update ppocrv3 introduction
Showing
doc/ppocr_v3/GTC.png
0 → 100644
{kind=link}
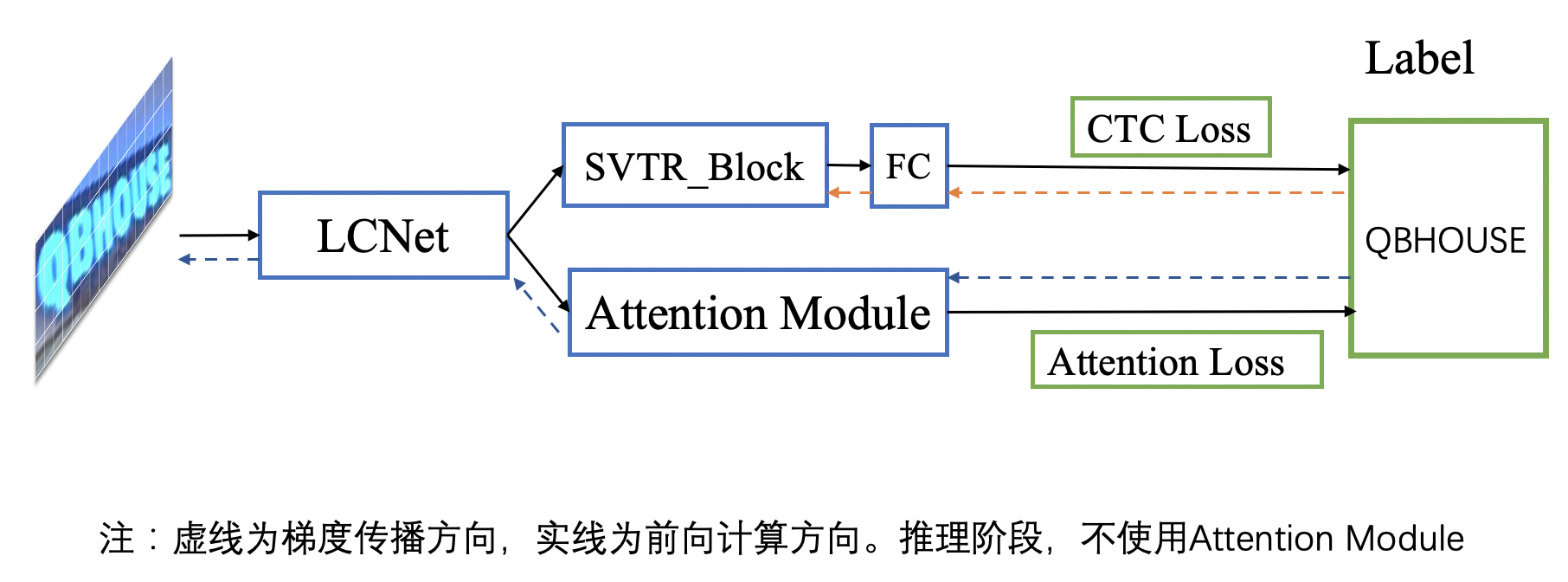
415.0 KB
doc/ppocr_v3/SSL.png
0 → 100644
{kind=link}
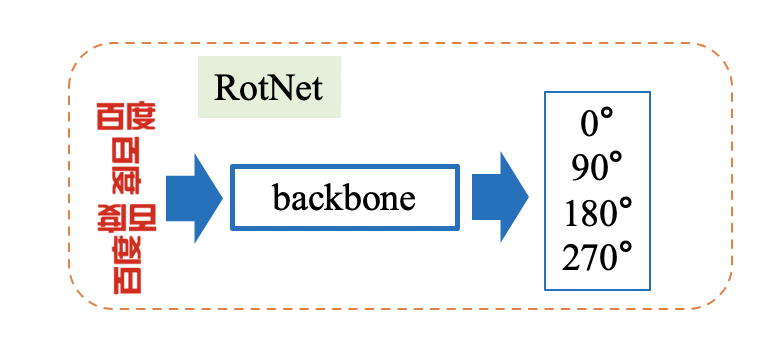
111.5 KB
doc/ppocr_v3/UDML.png
0 → 100644
{kind=link}
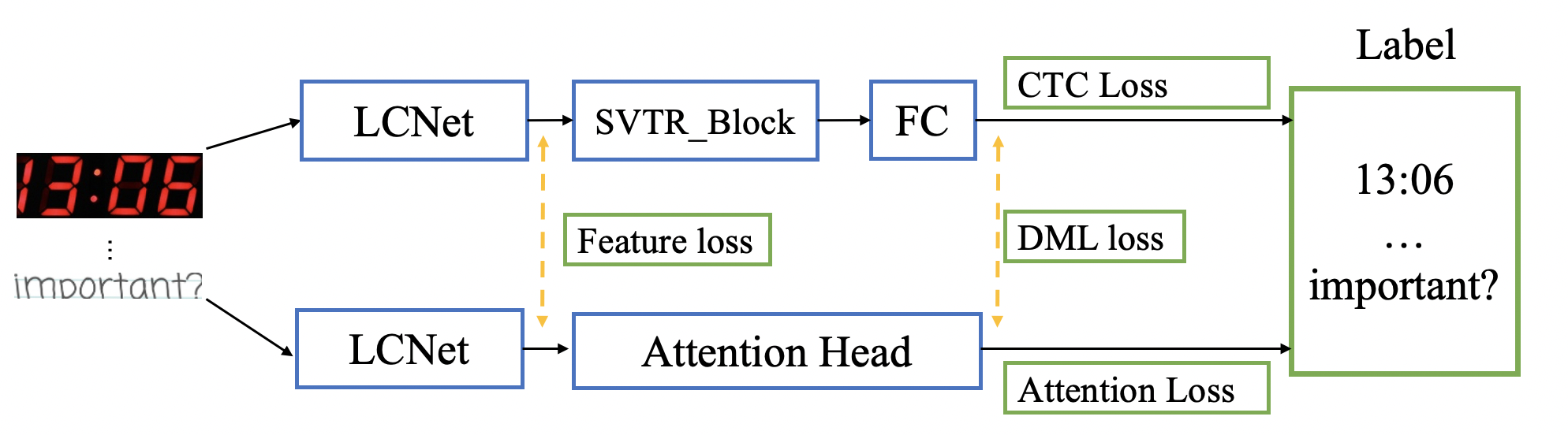
348.7 KB
