Merge branch 'dygraph' into add_test_serving
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
ppocr/utils/dict90.txt
0 → 100644
tests/docs/compare_right.png
0 → 100644
{kind=link}

33.0 KB
tests/docs/compare_wrong.png
0 → 100644
{kind=link}
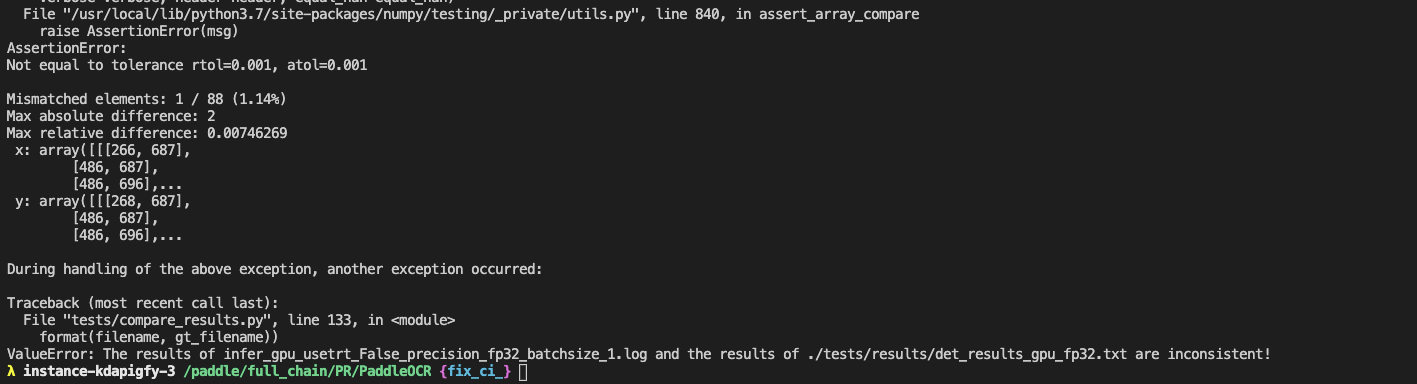
64.2 KB
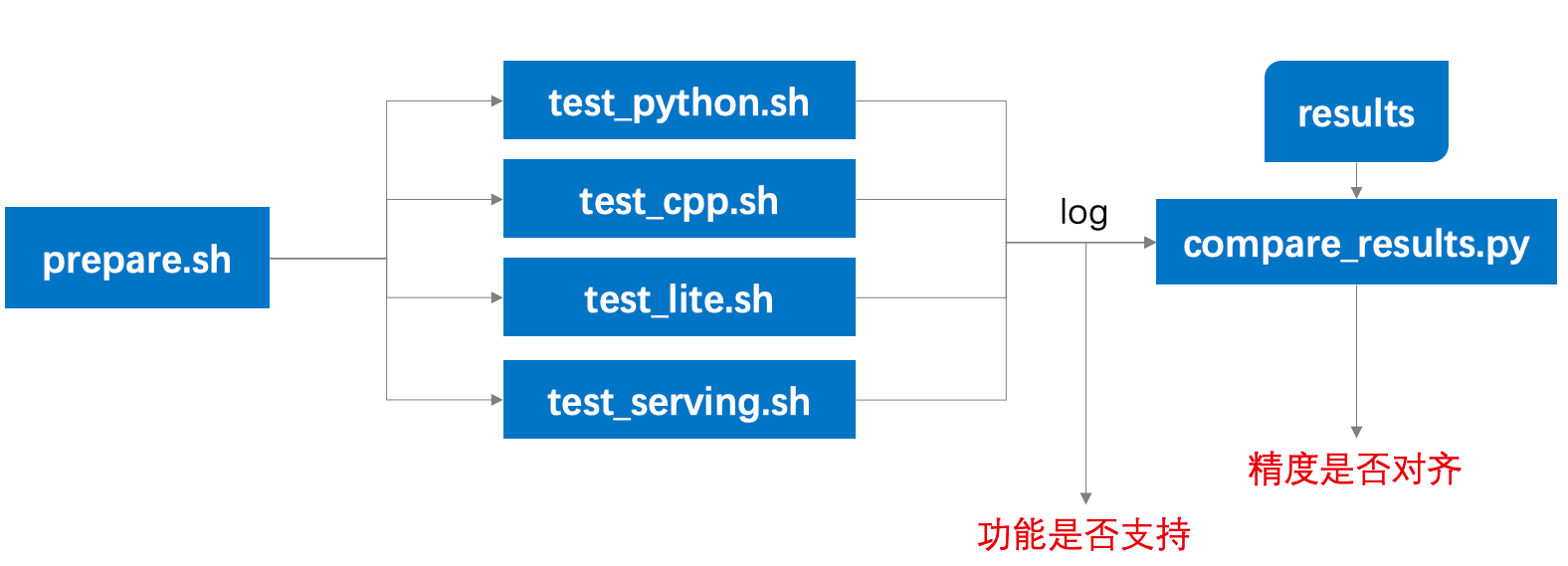
tests/docs/guide.png
0 → 100644
{kind=link}

138.3 KB
tests/docs/test.png
0 → 100644
{kind=link}
71.8 KB
tests/docs/test_cpp.md
0 → 100644
tests/docs/test_python.md
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
tests/test.sh
已删除
100644 → 0
此差异已折叠。