“f76dbd5830d011f3d5c8a8fde5d4e7738979671b”上不存在“source/dnode/mnode/impl/src/mnodeProfile.c”
Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
doc/datasets/icdar_rec.png
0 → 100644
{kind=link}

921.4 KB
doc/ic15_location_download.png
0 → 100644
{kind=link}
80.1 KB
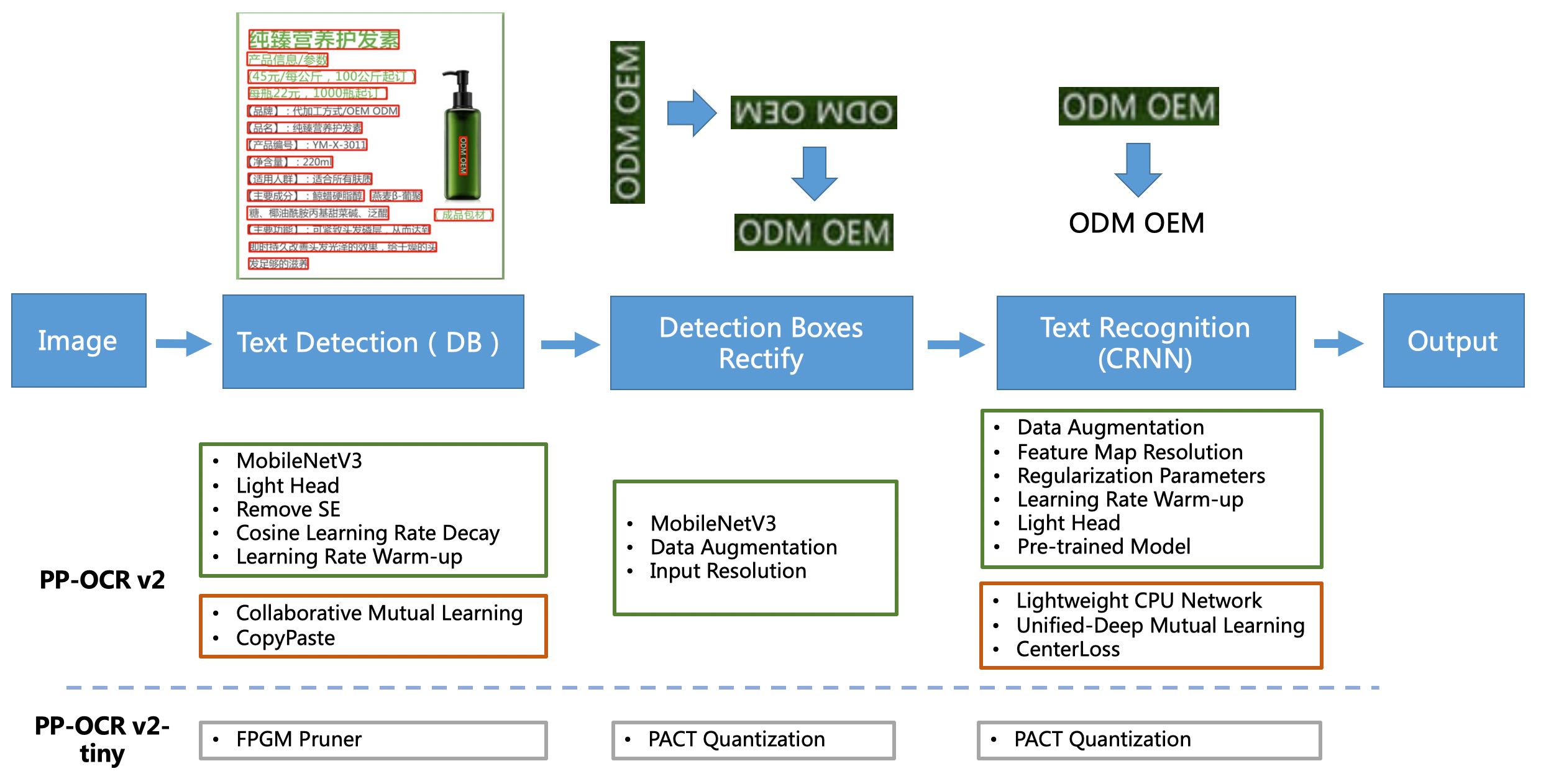
doc/ppocrv2_framework.jpg
0 → 100644
{kind=link}
260.7 KB