Merge pull request #6191 from andyjpaddle/dygraph
update en img for ppocrv3
Showing
doc/ppocr_v3/GTC_en.png
0 → 100644
{kind=link}
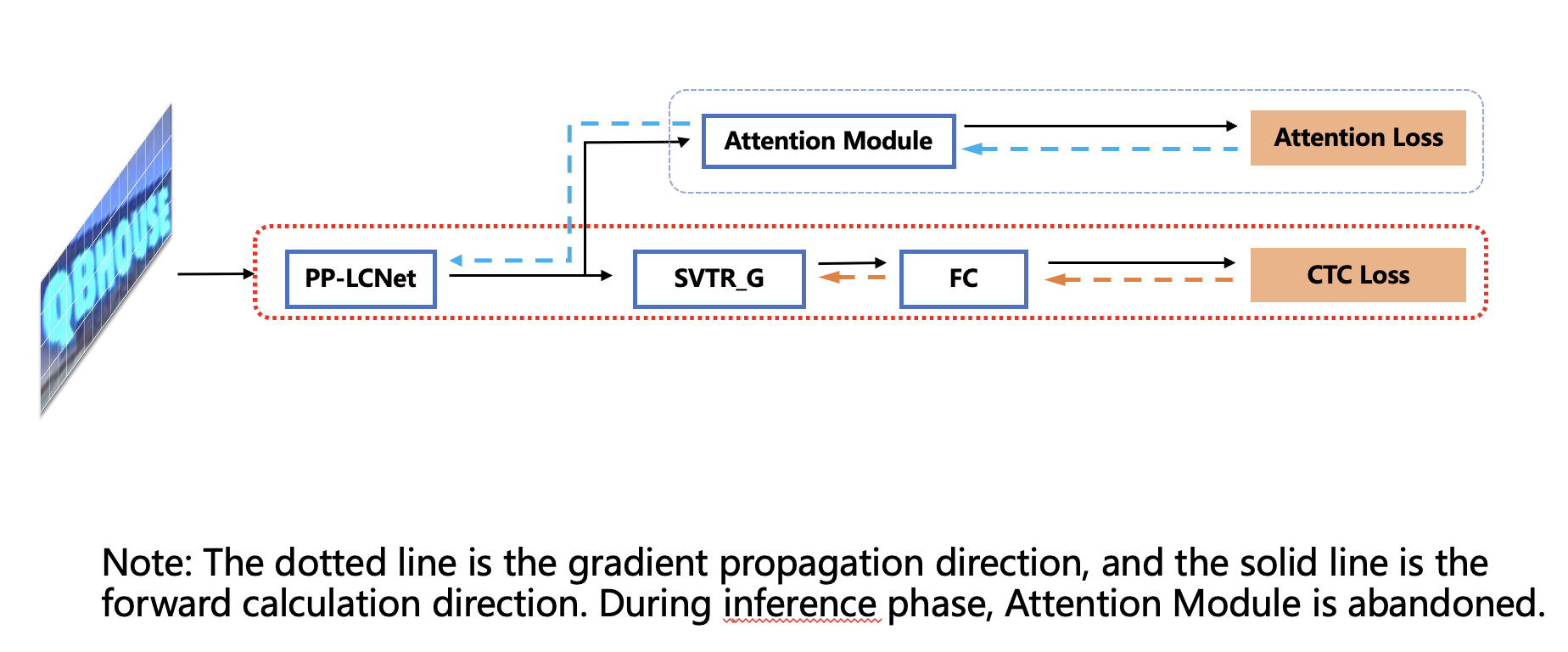
166.5 KB
doc/ppocr_v3/LCNet_SVTR_en.png
0 → 100644
{kind=link}
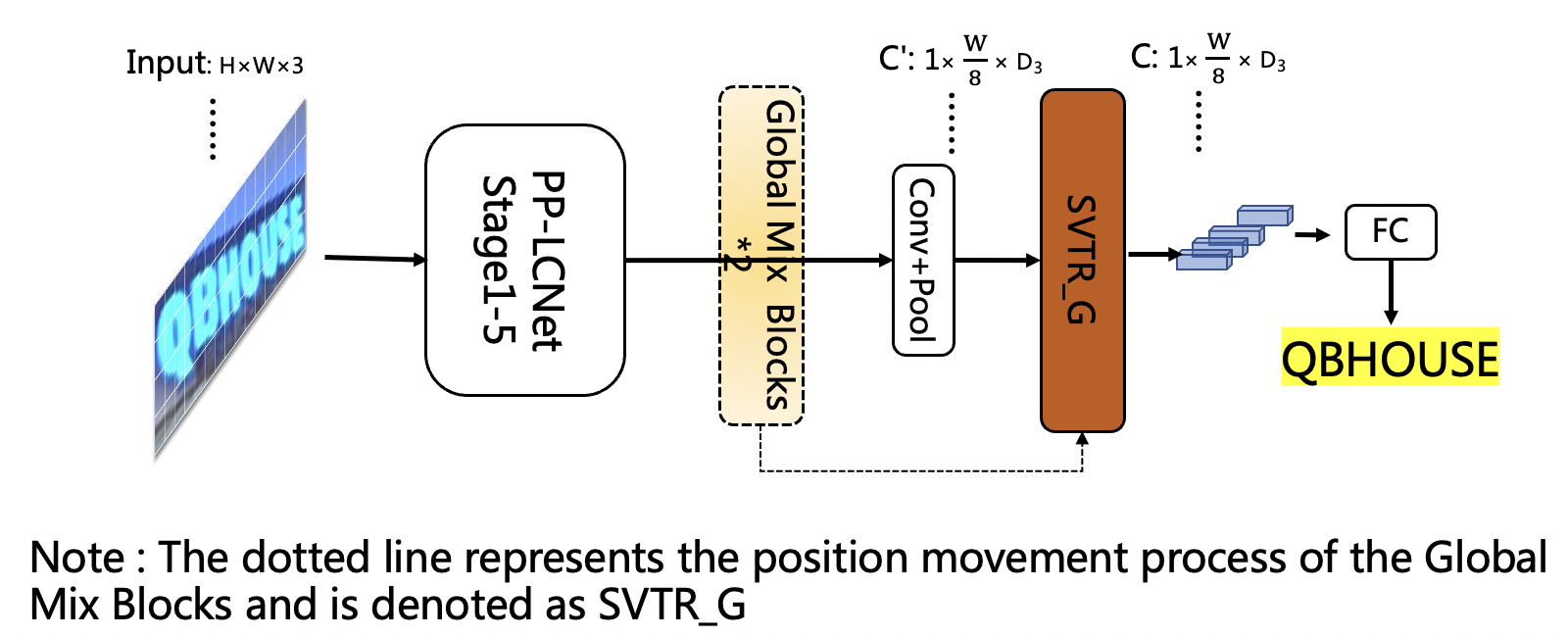
499.6 KB
update en img for ppocrv3
166.5 KB
499.6 KB