- Release [PP-Structurev2](./ppstructure/),with functions and performance fully upgraded, adapted to Chinese scenes, and new support for [Layout Recovery](./ppstructure/recovery) and **one line command to convert PDF to Word**;
- Release [PP-StructureV2](./ppstructure/),with functions and performance fully upgraded, adapted to Chinese scenes, and new support for [Layout Recovery](./ppstructure/recovery) and **one line command to convert PDF to Word**;
-[Layout Analysis](./ppstructure/layout) optimization: model storage reduced by 95%, while speed increased by 11 times, and the average CPU time-cost is only 41ms;
-[Table Recognition](./ppstructure/table) optimization: 3 optimization strategies are designed, and the model accuracy is improved by 6% under comparable time consumption;
-[Key Information Extraction](./ppstructure/kie) optimization:a visual-independent model structure is designed, the accuracy of semantic entity recognition is increased by 2.8%, and the accuracy of relation extraction is increased by 9.1%.
-**🔥2022.7 Release [OCR scene application collection](./applications/README_en.md)**
- Release **9 vertical models** such as digital tube, LCD screen, license plate, handwriting recognition model, high-precision SVTR model, etc, covering the main OCR vertical applications in general, manufacturing, finance, and transportation industries.
...
...
@@ -129,7 +129,7 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
@@ -15,15 +15,15 @@ English | [简体中文](README_ch.md)
PP-Structure is an intelligent document analysis system developed by the PaddleOCR team, which aims to help developers better complete tasks related to document understanding such as layout analysis and table recognition.
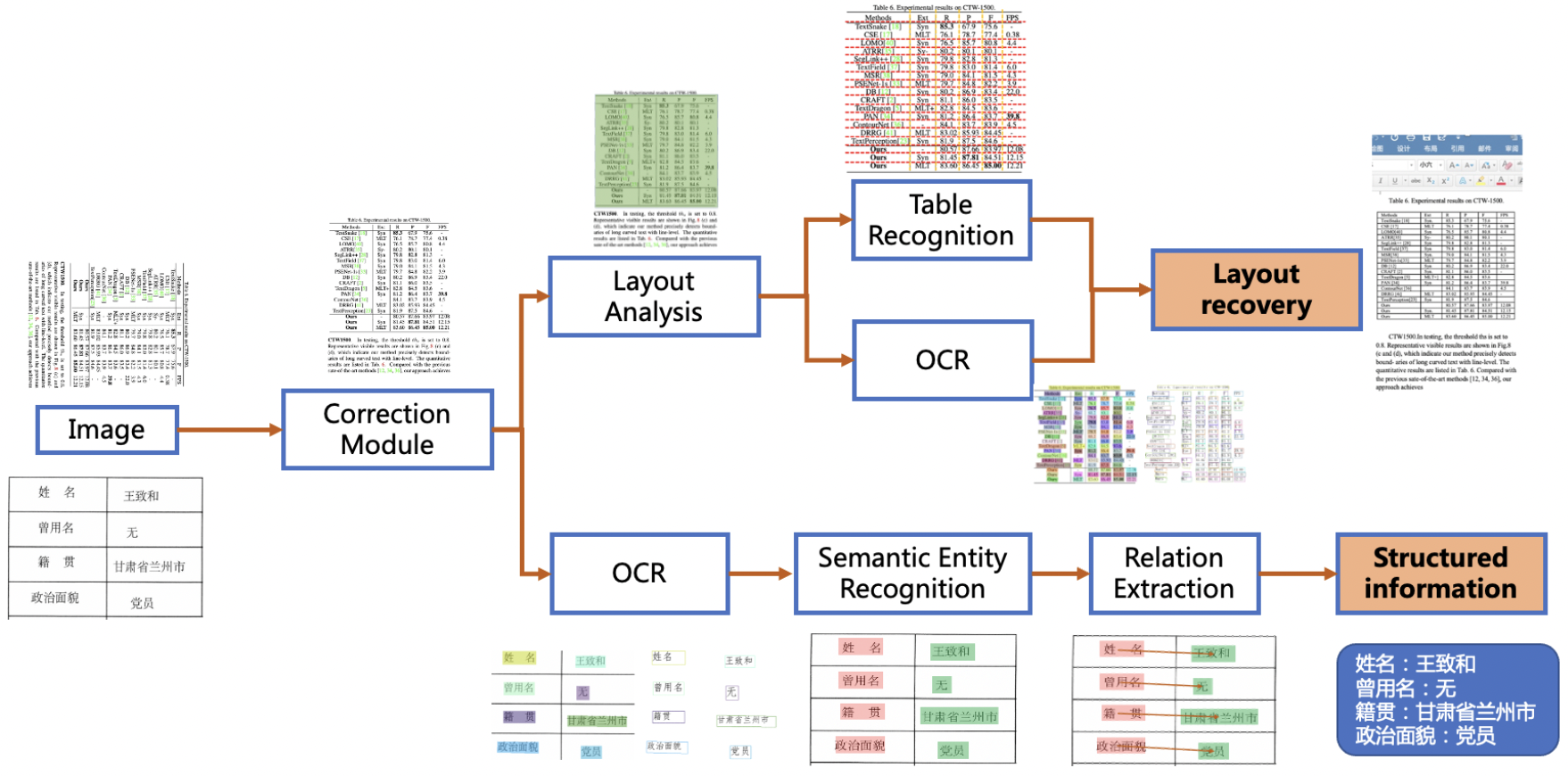
The pipeline of PP-Structurev2 system is shown below. The document image first passes through the image direction correction module to identify the direction of the entire image and complete the direction correction. Then, two tasks of layout information analysis and key information extraction can be completed.
The pipeline of PP-StructureV2 system is shown below. The document image first passes through the image direction correction module to identify the direction of the entire image and complete the direction correction. Then, two tasks of layout information analysis and key information extraction can be completed.
