“5f2ecb855e9c52b4bdc1a6cab5194394de08210e”上不存在“ppocr/modeling/git@gitcode.net:s920243400/PaddleOCR.git”
Merge pull request #3918 from grasswolfs/update_readme_0906
update readme
Showing
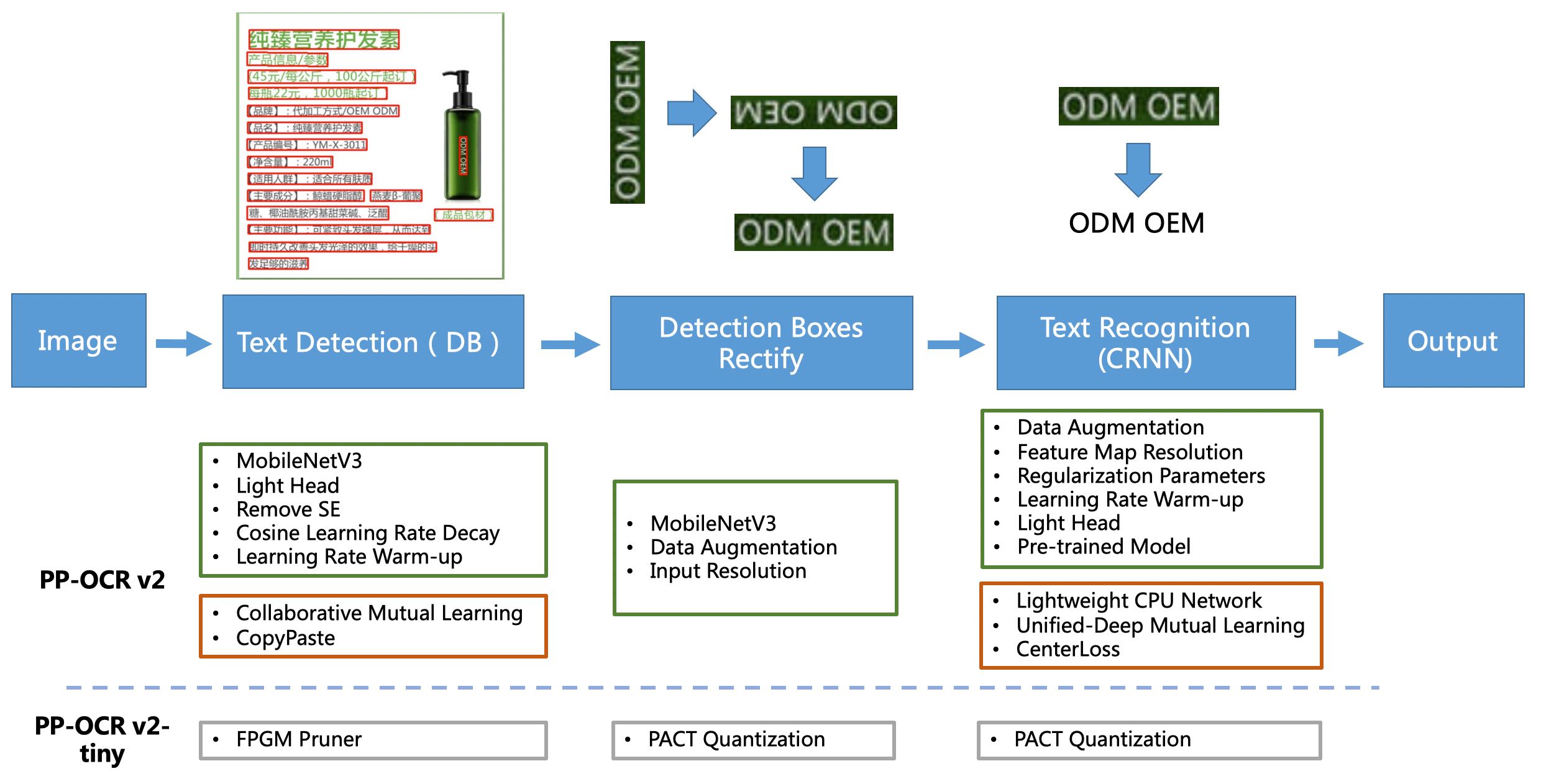
doc/ppocrv2_framework.jpg
0 → 100644
{kind=link}
260.7 KB