Merge remote-tracking branch 'upstream/develop' into develop
update
Showing
deploy/pdserving/readme_en.md
0 → 100644
doc/doc_ch/algorithm_overview.md
0 → 100644
doc/doc_ch/tree.md
0 → 100644
doc/doc_ch/tricks.md
已删除
100644 → 0
doc/doc_en/models_list_en.md
0 → 100644
doc/french.ttf
0 → 100644
文件已添加
doc/german.ttf
0 → 100644
文件已添加
doc/imgs_results/1101.jpg
0 → 100644
{kind=link}

81.7 KB
doc/imgs_results/1102.jpg
0 → 100644
{kind=link}

147.1 KB
doc/imgs_results/1103.jpg
0 → 100644
{kind=link}
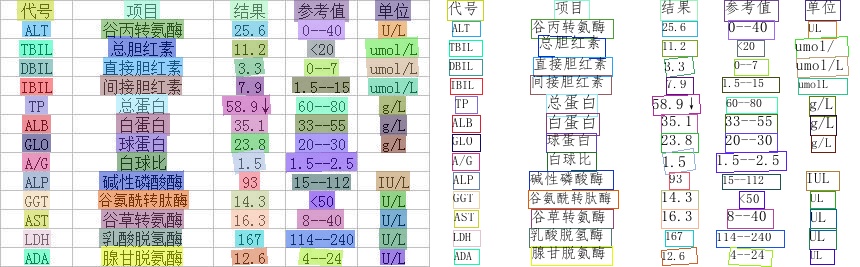
124.2 KB
doc/imgs_results/1104.jpg
0 → 100644
{kind=link}
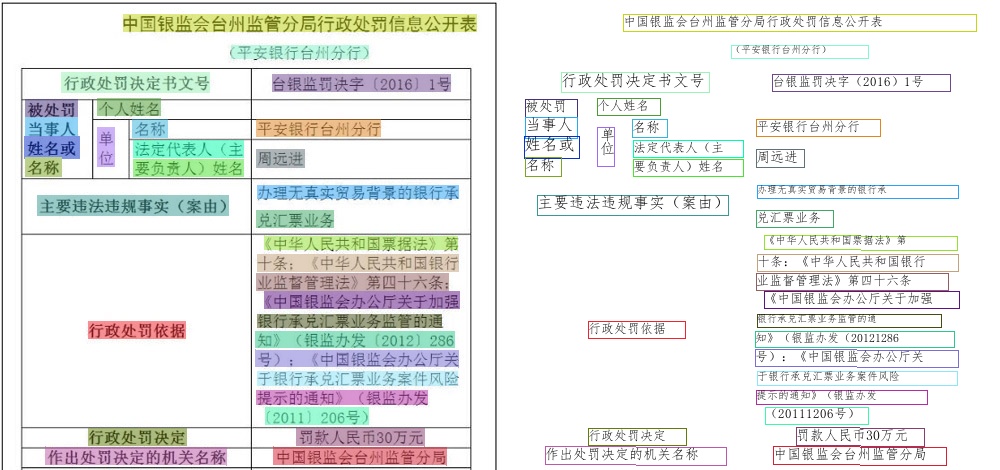
163.6 KB
doc/imgs_results/1105.jpg
0 → 100644
{kind=link}

136.8 KB
doc/imgs_results/1110.jpg
0 → 100644
{kind=link}

130.1 KB
doc/imgs_results/1112.jpg
0 → 100644
{kind=link}

101.8 KB
doc/imgs_words/french/1.jpg
0 → 100644
{kind=link}

9.5 KB
doc/imgs_words/french/2.jpg
0 → 100644
{kind=link}

12.6 KB
doc/imgs_words/german/1.jpg
0 → 100644
{kind=link}

8.2 KB
doc/imgs_words/japan/1.jpg
0 → 100644
{kind=link}

8.7 KB
doc/imgs_words/korean/1.jpg
0 → 100644
{kind=link}

3.6 KB
doc/imgs_words/korean/2.jpg
0 → 100644
{kind=link}

4.4 KB
doc/japan.ttc
0 → 100644
文件已添加
doc/korean.ttf
0 → 100644
文件已添加
ppocr/utils/french_dict.txt
0 → 100644
ppocr/utils/german_dict.txt
0 → 100644
ppocr/utils/japan_dict.txt
0 → 100644
此差异已折叠。
ppocr/utils/korean_dict.txt
0 → 100644
此差异已折叠。
train_data/gen_label.py
0 → 100644