- In the layout analysis task, the image first goes through the layout analysis model to divide the image into different areas such as text, table, and figure, and then analyze these areas separately. For example, the table area is sent to the form recognition module for structured recognition, and the text area is sent to the OCR engine for text recognition. Finally, the layout recovery module restores it to a word or pdf file with the same layout as the original image;
- In the key information extraction task, the OCR engine is first used to extract the text content, and then the SER(semantic entity recognition) module obtains the semantic entities in the image, and finally the RE(relationship extraction) module obtains the correspondence between the semantic entities, thereby extracting the required key information.
More technical details: 👉 [PP-Structurev2 Technical Report](docs/PP-Structurev2_introduction.md)
More technical details: 👉 [PP-StructureV2 Technical Report](https://arxiv.org/abs/2210.05391)
PP-Structurev2 supports independent use or flexible collocation of each module. For example, you can use layout analysis alone or table recognition alone. Click the corresponding link below to get the tutorial for each independent module:
PP-StructureV2 supports independent use or flexible collocation of each module. For example, you can use layout analysis alone or table recognition alone. Click the corresponding link below to get the tutorial for each independent module:
-[Layout Analysis](layout/README.md)
-[Table Recognition](table/README.md)
...
...
@@ -32,7 +32,7 @@ PP-Structurev2 supports independent use or flexible collocation of each module.
## 2. Features
The main features of PP-Structurev2 are as follows:
The main features of PP-StructureV2 are as follows:
- Support layout analysis of documents in the form of images/pdfs, which can be divided into areas such as **text, titles, tables, figures, formulas, etc.**;
- Support common Chinese and English **table detection** tasks;
- Support structured table recognition, and output the final result to **Excel file**;
...
...
@@ -43,7 +43,7 @@ The main features of PP-Structurev2 are as follows:
## 3. Results
PP-Structurev2 supports the independent use or flexible collocation of each module. For example, layout analysis can be used alone, or table recognition can be used alone. Only the visualization effects of several representative usage methods are shown here.
