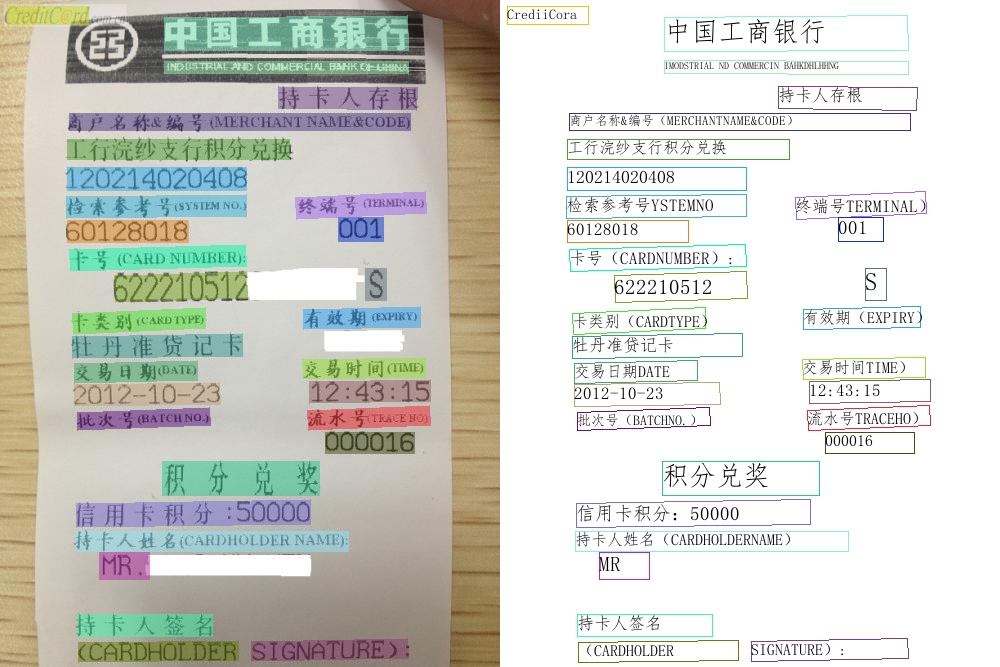
192.1 KB
{kind=link}

63.8 KB
{kind=link}
文件已移动
{kind=link}

137.6 KB
{kind=link}

78.3 KB
{kind=link}

128.9 KB
{kind=link}

89.5 KB
{kind=link}

224.0 KB
{kind=link}

180.0 KB
{kind=link}

303.3 KB
{kind=link}

140.1 KB
{kind=link}

322.6 KB
{kind=link}

198.7 KB
{kind=link}

141.5 KB
{kind=link}

129.3 KB
{kind=link}

95.6 KB
{kind=link}

118.0 KB
{kind=link}

113.5 KB
{kind=link}

151.0 KB
{kind=link}

62.3 KB
{kind=link}

120.3 KB
{kind=link}

123.1 KB
{kind=link}

153.5 KB
doc/imgs_results/det_res_22.jpg
0 → 100644
{kind=link}

76.3 KB
doc/imgs_results/french_0.jpg
0 → 100644
{kind=link}

249.3 KB
doc/imgs_results/img_10.jpg
已删除
100644 → 0
{kind=link}

138.7 KB
doc/imgs_results/img_11.jpg
已删除
100644 → 0
{kind=link}

118.2 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/imgs_results_vis2/1.jpg
已删除
100644 → 0
{kind=link}

342.2 KB
doc/imgs_results_vis2/10.jpg
已删除
100644 → 0
{kind=link}

77.1 KB
doc/imgs_results_vis2/11.jpg
已删除
100644 → 0
{kind=link}

157.4 KB
doc/imgs_results_vis2/12.jpg
已删除
100644 → 0
{kind=link}

495.5 KB
doc/imgs_results_vis2/13.png
已删除
100644 → 0
{kind=link}

1.0 MB
doc/imgs_results_vis2/15.jpg
已删除
100644 → 0
{kind=link}

334.6 KB
doc/imgs_results_vis2/16.png
已删除
100644 → 0
{kind=link}

339.9 KB
doc/imgs_results_vis2/17.png
已删除
100644 → 0
{kind=link}
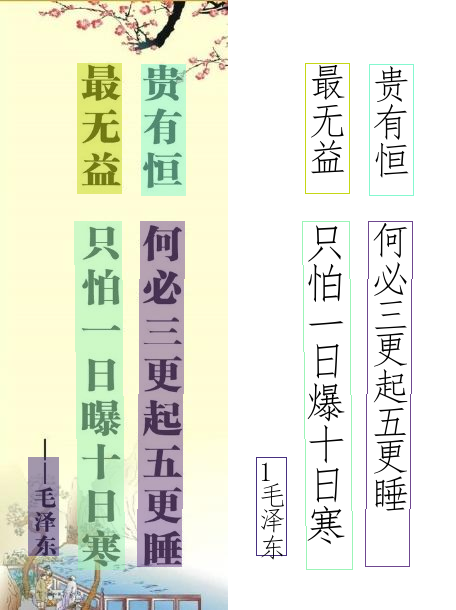
214.5 KB
doc/imgs_results_vis2/2.jpg
已删除
100644 → 0
{kind=link}

96.8 KB
doc/imgs_results_vis2/22.jpg
已删除
100644 → 0
{kind=link}

99.7 KB
doc/imgs_results_vis2/3.jpg
已删除
100644 → 0
{kind=link}

285.3 KB
doc/imgs_results_vis2/4.jpg
已删除
100644 → 0
{kind=link}

178.5 KB
doc/imgs_results_vis2/5.jpg
已删除
100644 → 0
{kind=link}

181.9 KB
doc/imgs_results_vis2/6.jpg
已删除
100644 → 0
{kind=link}

193.7 KB
doc/imgs_results_vis2/7.jpg
已删除
100644 → 0
{kind=link}

350.3 KB
doc/imgs_results_vis2/8.jpg
已删除
100644 → 0
{kind=link}

116.3 KB
doc/imgs_results_vis2/9.jpg
已删除
100644 → 0
{kind=link}

537.2 KB