Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into dygraph
Showing
{kind=link}
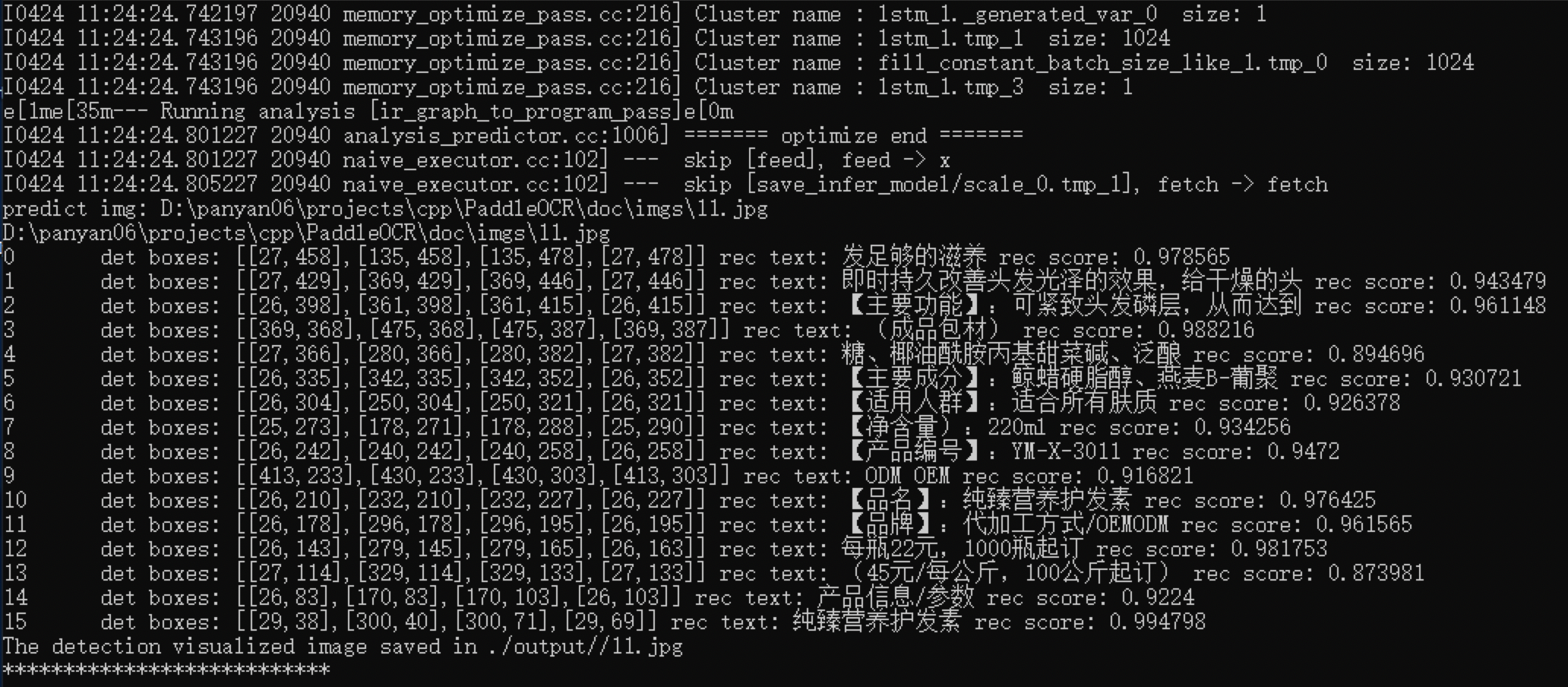
791.1 KB
{kind=link}
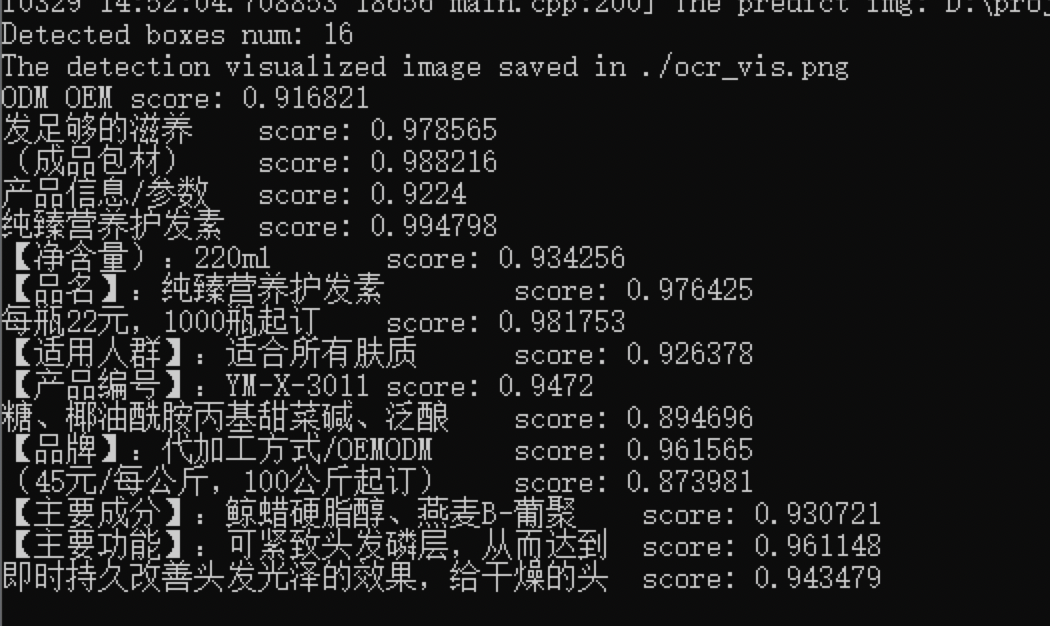
352.4 KB
{kind=link}
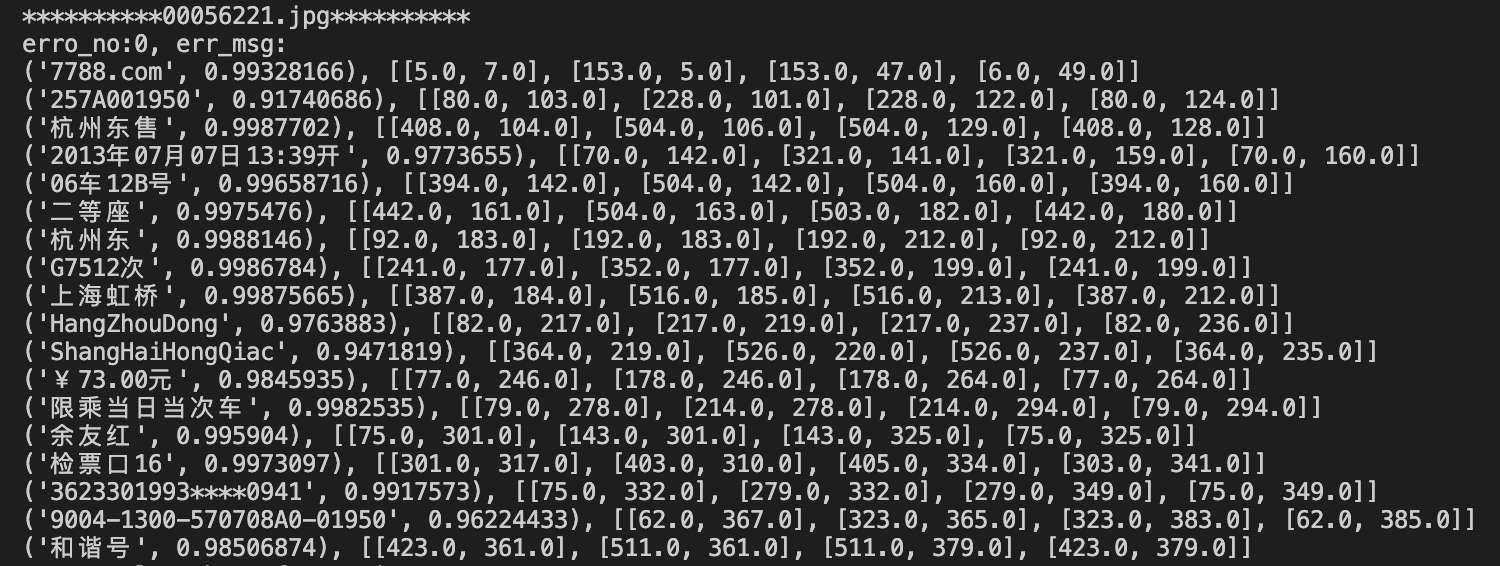
492.9 KB
{kind=link}