PP-StructureV2 supports the independent use or flexible collocation of each module. For example, layout analysis can be used alone, or table recognition can be used alone. Only the visualization effects of several representative usage methods are shown here.
### 3.1 Layout analysis and table recognition
...
...
@@ -59,7 +59,7 @@ The following figure shows the effect of layout recovery based on the results of
* SER
Different colored boxes in the figure represent different categories.
Different colored boxes in the figure represent different categories.
@@ -48,7 +48,7 @@ For more detailed introduction of the algorithms, please refer to Chapter 6 of [
## 2. KIE Pipeline
Token based methods such as LayoutXLM are implemented in PaddleOCR. What's more, in PP-Structurev2, we simplify the LayoutXLM model and proposed VI-LayoutXLM, in which the visual feature extraction module is removed for speed-up. The textline sorting strategy conforming to the human reading order and UDML knowledge distillation strategy are utilized for higher model accuracy.
Token based methods such as LayoutXLM are implemented in PaddleOCR. What's more, in PP-StructureV2, we simplify the LayoutXLM model and proposed VI-LayoutXLM, in which the visual feature extraction module is removed for speed-up. The textline sorting strategy conforming to the human reading order and UDML knowledge distillation strategy are utilized for higher model accuracy.
In the non end-to-end KIE method, KIE needs at least ** 2 steps**. Firstly, the OCR model is used to extract the text and its position. Secondly, the KIE model is used to extract the key information according to the image, text position and text content.
...
...
@@ -125,7 +125,7 @@ Take the ID card scenario as an example. The key information generally includes
In terms of data, generally speaking, for relatively fixed scenes, **50** training images can achieve acceptable effects. You can refer to [PPOCRLabel](../../PPOCRLabel/README.md) for finish the labeling process.
In terms of model, it is recommended to use the VI-layoutXLM model proposed in PP-Structurev2. It is improved based on the LayoutXLM model, removing the visual feature extraction module, and further improving the model inference speed without the significant reduction on model accuracy. For more tutorials, please refer to [VI-LayoutXLM introduction](../../doc/doc_en/algorithm_kie_vi_layoutxlm_en.md) and [KIE tutorial](../../doc/doc_en/kie_en.md).
In terms of model, it is recommended to use the VI-layoutXLM model proposed in PP-StructureV2. It is improved based on the LayoutXLM model, removing the visual feature extraction module, and further improving the model inference speed without the significant reduction on model accuracy. For more tutorials, please refer to [VI-LayoutXLM introduction](../../doc/doc_en/algorithm_kie_vi_layoutxlm_en.md) and [KIE tutorial](../../doc/doc_en/kie_en.md).
#### 2.2.2 SER + RE
...
...
@@ -155,7 +155,7 @@ For each textline, you need to add 'ID' and 'linking' field information. The 'ID
In terms of data, generally speaking, for relatively fixed scenes, about **50** training images can achieve acceptable effects.
In terms of model, it is recommended to use the VI-layoutXLM model proposed in PP-Structurev2. It is improved based on the LayoutXLM model, removing the visual feature extraction module, and further improving the model inference speed without the significant reduction on model accuracy. For more tutorials, please refer to [VI-LayoutXLM introduction](../../doc/doc_en/algorithm_kie_vi_layoutxlm_en.md) and [KIE tutorial](../../doc/doc_en/kie_en.md).
In terms of model, it is recommended to use the VI-layoutXLM model proposed in PP-StructureV2. It is improved based on the LayoutXLM model, removing the visual feature extraction module, and further improving the model inference speed without the significant reduction on model accuracy. For more tutorials, please refer to [VI-LayoutXLM introduction](../../doc/doc_en/algorithm_kie_vi_layoutxlm_en.md) and [KIE tutorial](../../doc/doc_en/kie_en.md).

{kind=link}