Merge pull request #7940 from dorren002/new_branch
add handwritten mathematical expression recognition algorithm CAN
Showing
configs/rec/rec_d28_can.yml
0 → 100644
{kind=link}
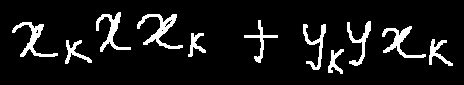
11.5 KB
{kind=link}
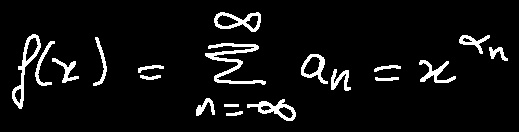
14.9 KB
{kind=link}
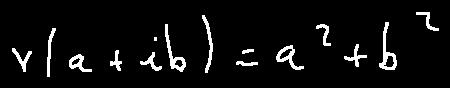
4.8 KB
doc/doc_ch/algorithm_rec_can.md
0 → 100644
ppocr/losses/rec_can_loss.py
0 → 100644