doc/ppocr_v3/ppocr_v3.png
0 → 100644
{kind=link}
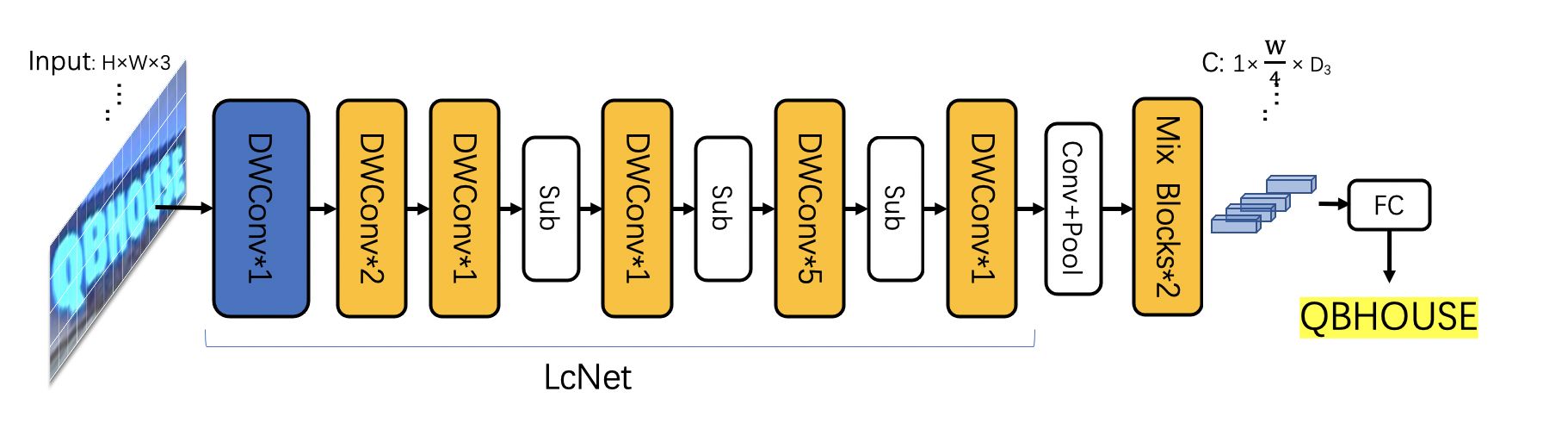
400.5 KB
doc/ppocr_v3/recconaug.png
0 → 100644
{kind=link}
296.6 KB
doc/ppocr_v3/svtr_g2.png
0 → 100644
{kind=link}
400.5 KB
doc/ppocr_v3/svtr_g4.png
0 → 100644
{kind=link}
334.2 KB
doc/ppocr_v3/svtr_tiny.jpg
0 → 100644
{kind=link}
323.6 KB