594.4 KB
{kind=link}

628.5 KB
{kind=link}
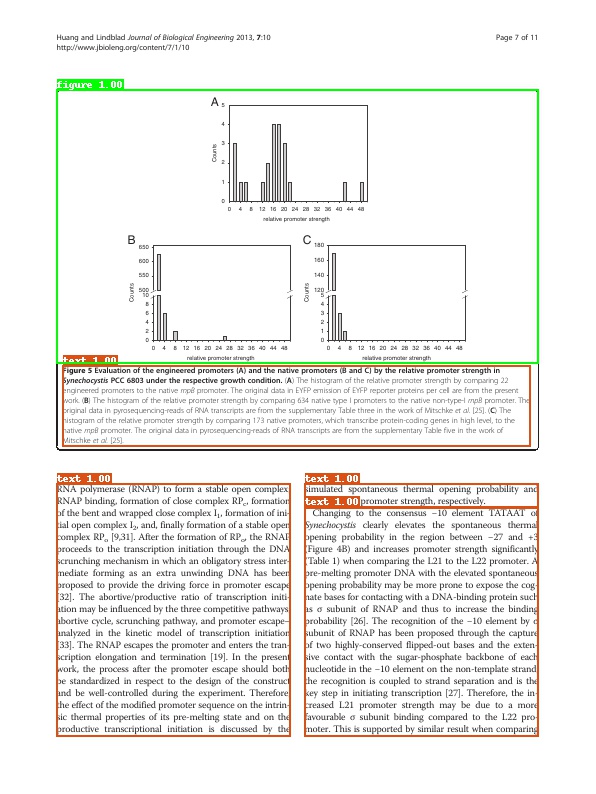
162.7 KB
{kind=link}

120.4 KB
{kind=link}

613.0 KB
{kind=link}
224.1 KB
791.1 KB
352.4 KB
492.9 KB
594.4 KB
628.5 KB
162.7 KB
120.4 KB
613.0 KB
224.1 KB